Megjegyzés
Az oldalhoz való hozzáféréshez engedély szükséges. Megpróbálhat bejelentkezni vagy módosítani a címtárat.
Az oldalhoz való hozzáféréshez engedély szükséges. Megpróbálhatja módosítani a címtárat.
Ez az oktatóanyag bemutatja, hogy egy Azure Databricks-jegyzetfüzet használatával adatokat importálhat egy CSV-fájlból, amely babanévadatokat tartalmaz health.data.ny.gov a Unity Catalog-kötetbe Python, Scala és R használatával. Megtudhatja továbbá, hogyan módosíthatja az oszlopnevet, vizualizálhatja az adatokat, és menthet egy táblába.
Megjegyzés:
Ha a Databricks Free Editiont használja, az oktatóanyagban szereplő összes kódhoz válassza a Python lapot. Az Ingyenes kiadás nem támogatja az R-t vagy a Scalát. Emellett a Free Edition korlátozza a kimenő internet-hozzáférést, ezért a CSV-fájlt a munkaterület felhasználói felületén kell feltöltenie ahelyett, hogy kóddal töltené le. Részletes útmutatásért lásd a 3. lépést .
Követelmények
A cikkben szereplő feladatok elvégzéséhez meg kell felelnie a következő követelményeknek:
- A munkaterületen engedélyezve kell lennie Unity Catalog. A Unity Catalog használatának első lépéseiről további információt a Unity Catalog használatának első lépéseit ismertető cikkben talál. Az Azure Databricks Free Edition és az ingyenes próbaverziós munkaterületek alapértelmezés szerint engedélyezve vannak a Unity Katalógusban.
- Rendelkeznie kell a kötet
WRITE VOLUMEjogosultságával, a fő sémaUSE SCHEMAjogosultságával és a fő katalógusUSE CATALOGjogosultságával. Az Ingyenes kiadás felhasználói alapértelmezés szerint rendelkeznek ezekkel a jogosultságokkal a munkaterület-katalógusban ésdefaulta sémában. - Rendelkeznie kell engedéllyel egy meglévő számítási erőforrás használatához vagy egy új számítási erőforrás létrehozásához. A Compute megtekintéséhez forduljon az Azure Databricks rendszergazdájához.
Tipp.
A cikk befejezett jegyzetfüzeteit az adatjegyzetfüzetek importálása és vizualizációja című témakörben találja.
1. lépés: Új jegyzetfüzet létrehozása
Ha jegyzetfüzetet szeretne létrehozni a munkaterületen, kattintson ![]() az Oldalsáv Új gombjára, majd a Jegyzetfüzet elemre. Megnyílik egy üres jegyzetfüzet a munkaterületen.
az Oldalsáv Új gombjára, majd a Jegyzetfüzet elemre. Megnyílik egy üres jegyzetfüzet a munkaterületen.
A jegyzetfüzetek létrehozásáról és kezeléséről további információt a Databricks-jegyzetfüzetek kezelése című témakörben talál.
2. lépés: Változók definiálása
Ebben a lépésben a cikkben létrehozott példajegyzetfüzetben használt változókat definiálja. Szüksége van a Unity Catalog katalógus, séma és kötet nevére.
Tipp.
Ha nem ismeri a katalógus és a séma nevét, kattintson az ![]() Katalógus az oldalsávon. A munkaterület-katalógus egy nevet oszt meg a munkaterülettel, és megjelenik a katalóguspanelen. Nyissa meg az elérhető sémák megtekintéséért. Az Ingyenes kiadás és az ingyenes próbaverzió felhasználói használhatják a munkaterület katalógusát és a sémát
Katalógus az oldalsávon. A munkaterület-katalógus egy nevet oszt meg a munkaterülettel, és megjelenik a katalóguspanelen. Nyissa meg az elérhető sémák megtekintéséért. Az Ingyenes kiadás és az ingyenes próbaverzió felhasználói használhatják a munkaterület katalógusát és a sémát default .
Ha nem rendelkezik kötettel, hozzon létre egyet úgy, hogy a következő parancsot futtatja egy jegyzetfüzetcellában, és cserélje le a <catalog_name> és <schema_name> helyére a saját értékeit.
CREATE VOLUME IF NOT EXISTS <catalog_name>.<schema_name>.my_volume
Másolja és illessze be a következő kódot az új üres jegyzetfüzetcellába. Cserélje le a
<catalog-name>,<schema-name>és<volume-name>elemeket a Unity Catalog kötetének katalógus-, séma- és kötetneveire. Ha szeretné, cserélje le atable_nameértéket egy tetszőleges táblanévre. A babanév adatait a cikk későbbi részében ebbe a táblába mentheti.Nyomja meg a
Shift+Entergombot a cella futtatásához és egy új üres cella létrehozásához.Python
catalog = "<catalog_name>" schema = "<schema_name>" volume = "<volume_name>" download_url = "https://health.data.ny.gov/api/views/jxy9-yhdk/rows.csv" file_name = "baby_names.csv" table_name = "baby_names" path_volume = "/Volumes/" + catalog + "/" + schema + "/" + volume path_table = catalog + "." + schema print(path_table) # Show the complete path print(path_volume) # Show the complete pathScala
val catalog = "<catalog_name>" val schema = "<schema_name>" val volume = "<volume_name>" val downloadUrl = "https://health.data.ny.gov/api/views/jxy9-yhdk/rows.csv" val fileName = "baby_names.csv" val tableName = "baby_names" val pathVolume = s"/Volumes/${catalog}/${schema}/${volume}" val pathTable = s"${catalog}.${schema}" print(pathVolume) // Show the complete path print(pathTable) // Show the complete pathR
catalog <- "<catalog_name>" schema <- "<schema_name>" volume <- "<volume_name>" download_url <- "https://health.data.ny.gov/api/views/jxy9-yhdk/rows.csv" file_name <- "baby_names.csv" table_name <- "baby_names" path_volume <- paste("/Volumes/", catalog, "/", schema, "/", volume, sep = "") path_table <- paste(catalog, ".", schema, sep = "") print(path_volume) # Show the complete path print(path_table) # Show the complete path
3. lépés: CSV-fájl importálása
Ebben a lépésben importál egy CSV-fájlt, amely babanévadatokat tartalmaz health.data.ny.gov a Unity Catalog-kötetbe. Válasszon az alábbi módszerek közül :
- Feltöltés a munkaterület felhasználói felületén – Ezt a módszert akkor használja, ha a Databricks Free Edition kiadásban van, vagy ha a B lehetőségben a kódletöltés hálózati hibával meghiúsul. A Free Edition és más kiszolgáló nélküli számítási környezetek korlátozzák a kimenő internet-hozzáférést, ezért fel kell töltenie a fájlt a helyi gépről.
- Letöltés kóddal – Ezt a módszert akkor használja, ha a számítási környezet kimenő internet-hozzáféréssel rendelkezik.
A lehetőség A: Feltöltés a munkaterület felhasználói felületén
- A helyi számítógépén, a böngészőben nyissa meg a health.data.ny.gov/api/views/jxy9-yhdk/rows.csv fájlt. A fájl a következő módon
rows.csvtölthető le a számítógépre: . - Keresse meg a letöltött fájlt a számítógépén, és nevezze át
rows.csv-rólbaby_names.csv-re. Ez megegyezik afile_name2. lépésben definiált változóval. - Térjen vissza az Azure Databricks-munkaterületre. Az oldalsávon kattintson az
 Új > adat hozzáadása vagy feltöltése.
Új > adat hozzáadása vagy feltöltése. - Kattintson a Fájlok feltöltése kötetre elemre.
- Kattintson a Tallózás gombra , jelölje ki a
baby_names.csvfájlt, vagy húzza a feltöltési területre. - A Célkötet területen válassza ki a 2. lépésben megadott kötetet.
- A feltöltés befejezése után térjen vissza a jegyzetfüzethez, és folytassa a 4. lépéssel.
A fájlok feltöltésével kapcsolatos további információkért lásd: Fájlok használata a Unity-katalógus köteteiben.
B. lehetőség: Letöltés kóddal
Másolja és illessze be a következő kódot az új üres jegyzetfüzetcellába. Ez a kód a
rows.csvfájlt másolja be a Unity Catalog-kötetbe a Databricks dbutils parancs használatával.Nyomja meg a
Shift+Entergombot a cella futtatásához, majd lépjen a következő cellára.Python
dbutils.fs.cp(f"{download_url}", f"{path_volume}" + "/" + f"{file_name}")Scala
dbutils.fs.cp(downloadUrl, s"${pathVolume}/${fileName}")R
dbutils.fs.cp(download_url, paste(path_volume, "/", file_name, sep = ""))
4. lépés: CSV-adatok betöltése DataFrame-be
Ebben a lépésben egy df nevű DataFrame-et hoz létre abból a CSV-fájlból, amelyet korábban betöltött a Unity Catalog-kötetbe a spark.read.csv metódus használatával.
Másolja és illessze be a következő kódot az új üres jegyzetfüzetcellába. Ez a kód betölti a babanév adatait a DataFrame-be
dfa CSV-fájlból.Nyomja meg a
Shift+Entergombot a cella futtatásához, majd lépjen a következő cellára.Python
df = spark.read.csv(f"{path_volume}/{file_name}", header=True, inferSchema=True, sep=",")Scala
val df = spark.read .option("header", "true") .option("inferSchema", "true") .option("delimiter", ",") .csv(s"${pathVolume}/${fileName}")R
# Load the SparkR package that is already preinstalled on the cluster. library(SparkR) df <- read.df(paste(path_volume, "/", file_name, sep=""), source="csv", header = TRUE, inferSchema = TRUE, delimiter = ",")
Számos támogatott fájlformátumból tölthet be adatokat.
5. lépés: Adatok megjelenítése jegyzetfüzetből
Ebben a lépésben a display() metódussal jeleníti meg a DataFrame tartalmát a jegyzetfüzet egy táblájában, majd megjelenítheti az adatokat egy felhőalapú szódiagramon a jegyzetfüzetben.
Másolja és illessze be a következő kódot az új üres jegyzetfüzetcellába, majd kattintson a Cella futtatása elemre az adatok táblázatbeli megjelenítéséhez.
Python
display(df)Scala
display(df)R
display(df)Tekintse át az eredményeket a táblázatban.
A Tábla lap mellett kattintson a +, majd a Vizualizációselemre.
A vizualizációszerkesztőben kattintson a Vizualizáció típusa elemre, és ellenőrizze, hogy a Word-felhő van-e kiválasztva.
A Szavak oszlopbanellenőrizze, hogy a
First Namevan-e kijelölve.A Frekvenciakorlátesetében kattintson a
35gombra.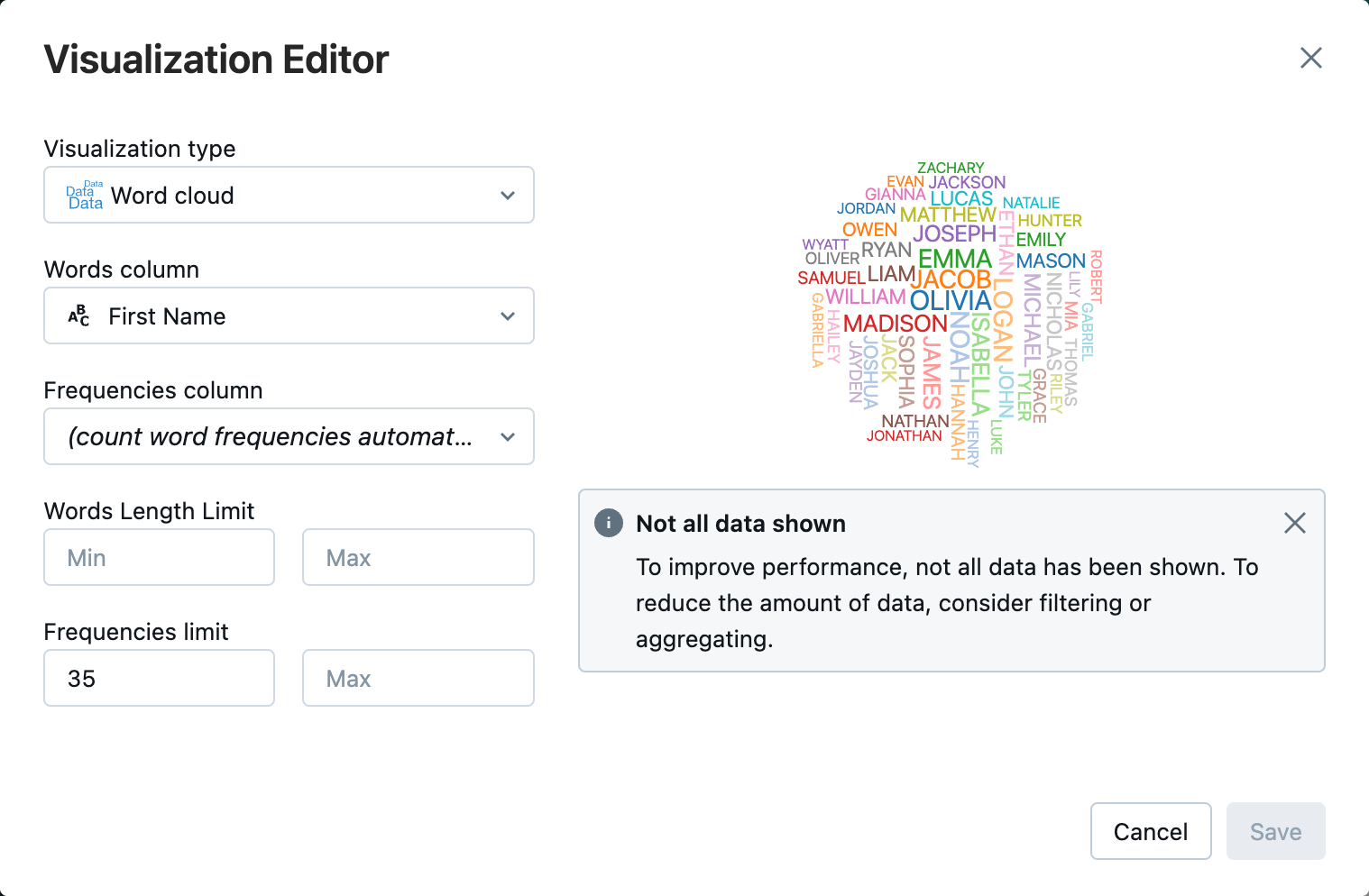
Kattintson a Mentés.
6. lépés: A DataFrame mentése táblába
Fontos
A DataFrame Unity-katalógusban való mentéséhez CREATE táblajogokkal kell rendelkeznie a katalógusban és a sémában. A Unity Catalog engedélyekkel kapcsolatos további információkért tekintse meg Jogosultságok és biztonságos objektumok a Unity Catalog és Jogosultságok kezelése a Unity Katalógusbancímű témakört.
Másolja és illessze be a következő kódot egy üres jegyzetfüzetcellába. Ez a kód egy szóközt cserél le az oszlopnévben. Speciális karakterek, például szóközök nem engedélyezettek az oszlopnevekben. Ez a kód az Apache Spark
withColumnRenamed()metódust használja.Python
df = df.withColumnRenamed("First Name", "First_Name") df.printSchemaScala
val dfRenamedColumn = df.withColumnRenamed("First Name", "First_Name") // when modifying a DataFrame in Scala, you must assign it to a new variable dfRenamedColumn.printSchema()R
df <- withColumnRenamed(df, "First Name", "First_Name") printSchema(df)Másolja és illessze be a következő kódot egy üres jegyzetfüzetcellába. Ez a kód a Cikk elején definiált táblanévváltozó használatával menti a DataFrame tartalmát a Unity Catalog egyik táblájába.
Python
df.write.mode("overwrite").saveAsTable(f"{path_table}" + "." + f"{table_name}")Scala
dfRenamedColumn.write.mode("overwrite").saveAsTable(s"${pathTable}.${tableName}")R
saveAsTable(df, paste(path_table, ".", table_name), mode = "overwrite")A táblázat mentésének ellenőrzéséhez kattintson Katalógus a bal oldali oldalsávon a Katalóguskezelő felhasználói felületének megnyitásához. Nyissa meg a katalógust, majd a sémát annak ellenőrzéséhez, hogy megjelenik-e a tábla.
A táblázatra kattintva megtekintheti a táblázatsémát az Áttekintés lapon.
Kattintson Mintaadatok elemre a táblázat 100 adatsorának megtekintéséhez.
Adatjegyzetfüzetek importálása és vizualizációja
A cikk lépéseinek végrehajtásához használja az alábbi jegyzetfüzetek egyikét. Cserélje le a <catalog-name>, <schema-name>és <volume-name> elemeket a Unity Catalog kötetének katalógus-, séma- és kötetneveire. Ha szeretné, cserélje le a table_name értéket egy tetszőleges táblanévre.
Python
Adatok importálása CSV-ből a Python használatával
Scala
Adatok importálása CSV-ből a Scala használatával
R
Adatok importálása CSV-ből az R használatával
Következő lépések
- A feltáró adatelemzési (EDA) technikák megismeréséhez lásd a Oktatóanyag: EDA technikái Databricks jegyzetfüzetekkel.
- Az ETL-(kinyerési, átalakítási és betöltési) folyamat létrehozásáról lásd a következőket: Oktatóanyag: ETL-folyamat létrehozása Lakeflow-folyamatokkal és Oktatóanyag: ETL-folyamat létrehozása Apache Sparkkal a Databricks platformon