Megjegyzés
Az oldalhoz való hozzáféréshez engedély szükséges. Megpróbálhat bejelentkezni vagy módosítani a címtárat.
Az oldalhoz való hozzáféréshez engedély szükséges. Megpróbálhatja módosítani a címtárat.
Ez a cikk bemutatja, hogyan használható kiszolgáló nélküli számítás a jegyzetfüzetekhez. A kiszolgáló nélküli számítási feladatokhoz való használatáról további információt a Lakeflow-feladatok futtatása kiszolgáló nélküli számítással munkafolyamatokhoz című témakörben talál.
A kiszolgáló nélküli számítás notebookokban való használatával kapcsolatos díjszabási információkért lásd a Databricks díjszabását.
Követelmények
- A munkaterületet a Unity Catalog engedélyezésére kell alkalmassá tenni.
- A munkaterületnek támogatott régióban kell lennie a kiszolgáló nélküli számításhoz. Tekintse meg az Azure Databricks-régiókat.
Jegyzetfüzet csatolása kiszolgáló nélküli számításhoz
Ha a munkaterület engedélyezve van a kiszolgáló nélküli interaktív számításhoz, a munkaterület összes felhasználója hozzáférhet a jegyzetfüzetek kiszolgáló nélküli számításához. Nincs szükség további engedélyekre.
A kiszolgáló nélküli számításhoz való csatoláshoz kattintson a Csatlakozás legördülő menüre a jegyzetfüzetben, és válassza Kiszolgáló nélkülilehetőséget. Új jegyzetfüzetek esetén a csatolt számítás automatikusan kiszolgáló nélkülire vált a kód végrehajtásakor, ha nincs más erőforrás kijelölve.
Lekérdezési elemzések megtekintése
A jegyzetfüzetekhez és feladatokhoz készült kiszolgáló nélküli számítás lekérdezési megállapításokat használ a Spark végrehajtási teljesítményének felméréséhez. Miután futtatott egy cellát egy jegyzetfüzetben, az SQL- és Python-lekérdezésekkel kapcsolatos elemzéseket a Teljesítmény megtekintése hivatkozásra kattintva tekintheti meg.
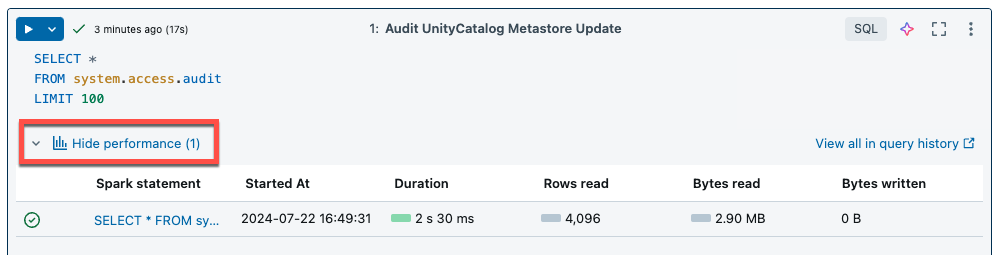
A lekérdezési metrikák megtekintéséhez kattintson bármelyik Spark-utasításra. Innen a Lekérdezésprofil megtekintése gombra kattintva megtekintheti a lekérdezés végrehajtásának vizualizációját. A lekérdezési profilokról további információt a Lekérdezésprofil című témakörben talál.
Feljegyzés
A feladatfuttatások teljesítményelemzéseinek megtekintéséhez tekintse meg a feladatfuttatás lekérdezési elemzéseinek megtekintése című témakört.
Lekérdezések előzményei
A kiszolgáló nélküli számításon futó összes lekérdezést a rendszer a munkaterület lekérdezési előzményoldalán is rögzíti. A lekérdezési előzményekről további információt a Lekérdezési előzmények című témakörben talál.
Lekérdezéselemzés korlátozásai
- A lekérdezésprofil csak a lekérdezés végrehajtása után érhető el.
- A metrikák élőben frissülnek, bár a lekérdezési profil nem jelenik meg a végrehajtás során.
- Csak a következő lekérdezési állapotok szerepelnek: FUTTATÁS, MEGSZAKÍTVA, HIBA, KÉSZ.
- A lekérdezések futtatása nem szakítható meg a lekérdezéselőzmények oldaláról. Jegyzetfüzetekben vagy munkákban törölhetők.
- Részletes metrikák nem érhetők el.
- A lekérdezésprofil letöltése nem érhető el.
- A Spark felhasználói felülethez való hozzáférés nem érhető el.
- Az utasítás szövege csak az utolsó futtatott sort tartalmazza. Azonban ennek a sornak előzőleg több olyan sora is lehet, amely ugyanannak a nyilatkozatnak a részeként futott.
Kiszolgáló nélküli túlköltekeztetés elleni védelem
A hosszan futó lekérdezések szabályozásához a kiszolgáló nélküli jegyzetfüzetek alapértelmezett végrehajtási időkorlátja 2,5 óra. Beállíthatja az időtúllépés hosszát manuálisan, ha a jegyzetfüzetben konfigurálja a spark.databricks.execution.timeout értéket. Lásd: Spark-tulajdonságok konfigurálása kiszolgáló nélküli jegyzetfüzetekhez és feladatokhoz.