Adatok betöltése az Apache Kafkából az Azure Data Explorer
Az Apache Kafka egy elosztott streamelési platform valós idejű streamelési adatfolyamok létrehozásához, amelyek megbízhatóan mozgatják az adatokat a rendszerek vagy alkalmazások között. A Kafka Connect egy olyan eszköz, amely skálázható és megbízható adatstreamelést biztosít az Apache Kafka és más adatrendszerek között. A Kusto Kafka Sink a Kafka összekötőjeként szolgál, és nem igényel kódot. Töltse le a fogadó összekötő jar-t a Git-adattárból vagy a Confluent Connector Hubról.
Ez a cikk bemutatja, hogyan lehet adatokat betöltésre a Kafkával egy önálló Docker-beállítással a Kafka-fürt és a Kafka-összekötőfürt beállításának egyszerűsítéséhez.
További információkért lásd az összekötő Git-adattárát és a verzióspecifikusakat.
Előfeltételek
- Azure-előfizetés. Hozzon létre egy ingyenes Azure-fiókot.
- Egy Azure Data Explorer-fürtöt és adatbázist az alapértelmezett gyorsítótár- és adatmegőrzési szabályzatokkal, vagy egy KQL-adatbázist a Microsoft Fabricben.
- Azure parancssori felület (CLI).
- Docker és Docker Compose.
Microsoft Entra szolgáltatásnév létrehozása
A Microsoft Entra szolgáltatásnév a Azure Portal vagy programozott módon hozható létre, az alábbi példához hasonlóan.
Ez a szolgáltatásnév lesz az összekötő által használt identitás, amellyel adatokat írhat a táblában a Kusto-ban. Később engedélyeket ad a szolgáltatásnévnek a Kusto-erőforrások eléréséhez.
Jelentkezzen be az Azure-előfizetésbe az Azure CLI-vel. Ezután hitelesítés a böngészőben.
az loginVálassza ki az előfizetést az egyszerű szolgáltatás üzemeltetéséhez. Erre a lépésre akkor van szükség, ha több előfizetéssel rendelkezik.
az account set --subscription YOUR_SUBSCRIPTION_GUIDHozza létre a szolgáltatásnevet. Ebben a példában a szolgáltatásnév neve
my-service-principal.az ad sp create-for-rbac -n "my-service-principal" --role Contributor --scopes /subscriptions/{SubID}A visszaadott JSON-adatokból másolja ki a ,
passworda éstenantaappIdértéket későbbi használatra.{ "appId": "1234abcd-e5f6-g7h8-i9j0-1234kl5678mn", "displayName": "my-service-principal", "name": "my-service-principal", "password": "1234abcd-e5f6-g7h8-i9j0-1234kl5678mn", "tenant": "1234abcd-e5f6-g7h8-i9j0-1234kl5678mn" }
Létrehozta Microsoft Entra alkalmazást és szolgáltatásnevet.
Céltábla létrehozása
A lekérdezési környezetből hozzon létre egy nevű
Stormstáblát a következő paranccsal:.create table Storms (StartTime: datetime, EndTime: datetime, EventId: int, State: string, EventType: string, Source: string)Hozza létre a megfelelő táblaleképezést
Storms_CSV_Mappingaz betöltött adatokhoz a következő paranccsal:.create table Storms ingestion csv mapping 'Storms_CSV_Mapping' '[{"Name":"StartTime","datatype":"datetime","Ordinal":0}, {"Name":"EndTime","datatype":"datetime","Ordinal":1},{"Name":"EventId","datatype":"int","Ordinal":2},{"Name":"State","datatype":"string","Ordinal":3},{"Name":"EventType","datatype":"string","Ordinal":4},{"Name":"Source","datatype":"string","Ordinal":5}]'Hozzon létre egy betöltési kötegelési szabályzatot a táblában a konfigurálható várólista-betöltési késés érdekében.
Tipp
A betöltési kötegelési szabályzat egy teljesítményoptimalizáló, és három paramétert tartalmaz. Az első feltétel teljesülése aktiválja az Azure Data Explorer táblába való betöltést.
.alter table Storms policy ingestionbatching @'{"MaximumBatchingTimeSpan":"00:00:15", "MaximumNumberOfItems": 100, "MaximumRawDataSizeMB": 300}'Az Microsoft Entra szolgáltatásnév létrehozása szolgáltatásnévvel engedélyt adhat az adatbázis használatához.
.add database YOUR_DATABASE_NAME admins ('aadapp=YOUR_APP_ID;YOUR_TENANT_ID') 'AAD App'
A tesztkörnyezet futtatása
A következő tesztkörnyezet lehetővé teszi az adatok létrehozásának megkezdését, a Kafka-összekötő beállítását és az adatok azure Data Explorer az összekötővel való streamelésének élményét. Ezután megtekintheti a betöltött adatokat.
A git-adattár klónozása
Klónozza a labor git-adattárát.
Hozzon létre egy helyi könyvtárat a számítógépen.
mkdir ~/kafka-kusto-hol cd ~/kafka-kusto-holKlónozza az adattárat.
cd ~/kafka-kusto-hol git clone https://github.com/Azure/azure-kusto-labs cd azure-kusto-labs/kafka-integration/dockerized-quickstart
A klónozott adattár tartalma
Futtassa a következő parancsot a klónozott adattár tartalmának listázásához:
cd ~/kafka-kusto-hol/azure-kusto-labs/kafka-integration/dockerized-quickstart
tree
A keresés eredménye a következő:
├── README.md
├── adx-query.png
├── adx-sink-config.json
├── connector
│ └── Dockerfile
├── docker-compose.yaml
└── storm-events-producer
├── Dockerfile
├── StormEvents.csv
├── go.mod
├── go.sum
├── kafka
│ └── kafka.go
└── main.go
Tekintse át a klónozott adattárban lévő fájlokat
Az alábbi szakaszok a fenti fájlfában található fájlok fontos részeit ismertetik.
adx-sink-config.json
Ez a fájl tartalmazza a Kusto-fogadó tulajdonságokat tartalmazó fájlt, ahol frissíteni fogja a konfiguráció részleteit:
{
"name": "storm",
"config": {
"connector.class": "com.microsoft.azure.kusto.kafka.connect.sink.KustoSinkConnector",
"flush.size.bytes": 10000,
"flush.interval.ms": 10000,
"tasks.max": 1,
"topics": "storm-events",
"kusto.tables.topics.mapping": "[{'topic': 'storm-events','db': '<enter database name>', 'table': 'Storms','format': 'csv', 'mapping':'Storms_CSV_Mapping'}]",
"aad.auth.authority": "<enter tenant ID>",
"aad.auth.appid": "<enter application ID>",
"aad.auth.appkey": "<enter client secret>",
"kusto.ingestion.url": "https://ingest-<name of cluster>.<region>.kusto.windows.net",
"kusto.query.url": "https://<name of cluster>.<region>.kusto.windows.net",
"key.converter": "org.apache.kafka.connect.storage.StringConverter",
"value.converter": "org.apache.kafka.connect.storage.StringConverter"
}
}
Cserélje le a következő attribútumok értékeit az Azure Data Explorer beállításának megfelelően: aad.auth.authority, aad.auth.appid, , aad.auth.appkeykusto.tables.topics.mapping (az adatbázis neve), kusto.ingestion.urlés kusto.query.url.
Összekötő – Dockerfile
Ez a fájl rendelkezik az összekötőpéldány docker-lemezképének létrehozásához szükséges parancsokkal. Tartalmazza az összekötő letöltését a Git-adattár kiadási könyvtárából.
Storm-events-producer könyvtár
Ez a könyvtár egy Go program, amely beolvassa a helyi "StormEvents.csv" fájlt, és közzéteszi az adatokat egy Kafka-témakörben.
docker-compose.yaml
version: "2"
services:
zookeeper:
image: debezium/zookeeper:1.2
ports:
- 2181:2181
kafka:
image: debezium/kafka:1.2
ports:
- 9092:9092
links:
- zookeeper
depends_on:
- zookeeper
environment:
- ZOOKEEPER_CONNECT=zookeeper:2181
- KAFKA_ADVERTISED_LISTENERS=PLAINTEXT://localhost:9092
kusto-connect:
build:
context: ./connector
args:
KUSTO_KAFKA_SINK_VERSION: 1.0.1
ports:
- 8083:8083
links:
- kafka
depends_on:
- kafka
environment:
- BOOTSTRAP_SERVERS=kafka:9092
- GROUP_ID=adx
- CONFIG_STORAGE_TOPIC=my_connect_configs
- OFFSET_STORAGE_TOPIC=my_connect_offsets
- STATUS_STORAGE_TOPIC=my_connect_statuses
events-producer:
build:
context: ./storm-events-producer
links:
- kafka
depends_on:
- kafka
environment:
- KAFKA_BOOTSTRAP_SERVER=kafka:9092
- KAFKA_TOPIC=storm-events
- SOURCE_FILE=StormEvents.csv
A tárolók indítása
Egy terminálban indítsa el a tárolókat:
docker-compose upAz előállító alkalmazás elkezd eseményeket küldeni a
storm-eventstémakörbe. A következő naplókhoz hasonló naplóknak kell megjelennie:.... events-producer_1 | sent message to partition 0 offset 0 events-producer_1 | event 2007-01-01 00:00:00.0000000,2007-01-01 00:00:00.0000000,13208,NORTH CAROLINA,Thunderstorm Wind,Public events-producer_1 | events-producer_1 | sent message to partition 0 offset 1 events-producer_1 | event 2007-01-01 00:00:00.0000000,2007-01-01 05:00:00.0000000,23358,WISCONSIN,Winter Storm,COOP Observer ....A naplók ellenőrzéséhez futtassa a következő parancsot egy külön terminálban:
docker-compose logs -f | grep kusto-connect
Az összekötő indítása
Az összekötő elindításához használjon Kafka Connect REST-hívást.
Egy külön terminálban indítsa el a fogadó feladatot a következő paranccsal:
curl -X POST -H "Content-Type: application/json" --data @adx-sink-config.json http://localhost:8083/connectorsAz állapot ellenőrzéséhez futtassa a következő parancsot egy külön terminálban:
curl http://localhost:8083/connectors/storm/status
Az összekötő megkezdi a betöltési folyamatok várólistára helyezését az Azure Data Explorer.
Megjegyzés
Ha naplóösszekötő-problémákat tapasztal, hozzon létre egy problémát.
Adatok lekérdezése és áttekintése
Adatbetöltés megerősítése
Várjon, amíg az adatok megérkeznek a
Stormstáblába. Az adatok átvitelének ellenőrzéséhez ellenőrizze a sorok számát:Storms | countEllenőrizze, hogy nincsenek-e hibák a betöltési folyamatban:
.show ingestion failuresAz adatok megtekintése után próbálkozzon néhány lekérdezéssel.
Adatok lekérdezése
Az összes rekord megtekintéséhez futtassa a következő lekérdezést:
StormsAdott adatok használata
whereésprojectszűrése:Storms | where EventType == 'Drought' and State == 'TEXAS' | project StartTime, EndTime, Source, EventIdHasználja az operátort
summarize:Storms | summarize event_count=count() by State | where event_count > 10 | project State, event_count | render columnchart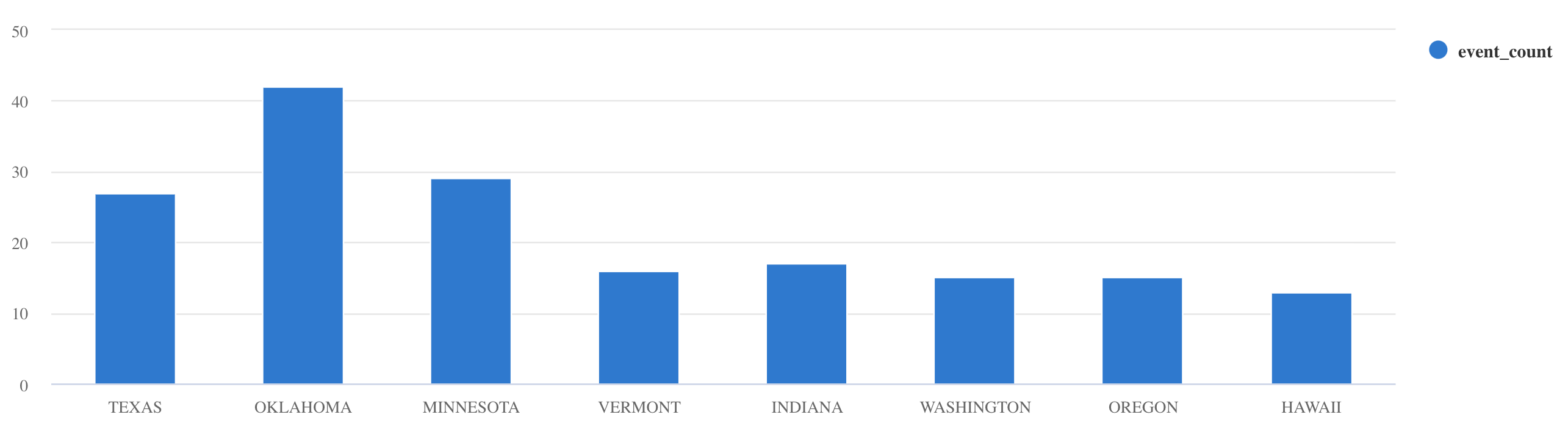
További lekérdezési példákért és útmutatásért lásd: Lekérdezések írása a KQL-ben és Kusto lekérdezésnyelv dokumentáció.
Alaphelyzetbe állítás
Az alaphelyzetbe állításhoz hajtsa végre a következő lépéseket:
- A tárolók leállítása (
docker-compose down -v) - Törlés (
drop table Storms) - A tábla újbóli létrehozása
Storms - Táblaleképezés újbóli létrehozása
- Tárolók újraindítása (
docker-compose up)
Az erőforrások eltávolítása
Az Azure Data Explorer-erőforrások törléséhez használja az az cluster delete vagy az Kusto database delete parancsot:
az kusto cluster delete -n <cluster name> -g <resource group name>
az kusto database delete -n <database name> --cluster-name <cluster name> -g <resource group name>
A Kafka Sink-összekötő finomhangolása
Hangolja a Kafka Sink-összekötőt a betöltési kötegelési szabályzattal való együttműködéshez:
- Hangolja a Kafka Fogadó
flush.size.bytesméretkorlátját 1 MB-tól kezdve, és növelje a 10 MB-os vagy 100 MB-os növekményekkel. - A Kafka Sink használatakor az adatok kétszer lesznek összesítve. Az összekötő oldalán lévő adatok a kiürítési beállítások szerint, az Azure Data Explorer szolgáltatás oldalán pedig a kötegelési szabályzatnak megfelelően lesznek összesítve. Ha a kötegelési idő túl rövid, és az összekötő és a szolgáltatás nem tud adatokat beszúrni, a kötegelési időt növelni kell. Állítsa be a kötegelési méretet 1 GB-ra, és szükség szerint növelje vagy csökkentse 100 MB-os növekményekkel. Ha például a kiürítési méret 1 MB, és a kötegelési szabályzat mérete 100 MB, miután a Kafka Sink-összekötő összesít egy 100 MB-os köteget, az Azure Data Explorer szolgáltatás betölti a 100 MB-os köteget. Ha a kötegelési szabályzat időtartama 20 másodperc, és a Kafka Sink-összekötő 20 másodperc alatt 50 MB-ot ürít ki – akkor a szolgáltatás betölt egy 50 MB-os köteget.
- Skálázhat példányok és Kafka-partíciók hozzáadásával. Növelje
tasks.maxa partíciók számát. Hozzon létre egy partíciót, ha elegendő adattal rendelkezik a beállítás méreténekflush.size.bytesmegfelelő blob létrehozásához. Ha a blob kisebb, a köteg akkor lesz feldolgozva, amikor eléri az időkorlátot, így a partíció nem kap elég átviteli sebességet. A partíciók nagy száma nagyobb feldolgozási többletterhelést jelent.
Kapcsolódó tartalom
- További információ a Big Data architektúrájáról.
- Megtudhatja, hogyan lehet JSON formátumú mintaadatokat beolvasni az Azure Data Explorer.
- További Kafka-tesztkörnyezetek esetén: