Adatok migrálása a MongoDB-ből egy Azure Cosmos DB for MongoDB-fiókba az Azure Databricks használatával
A KÖVETKEZŐKRE VONATKOZIK: ![]() MongoDB
MongoDB
Ez a migrálási útmutató az adatbázisok MongoDB-ből MongoDB-hez készült Azure Cosmos DB API-ba való migrálásáról szóló sorozat része. A kritikus migrálási lépések a migrálás előtti, a migrálás utáni és a migrálás utáni lépések, ahogyan az alább látható.
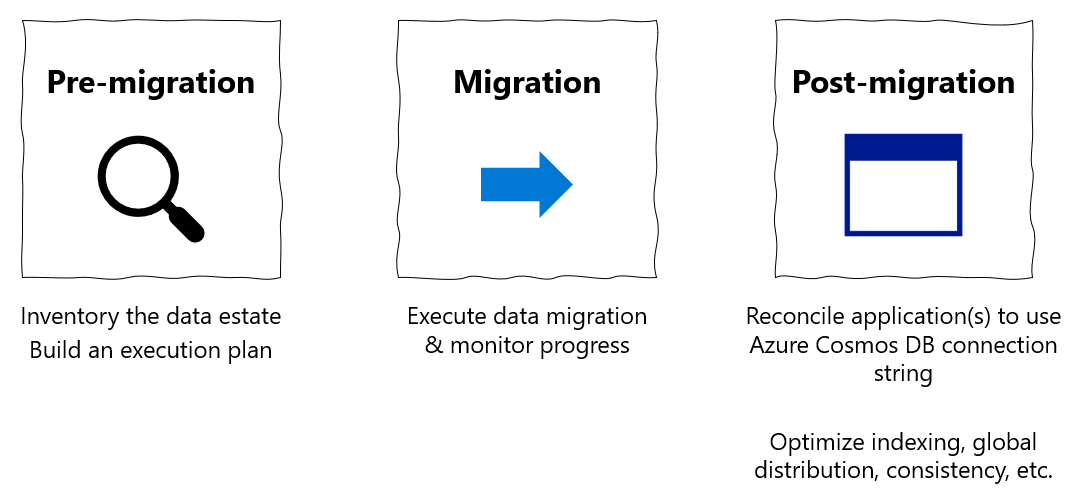
Adatmigrálás az Azure Databricks használatával
Az Azure Databricks egy szolgáltatásként nyújtott platform (PaaS) az Apache Sparkhoz. Lehetővé teszi az offline migrálást egy nagy méretű adathalmazon. Az Azure Databricks használatával offline migrálhatja az adatbázisokat a MongoDB-ből a MongoDB-hez készült Azure Cosmos DB-be.
Az oktatóanyag során a következőket fogja elsajátítani:
Azure Databricks-fürt kiépítése
Függőségek hozzáadása
Scala- vagy Python-jegyzetfüzet létrehozása és futtatása
Az áttelepítési teljesítmény optimalizálása
A migrálás során esetleg megfigyelt sebességkorlátozó hibák elhárítása
Előfeltételek
Az oktatóanyag elvégzéséhez a következőkre lesz szüksége:
- Végezze el az áttelepítés előtti lépéseket, például az átviteli sebesség becslését és egy szegmenskulcs kiválasztását.
- Hozzon létre egy Azure Cosmos DB-fiókot MongoDB-fiókhoz.
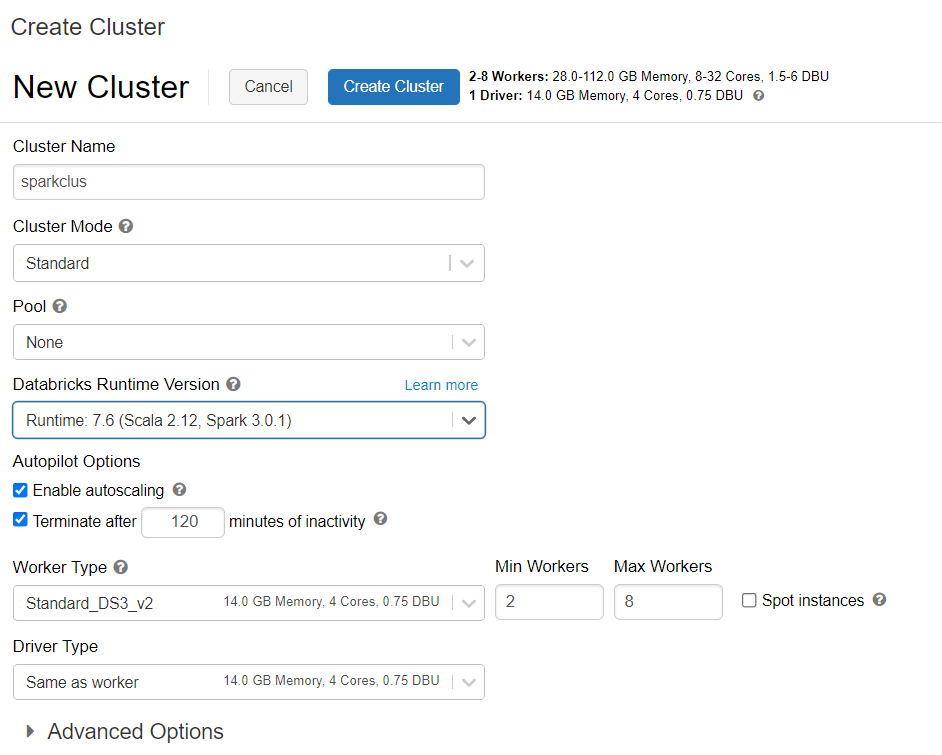
Azure Databricks-fürt kiépítése
Az Azure Databricks-fürt kiépítéséhez kövesse az utasításokat. Javasoljuk, hogy válassza a Databricks 7.6-os verzióját, amely támogatja a Spark 3.0-t.
Függőségek hozzáadása
Adja hozzá a MongoDB Spark-összekötőt a fürthöz, hogy natív MongoDB-hez és Azure Cosmos DB-hez készült MongoDB-végpontokhoz is csatlakozzon. A fürtben válassza a Kódtárak>új>maven telepítése lehetőséget, majd adja hozzá org.mongodb.spark:mongo-spark-connector_2.12:3.0.1 a Maven koordinátáit.
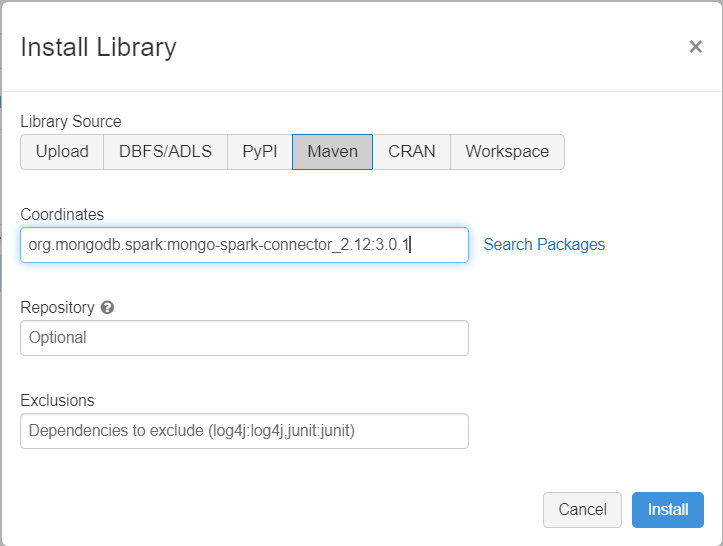
Válassza a Telepítés lehetőséget, majd indítsa újra a fürtöt, amikor a telepítés befejeződött.
Feljegyzés
A MongoDB Connector for Spark-kódtár telepítése után indítsa újra a Databricks-fürtöt.
Ezután létrehozhat egy Scala- vagy Python-jegyzetfüzetet a migráláshoz.
Scala-jegyzetfüzet létrehozása migráláshoz
Scala-jegyzetfüzet létrehozása a Databricksben. A következő kód futtatása előtt mindenképpen adja meg a megfelelő értékeket a változókhoz:
import com.mongodb.spark._
import com.mongodb.spark.config._
import org.apache.spark._
import org.apache.spark.sql._
var sourceConnectionString = "mongodb://<USERNAME>:<PASSWORD>@<HOST>:<PORT>/<AUTHDB>"
var sourceDb = "<DB NAME>"
var sourceCollection = "<COLLECTIONNAME>"
var targetConnectionString = "mongodb://<ACCOUNTNAME>:<PASSWORD>@<ACCOUNTNAME>.mongo.cosmos.azure.com:10255/?ssl=true&replicaSet=globaldb&retrywrites=false&maxIdleTimeMS=120000&appName=@<ACCOUNTNAME>@"
var targetDb = "<DB NAME>"
var targetCollection = "<COLLECTIONNAME>"
val readConfig = ReadConfig(Map(
"spark.mongodb.input.uri" -> sourceConnectionString,
"spark.mongodb.input.database" -> sourceDb,
"spark.mongodb.input.collection" -> sourceCollection,
))
val writeConfig = WriteConfig(Map(
"spark.mongodb.output.uri" -> targetConnectionString,
"spark.mongodb.output.database" -> targetDb,
"spark.mongodb.output.collection" -> targetCollection,
"spark.mongodb.output.maxBatchSize" -> "8000"
))
val sparkSession = SparkSession
.builder()
.appName("Data transfer using spark")
.getOrCreate()
val customRdd = MongoSpark.load(sparkSession, readConfig)
MongoSpark.save(customRdd, writeConfig)
Python-jegyzetfüzet létrehozása migráláshoz
Python-jegyzetfüzet létrehozása a Databricksben. A következő kód futtatása előtt mindenképpen adja meg a megfelelő értékeket a változókhoz:
from pyspark.sql import SparkSession
sourceConnectionString = "mongodb://<USERNAME>:<PASSWORD>@<HOST>:<PORT>/<AUTHDB>"
sourceDb = "<DB NAME>"
sourceCollection = "<COLLECTIONNAME>"
targetConnectionString = "mongodb://<ACCOUNTNAME>:<PASSWORD>@<ACCOUNTNAME>.mongo.cosmos.azure.com:10255/?ssl=true&replicaSet=globaldb&retrywrites=false&maxIdleTimeMS=120000&appName=@<ACCOUNTNAME>@"
targetDb = "<DB NAME>"
targetCollection = "<COLLECTIONNAME>"
my_spark = SparkSession \
.builder \
.appName("myApp") \
.getOrCreate()
df = my_spark.read.format("com.mongodb.spark.sql.DefaultSource").option("uri", sourceConnectionString).option("database", sourceDb).option("collection", sourceCollection).load()
df.write.format("mongo").mode("append").option("uri", targetConnectionString).option("maxBatchSize",2500).option("database", targetDb).option("collection", targetCollection).save()
Az áttelepítési teljesítmény optimalizálása
Az áttelepítési teljesítmény az alábbi konfigurációkkal módosítható:
A Spark-fürtben lévő feldolgozók és magok száma: A további feldolgozók több számítási szegmenst jelentenek a feladatok végrehajtásához.
maxBatchSize: Az
maxBatchSizeérték szabályozza, hogy a rendszer milyen sebességgel mentse az adatokat a cél Azure Cosmos DB-gyűjteménybe. Ha azonban a maxBatchSize túl magas a gyűjtemény átviteli sebességéhez, az sebességkorlátozási hibákat okozhat.A Spark-fürt végrehajtóinak számától függően módosítania kell a feldolgozók számát és a maxBatchSize értéket, esetleg az egyes dokumentumok méretét (és ezért a ru-költségeket) és a célgyűjtemény átviteli sebességkorlátjait.
Tipp.
maxBatchSize = Gyűjtemény átviteli sebessége / ( 1 dokumentum ru költsége * Spark-feldolgozók száma * processzormagok száma feldolgozónként )
MongoDB Spark particionáló és partitionKey: A használt alapértelmezett particionáló a MongoDefaultPartitioner, az alapértelmezett partitionKey pedig _id. A particionáló módosítható úgy, hogy értéket
MongoSamplePartitionerrendel a bemeneti konfigurációs tulajdonsághozspark.mongodb.input.partitioner. Hasonlóképpen a partitionKey is módosítható a megfelelő mezőnévnek a bemeneti konfigurációs tulajdonsághozspark.mongodb.input.partitioner.partitionKeyvaló hozzárendelésével. A jobb particionáláskulcs segíthet elkerülni az adateltérést (sok rekord íródik ugyanahhoz a szegmenskulcs-értékhez).Indexek letiltása az adatátvitel során: Nagy mennyiségű adatmigrálás esetén fontolja meg az indexek letiltását, különösen a helyettesítő karakterek indexét a célgyűjteményben. Az indexek növelik az egyes dokumentumok írási költségét. Ezeknek a kérelemegységeknek a felszabadítása segíthet az adatátviteli sebesség javításában. Az adatok áttelepítése után engedélyezheti az indexeket.
Hibaelhárítás
Időtúllépési hiba (50-ös hibakód)
50 hibakód jelenhet meg az Azure Cosmos DB for MongoDB-adatbázison végzett műveletekhez. A következő forgatókönyvek időtúllépési hibákat okozhatnak:
- Az adatbázishoz lefoglalt átviteli sebesség alacsony: Győződjön meg arról, hogy a célgyűjteményhez elegendő átviteli sebesség van hozzárendelve.
- Túlzott adateltérés nagy adatmennyiséggel. Ha nagy mennyiségű adatot szeretne áttelepíteni egy adott táblába, de jelentős eltérés van az adatokban, akkor is előfordulhat, hogy a sebességkorlátozás akkor is tapasztalható, ha több kérelemegység van kiépítve a táblában. A kérelemegységek egyenlően vannak elosztva a fizikai partíciók között, és a nagy adateltérés szűk keresztmetszetet okozhat az egyetlen szegmensre irányuló kérések számára. Az adateltérés nagy számú rekordot jelent ugyanahhoz a szegmenskulcs-értékhez.
Sebességkorlátozás (hibakód: 16500)
Előfordulhat, hogy egy 16500-ás hibakód jelenik meg az Azure Cosmos DB for MongoDB-adatbázison végzett műveletekhez. Ezek sebességkorlátozó hibák, és a régebbi fiókokban vagy fiókokban figyelhetők meg, ahol a kiszolgálóoldali újrapróbálkozási funkció le van tiltva.
- Kiszolgálóoldali újrapróbálkozás engedélyezése: Engedélyezze a kiszolgálóoldali újrapróbálkozási (SSR) funkciót, és hagyja, hogy a kiszolgáló automatikusan újrapróbálkozza a korlátozott sebességű műveleteket.
Áttelepítés utáni optimalizálás
Az adatok migrálása után csatlakozhat az Azure Cosmos DB-hez, és kezelheti az adatokat. A migrálást követően további lépéseket is követhet, például optimalizálhatja az indexelési szabályzatot, frissítheti az alapértelmezett konzisztenciaszintet, vagy konfigurálhatja az Azure Cosmos DB-fiók globális terjesztését. További információkért tekintse meg a migrálás utáni optimalizálási cikket.
További erőforrások
- Kapacitástervezést szeretne végezni az Azure Cosmos DB-be való migráláshoz?
- Ha csak annyit tud, hogy hány virtuális mag és kiszolgáló található a meglévő adatbázisfürtben, olvassa el a kérelemegységek becslését virtuális magok vagy vCPU-k használatával
- Ha ismeri az aktuális adatbázis számítási feladataira vonatkozó tipikus kérési arányokat, olvassa el a kérelemegységek becslését az Azure Cosmos DB kapacitástervezővel
Következő lépések
Visszajelzés
Hamarosan elérhető: 2024-ben fokozatosan kivezetjük a GitHub-problémákat a tartalom visszajelzési mechanizmusaként, és lecseréljük egy új visszajelzési rendszerre. További információ: https://aka.ms/ContentUserFeedback.
Visszajelzés küldése és megtekintése a következőhöz: