Több száz terabájtnyi adat migrálása az Azure Cosmos DB-be
A KÖVETKEZŐKRE VONATKOZIK: ![]() NoSQL
NoSQL ![]() MongoDB
MongoDB ![]() Cassandra
Cassandra ![]() Gremlin
Gremlin ![]() Asztal
Asztal
Az Azure Cosmos DB több terabájtnyi adatot tud tárolni. Nagy léptékű adatmigrálás elvégzésével áthelyezheti éles számítási feladatait az Azure Cosmos DB-be. Ez a cikk azokat a kihívásokat ismerteti, amelyek a nagy léptékű adatok az Azure Cosmos DB-be való áthelyezésével kapcsolatosak, továbbá bemutatja az eszközt, amely segít a kihívások leküzdésében, és az adatok az Azure Cosmos DB-be történő migrálásában. Ebben az esettanulmányban az ügyfél az Azure Cosmos DB API for NoSQL-t használta.
Mielőtt a teljes számítási feladatot áttelepítené az Azure Cosmos DB-be, migrálhatja az adatok egy részhalmazát, hogy érvényesítsen néhány szempontot, például a partíciókulcs-választást, a lekérdezési teljesítményt és az adatmodellezést. A koncepció igazolásának ellenőrzése után a teljes számítási feladatot áthelyezheti az Azure Cosmos DB-be.
Eszközök az adatmigráláshoz
Az Azure Cosmos DB migrálási stratégiái jelenleg eltérnek az API-választás és az adatok mérete alapján. Kisebb adathalmazok migrálásához – adatmodellezés, lekérdezési teljesítmény, partíciókulcs-választás stb. – az Azure Data Factory Azure Cosmos DB-összekötőjét használhatja. Ha ismeri a Sparkot, az Azure Cosmos DB Spark-összekötőt is használhatja az adatok migrálásához.
A nagy léptékű migrálás kihívásai
Az adatok Azure Cosmos DB-be való migrálására szolgáló meglévő eszközök bizonyos korlátozásokkal rendelkeznek, amelyek nagy méretekben különösen nyilvánvalóvá válnak:
Korlátozott vertikális felskálázási képességek: Annak érdekében, hogy a lehető leggyorsabban migrálhassa a terabájtnyi adatot az Azure Cosmos DB-be, és hatékonyan felhasználhassa a teljes kiosztott átviteli sebességet, a migrálási ügyfeleknek korlátlanul fel kell tudniuk skálázni őket.
Az előrehaladás nyomon követésének és ellenőrzésének hiánya: Fontos nyomon követni a migrálás előrehaladását, és ellenőrizni kell a nagy adathalmazok migrálása során. Ellenkező esetben az áttelepítés során fellépő hibák leállják az áttelepítést, és a folyamatot teljesen el kell kezdenie. Nem lenne hatékony a teljes migrálási folyamat újraindítása, ha annak 99%-a már befejeződött.
A kézbesítetlen levelek üzenetsorának hiánya: A nagy adathalmazokban bizonyos esetekben problémák merülhetnek fel a forrásadatok egyes részeivel kapcsolatban. Emellett átmeneti problémák is lehetnek az ügyféllel vagy a hálózattal kapcsolatban. Az ilyen esetek egyike sem okozhatja a teljes migrálás meghiúsulását. Annak ellenére, hogy a legtöbb migrálási eszköz robusztus újrapróbálkozó képességekkel rendelkezik, amelyek védik az időszakos problémákat, ez nem mindig elég. Ha például a forrásadat-dokumentumok kevesebb mint 0,01%-a nagyobb 2 MB-nál, akkor a dokumentum írása meghiúsul az Azure Cosmos DB-ben. Ideális esetben hasznos lehet, ha a migrálási eszköz ezeket a "sikertelen" dokumentumokat egy másik, a migrálás után feldolgozható üzenetsorba megőrzi.
Ezen korlátozások közül számos ki van javítva olyan eszközök esetében, mint az Azure Data Factory, az Azure Data Migration Services.
Egyéni eszköz tömeges végrehajtótárral
A fenti szakaszban ismertetett kihívások egy olyan egyéni eszközzel oldhatók meg, amely több példányra egyszerűen skálázható, és ellenáll az átmeneti hibáknak. Emellett az egyéni eszköz szüneteltetheti és folytathatja a migrálást különböző ellenőrzőpontokon. Az Azure Cosmos DB már biztosítja a tömeges végrehajtói kódtárat , amely ezen funkciók némelyikét tartalmazza. A tömeges végrehajtói kódtár például már rendelkezik az átmeneti hibák kezelésére szolgáló funkcióval, és egyetlen csomópont szálainak skálázásához csomópontonként körülbelül 500 K kérelemegységet használhat fel. A tömeges végrehajtói kódtár a forrásadatkészletet olyan mikro kötegekre is particionálta, amelyek egymástól függetlenül, ellenőrzőpont-készítés formájában működnek.
Az egyéni eszköz a tömeges végrehajtói kódtárat használja, és támogatja a több ügyfél közötti horizontális felskálázást, valamint a hibák nyomon követését a betöltési folyamat során. Az eszköz használatához a forrásadatokat külön fájlokba kell particionálnia az Azure Data Lake Storage-ban (ADLS), hogy a különböző migrálási feldolgozók fel tudják venni az egyes fájlokat, és betöltsék őket az Azure Cosmos DB-be. Az egyéni eszköz egy külön gyűjteményt használ, amely metaadatokat tárol az egyes forrásfájlok áttelepítési folyamatáról az ADLS-ben, és nyomon követi a hozzájuk kapcsolódó hibákat.
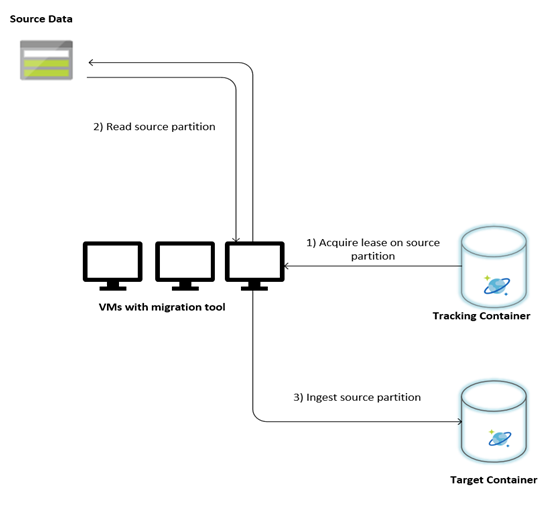
Az alábbi kép az egyéni eszköz használatával végzett migrálási folyamatot ismerteti. Az eszköz virtuális gépeken fut, és minden virtuális gép lekérdezi a nyomkövetési gyűjteményt az Azure Cosmos DB-ben, hogy megszerezze a bérletet az egyik forrásadatpartíción. Ha ez megtörtént, az eszköz beolvassa a forrásadatpartíciót, és betölti az Azure Cosmos DB-be a tömeges végrehajtói kódtár használatával. Ezután a nyomkövetési gyűjtemény frissül az adatbetöltés előrehaladásának és a felmerülő hibáknak a rögzítéséhez. Az adatpartíció feldolgozása után az eszköz megpróbálja lekérdezni a következő elérhető forráspartíciót. A következő forráspartíció feldolgozása mindaddig folytatódik, amíg az összes adat át nem lesz migrálva. Az eszköz forráskódja az Azure Cosmos DB tömeges betöltési adattárában érhető el.
A nyomkövetési gyűjtemény az alábbi példában látható dokumentumokat tartalmazza. Ezeket a dokumentumokat a forrásadatok minden partíciója esetében látni fogja. Minden dokumentum tartalmazza a forrásadatpartíció metaadatait, például a helyét, az áttelepítés állapotát és a hibákat (ha vannak):
{
"owner": "25812@bulkimporttest07",
"jsonStoreEntityImportResponse": {
"numberOfDocumentsReceived": 446688,
"isError": false,
"totalRequestUnitsConsumed": 3950252.2800000003,
"errorInfo": [],
"totalTimeTakenInSeconds": 188,
"numberOfDocumentsImported": 446688
},
"storeType": "AZURE_BLOB",
"name": "sourceDataPartition",
"location": "sourceDataPartitionLocation",
"id": "sourceDataPartitionId",
"isInProgress": false,
"operation": "unpartitioned-writes",
"createDate": {
"seconds": 1561667225,
"nanos": 146000000
},
"completeDate": {
"seconds": 1561667515,
"nanos": 180000000
},
"isComplete": true
}
Az adatmigrálás előfeltételei
Az adatmigrálás megkezdése előtt érdemes megfontolni néhány előfeltételt:
Az adatméret becslése:
Előfordulhat, hogy a forrásadat mérete nem pontosan megfelel az Azure Cosmos DB adatméretének. A forrásból származó néhány mintadokumentum beszúrható az adatméretük ellenőrzéséhez az Azure Cosmos DB-ben. A mintadokumentum méretétől függően az Azure Cosmos DB teljes adatmérete a migrálás után megbecsülhető.
Ha például az Azure Cosmos DB-ben végzett migrálás után minden dokumentum körülbelül 1 KB, és ha a forrásadatkészletben körülbelül 60 milliárd dokumentum található, az azt jelentené, hogy az Azure Cosmos DB becsült mérete megközelítené a 60 TB-ot.
Tárolók előzetes létrehozása elegendő kérelemegységtel:
Bár az Azure Cosmos DB automatikusan skálázza ki a tárterületet, nem ajánlott a legkisebb tárolóméretből kiindulni. A kisebb tárolók alacsonyabb átviteli sebességgel rendelkeznek, ami azt jelenti, hogy a migrálás sokkal tovább tart. Ehelyett érdemes létrehozni a tárolókat a végső adatmérettel (az előző lépésben becsült módon), és győződjön meg arról, hogy a migrálási számítási feladat teljes mértékben kihasználja a kiosztott átviteli sebességet.
Az előző lépésben. mivel az adatméretet körülbelül 60 TB-ra becsülték, a teljes adatkészlet elhelyezéséhez legalább 2,4 M kérelemegységet tartalmazó tárolóra van szükség.
A migrálás sebességének becslése:
Feltételezve, hogy a migrálási számítási feladat a teljes kiosztott átviteli sebességet képes felhasználni, a kiosztott teljes adatmennyiség becslést adna a migrálási sebességről. Az előző példát folytatva 5 kérelemegység szükséges egy 1 KB-os dokumentum írásához az Azure Cosmos DB API for NoSQL-fiókba. A 2,4 millió kérelemegység másodpercenként 480 000 dokumentum (vagy 480 MB/s) átadását teszi lehetővé. Ez azt jelenti, hogy a 60 TB teljes migrálása 125 000 másodpercet vagy körülbelül 34 órát vesz igénybe.
Ha azt szeretné, hogy a migrálás egy napon belül befejeződjön, a kiosztott átviteli sebességet 5 millió kérelemegységre kell növelnie.
Az indexelés kikapcsolása:
Mivel a migrálást a lehető leghamarabb végre kell hajtani, célszerű minimalizálni az egyes betöltött dokumentumok indexeinek létrehozására fordított időt és kérelemegységeket. Az Azure Cosmos DB automatikusan indexeli az összes tulajdonságot, érdemes minimalizálni az indexelést néhány kifejezésre, vagy teljesen kikapcsolni a migrálás során. A tároló indexelési házirendjét kikapcsolhatja úgy, hogy az indexelésiMode értéket egyikre sem módosítja az alábbiak szerint:
{
"indexingMode": "none"
}
Az áttelepítés befejezése után frissítheti az indexelést.
Migrálási folyamat
Az előfeltételek teljesítése után az alábbi lépésekkel migrálhatja az adatokat:
Először importálja az adatokat a forrásból az Azure Blob Storage-ba. A migrálás sebességének növelése érdekében hasznos a különböző forráspartíciók közötti párhuzamosítás. A migrálás megkezdése előtt a forrásadatkészletet körülbelül 200 MB méretű fájlokra kell particionálni.
A tömeges végrehajtói kódtár felskálázható, így egyetlen ügyfél virtuális gépen 500 000 kérelemegységet használhat fel. Mivel az elérhető átviteli sebesség 5 millió kérelemegység, 10 Ubuntu 16.04 virtuális gépet (Standard_D32_v3) kell üzembe helyezni ugyanabban a régióban, ahol az Azure Cosmos DB-adatbázis található. Ezeket a virtuális gépeket az áttelepítési eszközzel és annak beállításfájljával kell előkészíteni.
Futtassa az üzenetsor-lépést az egyik ügyfél virtuális gépen. Ez a lépés létrehozza a nyomkövetési gyűjteményt, amely megvizsgálja az ADLS-tárolót, és létrehoz egy folyamatkövetési dokumentumot a forrásadatkészlet partíciófájljaihoz.
Ezután futtassa az importálási lépést az összes ügyfél virtuális gépen. Mindegyik ügyfél tulajdonjogot vállalhat egy forráspartíción, és betöltheti az adatait az Azure Cosmos DB-be. Miután elkészült, és az állapota frissül a nyomkövetési gyűjteményben, az ügyfelek lekérdezhetik a következő elérhető forráspartíciót a nyomkövetési gyűjteményben.
Ez a folyamat a forráspartíciók teljes készletének betöltéséig folytatódik. Az összes forráspartíció feldolgozása után az eszközt újra kell futtatni a hibajavítási módban ugyanazon a nyomkövetési gyűjteményen. Ez a lépés a hibák miatt újra feldolgozandó forráspartíciók azonosításához szükséges.
A hibák némelyike a forrásadatok helytelen dokumentumai miatt lehet. Ezeket azonosítani és kijavítani kell. Ezután futtassa újra az importálási lépést a sikertelen partíciókon az újratöltésükhöz.
A migrálás befejezése után ellenőrizheti, hogy az Azure Cosmos DB-ben a dokumentumszám megegyezik-e a forrásadatbázis dokumentumszámával. Ebben a példában az Azure Cosmos DB teljes mérete 65 terabájtra változott. A migrálás után az indexelés szelektíven be van kapcsolva, és a kérelemegységek a számítási feladat műveletei által megkövetelt szintre csökkenthetők.
Következő lépések
- További információ a .NET-ben és Java-ban a tömeges végrehajtói kódtárat használó mintaalkalmazások kipróbálásával.
- A tömeges végrehajtói kódtár integrálva van az Azure Cosmos DB Spark-összekötőbe, további információt az Azure Cosmos DB Spark-összekötőről szóló cikkben talál.
- A nagy léptékű migrálásokkal kapcsolatos további segítségért lépjen kapcsolatba az Azure Cosmos DB termékcsapatával, és nyissa meg az "Általános tanácsadás" és a "Nagy (TB+) migrálások" probléma altípusú támogatási jegyet.
- Kapacitástervezést szeretne végezni az Azure Cosmos DB-be való migráláshoz? A kapacitástervezéshez használhatja a meglévő adatbázisfürt adatait.
- Ha csak annyit tud, hogy hány virtuális mag és kiszolgáló található a meglévő adatbázisfürtben, olvassa el a kérelemegységek becslését virtuális magok vagy vCPU-k használatával
- Ha ismeri az aktuális adatbázis számítási feladataira vonatkozó tipikus kérési arányokat, olvassa el a kérelemegységek becslését az Azure Cosmos DB kapacitástervezővel