Megjegyzés
Az oldalhoz való hozzáféréshez engedély szükséges. Megpróbálhat bejelentkezni vagy módosítani a címtárat.
Az oldalhoz való hozzáféréshez engedély szükséges. Megpróbálhatja módosítani a címtárat.
Fontos
Az Azure Cosmos DB for PostgreSQL már nem támogatott új projektek esetén. Ne használja ezt a szolgáltatást új projektekhez. Ehelyett használja az alábbi két szolgáltatás egyikét:
Az Azure Cosmos DB for NoSQL használata nagy léptékű forgatókönyvekhez tervezett elosztott adatbázis-megoldáshoz 99,999% rendelkezésre állási szolgáltatásiszint-szerződéssel (SLA), azonnali automatikus skálázással és automatikus feladatátvétellel több régióban.
Használja az Azure Database For PostgreSQL Rugalmas fürtök funkcióját a megosztott PostgreSQL-hez a nyílt forráskódú Citus-bővítmény használatával.
A közös elhelyezés azt jelenti, hogy a kapcsolódó információkat ugyanazon csomópontokon tároljuk. A lekérdezések gyorsak lehetnek, ha az összes szükséges adat elérhető hálózati forgalom nélkül. A kapcsolódó adatok különböző csomópontokon való áthelyezése lehetővé teszi, hogy a lekérdezések hatékonyan fussanak párhuzamosan az egyes csomópontokon.
Hash-disztribúciójú táblák adatelhelyezése
Az Azure Cosmos DB for PostgreSQL-ben egy sor akkor tárolódik egy szegmensben, ha a terjesztési oszlopban lévő érték kivonata a szegmens kivonattartományába esik. Az azonos hash tartományú szegmensek mindig ugyanazon a csomóponton helyezkednek el. Az egyenlő eloszlási oszlopértékekkel rendelkező sorok mindig ugyanazon a csomóponton találhatók a táblák között. A kivonatelosztott táblák fogalmát soralapú horizontális skálázásnak is nevezik. Sémaalapú felosztás esetén az elosztott sémán belüli táblák mindig együtt helyezkednek el.
Az ábra azokat a töredékeket mutatja, amelyek azonos kivonattartományba esnek, és ugyanazon a csomóponton helyezkednek el mind az események, mind az oldalak szegmensei számára.
Gyakorlati példa a közös elhelyezésre
Vegye figyelembe a következő táblázatokat, amelyek egy több-bérlős webelemzési SaaS részét képezhetik:
CREATE TABLE event (
tenant_id int,
event_id bigint,
page_id int,
payload jsonb,
primary key (tenant_id, event_id)
);
CREATE TABLE page (
tenant_id int,
page_id int,
path text,
primary key (tenant_id, page_id)
);
Most olyan lekérdezéseket szeretnénk megválaszolni, amelyeket egy ügyféloldali irányítópult adhat ki. Egy példa lekérdezés: "Adja vissza az elmúlt hét látogatásainak számát a 'blog' kezdetű összes oldal esetében a hatos számú lakásban."
Ha az adataink egyetlen PostgreSQL-kiszolgálón találhatóak, egyszerűen kifejezhetjük a lekérdezésünket az SQL által kínált relációs műveletek gazdag készletével:
SELECT page_id, count(event_id)
FROM
page
LEFT JOIN (
SELECT * FROM event
WHERE (payload->>'time')::timestamptz >= now() - interval '1 week'
) recent
USING (tenant_id, page_id)
WHERE tenant_id = 6 AND path LIKE '/blog%'
GROUP BY page_id;
Mindaddig, amíg a lekérdezés munkakészlete elfér a memóriában, egy egykiszolgálós tábla megfelelő megoldás. Tekintsük át az adatmodell és az Azure Cosmos DB for PostgreSQL skálázásának lehetőségeit.
Táblák elosztása azonosító szerint
Az egykiszolgálós lekérdezések a bérlők számának növekedésével és az egyes bérlők számára tárolt adatok növekedésével kezdenek lelassulni. Amikor a munkakészlet már nem fér bele a memóriába, a CPU szűk keresztmetszetté válik.
Ebben az esetben több csomóponton is skálázhatjuk az adatokat az Azure Cosmos DB for PostgreSQL használatával. Amikor a szétosztás mellett döntünk, az első és legfontosabb döntés az elosztási oszlop kiválasztása. Kezdjük azzal a naiv választással, hogy az event_id-t használjuk az eseménytáblához, és a page_id-t a page táblához:
-- naively use event_id and page_id as distribution columns
SELECT create_distributed_table('event', 'event_id');
SELECT create_distributed_table('page', 'page_id');
Ha az adatok különböző feldolgozók között oszlanak el, nem tudunk olyan illesztéseket végrehajtani, mint egy PostgreSQL-csomóponton. Ehelyett két lekérdezést kell kiadnunk:
-- (Q1) get the relevant page_ids
SELECT page_id FROM page WHERE path LIKE '/blog%' AND tenant_id = 6;
-- (Q2) get the counts
SELECT page_id, count(*) AS count
FROM event
WHERE page_id IN (/*…page IDs from first query…*/)
AND tenant_id = 6
AND (payload->>'time')::date >= now() - interval '1 week'
GROUP BY page_id ORDER BY count DESC LIMIT 10;
Ezt követően az alkalmazásnak össze kell kapcsolnia a két lépés eredményeit.
A lekérdezések futtatásának a csomópontok között szétszórt szegmensekben lévő adatokkal kell konzultálnia.
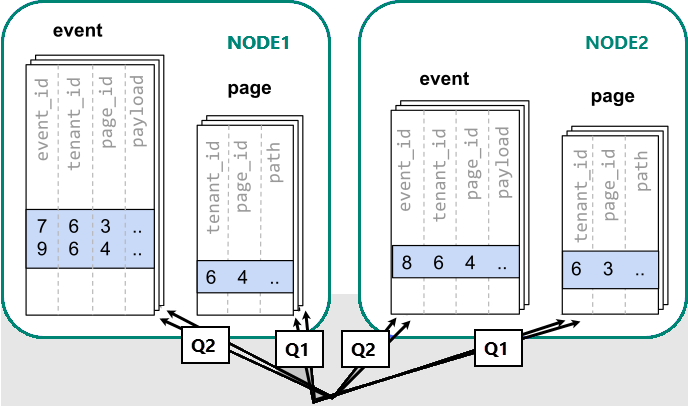
Ebben az esetben az adatterjesztés jelentős hátrányokat okoz:
- Az egyes szegmensek lekérdezésének és több lekérdezés futtatásának többletterhelése.
- Az 1. lekérdezés többletterhelése, amely sok sort ad vissza az ügyfélnek.
- A 2. negyedév nagy lesz.
- A lekérdezések több lépésben történő írásához az alkalmazás módosításaira van szükség.
Az adatok eloszlanak, így a lekérdezések párhuzamosak lehetnek. Ez csak akkor előnyös, ha a lekérdezés által végzett munka mennyisége lényegesen nagyobb, mint a számos szegmens lekérdezésének többletterhelése.
Táblák elosztása bérlő szerint
Az Azure Cosmos DB for PostgreSQL-ben az azonos terjesztési oszlopértékkel rendelkező sorok garantáltan ugyanazon a csomóponton találhatók. Újrakezdve létrehozhatjuk a tábláinkat a tenant_id-t használva terjesztési oszlopként.
-- co-locate tables by using a common distribution column
SELECT create_distributed_table('event', 'tenant_id');
SELECT create_distributed_table('page', 'tenant_id', colocate_with => 'event');
Az Azure Cosmos DB for PostgreSQL mostantól módosítás nélkül megválaszolhatja az eredeti egykiszolgálós lekérdezést (1. negyedév):
SELECT page_id, count(event_id)
FROM
page
LEFT JOIN (
SELECT * FROM event
WHERE (payload->>'time')::timestamptz >= now() - interval '1 week'
) recent
USING (tenant_id, page_id)
WHERE tenant_id = 6 AND path LIKE '/blog%'
GROUP BY page_id;
A tenant_id szűrése és csatlakoztatása miatt az Azure Cosmos DB for PostgreSQL tudja, hogy a teljes lekérdezés megválaszolható az adott bérlő adatait tartalmazó megosztott szegmensek készletével. Egyetlen PostgreSQL-csomópont egyetlen lépésben válaszolhat a lekérdezésre.
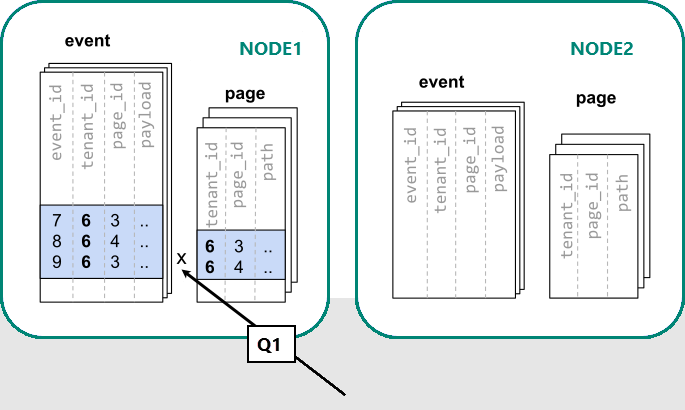
Bizonyos esetekben a lekérdezéseket és a táblasémákat úgy kell módosítani, hogy a bérlőazonosító egyedi korlátozásokban és csatlakozási feltételekben szerepeljenek. Ez a változás általában egyszerű.
Következő lépések
- Tekintse meg, hogyan van a bérlői adat elhelyezve a több-bérlős oktatóanyagban.