Megjegyzés
Az oldalhoz való hozzáféréshez engedély szükséges. Megpróbálhat bejelentkezni vagy módosítani a címtárat.
Az oldalhoz való hozzáféréshez engedély szükséges. Megpróbálhatja módosítani a címtárat.
Ez a cikk azt ismerteti, hogyan konfigurálhat kapcsolatot az Azure Databrickstől a Google Cloud Storage-ban (GCS) tárolt táblák és adatok olvasásához és írásához.
Ha GCS-gyűjtőből szeretne olvasni vagy írni, létre kell hoznia egy csatolt szolgáltatásfiókot, és hozzá kell rendelnie a gyűjtőt a szolgáltatásfiókhoz. Közvetlenül a szolgáltatásfiókhoz létrehozott kulccsal csatlakozik a gyűjtőhöz.
GCS-gyűjtő elérése közvetlenül Google Cloud-szolgáltatásfiók-kulccsal
Ha közvetlenül egy gyűjtőbe szeretne írni és olvasni, konfiguráljon egy, a Spark-konfigurációban definiált kulcsot.
1. lépés: Google Cloud-szolgáltatásfiók beállítása a Google Cloud Console használatával
Létre kell hoznia egy szolgáltatásfiókot az Azure Databricks-fürthöz. A Databricks azt javasolja, hogy a szolgáltatásfióknak adja meg a feladatai elvégzéséhez szükséges legkevesebb jogosultságot.
Kattintson az IAM és a Rendszergazda elemre a bal oldali navigációs panelen.
Kattintson a Szolgáltatásfiókok elemre.
Kattintson a + SZOLGÁLTATÁSFIÓK LÉTREHOZÁSA elemre.
Adja meg a szolgáltatásfiók nevét és leírását.
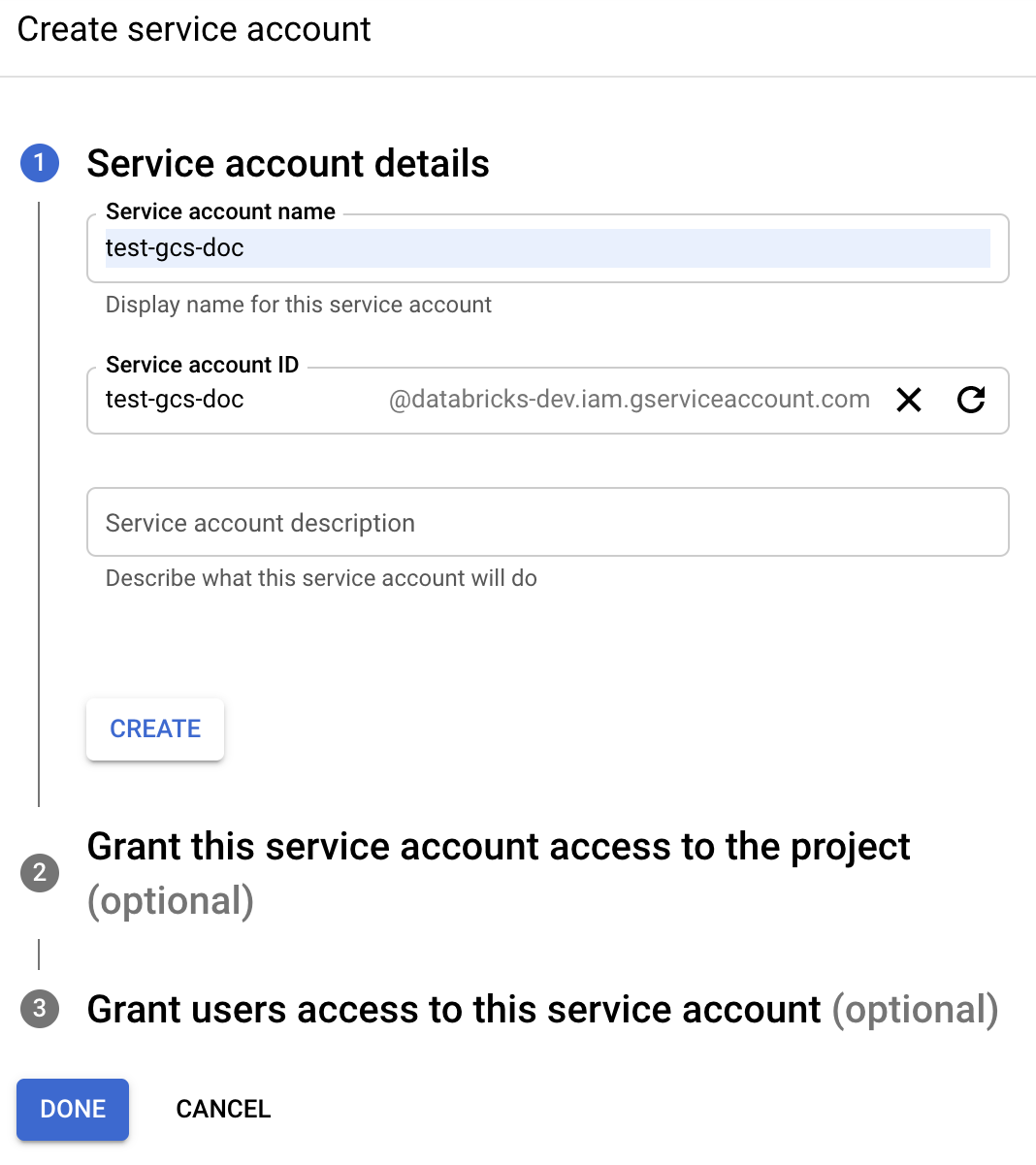
Kattintson a LÉTREHOZÁS gombra.
Kattintson a FOLYTATÁS gombra.
Kattintson a KÉSZ gombra.
2. lépés: Kulcs létrehozása a GCS-gyűjtő közvetlen eléréséhez
Figyelmeztetés
A szolgáltatásfiókhoz létrehozott JSON-kulcs egy privát kulcs, amelyet csak a jogosult felhasználókkal szabad megosztani, mivel ez szabályozza a Google Cloud-fiókban lévő adathalmazokhoz és erőforrásokhoz való hozzáférést.
- A Google Cloud-konzol szolgáltatásfiókok listájában kattintson az újonnan létrehozott fiókra.
- A Kulcsok szakaszban kattintson az ADD KEY Create new key (Kulcs > hozzáadása új kulcs létrehozása) elemre.
- Fogadja el a JSON-kulcs típusát.
- Kattintson a LÉTREHOZÁS gombra. A rendszer letölti a kulcsfájlt a számítógépre.
3. lépés: A GCS-gyűjtő konfigurálása
Gyűjtő létrehozása
Ha még nincs gyűjtője, hozzon létre egyet:
Kattintson a Bal oldali navigációs panelEn a Storage elemre .
Kattintson a CREATE BUCKET (GYŰJTŐ LÉTREHOZÁSA) gombra.
Kattintson a LÉTREHOZÁS gombra.
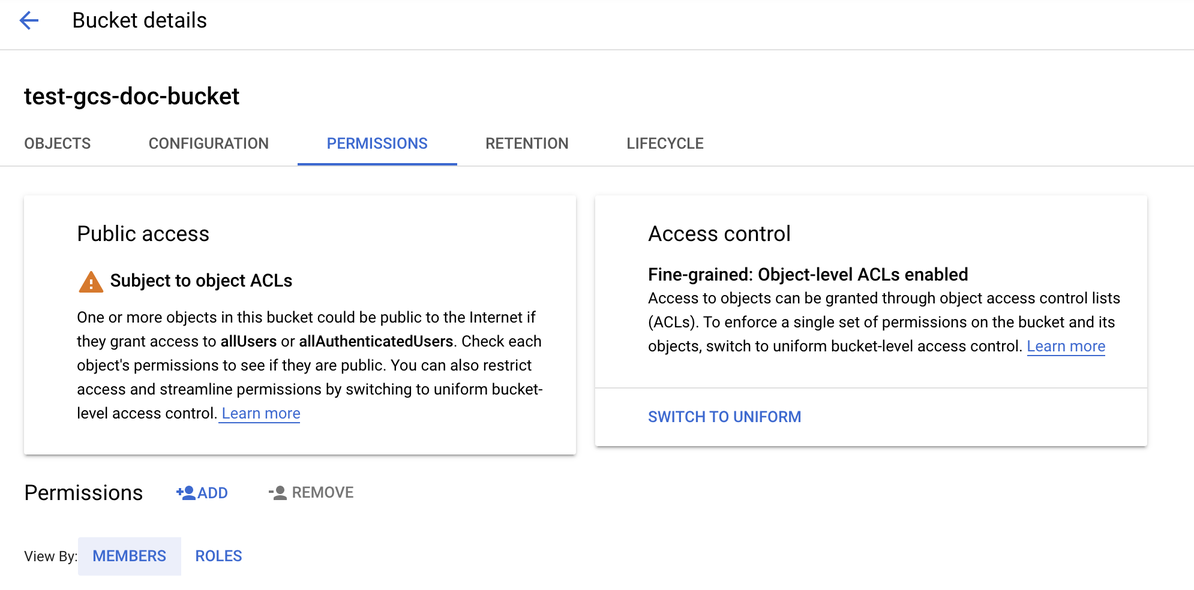
A gyűjtő konfigurálása
Konfigurálja a gyűjtő részleteit.
Kattintson az Engedélyek fülre .
Az Engedélyek címke mellett kattintson a HOZZÁADÁS gombra.
Adja meg a Storage-rendszergazdai engedélyt a gyűjtőben lévő szolgáltatásfiókhoz a Cloud Storage-szerepkörökből.
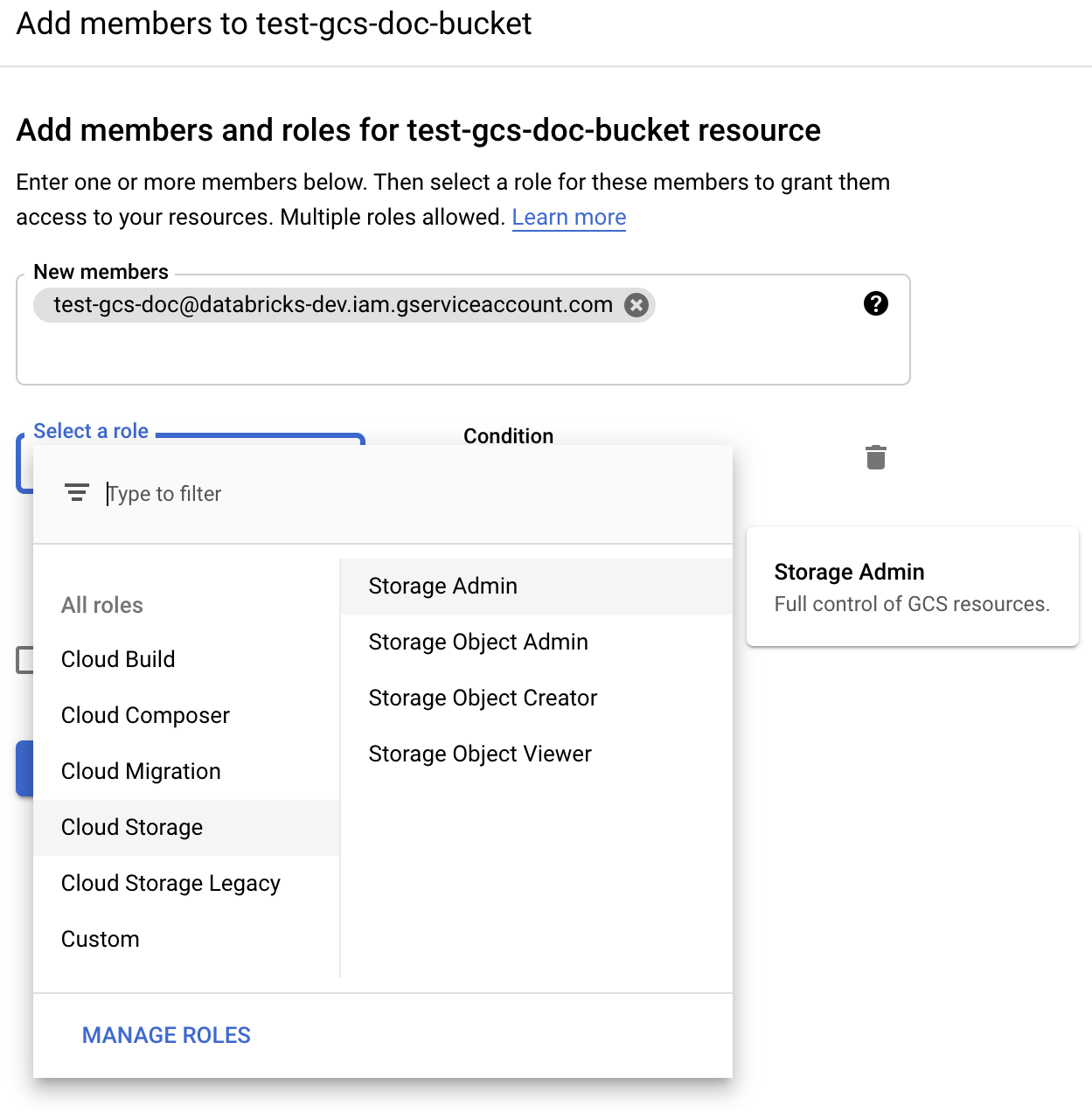
Kattintson a SAVE (Mentés) gombra.
4. lépés: A szolgáltatásfiók kulcsának elhelyezése a Databricks titkos kulcsaiban
A Databricks titkos hatókörök használatát javasolja az összes hitelesítő adat tárolására. A titkos kulcs és a titkos kulcs azonosítója a kulcs JSON-fájljából a Databricks titkos hatóköreibe helyezhető. Hozzáférést adhat a munkaterület felhasználóinak, szolgáltatásneveinek és csoportjainak a titkos kulcsok hatóköreinek olvasásához. Ez védi a szolgáltatásfiók kulcsát, miközben a felhasználók hozzáférhetnek a GCS-hez. Titkos kulcsok hatókörének létrehozásához lásd a Titkos kódok kezelése című témakört.
5. lépés: Azure Databricks-fürt konfigurálása
A Spark Config lapon konfiguráljon globális vagy gyűjtőnkénti konfigurációt. Az alábbi példák a Databricks-titkos kulcsokként tárolt értékek használatával állítják be a kulcsokat.
Feljegyzés
A fürthozzáférés-vezérlés és a jegyzetfüzet-hozzáférés-vezérlés együttes használata a szolgáltatásfiókhoz és a GCS-gyűjtőben lévő adatokhoz való hozzáférés védelméhez. Lásd: Számítási engedélyek és együttműködés a Databricks-jegyzetfüzetekkel.
Globális konfiguráció
Ezt a konfigurációt akkor használja, ha a megadott hitelesítő adatokat kell használni az összes gyűjtő eléréséhez.
spark.hadoop.google.cloud.auth.service.account.enable true
spark.hadoop.fs.gs.auth.service.account.email <client-email>
spark.hadoop.fs.gs.project.id <project-id>
spark.hadoop.fs.gs.auth.service.account.private.key {{secrets/scope/gsa_private_key}}
spark.hadoop.fs.gs.auth.service.account.private.key.id {{secrets/scope/gsa_private_key_id}}
<client-email> Cserélje le <project-id>a helyére a kulcs JSON-fájlban szereplő pontos mezőnevek értékeit.
Gyűjtőnkénti konfiguráció
Ezt a konfigurációt akkor használja, ha az adott gyűjtők hitelesítő adatait kell konfigurálnia. A gyűjtőnkénti konfiguráció szintaxisa hozzáfűzi a gyűjtő nevét az egyes konfigurációk végéhez, ahogyan az alábbi példában is látható.
Fontos
Gyűjtőnkénti konfigurációk a globális konfigurációk mellett használhatók. Ha meg van adva, a gyűjtőnkénti konfigurációk felülírják a globális konfigurációkat.
spark.hadoop.google.cloud.auth.service.account.enable.<bucket-name> true
spark.hadoop.fs.gs.auth.service.account.email.<bucket-name> <client-email>
spark.hadoop.fs.gs.project.id.<bucket-name> <project-id>
spark.hadoop.fs.gs.auth.service.account.private.key.<bucket-name> {{secrets/scope/gsa_private_key}}
spark.hadoop.fs.gs.auth.service.account.private.key.id.<bucket-name> {{secrets/scope/gsa_private_key_id}}
<client-email> Cserélje le <project-id>a helyére a kulcs JSON-fájlban szereplő pontos mezőnevek értékeit.
6. lépés: Olvasás a GCS-ből
Ha a GCS-gyűjtőből szeretne olvasni, használjon spark olvasási parancsot bármilyen támogatott formátumban, például:
df = spark.read.format("parquet").load("gs://<bucket-name>/<path>")
Ha a GCS-gyűjtőbe szeretne írni, használjon Spark-írási parancsot bármilyen támogatott formátumban, például:
df.write.mode("<mode>").save("gs://<bucket-name>/<path>")
Cserélje le <bucket-name> a 3. lépésben létrehozott gyűjtő nevére: A GCS-gyűjtő konfigurálása.