Megjegyzés
Az oldalhoz való hozzáféréshez engedély szükséges. Megpróbálhat bejelentkezni vagy módosítani a címtárat.
Az oldalhoz való hozzáféréshez engedély szükséges. Megpróbálhatja módosítani a címtárat.
Az alapelvek olyan nulla szintű szabályok, amelyek meghatározzák és befolyásolják az architektúrát. Ahhoz, hogy olyan data lakehouse-t hozzon létre, amely segít az üzlet sikerességében most és a jövőben, a szervezet érdekelt feleinek egyetértése kritikus fontosságú.
Adatok gondozása és megbízható adatmint-termékek nyújtása
Az adatok kurálása elengedhetetlen egy nagy értékű adattó létrehozásához a BI és az ML/AI számára. Az adatokat úgy kezelheti, mint egy egyértelmű definíciót, sémát és életciklust tartalmazó terméket. Biztosítsa a szemantikai konzisztenciát, és hogy az adatminőség rétegről rétegre javuljon, hogy az üzleti felhasználók teljes mértékben megbízhassanak az adatokban.
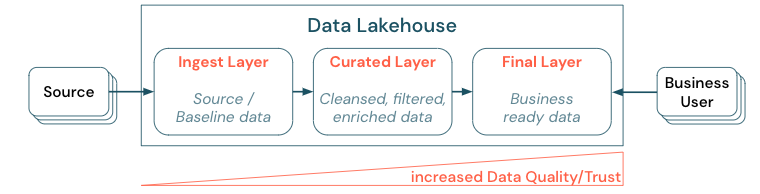
Az adatok rétegzett (vagy több ugrásos) architektúra létrehozásával történő kezelése kritikus fontosságú gyakorlat a lakehouse számára, mivel lehetővé teszi, hogy az adatcsoportok minőségi szintek szerint strukturálják az adatokat, és rétegenként definiálják a szerepköröket és a felelősségeket. Gyakori rétegzési módszer:
- Betöltési réteg: A forrásadatok a tóházba kerülnek az első rétegbe, és ott is meg kell őrizni őket. Ha az összes alsóbb rétegbeli adat létrejön a betöltési rétegből, szükség esetén újraépítheti a következő rétegeket ebből a rétegből.
- Válogatott réteg: A második réteg célja, hogy megtisztított, finomított, szűrt és összesített adatokat tároljon. Ennek a rétegnek a célja, hogy megbízható és megbízható alapot biztosítson az elemzésekhez és jelentésekhez minden szerepkörben és funkcióban.
- Utolsó réteg: A harmadik réteg az üzleti vagy projektigények köré jön létre; más nézetet biztosít adattermékként más üzleti egységeknek vagy projekteknek, előkészíti az adatokat a biztonsági igények köré (például anonimizált adatok), vagy optimalizálja a teljesítményt (előre összesített nézetekkel). Az ebben a rétegben található adattermékek az üzleti igazságnak tekinthetők.
Az összes rétegben futó folyamatoknak biztosítaniuk kell az adatminőségre vonatkozó korlátozások betartását, ami azt jelenti, hogy az adatok mindig pontosak, teljesek, hozzáférhetők és konzisztensek, még az egyidejű olvasások és írások során is. Az új adatok érvényesítése a válogatott rétegbe való adatbevitelkor történik, és az alábbi ETL-lépések az adatok minőségének javítása érdekében működnek. Az adatminőségnek javulnia kell, ahogy az adatok a rétegeken haladnak előre, és mint ilyen, az adatokba vetett bizalom később üzleti szempontból növekszik.
Adatsilók kiküszöbölése és az adatáthelyezés minimalizálása
Ne hozzon létre másolatokat olyan adathalmazokról, amelyek üzleti folyamatai ezekre a különböző másolatokra támaszkodnak. A másolatok adatsilókká válhatnak, amelyek elszabadulnak a szinkronizálásból, ami a data lake minőségének romlásához, végül pedig elavult vagy helytelen elemzésekhez vezet. Emellett az adatok külső partnerekkel való megosztásához használjon vállalati megosztási mechanizmust, amely biztonságos módon teszi lehetővé az adatokhoz való közvetlen hozzáférést.
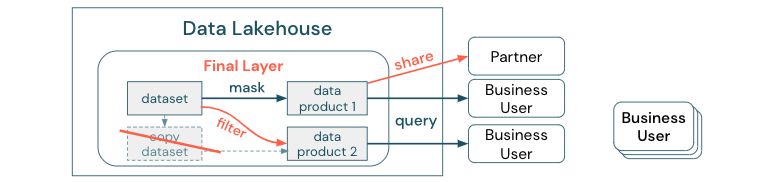
Az adatmásolás és az adatsiló közötti különbség egyértelművé tétele: Az adatok önálló vagy eldobható másolata önmagában nem káros. Néha szükség van az agilitás, a kísérletezés és az innováció fokozására. Ha azonban ezek a másolatok működésbe lépnek az alárendelt üzleti adattermékekkel, azok adatsilókká válnak.
Az adatsilók megelőzése érdekében az adatcsoportok általában megpróbálnak olyan mechanizmust vagy adatfolyamot létrehozni, amely az összes másolatot szinkronizálja az eredetivel. Mivel ez nem valószínű, hogy következetesen történik, az adatminőség végül romlik. Ez magasabb költségekhez és a felhasználói bizalom jelentős elvesztéséhez is vezethet. Másfelől számos üzleti használati eset megköveteli a partnerekkel vagy szállítókkal való adatmegosztást.
Fontos szempont az adathalmaz legújabb verziójának biztonságos és megbízható megosztása. Az adathalmaz másolatai gyakran nem elegendőek, mert gyorsan ki tudnak szállni a szinkronizálásból. Ehelyett az adatokat vállalati adatmegosztási eszközökkel kell megosztani.
Értékteremtés demokratizálása önkiszolgáló szolgáltatással
A legjobb data lake nem tud elegendő értéket nyújtani, ha a felhasználók nem tudnak könnyen hozzáférni a platformhoz vagy az adatokhoz a BI- és ML/AI-feladataikhoz. Csökkentse az összes üzleti egység adataihoz és platformjaihoz való hozzáférés korlátait. Fontolja meg a lean adatkezelési folyamatokat, és biztosítson önkiszolgáló hozzáférést a platformhoz és a mögöttes adatokhoz.
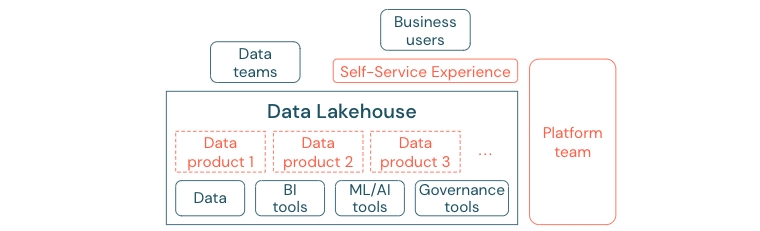
Az adatvezérelt kultúrába sikeresen áttelepített vállalkozások jól fognak fejlődni. Ez azt jelenti, hogy minden üzleti egység elemzési modellekből vagy saját vagy központilag szolgáltatott adatok elemzéséből nyeri a döntéseit. A fogyasztók számára az adatoknak könnyen felderíthetőnek és biztonságosan hozzáférhetőnek kell lenniük.
Az adattermelők számára jó fogalom az "adatok mint termék": Az adatokat egy üzleti egység vagy üzleti partner kínálja és tartja karban, mint egy termék, és más felek használják fel megfelelő engedélyekkel. Ahelyett, hogy központi csapatra és esetleg lassú kérési folyamatokra támaszkodik, ezeket az adattermékeket önkiszolgáló felületen kell létrehozni, kínálni, felderíteni és felhasználni.
Azonban nem csak az adatok számítanak. Az adatok demokratizálásához megfelelő eszközökre van szükség ahhoz, hogy mindenki képes legyen az adatok előállítására vagy felhasználására és megértésére. Ehhez a data lakehouse-nak egy modern adat- és AI-platformnak kell lennie, amely az adattermékek létrehozásához szükséges infrastruktúrát és eszközöket biztosítja anélkül, hogy duplikálja egy másik eszközverem beállításának erőfeszítését.
Szervezeti szintű adat- és AI-szabályozási stratégia bevezetése
Az adatok egy szervezet kritikus fontosságú objektumai, de nem adhat mindenkinek hozzáférést az összes adathoz. Az adathozzáférést aktívan kell kezelni. A hozzáférés-vezérlés, a naplózás és a vonalkövetés kulcsfontosságú az adatok helyes és biztonságos használatához.
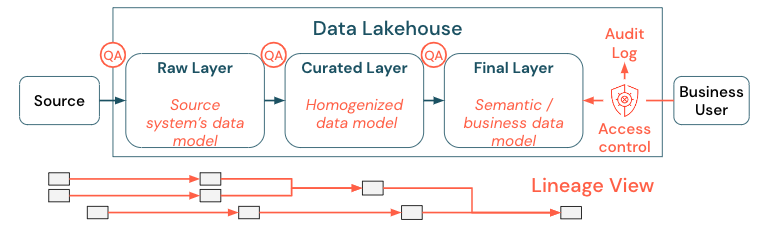
Az adatszabályozás széles körű témakör. A tóház a következő dimenziókat fedi le:
Adatminőség
A helyes és értelmes jelentések, elemzési eredmények és modellek legfontosabb előfeltétele a kiváló minőségű adatok. A minőségbiztosításnak (QA) az összes folyamatlépés körül meg kell jelennie. Ilyen például az adatszerződések létrehozása, az SLA-k teljesítése, a sémák stabil állapotban tartása és szabályozott módon történő fejlesztése.
Adatkatalógus
Egy másik fontos szempont az adatfelderítés: Az összes üzleti terület felhasználóinak, különösen az önkiszolgáló modellben, képesnek kell lenniük arra, hogy könnyen felderíthessék a releváns adatokat. Ezért a lakehouse-nak szüksége van egy adatkatalógusra, amely az összes üzleti szempontból releváns adatot lefedi. Az adatkatalógus elsődleges céljai a következők:
- Győződjön meg arról, hogy ugyanaz az üzleti koncepció egységesen van megnevezve és használva az egész vállalkozáson belül. Úgy tekinthet rá, mint egy szemantikai modellre a kurált és a végső rétegben.
- Pontosan nyomon követheti az adatsorokat, hogy a felhasználók elmagyarázhassák, hogyan érkeztek ezek az adatok az aktuális alakjukhoz és formájukhoz.
- Magas minőségű metaadatok karbantartása, ami ugyanolyan fontos, mint maga az adatok az adatok megfelelő használatához.
Hozzáférés-vezérlés
Mivel a tóházban lévő adatokból az értékteremtés minden üzleti területen történik, a tóházat első osztályú polgárként biztonságmal kell felépíteni. Előfordulhat, hogy a vállalatok nyitottabb adathozzáférési szabályzattal rendelkeznek, vagy szigorúan betartják a minimális jogosultságok elvét. Étől függetlenül az adathozzáférési vezérlőknek minden rétegben helyükön kell lenniük. Fontos, hogy a kezdetektől finom jogosultsági sémákat implementáljon (oszlop- és sorszintű hozzáférés-vezérlés, szerepköralapú vagy attribútumalapú hozzáférés-vezérlés). A vállalatok kevésbé szigorú szabályokkal kezdhetnek. A lakehouse platform növekedésével azonban már minden mechanizmusnak és folyamatnak létre kell lennie egy kifinomultabb biztonsági rendszer számára. Emellett a lakehouse-ban található adatokhoz való hozzáférést kezdettől fogva ellenőrzési naplóknak kell szabályoznia.
Nyitott felületek és nyílt formátumok ösztönzése
A nyílt felületek és az adatformátumok kulcsfontosságúak a lakehouse és más eszközök közötti interoperabilitás szempontjából. Leegyszerűsíti a meglévő rendszerekkel való integrációt, és olyan partnerek ökoszisztémáját is megnyitja, akik integrálták eszközeiket a platformmal.
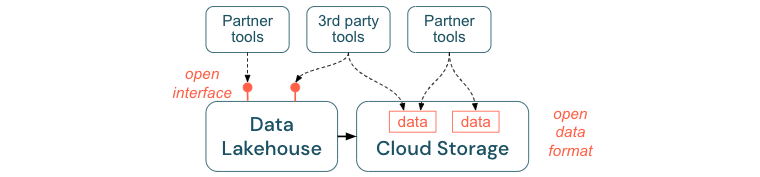
A nyílt felületek kritikus fontosságúak az együttműködési képesség engedélyezéséhez és az egyetlen szállítótól való függőség megelőzéséhez. A beszállítók hagyományosan olyan saját fejlesztésű technológiákat és zárt felületeket építettek ki, amelyek korlátozták a vállalatok számára az adatok tárolását, feldolgozását és megosztását.
A nyitott felületekre építkezve a jövőre építhet:
- Növeli az adatok élettartamát és hordozhatóságát, hogy több alkalmazással és több használati esettel használhassa.
- Megnyitja a partnerek ökoszisztémáját, akik gyorsan kihasználhatják a nyitott felületeket, hogy integrálják eszközeiket a Lakehouse platformba.
Végül az adatok nyílt formátumainak szabványosításával a teljes költség jelentősen alacsonyabb lesz; az adatok közvetlenül a felhőtárhelyen érhetők el anélkül, hogy egy olyan védett platformon keresztül kellene átvezetni az adatokat, amely magas kimenő és számítási költségeket okozhat.
Összeállítás a teljesítmény és a költség skálázásához és optimalizálásához
Az adatok elkerülhetetlenül tovább növekednek, és összetettebbé válnak. Ahhoz, hogy a szervezetet felkészítse a jövőbeli igényekre, a lakehouse-nak képesnek kell lennie a skálázásra. Például igény szerint könnyen hozzáadhat új erőforrásokat. A költségeket a tényleges fogyasztásra kell korlátozni.
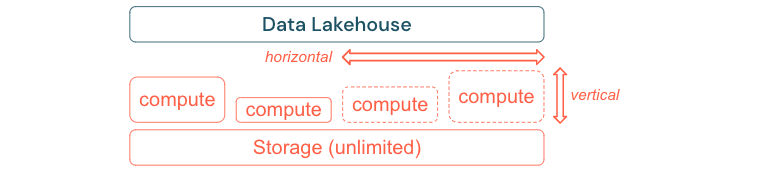
A standard ETL-folyamatok, üzleti jelentések és irányítópultok gyakran memória- és számítási szempontból kiszámítható erőforrásigényekkel rendelkeznek. Az új projektek, a szezonális tevékenységek vagy a modern megközelítések, például a modell betanítása (változás, előrejelzés, karbantartás) azonban az erőforrás-igény csúcsait eredményezik. Ahhoz, hogy egy vállalat elvégezhesse ezeket a számítási feladatokat, skálázható platformra van szükség a memóriához és a számításhoz. Az új erőforrásokat igény szerint könnyen hozzá kell adni, és csak a tényleges felhasználás hozhat létre költségeket. Amint vége a csúcsnak, az erőforrások újra felszabadíthatók, és ennek megfelelően csökkennek a költségek. Ezt gyakran nevezik horizontális skálázásnak (kevesebb vagy több csomópont) és függőleges skálázásnak (nagyobb vagy kisebb csomópontok).
A skálázás lehetővé teszi a vállalatok számára a lekérdezések teljesítményének javítását azáltal, hogy több erőforrással rendelkező csomópontokat vagy több csomópontot tartalmazó fürtöket választanak ki. De ahelyett, hogy a nagy gépek és fürtök állandóan rendelkezésre állnának, csak arra az időre állíthatók elő, amíg a költséghatékonysági arány optimalizálása szükséges. Az optimalizálás másik aspektusa a tárolás és a számítási erőforrások. Mivel nincs egyértelmű kapcsolat az adatokat használó adatok mennyisége és a számítási feladatok mennyisége között (például csak az adatok egy részének felhasználásával vagy a kis adatokon végzett intenzív számításokkal), célszerű olyan infrastruktúraplatformon rendezni, amely leválasztja a tárolási és számítási erőforrásokat.