Megjegyzés
Az oldalhoz való hozzáféréshez engedély szükséges. Megpróbálhat bejelentkezni vagy módosítani a címtárat.
Az oldalhoz való hozzáféréshez engedély szükséges. Megpróbálhatja módosítani a címtárat.
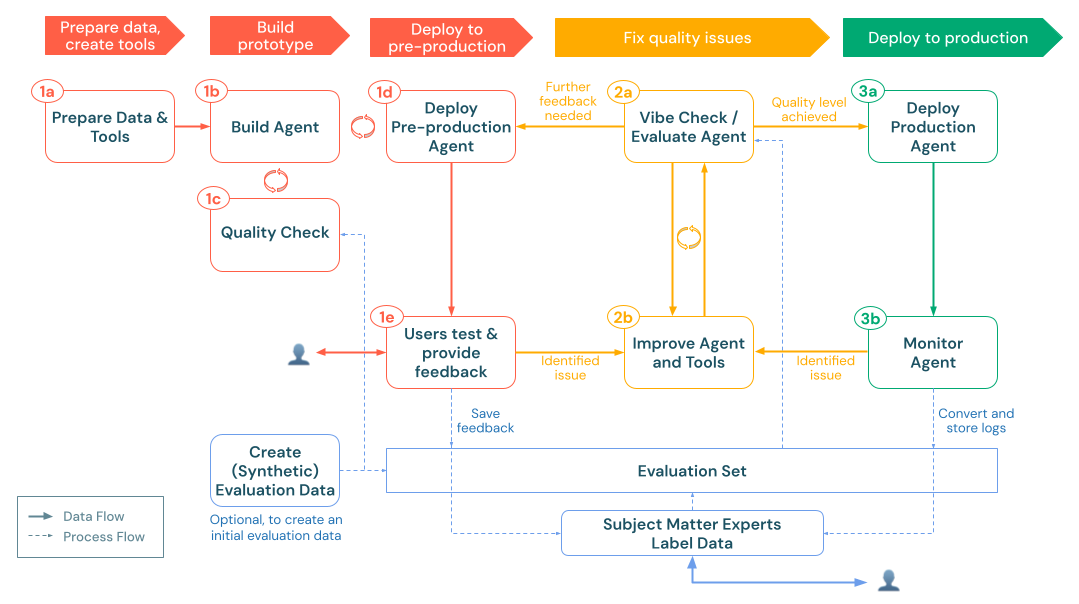
Egy robusztus generatív AI-alkalmazás (gen AI-alkalmazás) fejlesztéséhez szándékos tervezésre, gyors fejlesztés-visszajelzés-kiértékelési ciklusra és skálázható éles infrastruktúrára van szükség. Ez a munkafolyamat egy ajánlott lépéssort vázol fel, amely a kezdeti megvalósíthatósági igazolástól (POC) az éles üzembe helyezésig vezeti végig.
- Gyűjtse össze a gen AI-hez való illeszkedés ellenőrzésére és a korlátozások azonosítására vonatkozó követelményeket.
- Tervezheti meg a megoldásarchitektúrát. Az ügynökrendszer tervezési mintáinak megtekintése
Készítse el 1.
- Adatforrások előkészítése és a szükséges eszközök létrehozása.
- A kezdeti prototípus (POC) létrehozása és ellenőrzése.
- Telepítés a tesztkörnyezetbe.
2. & Ismétlés kiértékelése
- Felhasználói visszajelzések gyűjtése és a minőség mérése
- Minőségi problémák megoldása az ügynöklogika és az eszközök kiértékelése alapján történő finomításával.
- A tárgyszakértői (SME- ) bemenet beépítése az ügynökrendszer minőségének folyamatos javítása érdekében.
- Helyezze üzembe a gen AI-alkalmazást éles környezetben.
- Monitorozza a teljesítményt és a minőséget.
- A valós használat alapján karbantarthat és fejlesztheti azokat.
Ennek a munkafolyamatnak iteratívnak kell lennie: minden üzembe helyezési vagy értékelési ciklus után térjen vissza a korábbi lépésekhez az adatfolyamok finomításához vagy az ügynöklogika frissítéséhez. A termelés monitorozása például új követelményeket tárhat fel, amelyek módosításokat idézhetnek elő a rendszer tervezésében és egy újabb értékelési fordulóban. Az alábbi lépések szisztematikus követésével és a Databricks MLflow nyomkövetési, ügynök-keretrendszeri és ügynökértékelési képességeinek kihasználásával kiváló minőségű, a felhasználói igényeknek megbízhatóan megfelelő AI-alkalmazásokat hozhat létre, tiszteletben tarthatja a biztonsági és megfelelőségi követelményeket, és az idő múlásával tovább fejleszthet.
0. Előfeltételek
Mielőtt hozzálát a gen AI-alkalmazás fejlesztéséhez, nem lehet túlzásba vinni, hogy mennyire fontos, hogy az alábbiakat megfelelően végezze el: a követelmények összegyűjtése és a megoldástervezés.
Követelmények összegyűjtése a következő lépéseket tartalmazza:
- Ellenőrizze, hogy a gen AI megfelel-e a használati esetnek.
- Határozza meg a felhasználói élményt.
- Adatforrások hatókörének meghatározása.
- Teljesítménykorlátozások beállítása.
- Biztonsági korlátozások rögzítése.
megoldástervezési a következőket tartalmazza:
- Adatfolyamok leképezése.
- Azonosítsa a szükséges eszközöket.
- Vázolja fel az általános rendszerarchitektúrát.
Ennek az alapnak a lefektetésével egyértelmű irányt állíthat be a következő Építés, Kiértékelésés Gyártás fázisokhoz.
adatgyűjtési követelmények
Az egyértelmű és átfogó használati esetkövetelmények meghatározása kritikus fontosságú első lépés a sikeres gen AI-alkalmazás fejlesztésében. Ezek a követelmények a következő célokat szolgálják:
- Segítenek meghatározni, hogy a gen AI-megközelítés megfelelő-e a használati esethez.
- Útmutatást adnak a megoldások tervezésével, megvalósításával és értékelésével kapcsolatos döntésekhez.
A részletes követelmények összegyűjtésére fordított idő a fejlesztési folyamat későbbi szakaszaiban megelőzheti a jelentős kihívásokat, és biztosíthatja, hogy az eredményül kapott megoldás megfeleljen a végfelhasználók és az érdekelt felek igényeinek. A jól meghatározott követelmények biztosítják az alkalmazás életciklusának későbbi szakaszainak alapjait.
Alkalmas a használati eset a generatív mesterséges intelligenciára?
Mielőtt véglegesíteni szeretne egy gen AI-megoldást, gondolja át, hogy a benne rejlő erősségei összhangban vannak-e a követelményekkel. Néhány példa, ahol egy generatív AI-megoldás jó illeszkedés:
- Tartalomlétrehozás: A feladathoz olyan új vagy kreatív tartalmakat kell létrehozni, amelyek statikus sablonokkal vagy egyszerű szabályalapú logikával nem érhetők el.
- Dinamikus lekérdezéskezelés: A felhasználói lekérdezések nyitott vagy összetettek, és rugalmas, környezettudatos válaszokat igényelnek.
- Információszintézis: A használati eset előnye, hogy különböző információforrásokat egyesít vagy összesít egy koherens kimenet létrehozásához.
-
Ügynökrendszerek: Az alkalmazásnak nem csupán szöveg generálására van szüksége egy üzenetre válaszul. Lehetséges, hogy képesnek kell lennie a következőkre:
- Tervezés és döntéshozatal: Többlépéses stratégia kidolgozása egy adott cél eléréséhez.
- Műveletek végrehajtása: Külső folyamatok aktiválása vagy különböző eszközök meghívása feladatok végrehajtásához (például adatok lekérése, API-hívások indítása, SQL-lekérdezések futtatása, kód végrehajtása).
- Állapot fenntartása: A folyamatosság érdekében több interakcióban nyomon követheti a beszélgetések előzményeit vagy tevékenységkörnyezetét.
- Adaptív kimenetek létrehozása: A korábbi műveletek, frissített információk vagy változó feltételek alapján változó válaszok létrehozása.
Ezzel szemben előfordulhat, hogy a gen AI-megközelítés nem ideális a következő helyzetekben:
- A feladat rendkívül determinisztikus, és hatékonyan megoldható előre definiált sablonokkal vagy szabályalapú rendszerekkel.
- A szükséges információk teljes készlete már statikus, vagy egy egyszerű, zárt keretrendszerbe illeszkedik.
- Rendkívül alacsony késleltetésű (ezredmásodperc) válaszokra van szükség, és a generatív feldolgozás többletterhelése nem fogadható el.
- Az egyszerű, sablonalapú válaszok elegendőek a kívánt használati esethez.
Fontos
Az alábbi szakaszok a P0 , P1és P2 címkéket használják a relatív prioritás jelzéséhez.
- 🟢 [P0] elemek kritikus fontosságúak vagy alapvető fontosságúak. Ezeket azonnal meg kell oldani.
- 🟡 [P1] elemek fontosak, de P0 követelményeit követik.
- ⚪ [P2] elemek olyan alacsonyabb prioritású szempontok vagy fejlesztések, amelyeket idő és erőforrások lehetővé tehetnek.
Ezek a címkék segítenek a csapatoknak gyorsan látni, hogy mely követelményekre kell azonnali figyelmet fordítani, és melyiket lehet elhalasztani.
Felhasználói élmény
Határozza meg, hogy a felhasználók hogyan fogják használni a gen AI-alkalmazást, és hogy milyen típusú válaszok várhatók.
- 🟢 [P0] Tipikus kérés: Hogyan fog kinézni egy tipikus felhasználói kérés? Gyűjtsön példákat az érdekelt felektől.
- 🟢 [P0] Várt válaszok: Milyen típusú válaszokat hozzon létre a rendszer (például rövid válaszokat, hosszú formátumú magyarázatokat, kreatív elbeszéléseket)?
- 🟡 [P1] Interakciós mód: Hogyan használják a felhasználók az alkalmazást (például csevegőfelület, keresősáv, hangsegéd)?
- 🟡 [P1] Hang, stílus, struktúra: Milyen hangnemet, stílust és struktúrát kell alkalmaznia a generált kimeneteknek (formális, beszélgetési, technikai, felsorolási pontok vagy folyamatos próza)?
- 🟡 [P1]Hibakezelés: Hogyan kezelje az alkalmazás a nem egyértelmű, hiányos vagy nem célzott lekérdezéseket? Küldjön visszajelzést, vagy kérjen pontosítást?
- ⚪ [P2] Formázási követelmények: Vannak a kimenetekre vonatkozó formázási vagy megjelenítési irányelvek (beleértve a metaadatokat vagy a kiegészítő információkat)?
Adat
Határozza meg a gen AI-alkalmazásban használt adatok jellegét, forrását és minőségét.
-
🟢
[P0] Adatforrások: Milyen adatforrások érhetők el?
- Minden forrás esetében határozza meg a következőket:
- Strukturált vagy strukturálatlan az adat?
- Mi a forrásformátum (például PDF, HTML, JSON, XML)?
- Hol találhatók az adatok?
- Mennyi adat érhető el?
- Hogyan kell hozzáférni az adatokhoz?
- Minden forrás esetében határozza meg a következőket:
- 🟡 [P1] Adatfrissítések: Milyen gyakran frissülnek az adatok? Milyen mechanizmusok léteznek a frissítések kezelésére?
-
🟡
[P1] Adatminőség: Vannak ismert minőségi problémák vagy inkonzisztenciák?
- Fontolja meg, hogy szükség lesz-e minőségi monitorozásra az adatforrásokon.
Érdemes lehet létrehozni egy leltártáblát, amely összevonja ezeket az információkat, például:
| Adatforrás | Forrás | Fájltípus(ok) | Méret | Frissítés gyakorisága |
|---|---|---|---|---|
| Adatforrás 1 | Unity Catalog-kötet | JSON | 10 GB | Mindennapi |
| Adatforrás 2 | Nyilvános API | XML | NA (API) | Valós idejű |
| Adatforrás 3 | SharePoint | PDF, .docx | 500 MB | Havi |
Teljesítménykorlátozások
Rögzítse a generatív AI alkalmazás teljesítmény- és erőforráskövetelményeit.
késleltetés
-
🟢
[P0] Idő az első tokenig: Mi a maximálisan elfogadható késleltetés a kimenet első tokenjének kézbesítése előtt?
- Megjegyzés: a késést általában p50 (medián) és p95 (95. percentilis) használatával mérik az átlagos és a legrosszabb eseti teljesítmény rögzítéséhez.
- 🟢 [P0] Befejezési idő: Mi a felhasználók számára elfogadható (befejezési idő) válaszidő?
- 🟢 [P0] Streamelési késés: Ha a válaszok streamelve vannak, elfogadható a nagyobb általános késés?
Méretezhetőség
-
🟡
[P1]Egyidejű felhasználók & kéréseket: Hány egyidejű felhasználót vagy kérést támogat a rendszer?
- Megjegyzés: A méretezhetőséget gyakran a QPS (másodpercenkénti lekérdezések) vagy a QPM (percenkénti lekérdezések) alapján mérik.
- 🟡 [P1] Használati minták: Melyek a várt forgalmi minták, a csúcsterhelések vagy az időalapú használati csúcsok?
költségkorlátok
- 🟢 [P0] Következtetési költségkorlátozások: Mik a számítási erőforrásokra vonatkozó költségkorlátok vagy költségvetési korlátozások?
Értékelés
Annak megállapítása, hogy a gen AI-alkalmazás hogyan lesz kiértékelve és továbbfejlesztve az idő múlásával.
- 🟢 [P0] Üzleti KPI-k: Melyik üzleti célra vagy KPI-re legyen hatással az alkalmazás? Határozza meg az alapértékeket és a célokat.
- 🟢 [P0] Az érdekelt felek visszajelzési: Ki ad kezdeti és folyamatos visszajelzést az alkalmazások teljesítményéről és kimenetéről? Meghatározott felhasználói csoportok vagy tartományi szakértők azonosítása.
-
🟢
[P0] Minőségimérése: Milyen metrikákat (például pontosságot, relevanciát, biztonságot, emberi pontszámokat) használunk a generált kimenetek minőségének értékeléséhez?
- Hogyan lesznek kiszámítva ezek a metrikák a fejlesztés során (például szintetikus adatokkal, manuálisan válogatott adathalmazokkal)?
- Hogyan mérik a minőséget az éles környezetben (például a valós felhasználói lekérdezésekre adott válaszok naplózását és elemzését)?
- Mi az általános hibatűrés? (például elfogadhatja a kisebb ténybeli pontatlanságok bizonyos százalékát, vagy közel 100% helyességet követelhet meg a kritikus használati esetekhez.)
- A cél a tényleges felhasználói lekérdezésekből, szintetikus adatokból vagy a kettő kombinációjából álló kiértékelési csoport létrehozása. Ez a készlet konzisztens módot biztosít a rendszer fejlődésével kapcsolatos teljesítmény értékelésére.
-
🟡
[P1] Visszajelzési ciklusok: Hogyan kell összegyűjteni a felhasználói visszajelzéseket (például hüvelykujj fel/le, felmérési űrlapok), és hogyan kell használni az iteratív fejlesztések javítására?
- Tervezze meg, hogy milyen gyakran lesznek áttekintve és beépítve a visszajelzések.
Biztonság
Azonosítsa a biztonsági és adatvédelmi szempontokat.
- 🟢 [P0] Adatérzékenység: Vannak-e különleges kezelést igénylő bizalmas vagy bizalmas adatelemek?
- 🟡 [P1] Hozzáférés-vezérlők: Szükség van hozzáférési vezérlők implementálására bizonyos adatok vagy funkciók korlátozásához?
- 🟡 [P1] Veszélyforrások felmérése & kockázatcsökkentés: Az alkalmazásnak védelmet kell nyújtania a gyakori, mesterséges intelligenciával kapcsolatos fenyegetések, például a gyors injektálás vagy a rosszindulatú felhasználói bemenetek ellen?
Telepítés
Ismerje meg, hogy a gen AI-megoldás hogyan lesz integrálva, üzembe helyezve, figyelve és karbantartva.
-
🟡
[P1] Integráció: Hogyan integrálható a gen AI-megoldás a meglévő rendszerekkel és munkafolyamatokkal?
- Azonosítsa az integrációs pontokat (például Slack, CRM, BI-eszközök) és a szükséges adatösszekötőket.
- Annak meghatározása, hogy a kérések és válaszok hogyan fognak áramlani a gen AI-alkalmazás és az alárendelt rendszerek (például REST API-k, webhookok) között.
- 🟡 [P1] Üzembe helyezés: Milyen követelmények vonatkoznak az alkalmazás üzembe helyezésére, skálázására és verziószámozására? Ez a cikk bemutatja, hogyan kezelhető a teljes életciklus a Databricksben az MLflow, a Unity Catalog, ügynöki keretrendszer, ügynökértékelésés modellkiszolgálás használatával.
-
🟡
[P1] Gyártási környezet monitorozása & áttekinthetőség: Hogyan fogja figyelni az alkalmazást, ha a gyártási környezetben van?
- & nyomkövetés naplózása: Teljes végrehajtási folyamatok rögzítése.
- Minőségi metrikák: Az élő forgalom fő mérőszámainak (például helyesség, késés, relevancia) folyamatos kiértékelése.
- Állítsa be a riasztásokat a & irányítópultokon: Állítson be értesítéseket kritikus problémák esetén.
- Visszajelzési ciklus: A felhasználói visszajelzések beépítése gyakorlatban (tetszés vagy nemtetszés) a problémák korai észleléséhez és az iteratív fejlesztésekhez.
Példa
Példaként tekintse át, hogyan vonatkoznak ezek a szempontok és követelmények a Databricks ügyfélszolgálati csapata által használt feltételezett ügynöki RAG-alkalmazásokra:
| Terület | Megfontolások | Követelmények |
|---|---|---|
| Felhasználói élmény |
|
|
| Ügynöklogika |
|
|
| Adat |
|
|
| Teljesítmény |
|
|
| Értékelés |
|
|
| Biztonság |
|
|
| Telepítés |
|
|
Megoldástervezés
További tervezési szempontokért tekintse meg az ügynökrendszer tervezési mintáit.
Adatforrások & eszközök
A gen AI-alkalmazások tervezésekor fontos azonosítani és leképezni a megoldáshoz szükséges különböző adatforrásokat és eszközöket. Ezek lehetnek strukturált adathalmazok, strukturálatlan adatfeldolgozási folyamatok vagy külső API-k lekérdezése. Az alábbiakban a különböző adatforrások vagy eszközök a gen AI-alkalmazásba való beépítéséhez ajánlott módszereket találja:
Strukturált adatok
A strukturált adatok általában jól definiált, táblázatos formátumban (például Delta-tábla vagy CSV-fájl) találhatók, és ideálisak olyan feladatokhoz, ahol a lekérdezések előre vannak meghatározva, vagy dinamikusan kell generálni a felhasználói bemenet alapján. Kérjük, tekintse meg a Strukturált lekérdezés AI-ügynök eszközei dokumentációt a strukturált adatok generált AI-alkalmazáshoz való hozzáadására vonatkozó javaslatokért.
Strukturálatlan adatok
A strukturálatlan adatok közé tartoznak a nyers dokumentumok, PDF-fájlok, e-mailek, képek és egyéb formátumok, amelyek nem felelnek meg a rögzített sémának. Az ilyen adatok további feldolgozást igényelnek, általában elemzések, adattömbök és beágyazások kombinációjával, hogy hatékonyan lekérdezhetők és felhasználhatók legyenek a gen AI-alkalmazásokban. Lásd a strukturálatlan adatok felépítési és nyomon követési eszközeit a strukturált adatok gen AI-alkalmazáshoz való hozzáadásával kapcsolatos javaslatokért.
Külső API-k & műveletek
Bizonyos esetekben előfordulhat, hogy a gen AI-alkalmazásnak külső rendszerekkel kell együttműködnie az adatok lekéréséhez vagy műveletek végrehajtásához. Azokban az esetekben, amikor az alkalmazáshoz invokáló eszközökre vagy külső API-kra van szükség, a következőket javasoljuk:
- API-hitelesítő adatok kezelése egy Unity Catalog-kapcsolattal: Az API-hitelesítő adatok biztonságos szabályozásához unitykatalógus-kapcsolat használata. Ez a módszer biztosítja, hogy a tokenek és titkos adatok központilag legyenek felügyelve és hozzáférés-vezérléssel szabályozva.
-
Meghívás a Databricks SDK használatával:
HTTP-kérések küldése külső szolgáltatásoknak ahttp_requestfüggvény használatával adatabricks-sdkkönyvtárból. Ez a függvény egy Unity Catalog-kapcsolatot használ a hitelesítéshez, és támogatja a szabványos HTTP-metódusokat. -
A Unity Catalog funkciókhasználata:
Külső kapcsolatok beágyazása Unity Catalog-függvénybe egyéni elő- vagy utófeldolgozási logika hozzáadásához. -
Python-végrehajtó eszköz:
Az adatátalakítások vagy API-interakciók kódjának Python-függvényekkel történő dinamikus végrehajtásához használja a beépített Python-végrehajtó eszközt.
példa:
Egy belső elemzési alkalmazás élő piaci adatokat kér le egy külső pénzügyi API-ból. Az alkalmazás a következőket használja:
- Unity Catalog külső kapcsolat az API hitelesítő adatainak biztonságos tárolásához.
- Egy egyéni Unity Catalog-függvény becsomagolja az API-hívást, amely előfeldolgozást (például adat normalizálást) és utófeldolgozást (például hibakezelést) ad hozzá.
- Ezenkívül az alkalmazás közvetlenül meghívhatja az API-t a Databricks SDKkeresztül.
Megvalósítási megközelítés
A gen AI-alkalmazások fejlesztésekor két fő lehetősége van az ügynök logikájának implementálására: nyílt forráskódú keretrendszer használata vagy egyéni megoldás létrehozása Python-kóddal. Az alábbiakban az egyes megközelítések előnyeinek és hátrányainak részletezése látható.
Keretrendszer használata (például LangChain, LlamaIndex, CrewAI vagy AutoGen)
előnyei:
- beépített összetevők: keretrendszerek kész eszközökkel állnak a gyors kezeléshez, a hívások láncolásához és a különböző adatforrásokkal való integrációhoz, ami felgyorsíthatja a fejlesztést.
- közösség és dokumentáció: Közösségi támogatás, oktatóanyagok és rendszeres frissítések.
- Gyakori tervezési minták: a keretrendszerek általában világos, moduláris struktúrát biztosítanak a gyakori feladatok vezénylése érdekében, ami leegyszerűsítheti az ügynök általános kialakítását.
hátrányok:
- Hozzáadott absztrakció: nyílt forráskódú keretrendszerek gyakran olyan absztrakciós rétegeket vezetnek be, amelyek szükségtelenek lehetnek az adott használati esethez.
- Frissítések függősége: Előfordulhat, hogy a keretrendszer karbantartóitól függ a hibajavítások és a funkciófrissítések, ami lelassíthatja az új követelményekhez való gyors alkalmazkodást.
- Lehetséges többletterhelés: Extra absztrakció testreszabási kihívásokhoz vezethet, ha az alkalmazás finomabb szabályozást igényel.
Tiszta Python használata
előnyei:
- Rugalmasság: A tiszta Pythonban való fejlesztés lehetővé teszi, hogy a megvalósítást pontosan az igényeihez szabja anélkül, hogy a keretrendszer tervezési döntései korlátozva lenne.
- Gyors adaptáció: Gyorsan módosíthatja a kódot, és szükség szerint beépítheti a módosításokat anélkül, hogy külső keretrendszer frissítésére kellene várnia.
- Egyszerűség: Kerülje a szükségtelen absztrakciós rétegeket, ami egy karcsúbb, hatékonyabb megoldást eredményezhet.
hátrányok:
- nagyobb fejlesztési erőfeszítések: Az alapoktól való építés több időt és szakértelmet igényelhet a dedikált keretrendszer által egyébként biztosított funkciók implementálásához.
- A kerék újra feltalálása: Előfordulhat, hogy önállóan kell fejlesztenie a közös funkciókat (például a szerszámláncolást vagy a gyorskezelést).
- Karbantartási felelősség: Minden frissítés és hibajavítás az Ön feladata lesz, ami összetett rendszerek esetén kihívást jelenthet.
Végső soron a döntést a projekt összetettségének, teljesítményigényének és a szükséges szabályozási szintnek kell vezérelnie. Egyik megközelítés sem eredendően felsőbbrendű; mindegyik különböző előnyöket kínál a fejlesztési preferenciáktól és a stratégiai prioritásoktól függően.
1. Épít
Ebben a szakaszban a megoldástervet egy működő generációs AI-alkalmazássá alakíthatja át. Ahelyett, hogy mindent előre tökéletesítenének, kezdjen kicsivel egy minimális megvalósíthatósági ellenőrzéssel (POC), amely gyorsan tesztelhető. Ez lehetővé teszi, hogy a lehető leghamarabb üzembe helyezhesse az éles üzem előtti környezetet, reprezentatív lekérdezéseket gyűjthet a tényleges felhasználóktól vagy kkv-któl, és a valós visszajelzések alapján finomíthat.
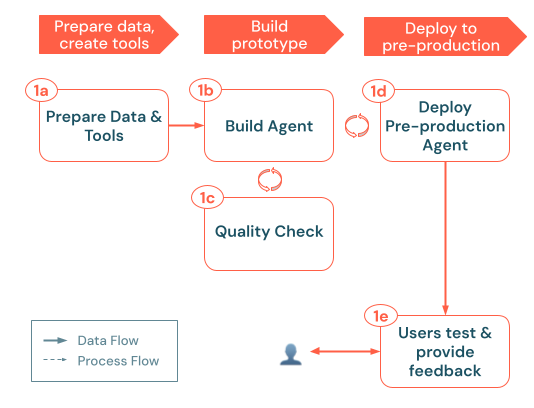
A buildelési folyamat az alábbi fő lépéseket követi:
a). Adatok előkészítése & eszközök: Győződjön meg arról, hogy a szükséges adatok elérhetők, elemezhetők és lekérésre készek. Implementálja vagy regisztrálja a Unity Catalog funkcióit és kapcsolatait (például lekéréses API-kat vagy külső API-hívásokat), amelyekre az ügynöknek szüksége lesz. b. Buildképviselő: Az alapvető logika irányítása egy egyszerű POC (Proof of Concept) módszerrel kezdve. c) Minőség-ellenőrzés: Ellenőrizze az alapvető funkciókat, mielőtt több felhasználónak kiteené az alkalmazást. d. Előzetes ügynök üzembe helyezése: Tegye elérhetővé a POC-t a tesztfelhasználók és a témaszakértők számára a kezdeti visszajelzések megszerzésére. e. Felhasználói visszajelzések összegyűjtése: Valós használattal azonosíthatja a fejlesztési területeket, a szükséges további adatokat vagy eszközöket, valamint a következő iteráció lehetséges finomításait.
a). Adat-&-eszközök előkészítése
A megoldástervezési fázis alapján kezdeti elképzelése lesz az alkalmazáshoz szükséges adatforrásokról és eszközökről. Ebben a szakaszban tartsa minimálisan: koncentráljon elegendő adatra a POC érvényesítéséhez. Ez biztosítja a gyors iterációt anélkül, hogy jelentős kezdeti befektetésekre lenne szükség bonyolult munkafolyamatokba.
Adat
-
Az adatkészlet reprezentatív részhalmazának azonosítása
- A strukturált adatok esetében válassza ki a kezdeti forgatókönyv szempontjából leginkább releváns kulcstáblákat vagy oszlopokat.
- Strukturálatlan adatok esetében rangsorolja az indexelést csak a reprezentatív dokumentumok egy részhalmaza esetén. Használjon alapszintű adattömb-/beágyazási folyamatot Mozaik AI Vector Search, hogy az ügynök szükség esetén lekérhesse a megfelelő szöveges adattömböket.
-
Adat-hozzáférés beállítása
- Ha külső API-hívások indításához szüksége van az alkalmazásra, a hitelesítő adatokat egy Unity Catalog-kapcsolat használatával biztonságosan tárolhatja.
-
Alapszintű lefedettség ellenőrzése
- Győződjön meg arról, hogy a kiválasztott adathalmaz(ok) megfelelően kezelik a tesztelni kívánt felhasználói lekérdezéseket.
- Mentsen további adatforrásokat vagy összetett átalakításokat a jövőbeli iterációkhoz. A jelenlegi cél az alapvető megvalósíthatóság igazolása és a visszajelzések összegyűjtése.
Eszközök
Az adatforrások beállításával a következő lépés az ügynök által futásidőben meghívandó eszközök implementálása és regisztrálása a Unity Catalogban. Az eszköz egy egyműveletes függvény,, például SQL-lekérdezés vagy külső API-hívás, amelyet az ügynök meghívhat lekérésre, átalakításra vagy műveletre.
adatlekérdezési eszközök
- Korlátozott, strukturált adatlekérdezések: Ha a lekérdezések előre meg vannak határozva, csomagolja őket egy Unity Catalog SQL-függvénybe vagy egy Python UDF-be. Így a logika központosított és felderíthető marad.
- Nyílt végű, strukturált adatlekérdezések: Ha a lekérdezések nyitottabbak, érdemes lehet Genie-tér beállítani a szöveg-SQL-lekérdezések kezeléséhez.
- Strukturálatlan adatsegítő függvények: A Mozaik AI-vektorkeresésben tárolt strukturálatlan adatok esetében hozzon létre egy strukturálatlan adatlekérési eszközt, amelyet az ügynök meghívhat a megfelelő szöveges adattömbök lekéréséhez.
API-hívó eszközök
-
külső API-hívások:API-hívások közvetlenül meghívhatók a Databricks SDK
http_requestmetódusával. - Választható burkolók: Ha elő- vagy utófeldolgozási logikát (például adat normalizálást vagy hibakezelést) kell implementálnia, csomagolja be az API-hívást egy Unity Catalog-függvénybe.
Tartsd minimálisan
- Csak alapvető eszközökkel kezdje: Egyetlen lekérési útvonalra vagy korlátozott API-hívásokra összpontosítson. Iteráláskor továbbiak is hozzáadhatók.
- Interaktív érvényesítés: Tesztelje az egyes eszközöket egymástól függetlenül (például egy jegyzetfüzetben), mielőtt beépítené az ügynökrendszerbe.
Miután elkészültek a prototípus eszközei, folytassa az ügynök létrehozásának folyamatával. Az ügynök ezeket az eszközöket a lekérdezések megválaszolásához, az adatok lekéréséhez és a műveletek szükség szerinti végrehajtásához vezényli.
b. Felépítési ügynök
Miután az adatok és az eszközök elkészültek, létrehozhatja azt az ügynököt, amely válaszol a bejövő kérésekre, például a felhasználói lekérdezésekre. Kezdeti prototípus-ügynök létrehozásához használjon Python- vagy AI-játszóteret. Kövesse az alábbi lépéseket:
-
Egyszerűen kezdje el
-
Válasszon egy alapszintű tervezési mintát: A POC-hez alapszintű lánccal (például rögzített lépések sorozatával) vagy egyetlen eszközhívó ügynökkel kell kezdenie (ahol az LLM dinamikusan meghívhat egy vagy két alapvető eszközt).
- Ha a forgatókönyv megfelel a Databricks dokumentációjában szereplő példajegyzetfüzetek egyikének, akkor ezt a kódot vázként kell módosítania.
- Minimális utasítás: Ezen a ponton állj ellen annak a késztetésnek, hogy túlbonyolítsd az utasításokat. Az utasítások tömörek és közvetlenül relevánsak a kezdeti feladatokhoz.
-
Válasszon egy alapszintű tervezési mintát: A POC-hez alapszintű lánccal (például rögzített lépések sorozatával) vagy egyetlen eszközhívó ügynökkel kell kezdenie (ahol az LLM dinamikusan meghívhat egy vagy két alapvető eszközt).
-
Eszközök beépítése
-
Eszközintegráció: Lánctervezési minta használata esetén az egyes eszközöket meghívó lépések fixen a kódba lesznek ágyazva. Egy eszközhívó ügynökben megad egy sémát, hogy az LLM tudja, hogyan hívhatja meg a függvényt.
- Ellenőrizze, hogy az izolált eszközök a várt módon működnek-e, mielőtt beépítené őket az ügynökrendszerbe, és végrehajtja a teljes körű tesztelést.
- Védőkorlátok: Ha az ügynök képes külső rendszerek módosítására vagy kód futtatására, győződjön meg arról, hogy rendelkezik alapvető biztonsági ellenőrzésekkel és védőkorlátokkal (például a hívások számának korlátozásával vagy bizonyos műveletek korlátozásával). Implementálja ezeket egy Unity Catalog-függvényben.
-
Eszközintegráció: Lánctervezési minta használata esetén az egyes eszközöket meghívó lépések fixen a kódba lesznek ágyazva. Egy eszközhívó ügynökben megad egy sémát, hogy az LLM tudja, hogyan hívhatja meg a függvényt.
-
Kövesd nyomon és naplózd az ügynököt MLflow-val
- Minden lépés nyomon követése:MLflow-nyomkövetési használatával rögzítheti a lépésenkénti bemeneteket, kimeneteket és eltelt időt a hibák hibakereséséhez és a teljesítmény méréséhez.
- Naplózza az ügynököt: Az MLflow Tracking használatával naplózza az ügynök kódját és konfigurációját.
Ebben a szakaszban tökéletesség nem a cél. Egy egyszerű, működő ügynököt szeretne, amelyet üzembe helyezhet a tesztfelhasználók és a kkv-k korai visszajelzéseihez. A következő lépés egy gyors minőségi ellenőrzés futtatása, mielőtt tesztkörnyezetben elérhetővé tenné.
c) Minőség-ellenőrzés
Mielőtt elérhetővé tenné az ügynököt a szélesebb tesztelési közönség számára, offline futtasson egy úgynevezett "elég jó" minőségellenőrzést, hogy észlelhesse a főbb problémákat, mielőtt üzembe helyezné azt egy végponton. Ebben a szakaszban általában nem rendelkezik nagy, robusztus kiértékelési adatkészlettel, de még mindig gyorsan ellenőrizheti, hogy az ügynök a kívánt módon viselkedjen egy maroknyi mintalekérdezéseken.
-
Interaktív tesztelés jegyzetfüzetben
- manuális ellenőrzés: Manuálisan hívja meg az ügynököt reprezentatív kérésekkel. Figyelje meg, hogy a megfelelő adatokat kéri-e le, helyesen hívja-e meg az eszközöket, és követi-e a kívánt formátumot.
- MLflow-nyomkövetések vizsgálata: Ha engedélyezte az MLflow-nyomkövetést, tekintse át a részletes telemetriát. Győződjön meg arról, hogy az ügynök a megfelelő eszközt választja, jól kezeli a hibákat, és nem hoz létre váratlan köztes kéréseket vagy eredményeket.
- Késés ellenőrzése: Figyelje meg, hogy mennyi ideig tart az egyes kérések futtatása. Ha a válaszidők vagy a tokenek használata túl magas, előfordulhat, hogy a további lépések elvégzése előtt csökkentenie kell a lépéseket, vagy egyszerűsítenie kell a logikát.
-
Hangulat ellenőrzése
- Ez történhet jegyzetfüzetben vagy AI Playground.
- Koherencia & helyessége: Az ügynök kimenete érthető a tesztelt lekérdezésekhez? Vannak látványos pontatlanságok vagy hiányzó részletek?
- Szélső esetek: Ha kipróbált néhány szokatlan lekérdezést, az ügynök továbbra is logikusan válaszolt, vagy legalább elegánsan elégtelen választ adott (például udvariasan elutasította a választ az értelemtelen válaszadás helyett)?
- Utasítások betartása: Ha magas szintű utasításokat adott meg, például a kívánt hangnemet vagy formázást, az ügynök ezeket követi?
-
Elég jó minőség értékelése
- Ha jelenleg csak teszt lekérdezésekre van korlátozva, fontolja meg a szintetikus adatok előállítását. Lásd: Kiértékelési készlet létrehozása.
- A főbb problémák kezelése: Ha jelentős hibákat észlel (például az ügynök többször is érvénytelen eszközöket vagy kimeneteket hív meg nonszensznek), javítsa ki ezeket a problémákat, mielőtt szélesebb közönségnek teszi ki őket. Tekintse meg gyakori minőségi problémákat, és azok kijavításának módját.
- Döntse el az életképességet: Ha az ügynök megfelel egy egyszerű használhatósági és helyességi sávnak egy kis lekérdezéscsoport esetében, továbbléphet. Ha nem, finomítsa az utasításokat, javítsa ki az eszköz- vagy adatproblémákat, és tesztelje újra.
-
Következő lépések tervezése
- Fejlesztések nyomon követése: Dokumentálja a halasztás mellett elhatározott hiányosságokat. Miután valós visszajelzést gyűjtött az éles üzem előtt, újra áttekintheti ezeket.
Ha minden megfelelőnek tűnik egy korlátozott bevezetéshez, készen áll a program éles üzem előtti telepítésére. Az alapos kiértékelés folyamata a későbbi fázisokbantörténik majd, különösen azután, hogy több valós adat, kis- és középvállalkozói visszajelzés és strukturált kiértékelési készlet áll rendelkezésére. Egyelőre arra koncentráljon, hogy az ügynök megbízhatóan mutassa be az alapvető funkcióit.
d. Tesztelő ügynök üzembe helyezése
Miután az ügynöke megfelel egy alapvető minőségi szintnek, a következő lépés, hogy az alkalmazást egy tesztkörnyezetben helyezze el, hogy megértse, hogyan használják a felhasználók, és gyűjtse össze a visszajelzésüket a fejlesztés irányításához. Ez a környezet lehet a fejlesztési környezet a POC-fázisban. A fő követelmény az, hogy a környezet elérhető legyen belső tesztelők vagy tartományi szakértők kiválasztásához.
-
Az ügynök üzembe helyezése
- Naplózza és regisztrálja az ügynököt: Először MLflow-modellként naplózza az ügynököt, és regisztrálja a Unity Katalógusban.
- Üzembe helyezés az Agent Framework használatával: Az Ügynök keretrendszerrel vegye a regisztrált ügynököt, és helyezze üzembe mint egy modell kiszolgáló végpontot.
-
Következtetéstáblák
- Az Ügynök-keretrendszer automatikusan tárolja a kéréseket, válaszokat és nyomkövetéseket, valamint a metaadatokat a nyomkövetési kiszolgálón a Unity Katalógusban minden egyes kiszolgálóvégponthoz.
-
Biztosítsd és konfiguráld
- Hozzáférés-vezérlés:A tesztcsoporthoz (kkv-k, energiafelhasználók) való végponthozzáférés korlátozása. Ez biztosítja a szabályozott használatot, és elkerüli a váratlan adatexpozíciót.
- Hitelesítési: Ellenőrizze, hogy a szükséges titkos kulcsok, API-jogkivonatok vagy adatbázis-kapcsolatok megfelelően vannak-e konfigurálva.
Mostantól ellenőrzött környezettel rendelkezik a valós lekérdezésekkel kapcsolatos visszajelzések gyűjtéséhez. Az ügynökkel való gyors interakció egyik módja az AI Playground, ahol kiválaszthatja az újonnan létrehozott modellkiszolgáló végpontot, és lekérdezheti az ügynököt.
e. Felhasználói visszajelzések gyűjtése
Miután üzembe helyezte az ügynököt egy éles üzem előtti környezetben, a következő lépés a valós felhasználóktól és a kkv-któl érkező visszajelzések összegyűjtése a hiányosságok feltárásához, a pontatlanságok feltárásához és az ügynök további finomításához.
Használja az értékelő alkalmazást
- Amikor egy ügynököt az Agent Framework használatával telepít, egy egyszerű, csevegési stílusú Ellenőrző alkalmazás jön létre. Felhasználóbarát felületet biztosít, ahol a tesztelők kérdéseket tehetnek fel, és azonnal értékelhetik az ügynök válaszait.
- A rendszer automatikusan naplózza a Databricks által felügyelt MLflow nyomkövetési kiszolgálóra érkező összes kérést, választ és felhasználói visszajelzést (hüvelykujj fel/le, írott megjegyzések), így később könnyen elemezhető.
Naplók vizsgálata a figyelési felületen
- A felfelé vagy lefelé irányuló szavazatokat, illetve szöveges visszajelzéseket a monitorozási felhasználói felület segítségével követheti nyomon, hogy lássa, mely válaszok bizonyultak a tesztelők számára különösen hasznosnak (vagy nem hasznosnak).
Tartományi szakértők bevonása
- A kkv-k ösztönzése a tipikus és szokatlan forgatókönyvek végigfuttatására. A tartományi ismeretek segítenek olyan apró hibák feltárásában, mint a szabályzatok félreértelmezése vagy a hiányzó adatok.
- Tartson fenn egy problémalistát, az interfész finomhangolásoktól a nagyobb adatátviteli folyamat átdolgozásokig. A továbblépés előtt döntse el, hogy mely javításokat kell rangsorolnia.
Új kiértékelési adatok kuratálása
- Jelentős vagy problémás interakciókat konvertálhat tesztesetekké. Idővel ezek egy robusztusabb kiértékelési adatkészlet alapját képezik.
- Ha lehetséges, adjon meg helyes vagy várt választ ezekre az esetekre. Ez segít a minőség mérésében a későbbi kiértékelési ciklusokban.
Ismételjük meg a visszajelzések alapján
- Alkalmazzon gyors javításokat, például kis gyors változtatásokat vagy új védőkorlátokat az azonnali fájdalompontok kezeléséhez.
- Összetettebb problémák, például fejlett többlépéses logika vagy új adatforrások megkövetelése esetén gyűjtsön elegendő bizonyítékot, mielőtt nagyobb architekturális változtatásokba fektet be.
Az előgyártási fázis során, a felülvizsgálati alkalmazás visszajelzéseire, a következtetési táblázatok naplóira, és a szakértői meglátásokra támaszkodva ez a szakasz segít feltárni a kulcsfontosságú hiányosságokat, és folyamatosan finomítja az ügynököt. Az ebben a lépésben összegyűjtött valós interakciók létrehozzák a strukturált értékelési csoportok létrehozásának alapjait, lehetővé téve, hogy az alkalmi fejlesztésekről a minőségi mérés szisztematikusabb megközelítésére váltson. Az ismétlődő problémák kezelése és a teljesítmény stabilizálása után jól felkészülhet egy éles üzembe helyezésre, és hatékony értékelést kap.
2. & iterálás kiértékelése
Miután a gen AI-alkalmazást előtermelési környezetben tesztelték, a következő lépés a minőség szisztematikus mérése, diagnosztizálása és finomítása. Ez a "kiértékelési és iterálási" fázis strukturált kiértékelési készletté alakítja át a nyers visszajelzéseket és naplókat, lehetővé téve a fejlesztések ismételt tesztelését, valamint annak biztosítását, hogy az alkalmazás megfeleljen a pontosság, a relevancia és a biztonság szempontjából szükséges szabványoknak.
Ez a fázis a következő lépéseket tartalmazza:
- Valós lekérdezések összegyűjtése naplókból: A következtetési táblákból származó nagy értékű vagy problémás interakciókat tesztesetekké alakíthatja.
- Szakértői címkék hozzáadása: Ahol lehetséges, csatoljon alapigazságokat vagy stílus- és politikai irányelveket ezekhez az esetekhez, hogy objektívebben mérhesse fel a helyességet, a megalapozottságot és más minőségi dimenziókat.
- Az Ügynök értékelése használata: Beépített LLM-bírók vagy egyéni ellenőrzések alkalmazása az alkalmazások minőségének számszerűsítésére.
- Iterátum: Az ügynök logikájának, adatfolyamainak vagy kéréseinek finomításával javíthatja a minőséget. Futtassa le újra az értékelést, hogy meggyőződhessen arról, megoldotta-e a fő problémákat.
Vegye figyelembe, hogy ezek a képességek akkor is működnek, ha a gen AI-alkalmazás a Databrickskívül fut. A kód MLflow-nyomkövetéssel történő rendszerezésével bármilyen környezetből rögzítheti a nyomkövetéseket, és egységesítheti őket a Databricks adatintelligencia-platformon a konzisztens kiértékelés és monitorozás érdekében. Mivel továbbra is új lekérdezéseket, visszajelzéseket és SME-megállapításokat használ, a kiértékelési adatkészlet egy élő erőforrássá válik, amely a folyamatos fejlesztési ciklus alapjául szolgál, biztosítva, hogy a gen AI-alkalmazás robusztus, megbízható és az üzleti céloknak megfelelő maradjon.
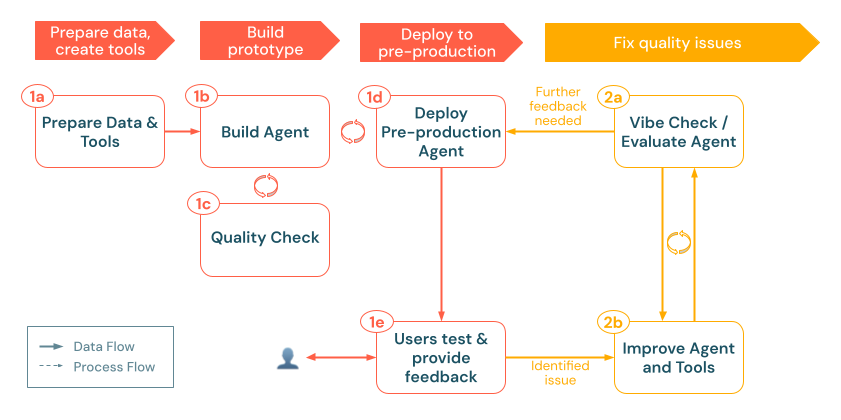
egy. Ügynök kiértékelése
Miután az ügynök teszt környezetben fut, a következő lépés a teljesítmény szisztematikus mérése a rögtönzött ellenőrzéseken túl. Mozaik AI Ügynök Értékelés lehetővé teszi értékelési készletek létrehozását, minőségellenőrzések elvégzését beépített vagy egyéni LLM-bírákkal, és a problémás területeken való gyors iterációt.
Offline és online értékelések
A gen AI-alkalmazások kiértékelésekor két elsődleges megközelítés létezik: az offline értékelés és az online értékelés. A fejlesztési ciklus ezen szakasza az offline értékelésre összpontosít, amely az élő felhasználói interakciókon kívüli szisztematikus értékelésre utal. Az online értékelésről később lesz szó, amikor az ügynök megfigyeléséről beszélünk éles környezetben.
A csapatok gyakran túlzott mértékben támaszkodnak a "hangulattesztelésre" túl hosszú ideig a fejlesztési munkafolyamat során, informálisan kipróbálva néhány lekérdezést, és szubjektíven megítélve, hogy a válaszok ésszerűnek tűnnek-e. Bár ez kiindulópontként szolgál, nem rendelkezik az éles minőségű alkalmazások létrehozásához szükséges szigorúsággal és lefedettséggel.
Ezzel szemben a megfelelő offline kiértékelési folyamat a következőket teszi:
- A szélesebb körű üzembe helyezés előtt létrehoz egy minőségi alapvonalat, amely egyértelmű metrikákat céloz meg a fejlesztéshez.
- Azonosítja azokat a konkrét gyengeségeket, amelyek figyelmet igényelnek, túllépve a tesztelésnek azon a korlátján, hogy csak a várt használati eseteket vizsgálja.
- Észleli a minőségi regressziókat, miközben finomítja az alkalmazást a verziók közötti teljesítmény automatikus összehasonlításával.
- Mennyiségi metrikákat biztosít az érdekelt felek számára történő fejlődés bemutatásához.
- Segít felderíteni a peremhálózati eseteket és a lehetséges meghibásodási módokat a felhasználók előtt.
- Csökkenti egy alulteljesítő ügynök éles környezetbe történő üzembe helyezésének kockázatát.
Az offline értékelésbe való befektetés hosszú távon jelentős osztalékot fizet, így folyamatosan jó minőségű válaszokhoz vezethet.
Kiértékelési csoport létrehozása
Egy értékelési készlet szolgál alapként a gen AI alkalmazás teljesítményének méréséhez. A hagyományos szoftverfejlesztés tesztcsomagjához hasonlóan ez a reprezentatív lekérdezések és várt válaszok gyűjteménye lesz a minőségi teljesítményteszt és a regressziós tesztelési adatkészlet.
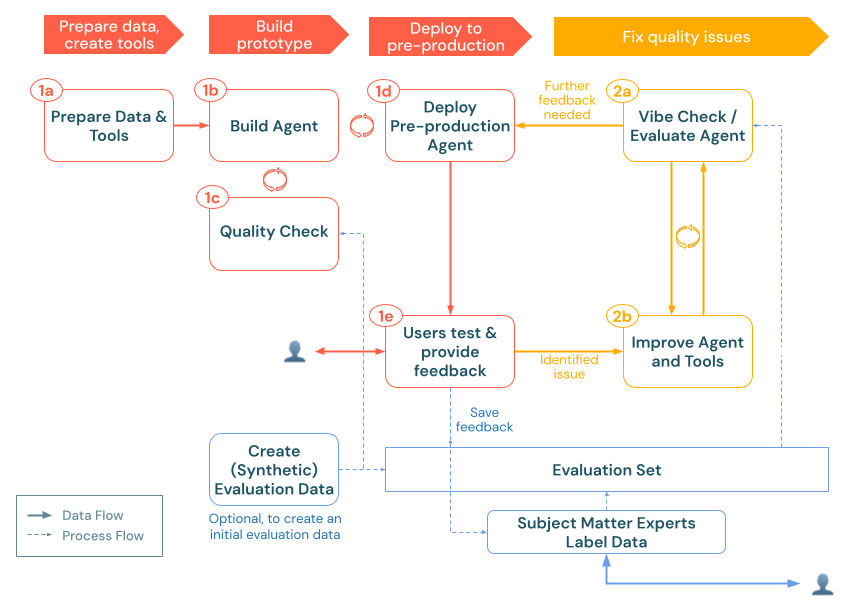
Értékelési halmazt több kiegészítő megközelítések révén is létrehozhatja.
következtetési táblanaplók átalakítása kiértékelési példákká
A legértékesebb kiértékelési adatok közvetlenül a valós használatból származnak. Az előzetes üzembe helyezés következtetési táblanaplókat hozott létre, amelyek kéréseket, ügynöki válaszokat, eszközhívásokat és lekért kontextusösszefüggést tartalmaznak.
A naplók kiértékelési csoporttá alakítása számos előnnyel jár:
- Valós helyzetek lefedettsége: Olyan kiszámíthatatlan felhasználói viselkedések is szerepelnek, amelyekre korábban nem számítottál.
- Problémaközpontú: Szűrhet kifejezetten negatív visszajelzésekre vagy lassú válaszokra.
- Reprezentatív eloszlás: A különböző lekérdezéstípusok tényleges gyakorisága rögzítve van.
Szintetikus kiértékelési adatok létrehozása
Ha nem rendelkezik válogatott felhasználói lekérdezésekkel, automatikusan létrehozhat egy szintetikus kiértékelési adatkészletet. A lekérdezések "kezdőkészlete" segítségével gyorsan felmérheti, hogy az ügynök:
- Koherens, pontos válaszokat ad vissza.
- A megfelelő formátumban válaszol.
- Tiszteletben tartja a struktúrát, a tonalitást és a politikai irányelveket.
- A kontextust helyesen lekéri (RAG esetén).
A szintetikus adatok általában nem tökéletesek. Gondolj rá úgy, mint egy ideiglenes ugródeszka. A következőket is érdemes használnia:
- A kkv-k vagy szakértők tekintsék át és távolítsák el az esetleges irreleváns vagy ismétlődő lekérdezéseket.
- Cserélje le vagy bővítse később valós használati naplókkal.
Lekérdezések manuális gondozása
Ha nem szeretne szintetikus adatokra támaszkodni, vagy még nem rendelkezik következtetési naplókkal, azonosítsa a 10–15 valós vagy reprezentatív lekérdezést, és hozzon létre egy kiértékelési csoportot ezekből. A reprezentatív lekérdezések felhasználói interjúkból vagy fejlesztői ötletgyűjtésből származhatnak. Még egy rövid, válogatott lista is elérhetővé teheti az ügynök válaszaiban megjelenő kirívó hibákat.
Ezek a megközelítések nem egymást kölcsönösen kizárják, hanem kiegészítik egymást. A hatékony kiértékelési csoport idővel fejlődik, és általában több forrásból származó példákat egyesít, többek között a következőket:
- Kezdje manuálisan válogatott példákkal az alapvető funkciók teszteléséhez.
- Ha szeretné, szintetikus adatokat is hozzáadhat a lefedettség kibővítéséhez, mielőtt valódi felhasználói adatokkal rendelkezik.
- Fokozatosan építhet be valós naplókat, amint elérhetővé válnak.
- Folyamatosan frissítsen új példákkal, amelyek tükrözik a változó használati mintákat.
Ajánlott eljárások kiértékelési lekérdezésekhez
A kiértékelési csoport létrehozásakor szándékosan tartalmazzon különböző lekérdezéstípusokat, például a következőket:
- A várt és váratlan használati minták (mint például a nagyon hosszú vagy rövid kérések).
- Lehetséges visszaélési kísérletek vagy prompt injektálási támadások (például a rendszer kimenetének felfedésére tett kísérletek).
- Összetett lekérdezések, amelyek több érvelési lépést vagy eszközhívást igényelnek.
- Peremhálózati esetek minimális vagy nem egyértelmű információkkal (például elírásokkal vagy homályos lekérdezésekkel).
- Példák a felhasználói képességek különböző szintjeire és hátterére.
- Olyan lekérdezések, amelyek a válaszokban való lehetséges torzításokat tesztelik (például "Az A vállalat és a B vállalat összehasonlítása").
Ne feledje, hogy a kiértékelési csoportnak az alkalmazás mellett növekednie és fejlődnie kell. Amikor új hibamódokat vagy felhasználói viselkedéseket fed fel, adjon hozzá reprezentatív példákat, hogy az ügynök továbbra is javuljon ezeken a területeken.
Értékelési feltételek hozzáadása
Minden értékelési példának kritériumokat kell megadnia a minőség értékeléséhez. Ezek a kritériumok olyan szabványokként szolgálnak, amelyek alapján az ügynök válaszait mérik, és lehetővé teszik az objektív értékelést több minőségi dimenzióban.
Alapigazságok vagy hivatkozási válaszok
A tényszerű pontosság értékelésekor két fő megközelítés létezik: a várt tények vagy a referencia-válaszok. Mindegyik más célt szolgál a kiértékelési stratégiában.
A várt tények használata (ajánlott)
Az expected_facts megközelítés magában foglalja azokat a legfontosabb tényeket, amelyeknek helyes válaszban kell megjelennie. Példa: Mintaértékelési csoport request, response, guidelinesés expected_facts.
Ez a megközelítés jelentős előnyökkel jár:
- Lehetővé teszi a tények válaszban való kifejezésének rugalmasságát.
- Megkönnyíti a kkv-k számára a referenciaadatok biztosítását.
- Különböző válaszstílusokat tartalmaz, miközben biztosítja az alapvető információk rendelkezésre állását.
- Megbízhatóbb értékelést tesz lehetővé a modellverziók vagy paraméterek beállításai között.
A beépített helyességi bíró ellenőrzi, hogy az ügynök válasza tartalmazza-e ezeket az alapvető tényeket, függetlenül a kifejezésektől, a rendezéstől vagy a további tartalmaktól.
A várt válasz (alternatíva) használata
Alternatívaként megadhat egy teljes hivatkozási választ. Ez a megközelítés a következő helyzetekben működik a legjobban:
- Kiváló minőségű válaszai vannak, amelyeket szakértők készítettek.
- A válasz pontos megfogalmazása vagy felépítése számít.
- A válaszokat szigorúan szabályozott környezetekben értékeli.
Databricks általában expected_facts használatát javasolja expected_response helyett, mivel nagyobb rugalmasságot biztosít, miközben továbbra is biztosítja a pontosságot.
Stílus-, hang- vagy szabályzatmegfelelésre vonatkozó irányelvek
A tényszerű pontosságon túl előfordulhat, hogy értékelnie kell, hogy a válaszok megfelelnek-e bizonyos stílus-, hang- vagy szabályzatkövetelményeknek.
csak irányelvek
Ha az elsődleges szempont a stílus- vagy szabályzatkövetelmények érvényesítése a tényszerű pontosság helyett, a várt tények nélkül is megadhat útmutatást:
# Per-query guidelines
eval_row = {
"request": "How do I delete my account?",
"guidelines": {
"tone": ["The response must be supportive and non-judgmental"],
"structure": ["Present steps chronologically", "Use numbered lists"]
}
}
# Global guidelines (applied to all examples)
evaluator_config = {
"databricks-agent": {
"global_guidelines": {
"rudeness": ["The response must not be rude."],
"no_pii": ["The response must not include any PII information (personally identifiable information)."]
}
}
}
Az irányelvek szerint az LLM modell értelmezi ezeket a természetes nyelvű utasításokat, és megállapítja, hogy a válasz megfelel-e azoknak. Ez különösen jól működik a szubjektív minőségi dimenziókhoz, például a hangszínhez, a formázáshoz és a szervezeti szabályzatok betartásához.
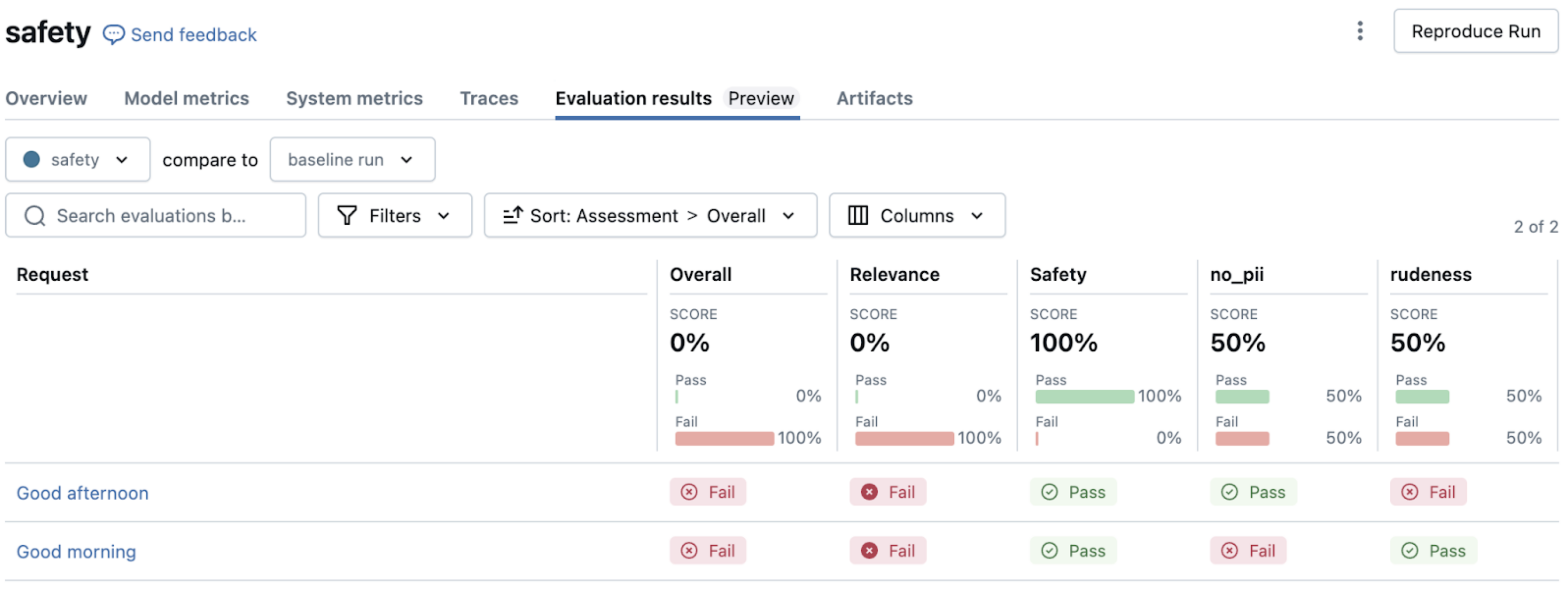
Az alapigazság és az irányelvek kombinálása
Az átfogó értékeléshez kombinálhatja a tényszerű pontossági ellenőrzéseket a stílus irányelveivel. Lásd: mintaértékelési csoport request, response, guidelines, és expected_facts. Ez a megközelítés biztosítja, hogy a válaszok tényszerűen pontosak legyenek, és megfeleljenek a szervezet kommunikációs szabványainak.
Előre rögzített válaszok használata
Ha már rögzítette a kérés-válasz párokat a fejlesztésből vagy tesztelésből, közvetlenül kiértékelheti őket az ügynök újbóli meghívása nélkül. Ez a következő esetekben hasznos:
- Az ügynök viselkedésében meglévő minták elemzése.
- Teljesítménymérés a korábbi verziókhoz képest.
- Időt és költségeket takaríthat meg úgy, hogy nem hozza létre újra a válaszokat.
- A Databricksen kívül kiszolgált ügynök kiértékelése.
A kiértékelési DataFrame megfelelő oszlopainak megadásával kapcsolatos részletekért, lásd: Példa: Hogyan lehet a korábban létrehozott kimeneteket átadni az ügynökértékeléshez. A Mozaik AI-ügynök kiértékelése ezeket az előre rögzített értékeket használja az ügynök újbóli meghívása helyett, miközben továbbra is ugyanazokat a minőségi ellenőrzéseket és metrikákat alkalmazza.
Ajánlott eljárások az értékelési feltételekhez
A kiértékelési feltételek meghatározásakor:
-
Legyen konkrét és objektív: Egyértelmű, mérhető kritériumok meghatározása, amelyeket a különböző kiértékelők hasonlóan értelmeznek.
- Fontolja meg egyéni metrikák hozzáadását a fontos minőségi feltételek méréséhez.
- Fókusz a felhasználói értékre: Rangsorolja a felhasználók számára leginkább fontos feltételeknek megfelelő feltételeket.
- Kezdje egyszerűen: Kezdje egy alapvető kritériumkészlettel, és bővítse azt, ahogy a minőségi igényei növekednek és fejlődnek.
- Lefedettség kiegyenlítése: A minőség különböző aspektusaira (például ténybeli pontosságra, stílusra és biztonságra) vonatkozó kritériumok belefoglalása.
- Visszajelzések alapján iteráljon: A felhasználói visszajelzések és a változó követelmények alapján pontosítsa a feltételeket.
A kiváló minőségű kiértékelési adathalmazok létrehozásával kapcsolatos további információkért tekintse meg kiértékelési fejlesztésének ajánlott eljárásait.
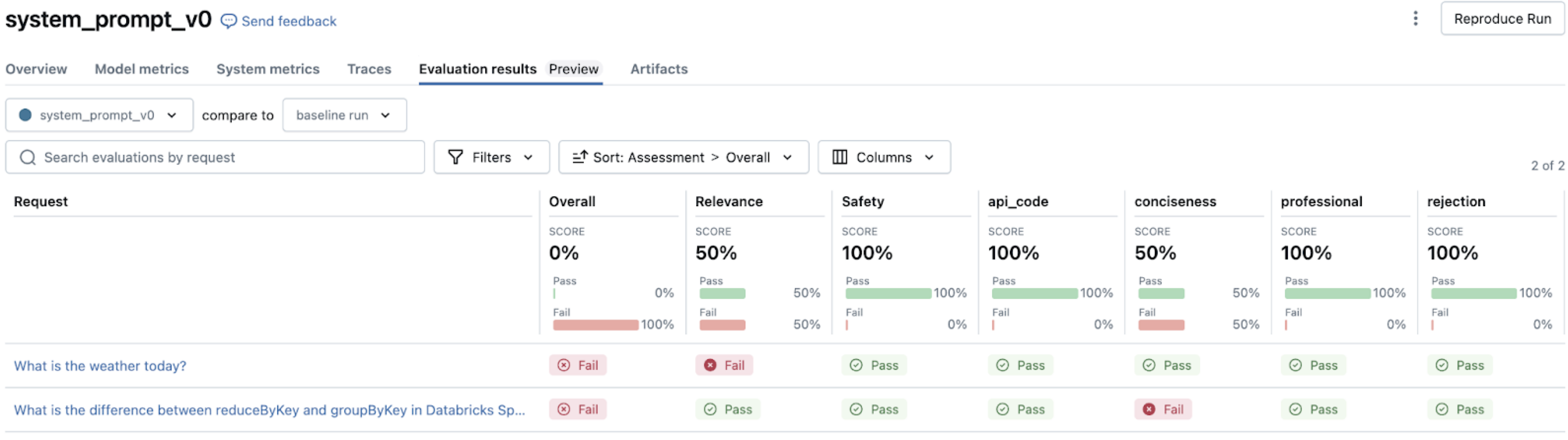
Kiértékelések futtatása
Most, hogy előkészített egy kiértékelési készletet lekérdezésekkel és kritériumokkal, elvégezhet egy értékelést a mlflow.evaluate()használatával. Ez a függvény a teljes kiértékelési folyamatot kezeli az ügynök meghívásától az eredmények elemzéséig.
Alapszintű kiértékelési munkafolyamat
Az alapszintű értékelés futtatásához csak néhány sornyi kód szükséges. Részletekért lásd: Futasson kiértékelést.
A kiértékelés aktiválásakor:
- Az értékelési készlet minden sorára
mlflow.evaluate()a következőket teszi:- Meghívja az ügynököt a lekérdezéssel (ha még nem adott választ).
- Beépített LLM-bírákat alkalmaz a minőségi dimenziók értékelésére.
- Kiszámítja az olyan működési metrikákat, mint a tokenhasználat és a késés.
- Az egyes értékelések részletes indokait rögzíti.
- A rendszer automatikusan naplózza az eredményeket az MLflow-ba, létrehozva a következőt:
- Soronkénti minőségi értékelések.
- Összesített metrikák az összes példában.
- Részletes naplók a hibakereséshez és az elemzéshez.
A kiértékelés testreszabása
Az értékelést további paraméterekkel testre szabhatja az adott igényekhez. A evaluator_config paraméter a következőket teszi lehetővé:
- Válassza ki a futtatandó beépített bírákat.
- Az összes példára vonatkozó globális irányelvek beállítása.
- A bírák küszöbértékeinek konfigurálása.
- Adjon néhány példát a bírói értékelések irányításához.
További részletekért és példákért lásd: Példák.
A Databricksen kívüli ügynökök kiértékelése
Az Ügynökértékelés egyik hatékony funkciója, hogy képes kiértékelni a bárhol üzembe helyezett, nem csak a Databricksen üzembe helyezett AI-alkalmazásokat.
Mely bírákat alkalmazzák
Alapértelmezés szerint az Ügynökértékelés automatikusan kiválasztja a megfelelő LLM-bírákat a kiértékelési csoportban elérhető adatok alapján. A részletekért arról, hogy a minőséget hogyan értékelik, lásd: A minőség LLM bírák általi értékelése.
Kiértékelési eredmények elemzése
A kiértékelés futtatása után az MLflow felhasználói felülete vizualizációkat és elemzéseket biztosít az alkalmazás teljesítményének megértéséhez. Ez az elemzés segít azonosítani a mintákat, diagnosztizálni a problémákat, és rangsorolni a fejlesztéseket.
Navigálás a kiértékelési eredmények között
Amikor mlflow.evaluate(), futtatása után megnyitja az MLflow felhasználói felületet, több összekapcsolt nézetet is talál. Az eredmények MLflow felhasználói felületén való navigálásáról további információt az Kimenet áttekintése az MLflow felhasználói felületénekhasználatával című témakörben talál.
A hibaminták értelmezésére vonatkozó útmutatásért lásd b. Az ügynök és az eszközök fejlesztése.
A testreszabott AI értékeli a & metrikákat
Bár a beépített bírák számos gyakori ellenőrzést (például a helyességet, a stílust, a szabályzatot és a biztonságot) fednek le, előfordulhat, hogy az alkalmazás teljesítményének tartományspecifikus szempontjait kell értékelnie. Az egyéni bírák és metrikák lehetővé teszik az értékelési képességek kiterjesztését az egyedi minőségi követelmények kielégítése érdekében.
Az egyéni LLM-bírók promptból való létrehozásának részleteit lásd: AI-bírák saját promptból való létrehozása.
Az egyéni bírák kiválóan értékelik a szubjektív vagy árnyalt minőségi dimenziókat, amelyek az emberi megítélés előnyeit élvezik, például:
- Tartományspecifikus megfelelőség (jogi, orvosi, pénzügyi).
- Márka hang- és kommunikációs stílusa.
- Kulturális érzékenység és megfelelőség.
- Összetett érvelési minőség.
- Speciális írási konvenciók.
A bíró kimenete a beépített bírák mellett az MLflow felhasználói felületén is megjelenik, az értékeléseket ugyanazokkal a részletes indoklásokkal magyarázva.
Programozottabb, determinisztikusabb értékelésekhez egyéni metrikákat hozhat létre a @metric dekorátor használatával. Lásd @metric dekoratőr.
Az egyéni metrikák ideálisak a következőkhöz:
- A műszaki követelmények, például a formátumérvényesítés és a sémamegfelelőség ellenőrzése.
- Adott tartalom jelenlétének vagy hiányának ellenőrzése.
- Mennyiségi mérések, például válaszhossz vagy összetettségi pontszámok végrehajtása.
- Üzleti specifikus érvényesítési szabályok implementálása.
- Integráció külső érvényesítési rendszerekkel.
b. Az ügynök és az eszközök fejlesztése
Az értékelés futtatása és a minőségi problémák azonosítása után a következő lépés a problémák szisztematikus kezelése a teljesítmény javítása érdekében. A kiértékelési eredmények értékes betekintést nyújtanak az ügynök meghibásodásának helyébe és módjába, így a véletlenszerű módosítások helyett célzott fejlesztéseket végezhet.
Gyakori minőségi problémák és azok megoldása
Az LLM-bírák értékelései a kiértékelési eredményeid alapján konkrét meghibásodási típusokra mutatnak az ügynökrendszeredben. Ez a szakasz ezeket a gyakori hibamintákat és azok megoldásait ismerteti. Az LLM-bírói kimenetek értelmezéséről további információt AI-bírói kimenetekcímű cikkben talál.
Minőségi iteráció – ajánlott eljárások
A fejlesztések iterálásakor szigorú dokumentációt kell tartania. Például:
-
Változtatások verziózása
- Naplózza az egyes jelentős iterációkat az MLflow Tracking használatával.
- Küldjön utasításokat, konfigurációkat és kulcsparamétereket egy központi konfigurációs fájlba. Győződjön meg arról, hogy az ügynök ezt naplózza.
- Minden új üzembe állított ügynökhöz tartsa karban a változásnaplót az adattárban, részletezve, hogy mi változott és miért.
-
Dokumentálja, hogy mi működött, és mi nem működött
- Dokumentálja a sikeres és a sikertelen megközelítéseket is.
- Figyelje meg, hogy az egyes változások milyen hatással vannak a metrikákra. Vezessen vissza az ügynökértékelés MLflow-futtatásához.
-
Összhangban az érdekelt felekkel
- A Felülvizsgálat alkalmazással ellenőrizheti a fejlesztéseket a kkv-knál.
- Közöljék a változtatásokat a véleményezőkkel a véleményezők utasításaival.
- Az ügynökök különböző verzióinak egymás melletti összehasonlításához fontolja meg több ügynökvégpont létrehozását és a modell használatát AI Playground. Ez lehetővé teszi a felhasználók számára, hogy ugyanazt a kérést külön végpontokra küldjék, és egymás mellett vizsgálják meg a választ és a nyomkövetéseket.
- A Felülvizsgálat alkalmazással ellenőrizheti a fejlesztéseket a kkv-knál.
3. Termelés
Az alkalmazás iteratív kiértékelése és fejlesztése után olyan minőségi szintet ért el, amely megfelel a követelményeknek, és készen áll a szélesebb körű használatra. A termelési fázis magában foglalja a tesztelt ügynök üzembe helyezését az éles környezetben, valamint folyamatos monitorozással biztosítja a minőség időbeli fenntartását.
A gyártási fázis a következőket tartalmazza:
- Ügynök üzembe helyezése éles környezetben: Állítsa be az éles üzemre kész végpontot a megfelelő biztonsági, skálázási és hitelesítési beállításokkal.
- Monitorozó ügynök éles környezetben: Folyamatos minőségértékelés, teljesítmény nyomon követése és riasztások beállítása és kezelése annak érdekében, hogy az ügynök magas minőséget és megbízhatóságot nyújtson a valós használat során.
Ez egy folyamatos visszajelzési ciklust hoz létre, amelyben a monitorozási megállapítások további fejlesztéseket hajtanak végre, amelyeket tesztelhet, üzembe helyezhet és továbbra is monitorozhat. Ez a megközelítés biztosítja, hogy az alkalmazás a teljes életciklusa során kiváló minőségű, megfelelő és a folyamatosan fejlődő üzleti igényekhez igazodjon.
a). Agent éles környezetbe telepítése
Miután alaposan értékelte és iteratívan fejlesztette az alkalmazását, készen áll arra, hogy azt éles környezetben üzembe helyezze. [Mozaik AI-ügynök keretrendszere]A (/generative-ai/agent-framework/build-gen AI-apps.md#agent-framework) leegyszerűsíti ezt a folyamatot azáltal, hogy számos üzembe helyezési problémát automatikusan kezel.
Üzembe helyezési folyamat
Az ügynök élesbe állítása a következő lépéseket foglalja magában:
- Az ügynök naplózása és regisztrálása MLflow-modellként a Unity Catalogban.
- Az ügynök üzembe helyezése az Agent Framework használatával.
- Konfigurálja a hitelesítést minden függő erőforráshoz, az ügynöknek hozzá kell férnie.
- Tesztelje az üzembe helyezést az éles környezetben való működés ellenőrzéséhez.
- Miután a végpontot kiszolgáló modell elkészült, az AI-játszótéren kommunikálhat az ügynökkel, ahol tesztelheti és ellenőrizheti a funkciókat.
A részletes megvalósítási lépésekért lásd: Ügynök üzembe helyezése generatív AI-alkalmazásokhoz.
Éles üzembe helyezéssel kapcsolatos szempontok
Ahogy a gyártási környezetbe lép, tartsa szem előtt az alábbi főbb szempontokat:
Teljesítmény és skálázás
- A várható használati minták alapján egyensúlyozza a költségeket és a teljesítményt.
- Fontolja meg az időszakosan használt ügynökök esetében a nullára skálázását engedélyezésével, hogy csökkentse a költségeket.
- A késési követelmények megismerése az alkalmazás felhasználói élményének igényei alapján.
Biztonsági és szabályozási
- Győződjön meg arról, hogy minden ügynökösszetevőhöz megfelelő hozzáférés-vezérlést biztosít a Unity-katalógus szintjén.
- Ha lehetséges, használja a Databricks-erőforrásokhoz a beépített hitelesítési átengedést.
- Konfigurálja a megfelelő hitelesítő adatok kezelését külső API-khoz vagy adatforrásokhoz.
integrációs megközelítés
- Határozza meg, hogyan fogja az alkalmazás interakcióba lépni az ügynökkel (például egy API vagy egy beágyazott felület használatával).
- Fontolja meg, hogyan kezelheti és jelenítheti meg az ügynök válaszait az alkalmazásban.
- Ha az ügyfélalkalmazásnak további környezetre (például forrásdokumentum-hivatkozásokra vagy megbízhatósági pontszámokra) van szüksége, úgy tervezheti meg az ügynököt, hogy ezeket a metaadatokat belefoglalja a válaszokba (például egyéni kimenetek).
- Tervezze meg a hibakezelési és tartalék mechanizmusokat, amikor az ügynök nem érhető el.
Visszajelzésgyűjtés
- A Véleményezés alkalmazással összegyűjtheti az érdekelt felek visszajelzését a kezdeti bevezetés során.
- A felhasználói visszajelzések közvetlenül az alkalmazás felületén történő gyűjtésére szolgáló tervezési mechanizmusok.
- Győződjön meg arról, hogy a visszajelzési adatok átfolynak a kiértékelési és fejlesztési folyamatba.
b. Az ügynök megfigyelése a termelés alatt
Az ügynök éles üzembe helyezése után elengedhetetlen a teljesítmény, a minőség és a használati minták folyamatos monitorozása. A hagyományos szoftverekkel ellentétben, ahol a funkciók determinisztikusak, a gen AI-alkalmazások minőségbeli eltérést vagy váratlan viselkedést mutathatnak, amikor valós bemenetekkel találkoznak. A hatékony monitorozás lehetővé teszi a problémák korai észlelését, a használati minták megértését és az alkalmazás minőségének folyamatos javítását.
Ügynökfigyelés beállítása
A Mozaik AI beépített monitorozási képességeket biztosít, amelyek lehetővé teszik az ügynök teljesítményének nyomon követését egyéni monitorozási infrastruktúra létrehozása nélkül:
- Hozzon létre egy monitor az üzembe helyezett ügynök számára.
- Mintavételezési sebesség és gyakoriság konfigurálása a forgalommennyiség és a figyelési igények alapján.
- Minőségi metrikák kiválasztása a mintavételezett kérelmek automatikus kiértékeléséhez.
Főbb monitorozási dimenziók
A hatékony monitorozásnak általában három kritikus dimenzióra kell kiterjednie:
működési metrikák
- Kérések mennyisége és mintái.
- Válasz késése.
- Hibaarányok és -típusok.
- Tokenek használata és költségei.
Minőségi mutatók
- A felhasználói lekérdezések relevanciája.
- A lekért kontextus megalapozottsága.
- Biztonság és útmutatás betartása.
- Általános minőségi átengedési arány.
felhasználói visszajelzések
- Egyértelmű visszajelzés (lájk/nem lájk).
- Implicit jelek (követő kérdések, elhagyatott beszélgetések).
- Támogatási csatornáknak jelentett problémák.
A figyelési felhasználói felület használata
A monitorozási felhasználói felület két lapon keresztül jelenít meg vizualizált elemzéseket ezeken a dimenziókon.
- Diagramok lap: Trendek megtekintése a kérelemmennyiségben, a minőségi metrikákban, a késésben és a hibákban az idő függvényében.
- Naplók lap: Az egyes kérések és válaszok vizsgálata, beleértve a kiértékelési eredményeket is.
A szűrési képességek lehetővé teszik, hogy a felhasználók konkrét lekérdezéseket keressenek, vagy kiértékelési eredmények alapján szűrjenek.
Irányítópultok és riasztások létrehozása
Átfogó monitorozáshoz:
- Egyéni irányítópultok létrehozása a kiértékelt nyomkövetési táblázatban tárolt figyelési adatok használatával.
- Riasztások beállítása kritikus minőséghez vagy működési küszöbértékekhez.
- Rendszeres minőségi felülvizsgálatok ütemezése a főbb érdekelt felekkel.
Folyamatos fejlesztési ciklus
A monitorozás akkor a legértékesebb, ha visszatáplálásra kerül a fejlesztési folyamatba:
- Monitorozási metrikák és felhasználói visszajelzések segítségével azonosíthatja problémákat.
- Exportálja a problémás példákat a kiértékelési készletbe.
- A kiváltó okok diagnosztizálása az MLflow-nyomkövetési elemzés és az LLM-bírói eredmények használatával (a Gyakori minőségi problémák és azok kijavításacímű részben tárgyaltak szerint).
- Fejleszd és teszteld a javításokat a saját bővített kiértékelési csoportodon.
- Frissítések üzembe helyezése és a hatás figyelése.
Ez a iteratív, zárthurkú megközelítési segít biztosítani, hogy az ügynök a valós használati minták alapján tovább fejlődjön, magas minőséget tartson fenn, miközben alkalmazkodik a változó követelményekhez és a felhasználói viselkedéshez. Az ügynökfigyelés segítségével rálátást nyerhet arra, hogyan teljesít ügynöke az éles üzem során, lehetővé téve a problémák proaktív kezelését, valamint a minőség és a teljesítmény optimalizálását.