Megjegyzés
Az oldalhoz való hozzáféréshez engedély szükséges. Megpróbálhat bejelentkezni vagy módosítani a címtárat.
Az oldalhoz való hozzáféréshez engedély szükséges. Megpróbálhatja módosítani a címtárat.
A medallion architektúra olyan adatrétegeket ír le, amelyek a lakehouse-ban tárolt adatok minőségét jelölik. Az Azure Databricks azt javasolja, hogy többrétegű megközelítést alkalmazzon a vállalati adattermékek egyetlen igazságforrásának létrehozására.
Ez az architektúra garantálja az atomitást, a konzisztenciát, az elkülönítést és a tartósságot, mivel az adatok több érvényesítési és átalakítási rétegen haladnak át, mielőtt a hatékony elemzésre optimalizált elrendezésben tárolva lesznek. A bronz (nyers), ezüst (ellenőrzött) és arany (dúsított) kifejezések az egyes rétegekben lévő adatok minőségét írják le.
Medallion architektúra adattervezési mintaként
A medallion architektúra az adatok logikai rendszerezésére szolgáló adattervezési minta. Célja, hogy fokozatosan és fokozatosan javítsa az adatok szerkezetét és minőségét, miközben az architektúra minden rétegén áthalad (a Bronz ⇒ Silver ⇒ Gold rétegtáblákból). A medallion architektúrákat néha többugrásos architektúráknak is szokták nevezni.
Az adatok ezen rétegeken keresztüli előrehaladásával a szervezetek növekményesen javíthatják az adatok minőségét és megbízhatóságát, így jobban alkalmasak az üzleti intelligencia és a gépi tanulási alkalmazások számára.
A medál architektúra követése ajánlott eljárás, de nem követelmény.
| Kérdés | Bronz | Ezüst | Arany |
|---|---|---|---|
| Mi történik ebben a rétegben? | Nyers adatbetöltés | Adattisztítás és -ellenőrzés | Dimenziómodellezés és összesítés |
| Ki a kívánt felhasználó? |
|
|
|
Példa medallion architektúrára
Ez a példa a medálos architektúrára, amely bronz-, ezüst- és aranyrétegeket mutat be, üzleti üzemeltetési csapat általi használatra. Minden réteg az ops-katalógus egy másik sémájában van tárolva.
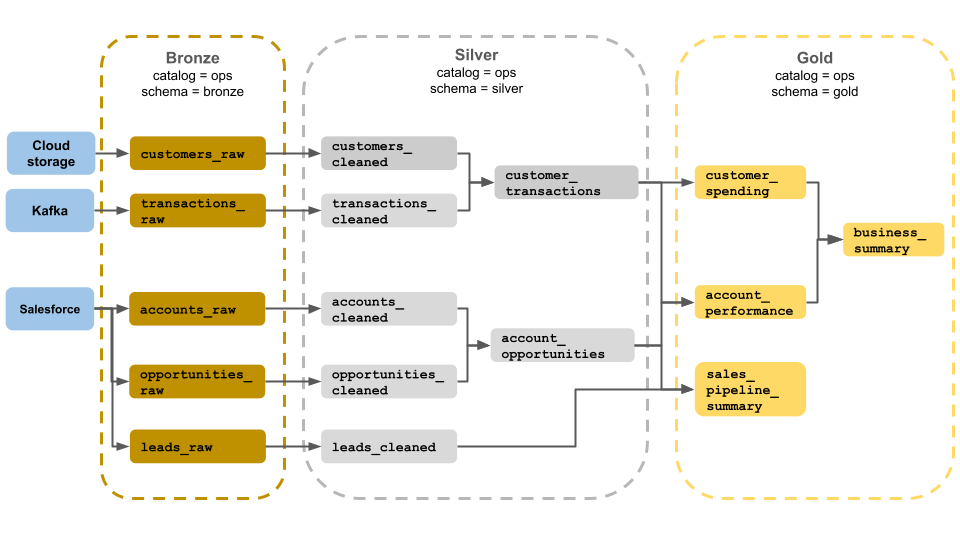
-
Bronz réteg (
ops.bronze): Nyers adatok betöltése a felhőbeli tárolóból, a Kafkából és a Salesforce-ból. Itt nem végez adattisztítást vagy -ellenőrzést. -
Ezüst réteg (
ops.silver): Az adatok törlése és ellenőrzése ebben a rétegben történik.- Az ügyfelekre és tranzakciókra vonatkozó adatokat a null értékek elhagyásával és az érvénytelen rekordok karanténba helyezésével tisztítják meg. Ezek az adathalmazok egy új adathalmazzá egyesülnek, amit
customer_transactions-nak neveznek. Az adattudósok ezt az adatkészletet prediktív elemzésre használhatják. - Hasonlóképpen, a Salesforce-ból származó fiókok és lehetőségadatkészletek is csatlakoznak a létrehozáshoz
account_opportunities, amelyet fiókadatokkal bővítenek. - Az
leads_rawadatok egy úgynevezettleads_cleanedadathalmazban lesznek megtisztítva.
- Az ügyfelekre és tranzakciókra vonatkozó adatokat a null értékek elhagyásával és az érvénytelen rekordok karanténba helyezésével tisztítják meg. Ezek az adathalmazok egy új adathalmazzá egyesülnek, amit
-
Aranyréteg (
ops.gold): Ezt a réteget üzleti felhasználók számára tervezték. Kevesebb adathalmazt tartalmaz, mint az ezüst és az arany.-
customer_spending: Az egyes ügyfelek átlagos és teljes kiadásai. -
account_performance: Minden fiók napi teljesítménye. -
sales_pipeline_summary: Információk a végpontok közötti értékesítési folyamatról. -
business_summary: A vezető munkatársakra vonatkozó, nagymértékben összesített információk.
-
Nyers adatok betöltése a bronz rétegbe
A bronz réteg nyers, páratlan adatokat tartalmaz. A bronzrétegbe betöltött adatok jellemzően a következő jellemzőkkel rendelkeznek:
- Az adatforrás nyers állapotát az eredeti formátumában tartalmazza és tartja karban.
- Növekményesen van hozzáfűzve, és idővel növekszik.
- Olyan számítási feladatok felhasználására szolgál, amelyek ezüsttáblák adatait bővítik, nem elemzők és adattudósok általi hozzáférésre.
- Az igazság egyetlen forrásaként szolgál, megőrizve az adatok hűségét.
- Az összes előzményadat megőrzésével lehetővé teszi az újrafeldolgozást és a naplózást.
- A forrásokból származó streamelési és kötegtranzakciók bármilyen kombinációja lehet, beleértve a felhőobjektum-tárolást (például S3, GCS, ADLS), üzenetbuszokat (például Kafka, Kinesis stb.) és összevont rendszereket (például Lakehouse Federation).
Az adatok törlésének vagy érvényesítésének korlátozása
A minimális adatérvényesítés a bronzrétegben történik. Az elvetett adatok elleni védelem érdekében az Azure Databricks azt javasolja, hogy a legtöbb mezőt sztringként, VARIANT-ként vagy binárisként tárolja a váratlan sémaváltozások elleni védelem érdekében. A metaadatok oszlopai hozzáadhatók, például az adatok származása vagy forrása számára (például _metadata.file_name ).
Adatok ellenőrzése és deduplikálása az ezüstrétegben
Az adatok törlése és ellenőrzése ezüst rétegben történik.
Ezüsttáblák készítése a bronz rétegből
Az ezüstréteg létrehozásához olvasson be egy vagy több bronz vagy ezüst táblából származó adatokat, és írjon adatokat ezüsttáblákba.
Az Azure Databricks nem javasolja, hogy közvetlenül a betöltés után ezüsttáblákra írjon. Amennyiben közvetlenül a betöltésből ír, a sémaváltozások vagy az adatforrásokban található sérült rekordok miatt hibák léphetnek fel. Feltételezve, hogy minden forrás csak hozzáfűzhetőek, konfigurálja úgy a legtöbb olvasást a bronz rétegből, hogy az folyamatos olvasás legyen. A kötegelt olvasásokat érdemes kis adathalmazokhoz (például kis dimenziós táblákhoz) fenntartani.
Az ezüstréteg az adatok érvényesített, megtisztított és bővített verzióit jelöli. Az ezüst réteg:
- Minden rekordnak mindig tartalmaznia kell legalább egy ellenőrzött, nem összesített ábrázolását. Ha az aggregátum-reprezentációk számos alsóbb rétegbeli számítási feladatot vezetnek, ezek a reprezentációk lehetnek az ezüstrétegben, de általában az aranyrétegben találhatók.
- Itt végezhet adattisztítást, deduplikációt és normalizálást.
- A hibák és inkonzisztenciák javításával javítja az adatminőséget.
- Az adatokat az alsóbb rétegbeli feldolgozáshoz használhatóbb formátumba építi.
Adatminőség kényszerítése
A következő műveleteket ezüsttáblákban hajtjuk végre:
- Séma érvényesítés
- Null és hiányzó értékek kezelése
- Adatdeduplikáció
- Rendelésen kívüli és késedelmes adatproblémák megoldása
- Adatminőség-ellenőrzések és -kényszerítés
- Sémafejlődés
- Típuskonverzió
- Csatlakozik
Adatok modellezésének megkezdése
Az ezüstrétegben gyakran el kell kezdeni az adatmodellezést, beleértve a nagymértékben beágyazott vagy félig strukturált adatok megjelenítésének kiválasztását:
- Használjon
VARIANTadattípust. - Használd a
JSONsztringeket. - Szerkezetek, térképek és tömbök létrehozása.
- A sémák laposítása vagy az adatok normalizálása több táblába.
Erőteljes elemzések aranyréteggel
Az aranyréteg az alsóbb rétegbeli elemzéseket, irányítópultokat, ml-eket és alkalmazásokat meghajtó adatok rendkívül kifinomult nézeteit jeleníti meg. Az aranyréteg adatai gyakran erősen összesítve és szűrve jelennek meg adott időszakokra vagy földrajzi régiókra vonatkozóan. Szemantikailag értelmezhető adathalmazokat tartalmaz, amelyek üzleti funkciókhoz és igényekhez igazodnak.
Az aranyréteg:
- Elemzéshez és jelentéskészítéshez szabott összesített adatokból áll.
- Igazodik az üzleti logikához és követelményekhez.
- A lekérdezések és irányítópultok teljesítményére van optimalizálva.
Igazodás az üzleti logikához és követelményekhez
Az aranyrétegben dimenziómodell használatával modellezheti az adatokat jelentéskészítéshez és elemzéshez kapcsolatok létrehozásával és mértékek definiálásával. Az aranyban lévő adatokhoz hozzáférő elemzőknek képesnek kell lenniük tartományspecifikus adatok keresésére és kérdések megválaszolására.
Mivel az aranyréteg üzleti tartományt modellez, egyes ügyfelek több aranyréteget hoznak létre, hogy megfeleljenek a különböző üzleti igényeknek, például a HR-nek, a pénzügynek és az informatikai részlegnek.
Elemzéshez és jelentéskészítéshez szabott aggregátumok létrehozása
A szervezeteknek gyakran összesített függvényeket kell létrehozniuk az olyan mértékekhez, mint az átlagok, a darabszámok, a maximumok és a minimumok. Ha például a vállalatnak válaszolnia kell a heti összes értékesítéssel kapcsolatos kérdésekre, létrehozhat egy materializált nézetet weekly_sales , amely előre összesíti ezeket az adatokat, hogy az elemzőknek és másoknak ne kelljen újra létrehozniuk a gyakran használt materializált nézeteket.
CREATE OR REPLACE MATERIALIZED VIEW weekly_sales AS
SELECT week,
prod_id,
region,
SUM(units) AS total_units,
SUM(units * rate) AS total_sales
FROM orders
GROUP BY week, prod_id, region
Optimalizálás a lekérdezések és irányítópultok teljesítményéhez
Az aranyrétegű táblák teljesítményre való optimalizálása ajánlott eljárás, mivel ezeket az adathalmazokat gyakran kérdezik le. A nagy mennyiségű előzményadat általában a sliver rétegben érhető el, és nem az aranyrétegben valósul meg.
A költségek szabályozása az adatbetöltés gyakoriságának módosításával
Az adatok betöltésének gyakoriságának meghatározásával szabályozhatja a költségeket.
| Adatbetöltés gyakorisága | Költség | Késleltetés | Deklaratív példák | Eljárási példák |
|---|---|---|---|---|
| Folyamatos növekményes betöltés | Magasabb | Alacsonyabb |
|
|
| Indított fokozatos betöltés | Alacsonyabb | Magasabb |
|
|
| Kötegelt betöltés manuális növekményes betöltéssel | Alacsonyabb | A ritkán végzett futtatások miatt a legmagasabb. |
|