Vészhelyreállítás
Az egyértelmű vészhelyreállítási minta kritikus fontosságú egy natív felhőbeli adatelemzési platform, például az Azure Databricks esetében. Kritikus fontosságú, hogy az adatcsapatok az Azure Databricks platformot akkor is használhatják, ha egy regionális szolgáltatásszintű felhőszolgáltató kimaradásról van szó, akár egy regionális katasztrófa, például hurrikán vagy földrengés vagy más forrás miatt.
Az Azure Databricks gyakran egy átfogó adat-ökoszisztéma alapvető része, amely számos szolgáltatást tartalmaz, beleértve a felsőbb rétegbeli adatbetöltési szolgáltatásokat (batch/streaming), a natív felhőbeli tárolást, például az ADLS gen2-t (a 2023. március 6. előtt létrehozott munkaterületekhez, az Azure Blob Storage-t), az alárendelt eszközöket és szolgáltatásokat, például az üzletiintelligencia-alkalmazásokat és a vezénylési eszközöket. Egyes használati esetek különösen érzékenyek lehetnek egy regionális szolgáltatáskimaradásra.
Ez a cikk a Databricks platform sikeres régiók közötti vészhelyreállítási megoldásának alapelveit és ajánlott eljárásait ismerteti.
Régión belüli magas rendelkezésre állási garanciák
Bár a témakör többi része a régiók közötti vészhelyreállítás megvalósítására összpontosít, fontos tisztában lenni az Azure Databricks által az egyetlen régión belül nyújtott magas rendelkezésre állási garanciákkal. A régión belüli magas rendelkezésre állási garanciák a következő összetevőkre vonatkoznak:
Az Azure Databricks vezérlősíkjának rendelkezésre állása
- A vezérlősík-szolgáltatások többsége Kubernetes-fürtökön fut, és automatikusan kezeli a virtuális gépek elvesztését az adott AZ-ban.
- A munkaterület adatai a régióban replikált, prémium szintű tárolóval rendelkező adatbázisokban lesznek tárolva. Az adatbázis (egyetlen kiszolgáló) tárolása nem replikálódik különböző AZ-k vagy régiók között. Ha a zónakimaradás hatással van az adatbázis tárolására, az adatbázis helyreállítása egy új példány biztonsági mentésből való létrehozásával történik.
- A DBR-rendszerképek kiszolgálásához használt tárfiókok szintén redundánsak a régión belül, és minden régióban vannak másodlagos tárfiókok, amelyeket az elsődleges leálláskor használnak. Tekintse meg az Azure Databricks-régiókat.
- Általánosságban elmondható, hogy a vezérlősík funkcióit a rendelkezésre állási zóna helyreállítása után ~15 percen belül vissza kell állítani.
A számítási sík rendelkezésre állása
- A munkaterület rendelkezésre állása a vezérlősík rendelkezésre állásától függ (a fent leírtak szerint).
- A DBFS-gyökér adataira nincs hatással, ha a DBFS-gyökér tárfiókja ZRS-sel vagy GZRS-sel van konfigurálva (alapértelmezés szerint GRS).
- A fürtök csomópontjait a rendszer lekéri a különböző rendelkezésre állási zónákból úgy, hogy csomópontokat kér le az Azure számítási szolgáltatótól (a fennmaradó zónákban elegendő kapacitást feltételezve a kérés teljesítéséhez). Ha egy csomópont elveszik, a fürtkezelő cserecsomópontokat kér az Azure számítási szolgáltatótól, amely lekéri őket az elérhető AZ-ekből. Az egyetlen kivétel az, ha az illesztőprogram-csomópont elveszik. Ebben az esetben a feladat vagy a fürtkezelő újraindítja őket.
Vészhelyreállítás áttekintése
A vészhelyreállítás olyan szabályzatokat, eszközöket és eljárásokat foglal magában, amelyek lehetővé teszik a létfontosságú technológiai infrastruktúra és rendszerek helyreállítását vagy folytatását természetes vagy ember által okozott katasztrófákat követően. Az Azure-hoz hasonló nagy felhőszolgáltatás számos ügyfelet kiszolgál, és beépített biztonsági őrökkel rendelkezik egyetlen hiba ellen. A régió például különböző energiaforrásokhoz csatlakoztatott épületek csoportja, amelyek garantálják, hogy egyetlen áramkimaradás ne állítson le egy régiót. A felhőrégiók hibái azonban előfordulhatnak, és a fennakadás mértéke és a szervezetre gyakorolt hatása eltérő lehet.
A vészhelyreállítási terv végrehajtása előtt fontos megérteni a vészhelyreállítás (DR) és a magas rendelkezésre állás (HA) közötti különbséget.
A magas rendelkezésre állás a rendszer rugalmassági jellemzője. A magas rendelkezésre állás biztosítja a működési teljesítmény minimális szintjét, amelyet általában konzisztens üzemidő vagy az üzemidő százalékos aránya határoz meg. A magas rendelkezésre állás a helyén (az elsődleges rendszerrel azonos régióban) valósul meg az elsődleges rendszer funkciójának kialakításával. Az Azure-hoz hasonló felhőszolgáltatások például magas rendelkezésre állású szolgáltatásokkal rendelkeznek, például az ADLS gen2 szolgáltatással (a 2023. március 6. előtt létrehozott munkaterületekhez, az Azure Blob Storage-hoz). A magas rendelkezésre állás nem igényel jelentős explicit előkészítést az Azure Databricks-ügyféltől.
Ezzel szemben a vészhelyreállítási tervhez olyan döntésekre és megoldásokra van szükség, amelyek az adott szervezetnél dolgoznak a kritikus rendszerek nagyobb regionális kimaradásának kezeléséhez. Ez a cikk a gyakori vészhelyreállítási terminológiát, a gyakori megoldásokat és az Azure Databricks vészhelyreállítási terveinek ajánlott eljárásait ismerteti.
Terminológia
Régió terminológiája
Ez a cikk a következő definíciókat használja a régiókhoz:
Elsődleges régió: Az a földrajzi régió, amelyben a felhasználók általában napi interaktív és automatizált adatelemzési számítási feladatokat futtatnak.
Másodlagos régió: Az a földrajzi régió, amelyben az informatikai csapatok ideiglenesen áthelyezik az adatelemzési számítási feladatokat az elsődleges régióban történő kimaradás során.
Georedundáns tárolás: Az Azure georedundáns tárolással rendelkezik a régiók között a tartós tároláshoz egy aszinkron tárolási replikációs folyamattal.
Fontos
Vészhelyreállítási folyamatok esetén a Databricks azt javasolja, hogy ne támaszkodjon georedundáns tárolásra az olyan adatok régiók közötti duplikációihoz, mint az ADLS gen2 (a 2023. március 6. előtt létrehozott munkaterületek esetében az Azure Blob Storage), amelyeket az Azure Databricks az Azure-előfizetés minden munkaterületéhez létrehoz. A Mély klón használata a Delta-táblákhoz általában, és az adatok delta formátumúvá konvertálása, ha lehetséges, a Deep Clone használata más adatformátumokhoz.
Üzembehelyezési állapot terminológiája
Ez a cikk az üzembe helyezés állapotának alábbi definícióit használja:
Aktív üzembe helyezés: A felhasználók csatlakozhatnak egy Azure Databricks-munkaterület aktív üzembe helyezéséhez, és számítási feladatokat futtathatnak. A feladatok rendszeres ütemezése az Azure Databricks ütemezője vagy más mechanizmus használatával történik. Az adatfolyamok ezen az üzembe helyezésen is végrehajthatók. Egyes dokumentumok gyakori telepítésként hivatkozhatnak egy aktív üzembe helyezésre.
Passzív üzembe helyezés: A folyamatok nem futnak passzív üzembe helyezésen. Az informatikai csapatok automatikus eljárásokat állíthatnak be a kód, a konfiguráció és más Azure Databricks-objektumok passzív üzembe helyezéséhez. Az üzembe helyezés csak akkor válik aktívvá, ha egy aktuális aktív üzembe helyezés leállt. Egyes dokumentumok hideg üzembe helyezésként hivatkozhatnak a passzív üzembe helyezésre.
Fontos
A projektek opcionálisan több passzív üzembe helyezést is tartalmazhatnak különböző régiókban, hogy további lehetőségeket biztosítsanak a regionális kimaradások megoldására.
Általánosságban elmondható, hogy egy csapatnak egyszerre csak egy aktív üzembe helyezése van, az úgynevezett aktív-passzív vészhelyreállítási stratégiában. Létezik egy kevésbé gyakori, active-active nevű vészhelyreállítási megoldási stratégia, amelyben két egyidejű aktív üzembe helyezés van.
Vészhelyreállítási iparág terminológiája
Két fontos iparági feltételt kell megértenie és definiálnia a csapata számára:
Helyreállítási pont célkitűzése: A helyreállítási pont célkitűzése (RPO) az a maximális célidőszak, amelyben az adatok (tranzakciók) elveszhetnek egy informatikai szolgáltatásból egy nagyobb incidens miatt. Az Azure Databricks üzembe helyezése nem tárolja a fő ügyféladatokat. Ezt külön rendszerekben, például az ADLS gen2-ben (a 2023. március 6. előtt létrehozott munkaterületeken, az Azure Blob Storage-ban) vagy más, ön által felügyelt adatforrásokban tárolja. Az Azure Databricks vezérlősíkja részben vagy teljes egészében tárol bizonyos objektumokat, például feladatokat és jegyzetfüzeteket. Az Azure Databricks esetében az RPO az a maximális célidőszak, amelyben az objektumok, például a feladatok és a jegyzetfüzetek módosításai elveszhetnek. Emellett ön a felelős a saját ügyféladataihoz tartozó RPO meghatározásáért az ADLS gen2-ben (a 2023. március 6. előtt létrehozott munkaterületek esetében, az Azure Blob Storage-ban) vagy más, ön által felügyelt adatforrásokban.
Helyreállítási idő célkitűzése: A helyreállítási idő célkitűzése (RTO) az idő célzott időtartama és egy szolgáltatási szint, amelyen belül egy üzleti folyamatot egy katasztrófa után vissza kell állítani.
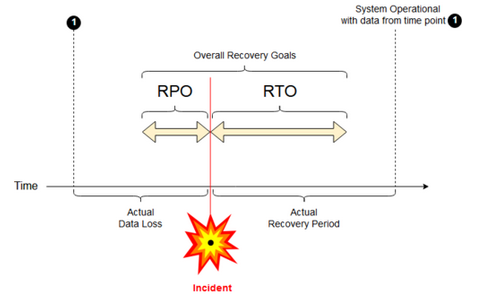
Vészhelyreállítás és adatsérülés
A vészhelyreállítási megoldás nem csökkenti az adatsérülést. Az elsődleges régióban sérült adatok replikálódnak az elsődleges régióból egy másodlagos régióba, és mindkét régióban sérültek. Más módokon is enyhíthetők az ilyen típusú hibák, például a Delta időutazás.
Tipikus helyreállítási munkafolyamat
Az Azure Databricks vészhelyreállítási forgatókönyve általában a következő módon történik:
Hiba történik az elsődleges régióban használt kritikus szolgáltatásban. Ez lehet adatforrás-szolgáltatás vagy hálózat, amely hatással van az Azure Databricks üzembe helyezésére.
A felhőszolgáltatónál vizsgálja meg a helyzetet.
Ha arra a következtetésre jut, hogy a vállalat nem tudja megvárni a probléma megoldását az elsődleges régióban, dönthet úgy, hogy feladatátvételt kell végrehajtania egy másodlagos régióba.
Ellenőrizze, hogy ugyanez a probléma nem érinti-e a másodlagos régiót is.
Feladatátvétel másodlagos régióba.
- Állítsa le az összes tevékenységet a munkaterületen. A felhasználók leállítja a számítási feladatokat. A felhasználókat vagy rendszergazdákat arra utasítjuk, hogy ha lehetséges, készítsenek biztonsági másolatot a legutóbbi módosításokról. A feladatok leállnak, ha még nem hiúsultak meg a kimaradás miatt.
- Indítsa el a helyreállítási eljárást a másodlagos régióban. A helyreállítási eljárás frissíti a másodlagos régióba irányuló kapcsolatok és hálózati forgalom útválasztását és átnevezését.
- A tesztelés után deklarálja a másodlagos régió működését. Az éles számítási feladatok most újraindulhatnak. A felhasználók bejelentkezhetnek az aktív üzembe helyezésbe. Ütemezett vagy késleltetett feladatokat is újrapróbálhat.
Az Azure Databricks-környezet részletes lépéseit a feladatátvétel tesztelése című témakörben találja.
Egy bizonyos ponton az elsődleges régióban a probléma mérséklódik, és ön megerősíti ezt a tényt.
Visszaállítás (feladat-visszavétel) az elsődleges régióba.
- Állítsa le az összes munkát a másodlagos régióban.
- Indítsa el a helyreállítási eljárást az elsődleges régióban. A helyreállítási eljárás kezeli a kapcsolat és a hálózati forgalom átirányítását és átnevezését az elsődleges régióba.
- Szükség szerint replikálja az adatokat az elsődleges régióba. Az összetettség csökkentése érdekében minimalizálhatja, hogy mennyi adatot kell replikálni. Ha például egyes feladatok írásvédettek, amikor a másodlagos üzembe helyezésben futnak, előfordulhat, hogy nem kell ezeket az adatokat replikálnia az elsődleges üzembe helyezésre az elsődleges régióban. Előfordulhat azonban, hogy van egy éles feladat, amelyet futtatnia kell, és szükség lehet az adatreplikálásra az elsődleges régióba.
- Tesztelje az üzembe helyezést az elsődleges régióban.
- Deklarálja az elsődleges régiót működőképesnek, és hogy ez az aktív üzembe helyezés. Éles számítási feladatok folytatása.
Az elsődleges régióba való visszaállításról további információt a visszaállítás tesztelése (feladat-visszavétel) című témakörben talál.
Fontos
Ezen lépések során adatvesztés történhet. A szervezetnek meg kell határoznia, hogy mennyi adatvesztés elfogadható, és mit tehet a veszteség csökkentése érdekében.
1. lépés: Az üzleti igények megismerése
Az első lépés az üzleti igények meghatározása és megértése. Határozza meg, hogy mely adatszolgáltatások kritikusak, és mi a várt RPO és RTO.
Vizsgálja meg az egyes rendszerek valós tűrőképességét, és ne feledje, hogy a vészhelyreállítás feladatátvétele és feladat-visszavétele költséges lehet, és más kockázatokat is hordoz. Egyéb kockázatok közé tartozhat az adatsérülés, az adatok duplikálása, ha nem a megfelelő tárolóhelyre ír, valamint azok a felhasználók, akik rossz helyen jelentkeznek be és módosítják a módosításokat.
Képezheti le az összes olyan Azure Databricks-integrációs pontot, amely hatással van a vállalkozására:
- A vészhelyreállítási megoldásnak interaktív folyamatokat, automatizált folyamatokat vagy mindkettőt kell kezelnie?
- Milyen adatszolgáltatásokat használ? Lehet, hogy néhány helyszíni.
- Hogyan jutnak el a bemeneti adatok a felhőbe?
- Ki használja fel ezeket az adatokat? Milyen folyamatok fogyasztják az alsóbb rétegben?
- Vannak olyan külső integrációk, amelyeknek tisztában kell lenniük a vészhelyreállítás változásaival?
Határozza meg azokat az eszközöket vagy kommunikációs stratégiákat, amelyek támogathatják a vészhelyreállítási tervet:
- Milyen eszközökkel fogja gyorsan módosítani a hálózati konfigurációkat?
- Előre definiálhatja a konfigurációt, és modulárissá teheti a vészhelyreállítási megoldások természetes és karbantartható módon való elhelyezéséhez?
- Mely kommunikációs eszközök és csatornák értesítik a belső csapatokat és harmadik feleket (integrációkat, alsóbb rétegbeli felhasználókat) a vészhelyreállítás feladatátvételi és feladat-visszavételi változásairól? És hogyan erősíted meg a nyugtázásukat?
- Milyen eszközökre vagy speciális támogatásra lesz szükség?
- Milyen szolgáltatások lesznek leállva, amíg a teljes helyreállítás be nem fejeződik?
2. lépés: Válasszon ki egy olyan folyamatot, amely megfelel az üzleti igényeinek
A megoldásnak a megfelelő adatokat kell replikálnia a vezérlősíkon, a számítási síkon és az adatforrásokban is. A vészhelyreállítás redundáns munkaterületeinek különböző régiókban különböző vezérlősíkokra kell megfeleltetniük. Az adatokat rendszeresen szinkronizálva kell tartania egy szkriptalapú megoldással, akár szinkronizálási eszközzel, akár CI/CD-munkafolyamattal. Nem szükséges szinkronizálni az adatokat magáról a számításisík-hálózatról, például a Databricks Runtime-feldolgozókról.
Ha a virtuális hálózatok injektálási funkcióját használja (nem minden előfizetéshez és üzembe helyezési típushoz érhető el), ezeket a hálózatokat sablonalapú eszközökkel, például a Terraformmal konzisztensen üzembe helyezheti mindkét régióban.
Emellett gondoskodnia kell arról, hogy az adatforrások szükség szerint replikálva legyenek a régiók között.
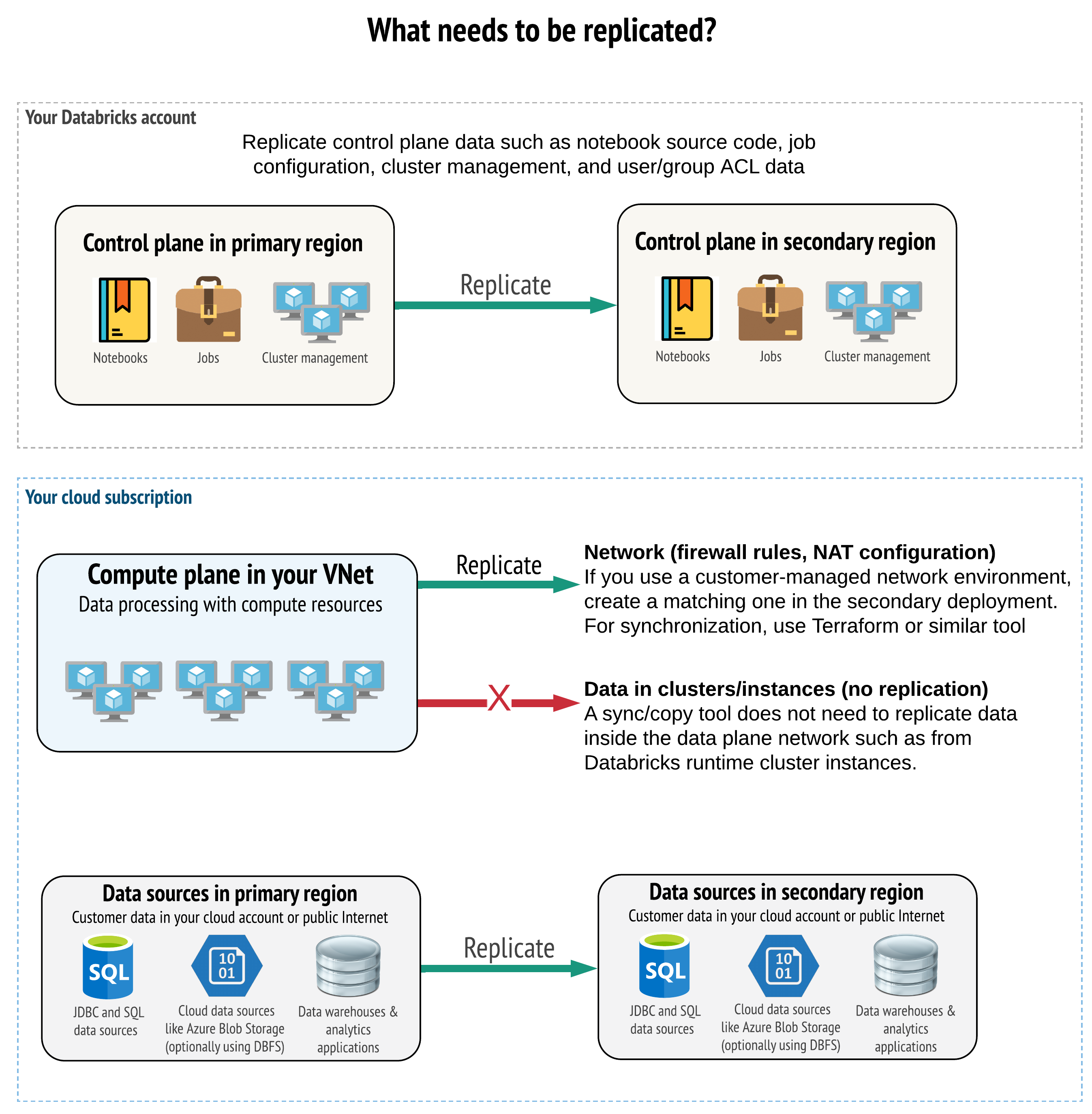
Általános ajánlott eljárások
A sikeres vészhelyreállítási terv általános ajánlott eljárásai a következők:
Ismerje meg, hogy mely folyamatok kritikus fontosságúak az üzletmenet szempontjából, és mely folyamatoknak kell vészhelyreállítást futtatniuk.
Egyértelműen határozza meg, hogy mely szolgáltatások vesznek részt, mely adatokat dolgozzák fel, mi az adatfolyam, és hol tárolják őket
A lehető legnagyobb mértékben elkülönítheti a szolgáltatásokat és az adatokat. Hozzon létre például egy speciális felhőalapú tárolót az adatokhoz vészhelyreállításhoz, vagy helyezze át a katasztrófa során szükséges Azure Databricks-objektumokat egy külön munkaterületre.
Az Ön felelőssége, hogy fenntartsa az integritást a Databricks vezérlősíkban nem tárolt egyéb objektumok elsődleges és másodlagos üzemelő példányai között.
Figyelmeztetés
Ajánlott, hogy ne tárolja az adatokat a munkaterület ADATBÁZISFS-gyökérhozzáféréséhez használt, 2023. március 6. előtt létrehozott munkaterületek esetében a gen2 gyökérszintű ADLS gen2-ben. Ez a DBFS-gyökértároló nem támogatott az éles ügyféladatokhoz. A Databricks azt is javasolja, hogy ezen a helyen ne tároljon kódtárakat, konfigurációs fájlokat vagy init-szkripteket.
Az adatforrások esetében, ahol lehetséges, javasoljuk, hogy natív Azure-eszközöket használjon a replikációhoz és a redundanciához az adatok vészhelyreállítási régiókba való replikálásához.
Helyreállítási megoldás stratégiájának kiválasztása
A tipikus vészhelyreállítási megoldások két (vagy esetleg több) munkaterületet foglalnak magukban. Számos stratégia közül választhat. Fontolja meg a fennakadás lehetséges hosszát (órák vagy akár egy nap), a munkaterület teljes működőképességének biztosítását, valamint az elsődleges régióba történő visszaállítás (feladat-visszavétel) erőfeszítést.
Aktív-passzív megoldásstratégia
Az aktív-passzív megoldás a leggyakoribb és legegyszerűbb megoldás, és ez a megoldástípus a cikk középpontjában áll. Az aktív-passzív megoldás szinkronizálja az aktív üzembe helyezés adatainak és objektumváltozásainak adatait és objektummódosításait a passzív üzembe helyezéssel. Ha szeretné, több passzív üzembe helyezést is használhat különböző régiókban, de ez a cikk az egyetlen passzív üzembehelyezési megközelítésre összpontosít. Vészhelyreállítási esemény során a másodlagos régióban a passzív üzembe helyezés lesz az aktív üzembe helyezés.
Ennek a stratégiának két fő változata van:
- Egységes (nagyvállalati szintű) megoldás: Pontosan egy olyan aktív és passzív üzembe helyezési készlet, amely a teljes szervezetet támogatja.
- Megoldás részleg vagy projekt szerint: Minden részleg vagy projekttartomány külön vészhelyreállítási megoldást tart fenn. Egyes szervezetek el szeretnék különíteni a vészhelyreállítás részleteit a részlegek között, és az egyes csapatok egyedi igényei alapján különböző elsődleges és másodlagos régiókat szeretnének használni.
Vannak más változatok is, például passzív üzembe helyezés írásvédett használati esetekhez. Ha írásvédett számítási feladatokkal rendelkezik, például felhasználói lekérdezésekkel, azok bármikor futtathatók passzív megoldáson, ha nem módosítják az adatokat vagy az Azure Databricks-objektumokat, például jegyzetfüzeteket vagy feladatokat.
Aktív-aktív megoldásstratégia
Egy aktív-aktív megoldásban az összes adatfolyamatot egyszerre futtatja mindkét régióban. Az operatív csapatnak biztosítania kell, hogy egy adatfolyamat, például egy feladat csak akkor legyen befejezettként megjelölve, ha mindkét régióban sikeresen befejeződött. Az objektumok éles környezetben nem módosíthatók, és szigorú CI/CD-előléptetést kell követnie a fejlesztéstől/előkészítéstől az éles környezetig.
Az aktív-aktív megoldás a legösszetettebb stratégia, és mivel a feladatok mindkét régióban futnak, további pénzügyi költségek is járnak.
Az aktív-passzív stratégiához hasonlóan ezt is egységes szervezeti megoldásként vagy részlegek szerint valósíthatja meg.
A munkafolyamattól függően előfordulhat, hogy a másodlagos rendszerben nincs szükség egyenértékű munkaterületre az összes munkaterülethez. Előfordulhat például, hogy egy fejlesztési vagy előkészítési munkaterületnek nincs szüksége duplikációra. Egy jól megtervezett fejlesztési folyamattal szükség esetén könnyen rekonstruálhatja ezeket a munkaterületeket.
Az eszköz kiválasztása
Az eszközöknek két fő módszere van arra, hogy az adatok az elsődleges és a másodlagos régióban lévő munkaterületek között a lehető hasonlóak maradjanak:
- Az elsődlegesről a másodlagosra másolt szinkronizálási ügyfél: A szinkronizálási ügyfél leküldi az éles adatokat és az eszközöket az elsődleges régióból a másodlagos régióba. Ez általában ütemezett alapon fut.
- CI/CD-eszközök párhuzamos üzembe helyezéshez: Az éles kód és az eszközök esetében olyan CI/CD-eszközkészletet használjon, amely egyszerre küldi le az éles rendszerek módosításait mindkét régióba. Ha például kódokat és eszközöket küld le az előkészítésről/fejlesztésről az éles környezetbe, a CI/CD-rendszer mindkét régióban egyszerre teszi elérhetővé. Az alapötlet az, hogy az Azure Databricks-munkaterület összes összetevője kódként infrastruktúraként legyen kezelve. A legtöbb összetevő együtt üzembe helyezhető az elsődleges és a másodlagos munkaterületeken is, míg egyes összetevőket csak vészhelyreállítási esemény után kell üzembe helyezni. Eszközök: Automation-szkriptek , minták és prototípusok.
Az alábbi ábra ezt a két megközelítést hasonlítja össze.
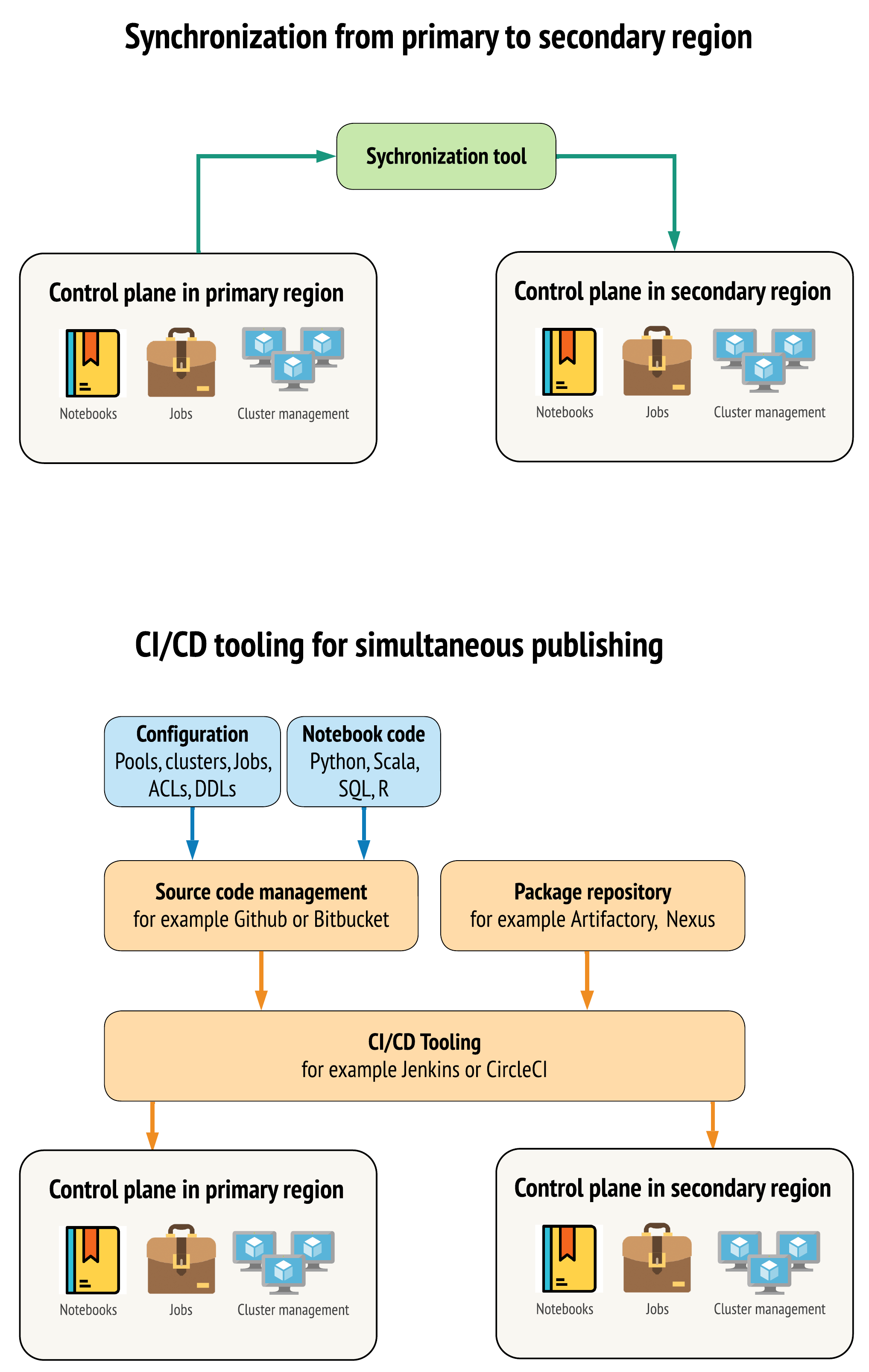
Az igényeitől függően kombinálhatja a megközelítéseket. Használhatja például a CI/CD-t a jegyzetfüzet forráskódjaként, de szinkronizálást használjon a konfigurációhoz, például készletekhez és hozzáférés-vezérlőkhöz.
Az alábbi táblázat bemutatja, hogyan kezelhetők különböző típusú adatok az egyes eszközkezelési beállításokkal.
| Leírás | Ci/CD-eszközök kezelése | Kezelés szinkronizálási eszközzel |
|---|---|---|
| Forráskód: jegyzetfüzet-forrásexportok és a csomagolt kódtárak forráskódja | Közös üzembe helyezés elsődleges és másodlagos környezetben is. | A forráskód szinkronizálása elsődlegesről másodlagosra. |
| Felhasználók és csoportok | Metaadatok kezelése konfigurációként a Gitben. Másik lehetőségként használja ugyanazt az identitásszolgáltatót (IdP) mindkét munkaterülethez. Felhasználói és csoportadatok együttes üzembe helyezése elsődleges és másodlagos üzemelő példányokon. | Használjon SCIM-et vagy más automatizálást mindkét régióhoz. A manuális létrehozás nem ajánlott, de használat esetén mindkettőt egyszerre kell elvégezni. Ha manuális beállítást használ, hozzon létre egy ütemezett automatizált folyamatot, amely összehasonlítja a felhasználók és a csoportok listáját a két üzembe helyezés között. |
| Készlet-konfigurációk | Sablon lehet a Gitben. Közös üzembe helyezés elsődleges és másodlagos környezetben. Másodlagos min_idle_instances esetben azonban a vészhelyreállítási eseményig nullának kell lennie. |
Azok a készletek, amelyek akkor min_idle_instances jönnek létre, amikor az API vagy a parancssori felület használatával szinkronizálódnak a másodlagos munkaterületre. |
| Feladatkonfigurációk | Sablon lehet a Gitben. Az elsődleges üzembe helyezéshez helyezze üzembe a feladatdefiníciót, ahogyan van. Másodlagos üzembe helyezés esetén helyezze üzembe a feladatot, és állítsa az egyidejűségeket nullára. Ez letiltja a feladatot ebben az üzembe helyezésben, és megakadályozza a további futtatásokat. Módosítsa az egyidejű értékeket, miután a másodlagos üzembe helyezés aktívvá válik. | Ha a feladatok valamilyen okból már meglévő <interactive> fürtökön futnak, akkor a szinkronizálási ügyfélnek a másodlagos munkaterület megfelelőjéhez cluster_id kell megfeleltetnie. |
| Hozzáférés-vezérlési lista (ACL-ek) | Sablon lehet a Gitben. Közös üzembe helyezés a jegyzetfüzetek, mappák és fürtök elsődleges és másodlagos üzemelő példányaihoz. A feladatok adatait azonban a vészhelyreállítási eseményig tárolja. | Az Engedélyek API beállíthatja a fürtök, a feladatok, a készletek, a jegyzetfüzetek és a mappák hozzáférés-vezérlését. A szinkronizálási ügyfélnek le kell képeznie a megfelelő objektumazonosítókat a másodlagos munkaterület minden objektumához. A Databricks azt javasolja, hogy hozzon létre egy objektumazonosító-térképet az elsődlegesről a másodlagos munkaterületre, miközben szinkronizálja ezeket az objektumokat a hozzáférés-vezérlők replikálása előtt . |
| Kódtárak | Szerepeljen a forráskódban és a fürt-/feladatsablonokban. | Egyéni tárak szinkronizálása központosított adattárakból, DBFS-ből vagy felhőbeli tárolóból (csatlakoztatható). |
| Fürt init szkriptjei | Tetszés szerint szerepeljen a forráskódban. | Az egyszerűbb szinkronizálás érdekében tárolja az init-szkripteket az elsődleges munkaterületen egy közös mappában vagy egy kis mappakészletben, ha lehetséges. |
| Csatlakoztatási pontok | Ha csak jegyzetfüzet-alapú feladatokon vagy Command API-on keresztül jött létre, vegye fel a forráskódba. | Használjon olyan feladatokat, amelyek Azure Data Factory-tevékenységként (ADF) futtathatók. Vegye figyelembe, hogy a tárolási végpontok változhatnak, mivel a munkaterületek különböző régiókban lennének. Ez nagyban függ az adatkatasztrófa-helyreállítási stratégiától is. |
| Tábla metaadatai | Ha csak jegyzetfüzet-alapú feladatokon vagy Command API-on keresztül jön létre, használja a forráskódot. Ez mind a belső Azure Databricks-metaadattárra, mind a külső konfigurált metaadattárra vonatkozik. | Hasonlítsa össze a metaadat-definíciókat a metaadattárak között a Spark Catalog API-val, vagy tábla létrehozása jegyzetfüzeten vagy szkripteken keresztül. Vegye figyelembe, hogy a mögöttes tároló táblái régióalapúak lehetnek, és eltérőek lesznek a metaadattár-példányok között. |
| Titkos kódok | Ha csak a Command API-val jön létre, vegye fel a forráskódba. Vegye figyelembe, hogy előfordulhat, hogy egyes titkos kulcsok tartalma megváltozik az elsődleges és a másodlagos között. | A titkos kódok mindkét munkaterületen az API-val jönnek létre. Vegye figyelembe, hogy előfordulhat, hogy egyes titkos kulcsok tartalma megváltozik az elsődleges és a másodlagos között. |
| Fürtkonfigurációk | Sablon lehet a Gitben. Közös üzembe helyezés elsődleges és másodlagos üzemelő példányokon, bár a másodlagos üzemelő példányokat a vészhelyreállítási eseményig le kell zárni. | A fürtök azután jönnek létre, hogy az API vagy a parancssori felület használatával szinkronizálódnak a másodlagos munkaterületre. Ezek igény szerint explicit módon is megszüntethetők az automatikus megszüntetési beállításoktól függően. |
| Jegyzetfüzet-, feladat- és mappaengedélyek | Sablon lehet a Gitben. Közös üzembe helyezés elsődleges és másodlagos üzemelő példányokon. | Replikálás az Engedélyek API használatával. |
Régiók és több másodlagos munkaterület kiválasztása
A vészhelyreállítási eseményindító teljes felügyeletére van szüksége. Ezt bármikor vagy bármilyen okból aktiválhatja. A művelet feladat-visszavételi (normál üzemi) módjának újraindítása előtt felelősséget kell vállalnia a vészhelyreállítás stabilizálásáért. Ez általában azt jelenti, hogy több Azure Databricks-munkaterületet kell létrehoznia az éles és vészhelyreállítási igények kiszolgálásához, és ki kell választania a másodlagos feladatátvételi régiót.
Az Azure-ban ellenőrizze az adatreplikálást, valamint a termék- és virtuálisgép-típusok rendelkezésre állását.
3. lépés: Munkaterületek előkészítése és egyszeri másolás
Ha egy munkaterület már éles környezetben van, általában egy egyszeri másolási műveletet kell futtatnia, hogy szinkronizálja a passzív üzembe helyezést az aktív üzembe helyezéssel. Ez az egyszeri másolás a következőket kezeli:
- Adatreplikáció: Replikálás felhőalapú replikációs megoldással vagy Delta Deep Clone művelettel.
- Jogkivonat-létrehozás: A tokengenerálás használatával automatizálhatja a replikációt és a jövőbeli számítási feladatokat.
- Munkaterület-replikáció: Munkaterület-replikáció használata a 4. lépésben ismertetett módszerekkel: Adatforrások előkészítése.
- Munkaterület érvényesítése: – tesztelje, hogy a munkaterület és a folyamat sikeresen végrehajtható-e, és hogy a várt eredményt adja-e.
A kezdeti egyszeri másolási művelet után a másolási és szinkronizálási műveletek gyorsabbak lesznek, és az eszközökről történő naplózás is naplózza, hogy mi változott és mikor változott.
4. lépés: Adatforrások előkészítése
Az Azure Databricks számos különböző adatforrást képes feldolgozni kötegelt feldolgozással vagy adatfolyamokkal.
Kötegelt feldolgozás adatforrásokból
Amikor az adatokat kötegelt feldolgozással dolgozzák fel, az általában egy olyan adatforrásban található, amely könnyen replikálható vagy egy másik régióba szállítható.
Előfordulhat például, hogy az adatok rendszeresen feltöltődnek egy felhőbeli tárolóhelyre. A másodlagos régió vészhelyreállítási módjában győződjön meg arról, hogy a fájlok fel lesznek töltve a másodlagos régió tárterületére. A számítási feladatoknak be kell olvasniuk a másodlagos régió tárolóit, és írniuk kell a másodlagos régió tárolóba.
Adatfolyamok
Az adatfolyam feldolgozása nagyobb kihívást jelent. A streamelési adatok különböző forrásokból is betölthetők, és feldolgozhatók és elküldhetők egy streamelési megoldásnak:
- Üzenetsor, például Kafka
- Adatbázis-módosítási adatrögzítési stream
- Fájlalapú folyamatos feldolgozás
- Fájlalapú ütemezett feldolgozás, más néven eseményindító egyszer
Minden ilyen esetben konfigurálnia kell az adatforrásokat a vészhelyreállítási mód kezelésére és a másodlagos üzembe helyezés használatára a másodlagos régióban.
A streamírók egy ellenőrzőpontot tárolnak a feldolgozott adatokkal kapcsolatos információkkal. Ez az ellenőrzőpont tartalmazhat egy adathelyet (általában felhőbeli tárolót), amelyet új helyre kell módosítani a stream sikeres újraindításához. Az ellenőrzőpont alatti almappában például előfordulhat, source hogy a fájlalapú felhőmappát tárolja.
Ezt az ellenőrzőpontot időben kell replikálni. Fontolja meg az ellenőrzőpont-időköz szinkronizálását bármely új felhőreplikációs megoldással.
Az ellenőrzőpont frissítése az író függvénye, ezért az adatfolyamok betöltésére, feldolgozására és tárolására vonatkozik egy másik streamforráson.
Streamelési számítási feladatok esetén győződjön meg arról, hogy az ellenőrzőpontok az ügyfél által felügyelt tárolóban vannak konfigurálva, hogy a számítási feladatok újrakezdéséhez replikálhatók legyenek a másodlagos régióba a legutóbbi hiba pontjától kezdve. Dönthet úgy is, hogy a másodlagos streamelési folyamatot az elsődleges eljárással párhuzamosan futtatja.
5. lépés: A megoldás implementálása és tesztelése
Rendszeresen tesztelje a vészhelyreállítás beállítását, hogy biztosan megfelelően működjön. Nincs érték a vészhelyreállítási megoldás fenntartásában, ha nem tudja használni, amikor szüksége van rá. Egyes vállalatok néhány havonta váltanak régiók között. A régiók rendszeres ütemezés szerinti váltása teszteli a feltételezéseket és a folyamatokat, és biztosítja, hogy megfeleljenek a helyreállítási igényeknek. Ez azt is biztosítja, hogy a szervezet tisztában legyen a vészhelyzetekre vonatkozó szabályzatokkal és eljárásokkal.
Fontos
A vészhelyreállítási megoldás rendszeres tesztelése valós körülmények között.
Ha azt tapasztalja, hogy hiányzik egy objektum vagy sablon, és továbbra is az elsődleges munkaterületen tárolt információkra kell támaszkodnia, módosítsa a tervet, hogy eltávolítsa ezeket az akadályokat, replikálja ezeket az információkat a másodlagos rendszerben, vagy más módon tegye elérhetővé.
Tesztelje a folyamatok és általában a konfiguráció szükséges szervezeti módosításait. A vészhelyreállítási terv hatással van az üzembehelyezési folyamatra, és fontos, hogy a csapat tudja, mit kell szinkronban tartani. A vészhelyreállítási munkaterületek beállítása után gondoskodnia kell arról, hogy az infrastruktúra (manuális vagy kód), a feladatok, a jegyzetfüzetek, a tárak és más munkaterület-objektumok elérhetők legyenek a másodlagos régióban.
Beszéljen a csapatával arról, hogyan bővítheti ki a standard munkafolyamatokat és konfigurációs folyamatokat a módosítások üzembe helyezéséhez az összes munkaterületen. Felhasználói identitások kezelése az összes munkaterületen. Ne felejtse el konfigurálni az olyan eszközöket, mint a feladatok automatizálása és az új munkaterületek monitorozása.
A konfigurációs eszközök módosításainak megtervezése és tesztelése:
- Betöltés: Annak megismerése, hogy hol találhatók az adatforrások, és hogy ezek a források hol kapják meg az adataikat. Ahol lehetséges, paraméterezheti a forrást, és győződjön meg arról, hogy külön konfigurációs sablonnal dolgozik a másodlagos üzemelő példányokkal és a másodlagos régiókkal. Készítsen egy tervet a feladatátvételhez, és tesztelje az összes feltételezést.
- Végrehajtási módosítások: Ha rendelkezik egy ütemezővel a feladatok vagy más műveletek aktiválásához, előfordulhat, hogy egy külön ütemezőt kell konfigurálnia, amely a másodlagos üzembe helyezéssel vagy annak adatforrásaival működik. Készítsen egy tervet a feladatátvételhez, és tesztelje az összes feltételezést.
- Interaktív kapcsolat: Fontolja meg, hogy a konfigurációt, a hitelesítést és a hálózati kapcsolatokat hogyan befolyásolhatják a REST API-k, CLI-eszközök vagy más szolgáltatások, például a JDBC/ODBC használata során fellépő regionális fennakadások. Készítsen egy tervet a feladatátvételhez, és tesztelje az összes feltételezést.
- Automatizálási változások: Minden automatizálási eszköz esetében készítsen tervet a feladatátvételre, és tesztelje az összes feltételezést.
- Kimenetek: Minden olyan eszköz esetében, amely kimeneti adatokat vagy naplókat hoz létre, készítsen egy tervet a feladatátvételhez, és tesztelje az összes feltételezést.
Feladatátvétel tesztelése
A vészhelyreállítást számos különböző forgatókönyv aktiválhatja. Váratlan törés aktiválhatja. Előfordulhat, hogy egyes alapvető funkciók leállnak, beleértve a felhőhálózatot, a felhőtárhelyet vagy egy másik alapvető szolgáltatást. Nincs hozzáférése a rendszer kecses leállításához, és meg kell próbálnia a helyreállítást. A folyamatot azonban kiválthatja egy leállítás vagy tervezett üzemkimaradás, vagy akár az aktív üzemelő példányok rendszeres váltása két régió között.
A feladatátvétel tesztelésekor csatlakozzon a rendszerhez, és futtasson leállítási folyamatot. Győződjön meg arról, hogy az összes feladat befejeződött, és a fürtök leálltak.
A szinkronizálási ügyfélprogram (vagy CI/CD-eszközök) a releváns Azure Databricks-objektumokat és -erőforrásokat replikálhatják a másodlagos munkaterületre. A másodlagos munkaterület aktiválásához a folyamat az alábbiak némelyikét vagy mindegyikét tartalmazhatja:
- Futtasson teszteket annak ellenőrzéséhez, hogy a platform naprakész-e.
- Tiltsa le a készleteket és fürtöket az elsődleges régióban, hogy ha a sikertelen szolgáltatás online állapotba áll, az elsődleges régió ne kezdje el az új adatok feldolgozását.
- Helyreállítási folyamat:
- Ellenőrizze a legújabb szinkronizált adatok dátumát. Lásd a vészhelyreállítási iparág terminológiát. Ennek a lépésnek a részletei az adatok szinkronizálásától és az egyedi üzleti igényektől függően változnak.
- Stabilizálja az adatforrásokat, és győződjön meg arról, hogy mindegyik elérhető. Vegye fel az összes külső adatforrást, például az Azure Cloud SQL-t, valamint a Delta Lake-t, a Parquetet vagy más fájlokat.
- Keresse meg a streamelési helyreállítási pontot. Állítsa be a folyamatot, hogy onnan újrainduljon, és egy folyamat készen áll a lehetséges duplikációk azonosítására és kiküszöbölésére (a Delta Lake megkönnyíti ezt).
- Végezze el az adatfolyam-folyamatot, és tájékoztassa a felhasználókat.
- Indítsa el a megfelelő készleteket (vagy növelje a
min_idle_instancesmegfelelő számot). - Indítsa el a megfelelő fürtöket (ha nem áll le).
- Módosítsa a feladatok egyidejű futtatását, és futtassa a megfelelő feladatokat. Ezek lehetnek egyszeri vagy időszakos futtatások.
- Minden olyan külső eszköz esetében, amely URL-címet vagy tartománynevet használ az Azure Databricks-munkaterülethez, frissítse a konfigurációkat, hogy figyelembe vegyék az új vezérlősíkot. Frissítse például a REST API-k és a JDBC/ODBC-kapcsolatok URL-címeit. Az Azure Databricks-webalkalmazás ügyféloldali URL-címe megváltozik a vezérlősík változásakor, ezért értesítse a szervezet felhasználóit az új URL-címről.
Visszaállítás tesztelése (feladat-visszavétel)
A feladat-visszavétel egyszerűbben szabályozható, és karbantartási időszakban is elvégezhető. Ez a terv az alábbiak némelyikét vagy mindegyikét tartalmazhatja:
- Megerősítést kaphat az elsődleges régió visszaállításáról.
- Tiltsa le a készleteket és fürtöket a másodlagos régióban, hogy ne kezdje el az új adatok feldolgozását.
- Szinkronizálja a másodlagos munkaterületen lévő új vagy módosított objektumokat az elsődleges üzembe helyezéssel. A feladatátvételi szkriptek kialakításától függően előfordulhat, hogy ugyanazokat a szkripteket futtatva szinkronizálhatja az objektumokat a másodlagos (vészhelyreállítási) régióból az elsődleges (éles) régióba.
- Szinkronizálja az új adatfrissítéseket az elsődleges üzembe helyezésre. A naplók és a Delta-táblák naplóinak nyomvonalával garantálhatja az adatok elvesztését.
- Állítsa le az összes számítási feladatot a vészhelyreállítási régióban.
- Módosítsa a feladatok és a felhasználók URL-címét az elsődleges régióra.
- Futtasson teszteket annak ellenőrzéséhez, hogy a platform naprakész-e.
- Indítsa el a megfelelő készleteket (vagy növelje a
min_idle_instancesmegfelelő számra). - Indítsa el a megfelelő fürtöket (ha nem áll le).
- Módosítsa a feladatok egyidejű futtatását, és futtassa a megfelelő feladatokat. Ezek lehetnek egyszeri vagy időszakos futtatások.
- Szükség esetén állítsa be ismét a másodlagos régiót a későbbi vészhelyreállításhoz.
Automation-szkriptek, minták és prototípusok
A vészhelyreállítási projektekhez megfontolandó automation-szkriptek:
- A Databricks azt javasolja, hogy a Databricks Terraform Provider használatával dolgozzon ki saját szinkronizálási folyamatot.
- Lásd még a Databricks-munkaterület migrálási eszközeit minta- és prototípusszkriptekhez. Az Azure Databricks-objektumok mellett replikálja a releváns Azure Data Factory-folyamatokat is, így a másodlagos munkaterületre leképezett társított szolgáltatásra hivatkoznak.
- A Databricks Sync (DBSync) projekt egy objektumszinkronizálási eszköz, amely a Databricks-munkaterületek biztonsági mentését, visszaállítását és szinkronizálását biztosítja.
Visszajelzés
Hamarosan elérhető: 2024-ben fokozatosan kivezetjük a GitHub-problémákat a tartalom visszajelzési mechanizmusaként, és lecseréljük egy új visszajelzési rendszerre. További információ: https://aka.ms/ContentUserFeedback.
Visszajelzés küldése és megtekintése a következőhöz: