Azure Data Explorer Connector for Apache Spark
Fontos
Ez az összekötő használható a Microsoft Fabric valós idejű elemzéseiben . Használja a cikkben található utasításokat a következő kivételekkel:
- Ha szükséges, hozzon létre adatbázisokat a KQL-adatbázis létrehozása című témakör utasításai alapján.
- Ha szükséges, hozzon létre táblákat az Üres tábla létrehozása című témakörben található utasítások alapján.
- Lekérdezési vagy betöltési URI-k lekérése az URI másolása című témakör utasításai alapján.
- Lekérdezések futtatása KQL-lekérdezéskészletben.
Az Apache Spark egy egységes elemzési motor a nagy léptékű adatfeldolgozáshoz. Az Azure Data Explorer egy gyors, teljes mértékben felügyelt adatelemző szolgáltatás, amellyel valós idejű elemzést végezhet nagy mennyiségű adatfolyamokon.
A Sparkhoz készült Azure Data Explorer-összekötő egy nyílt forráskód projekt, amely bármely Spark-fürtön futtatható. Adatforrást és adatgyűjtőt implementál az adatok Azure-Data Explorer és Spark-fürtök közötti áthelyezéséhez. Az Azure Data Explorer és az Apache Spark használatával gyors és méretezhető alkalmazásokat hozhat létre, amelyek adatvezérelt forgatókönyveket céloznak meg. Ilyen például a gépi tanulás (ML), az extract-transform-load (ETL) és a Log Analytics. Az összekötővel az Azure Data Explorer a standard Spark-forrás- és fogadóműveletek, például az írási, olvasási és írásistream-műveletek érvényes adattárává válik.
Az Azure Data Explorer üzenetsoros betöltéssel vagy streamelési betöltéssel írhat. Az Azure Data Explorer olvasása támogatja az oszlopok metszését és predikátumleküldését, amely szűri az Adatokat az Azure Data Explorer, csökkentve az átvitt adatok mennyiségét.
Megjegyzés
Az Azure Data Explorer-hez készült Synapse Spark-összekötővel kapcsolatos további információkért lásd: Csatlakozás az Azure-Data Explorer az Apache Spark használatával Azure Synapse Analyticshez.
Ez a témakör azt ismerteti, hogyan telepítheti és konfigurálhatja az Azure Data Explorer Spark-összekötőt, és hogyan helyezhet át adatokat az Azure Data Explorer és az Apache Spark-fürtök között.
Megjegyzés
Bár az alábbi példák egy Azure Databricks Spark-fürtre vonatkoznak, az Azure Data Explorer Spark-összekötő nem vesz közvetlen függőségeket a Databricks-hez vagy bármely más Spark-disztribúcióhoz.
Előfeltételek
- Azure-előfizetés. Hozzon létre egy ingyenes Azure-fiókot.
- Egy Azure-Data Explorer-fürt és -adatbázis. Hozzon létre egy fürtöt és egy adatbázist.
- Spark-fürt
- Telepítse az Azure Data Explorer összekötőtárat:
- Előre elkészített kódtárak a Spark 2.4+Scala 2.11 vagy a Spark 3+scala 2.12-hez
- Maven-adattár
- Maven 3.x telepítve
Tipp
A Spark 2.3.x-verziók szintén támogatottak, de előfordulhat, hogy pom.xml függőségek bizonyos módosításait igénylik.
A Spark-összekötő létrehozása
A 2.3.0-s verziótól kezdődően a spark-kusto-connector helyett új összetevő-azonosítókat vezetünk be: kusto-spark_3.0_2.12 a Spark 3.x és a Scala 2.12 és a kusto-spark_2.4_2.11 a Spark 2.4.x és a scala 2.11 célzására.
Megjegyzés
A 2.5.1-es verzió előtti verziók már nem működnek meglévő táblába való betöltéshez, frissítsen egy későbbi verzióra. Ez a lépés nem kötelező. Ha előre elkészített kódtárakat (például Maven) használ, olvassa el a Spark-fürt beállítása című témakört.
Buildelési előfeltételek
Ha nem használ előre elkészített kódtárakat, telepítenie kell a függőségekben felsorolt kódtárakat, beleértve a következő Kusto Java SDK-kódtárakat . A telepíteni kívánt verzió megkereséséhez tekintse meg a megfelelő kiadás pom-ját:
Tekintse meg ezt a forrást a Spark-összekötő létrehozásához.
A Maven-projektdefiníciókat használó Scala-/Java-alkalmazások esetében kapcsolja össze az alkalmazást a következő összetevővel (a legújabb verzió eltérhet):
<dependency> <groupId>com.microsoft.azure</groupId> <artifactId>kusto-spark_3.0_2.12</artifactId> <version>2.5.1</version> </dependency>
Parancsok összeállítása
Jar buildelése és az összes teszt futtatása:
mvn clean package
A jar létrehozásához futtassa az összes tesztet, és telepítse a jar-t a helyi Maven-adattárba:
mvn clean install
További információt az összekötők használatáról szóló cikkben talál.
Spark-fürt beállítása
Megjegyzés
Javasoljuk, hogy a következő lépések végrehajtásakor használja az Azure Data Explorer Spark-összekötő legújabb kiadását.
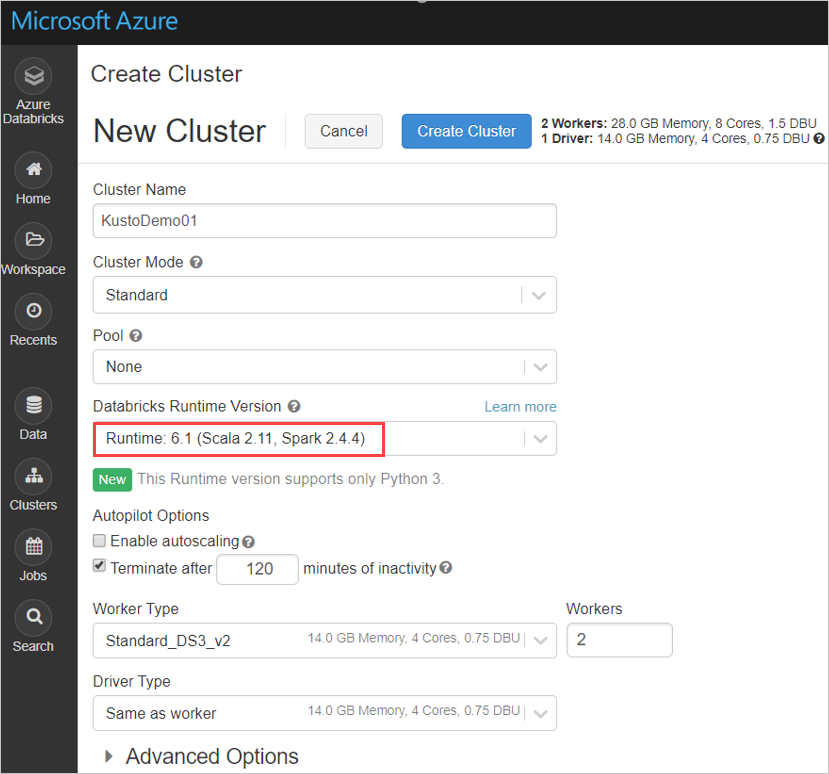
Konfigurálja az alábbi Spark-fürtbeállításokat az Azure Databricks-fürt alapján a Spark 2.4.4 és a Scala 2.11 vagy a Spark 3.0.1 és a Scala 2.12 használatával:
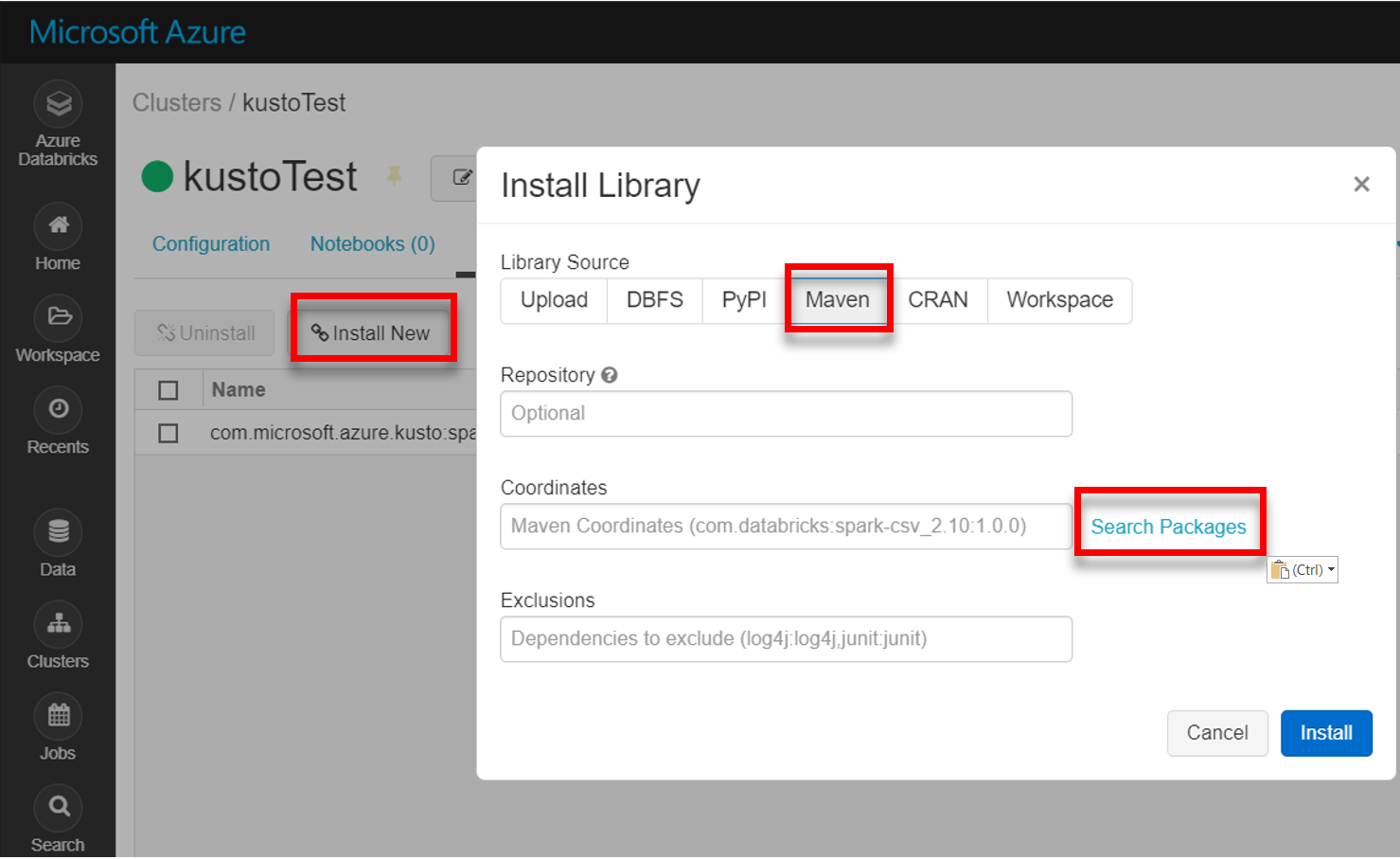
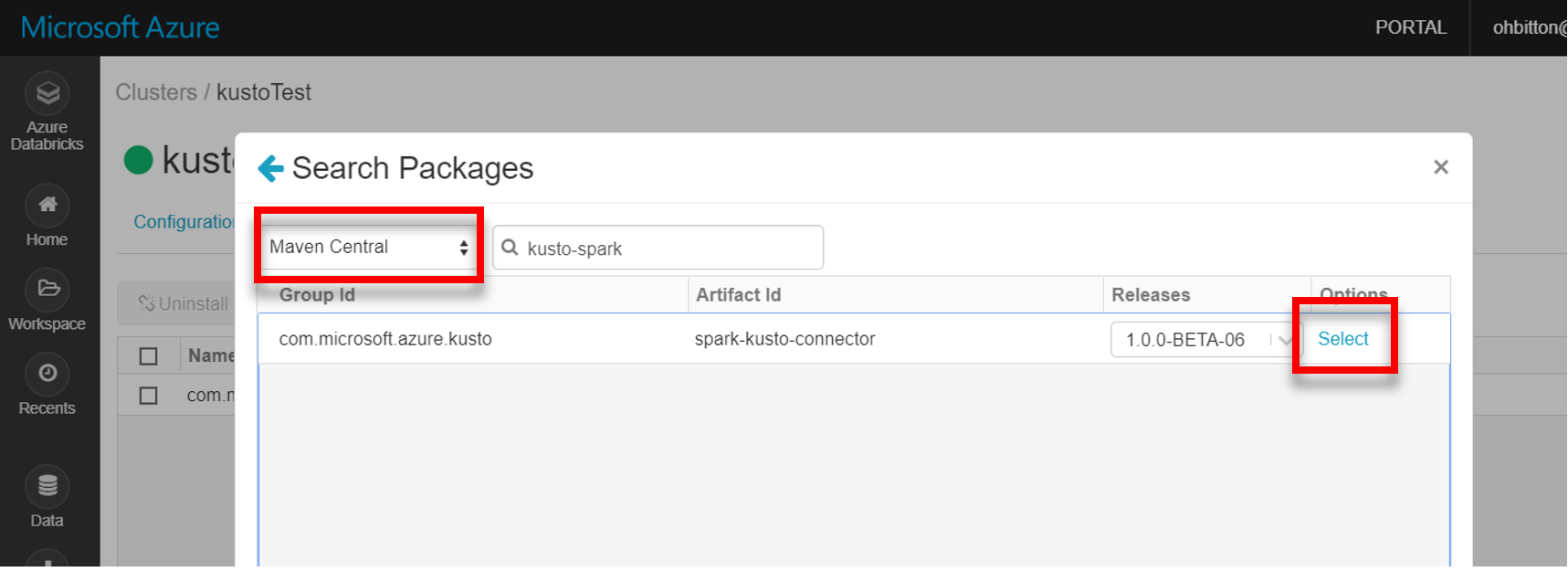
Telepítse a spark-kusto-connector legújabb kódtárát a Mavenből:
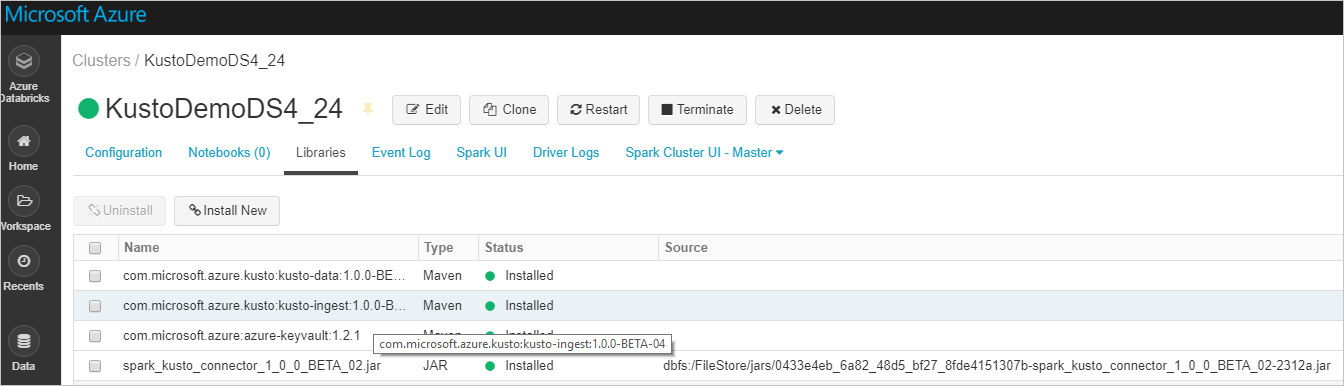
Ellenőrizze, hogy az összes szükséges kódtár telepítve van-e:
JAR-fájllal történő telepítés esetén ellenőrizze, hogy további függőségek lettek-e telepítve:
Hitelesítés
Az Azure Data Explorer Spark-összekötő lehetővé teszi a hitelesítést Microsoft Entra azonosítóval az alábbi módszerek egyikével:
- Egy Microsoft Entra alkalmazás
- Egy Microsoft Entra hozzáférési jogkivonat
- Eszközhitelesítés (nem éles forgatókönyvekhez)
- Azure-Key Vault Az Key Vault erőforrás eléréséhez telepítse az azure-keyvault csomagot, és adja meg az alkalmazás hitelesítő adatait.
alkalmazáshitelesítés Microsoft Entra
Microsoft Entra alkalmazáshitelesítés a legegyszerűbb és leggyakoribb hitelesítési módszer, és az Azure Data Explorer Spark-összekötőhöz ajánlott.
| Tulajdonságok | Beállítási sztring | Description |
|---|---|---|
| KUSTO_AAD_APP_ID | kustoAadAppId | Microsoft Entra alkalmazás (ügyfél) azonosítója. |
| KUSTO_AAD_AUTHORITY_ID | kustoAadAuthorityID | Microsoft Entra hitelesítésszolgáltató. Microsoft Entra címtár (bérlő) azonosítója. Nem kötelező – alapértelmezés szerint microsoft.com. További információ: Microsoft Entra szolgáltató. |
| KUSTO_AAD_APP_SECRET | kustoAadAppSecret | Microsoft Entra ügyfél alkalmazáskulcsát. |
Megjegyzés
A régebbi API-verziók (kevesebb mint 2.0.0) a következő elnevezéssel rendelkeznek: "kustoAAADClientID", "kustoClientAAADClientPassword", "kustoAADAuthorityID"
Azure Data Explorer jogosultságok
Adjon meg a következő jogosultságokat egy Azure Data Explorer-fürtön:
- Olvasáshoz (adatforráshoz) az Microsoft Entra identitásnak megtekintő jogosultságokkal kell rendelkeznie a céladatbázison, vagy rendszergazdai jogosultságokkal kell rendelkeznie a céltáblán.
- Íráshoz (adatgyűjtőhöz) a Microsoft Entra identitásnak betöltési jogosultságokkal kell rendelkeznie a céladatbázison. Új táblák létrehozásához felhasználói jogosultságokkal is rendelkeznie kell a céladatbázisban. Ha a céltábla már létezik, rendszergazdai jogosultságokat kell konfigurálnia a céltáblán.
Az Azure Data Explorer fő szerepköreivel kapcsolatos további információkért lásd: szerepköralapú hozzáférés-vezérlés. A biztonsági szerepkörök kezelésével kapcsolatban lásd: biztonsági szerepkörök kezelése.
Spark-fogadó: írás az Azure Data Explorer
Fogadóparaméterek beállítása:
val KustoSparkTestAppId = dbutils.secrets.get(scope = "KustoDemos", key = "KustoSparkTestAppId") val KustoSparkTestAppKey = dbutils.secrets.get(scope = "KustoDemos", key = "KustoSparkTestAppKey") val appId = KustoSparkTestAppId val appKey = KustoSparkTestAppKey val authorityId = "72f988bf-86f1-41af-91ab-2d7cd011db47" // Optional - defaults to microsoft.com val cluster = "Sparktest.eastus2" val database = "TestDb" val table = "StringAndIntTable"Spark DataFrame írása azure Data Explorer-fürtbe kötegként:
import com.microsoft.kusto.spark.datasink.KustoSinkOptions import org.apache.spark.sql.{SaveMode, SparkSession} df.write .format("com.microsoft.kusto.spark.datasource") .option(KustoSinkOptions.KUSTO_CLUSTER, cluster) .option(KustoSinkOptions.KUSTO_DATABASE, database) .option(KustoSinkOptions.KUSTO_TABLE, "Demo3_spark") .option(KustoSinkOptions.KUSTO_AAD_APP_ID, appId) .option(KustoSinkOptions.KUSTO_AAD_APP_SECRET, appKey) .option(KustoSinkOptions.KUSTO_AAD_AUTHORITY_ID, authorityId) .option(KustoSinkOptions.KUSTO_TABLE_CREATE_OPTIONS, "CreateIfNotExist") .mode(SaveMode.Append) .save()Vagy használja az egyszerűsített szintaxist:
import com.microsoft.kusto.spark.datasink.SparkIngestionProperties import com.microsoft.kusto.spark.sql.extension.SparkExtension._ val sparkIngestionProperties = Some(new SparkIngestionProperties()) // Optional, use None if not needed df.write.kusto(cluster, database, table, conf, sparkIngestionProperties)Streamelési adatok írása:
import org.apache.spark.sql.streaming.Trigger import java.util.concurrent.TimeUnit import java.util.concurrent.TimeUnit import org.apache.spark.sql.streaming.Trigger // Set up a checkpoint and disable codeGen. spark.conf.set("spark.sql.streaming.checkpointLocation", "/FileStore/temp/checkpoint") // Write to a Kusto table from a streaming source val kustoQ = df .writeStream .format("com.microsoft.kusto.spark.datasink.KustoSinkProvider") .options(conf) .trigger(Trigger.ProcessingTime(TimeUnit.SECONDS.toMillis(10))) // Sync this with the ingestionBatching policy of the database .start()
Spark-forrás: olvasás az Azure Data Explorer
Kis mennyiségű adat beolvasásakor adja meg az adat lekérdezést:
import com.microsoft.kusto.spark.datasource.KustoSourceOptions import org.apache.spark.SparkConf import org.apache.spark.sql._ import com.microsoft.azure.kusto.data.ClientRequestProperties val query = s"$table | where (ColB % 1000 == 0) | distinct ColA" val conf: Map[String, String] = Map( KustoSourceOptions.KUSTO_AAD_APP_ID -> appId, KustoSourceOptions.KUSTO_AAD_APP_SECRET -> appKey ) val df = spark.read.format("com.microsoft.kusto.spark.datasource"). options(conf). option(KustoSourceOptions.KUSTO_QUERY, query). option(KustoSourceOptions.KUSTO_DATABASE, database). option(KustoSourceOptions.KUSTO_CLUSTER, cluster). load() // Simplified syntax flavor import com.microsoft.kusto.spark.sql.extension.SparkExtension._ val cpr: Option[ClientRequestProperties] = None // Optional val df2 = spark.read.kusto(cluster, database, query, conf, cpr) display(df2)Nem kötelező: Ha az átmeneti blobtárolót adja meg (és nem az Azure Data Explorer), a blobok a hívó felelőssége alatt jönnek létre. Ez magában foglalja a tároló kiépítését, a hozzáférési kulcsok rotálását és az átmeneti összetevők törlését. A KustoBlobStorageUtils modul segédfüggvényeket tartalmaz a blobok törléséhez a fiók és a tároló koordinátái és a fiók hitelesítő adatai alapján, vagy egy teljes SAS URL-címet írási, olvasási és listázási engedélyekkel. Ha a megfelelő RDD-re már nincs szükség, minden tranzakció egy külön könyvtárban tárolja az átmeneti blobösszetevőket. Ez a könyvtár a Spark-illesztőprogram csomóponton jelentett olvasási tranzakciós információs naplók részeként van rögzítve.
// Use either container/account-key/account name, or container SaS val container = dbutils.secrets.get(scope = "KustoDemos", key = "blobContainer") val storageAccountKey = dbutils.secrets.get(scope = "KustoDemos", key = "blobStorageAccountKey") val storageAccountName = dbutils.secrets.get(scope = "KustoDemos", key = "blobStorageAccountName") // val storageSas = dbutils.secrets.get(scope = "KustoDemos", key = "blobStorageSasUrl")A fenti példában a Key Vault nem érhető el az összekötő felületével; a Databricks titkos kulcsainak használatát egyszerűbben lehet használni.
Olvassa el az Azure Data Explorer.
Ha az átmeneti blobtárolót adja meg, olvassa el az Azure Data Explorer az alábbiak szerint:
val conf3 = Map( KustoSourceOptions.KUSTO_AAD_APP_ID -> appId, KustoSourceOptions.KUSTO_AAD_APP_SECRET -> appKey KustoSourceOptions.KUSTO_BLOB_STORAGE_SAS_URL -> storageSas) val df2 = spark.read.kusto(cluster, database, "ReallyBigTable", conf3) val dfFiltered = df2 .where(df2.col("ColA").startsWith("row-2")) .filter("ColB > 12") .filter("ColB <= 21") .select("ColA") display(dfFiltered)Ha az Azure Data Explorer biztosítja az átmeneti blobtárolót, olvassa el az Azure Data Explorer az alábbiak szerint:
val conf3 = Map( KustoSourceOptions.KUSTO_AAD_CLIENT_ID -> appId, KustoSourceOptions.KUSTO_AAD_CLIENT_PASSWORD -> appKey) val df2 = spark.read.kusto(cluster, database, "ReallyBigTable", conf3) val dfFiltered = df2 .where(df2.col("ColA").startsWith("row-2")) .filter("ColB > 12") .filter("ColB <= 21") .select("ColA") display(dfFiltered)