Megjegyzés
Az oldalhoz való hozzáféréshez engedély szükséges. Megpróbálhat bejelentkezni vagy módosítani a címtárat.
Az oldalhoz való hozzáféréshez engedély szükséges. Megpróbálhatja módosítani a címtárat.
A Lakeflow-folyamatok számos új Python kódszerkezetet vezetnek be a folyamat materializált nézeteinek és streamtábláinak meghatározásához. A csővezetékek fejlesztésének Python-támogatása a PySpark DataFrame és a strukturált adatfolyam API-k alapjaira épül.
A Pythonnal és DataFrame-ekkel nem ismert felhasználók számára a Databricks az SQL-felület használatát javasolja. Lásd: Lakeflow-folyamatok kódjának fejlesztése SQL-lel. A két felület közötti döntéshez az SQL és a Python kiválasztása című témakörben talál segítséget.
A Lakeflow-folyamatok Python szintaxisának teljes referenciáját lásd: Lakeflow-folyamatok Python nyelvi referencia.
A Python alapjai folyamatfejlesztéshez
Python folyamatadatkészleteket létrehozó kódnak DataFrame-eket kell visszaadnia.
Az összes Lakeflow-folyamat Python API-ja a pyspark.pipelines modulban van implementálva. A Pythonnal implementált folyamatkódnak explicit módon importálnia kell a pipelines modult a Python-forrás tetején. Példáinkban a következő importálási parancsot használjuk, és a példákban dp-t használjuk arra, hogy pipelines-ra hivatkozzunk.
from pyspark import pipelines as dp
Megjegyzés:
Az Apache Spark™ deklaratív folyamatokat tartalmaz a Spark 4.1-ben, amely a pyspark.pipelines modulon keresztül érhető el. A Databricks Runtime további API-kkal és integrációkkal bővíti ezeket a nyílt forráskódú képességeket a felügyelt éles használathoz.
A nyílt forráskódú pipelines modullal írt kód módosítás nélkül fut az Azure Databricksben. A következő funkciók nem részei az Apache Sparknak:
dp.create_auto_cdc_flowdp.create_auto_cdc_from_snapshot_flow@dp.expect(...)
A folyamat alapértelmezés szerint beolvassa és írja a folyamatkonfiguráció során megadott katalógust és sémát. Lásd: Célkatalógus és sémabeállítása.
A folyamatspecifikus Python-kód egy kritikus módon különbözik a Python-kód más típusaitól: a Python-folyamatkód nem hívja meg közvetlenül az adatbetöltést és -átalakítást végző függvényeket adathalmazok létrehozásához. Ehelyett a Lakeflow-folyamatok az adott folyamatban konfigurált összes forráskódfájlban értelmezik a dp modul dekorátorfüggvényeit, és felépítenek egy adatfolyamgráfot.
Fontos
A folyamat futtatásakor nem várt viselkedés elkerülése érdekében ne tartalmazzon olyan kódot, amely az adathalmazokat definiáló függvényekben esetlegesen mellékhatásokat okoz. A részletekért lásd a Python-referenciát.
Materializált nézet vagy streamelési tábla létrehozása a Pythonnal
Használja a @dp.table-t egy streamelési táblázat létrehozásához a streamelési olvasás eredményeiből. Materializált nézetet hozhat létre a @dp.materialized_view kötegelt olvasás eredményeiből.
Alapértelmezés szerint a materializált nézetek és a streaming táblák nevei a függvénynevekből következtethetők. Az alábbi példakód a materializált nézet és a streamelési tábla létrehozásának alapszintaxisát mutatja be:
Megjegyzés:
Mindkét függvény ugyanarra a táblára hivatkozik a samples katalógusban, és ugyanazt a dekorátor függvényt használja. Ezek a példák kiemelik, hogy a materializált nézetek és streamelési táblák alapszintaxisának egyetlen különbsége a spark.read és a spark.readStreamhasználata.
Nem minden adatforrás támogatja a streamelési olvasásokat. Egyes adatforrásokat mindig streamelési szemantikával kell feldolgozni.
from pyspark import pipelines as dp
@dp.materialized_view()
def basic_mv():
return spark.read.table("samples.nyctaxi.trips")
@dp.table()
def basic_st():
return spark.readStream.table("samples.nyctaxi.trips")
Igény szerint megadhatja a tábla nevét a name dekorátor @dp.table argumentumával. Az alábbi példa ezt a mintát mutatja be egy materializált nézethez és streamelési táblához:
from pyspark import pipelines as dp
@dp.materialized_view(name = "trips_mv")
def basic_mv():
return spark.read.table("samples.nyctaxi.trips")
@dp.table(name = "trips_st")
def basic_st():
return spark.readStream.table("samples.nyctaxi.trips")
Adatok betöltése objektumtárolóból
A folyamatok támogatják az adatok betöltését az Azure Databricks által támogatott összes formátumból. Lásd: Adatformátum beállításai.
Megjegyzés:
A példák az automatikusan a munkaterületére csatlakoztatott /databricks-datasets alatt elérhető adatok felhasználását mutatják be. A Databricks kötetútvonalak vagy felhőalapú URI-k használatát javasolja a felhőobjektum-tárolóban tárolt adatokra való hivatkozáshoz. Lásd: Mik azok a Unity Catalog-kötetek?.
A Databricks az automatikus betöltő és a streamelő táblák használatát javasolja, amikor növekményes betöltési számítási feladatokat konfigurál a felhőobjektum-tárolóban tárolt adatokhoz. Lásd : Mi az automatikus betöltő?.
Az alábbi példa létrehoz egy streamelési táblát JSON-fájlokból az Automatikus betöltő használatával:
from pyspark import pipelines as dp
@dp.table()
def ingestion_st():
return (spark.readStream
.format("cloudFiles")
.option("cloudFiles.format", "json")
.load("/databricks-datasets/retail-org/sales_orders")
)
Az alábbi példa kötegfeldolgozási szemantikával olvas be egy JSON-könyvtárat, és létrehoz egy materializált nézetet.
from pyspark import pipelines as dp
@dp.materialized_view()
def batch_mv():
return spark.read.format("json").load("/databricks-datasets/retail-org/sales_orders")
Adatok validálása az elvárások alapján
Az elvárásokkal adatminőségi korlátozásokat állíthat be és kényszeríthet ki. Lásd: Adatminőség kezelése folyamatelvárásokkal.
Az alábbi kód @dp.expect_or_drop használ egy valid_data nevű elvárás definiálásához, amely az adatbetöltés során null értékű rekordokat ad vissza:
from pyspark import pipelines as dp
@dp.table()
@dp.expect_or_drop("valid_date", "order_datetime IS NOT NULL AND length(order_datetime) > 0")
def orders_valid():
return (spark.readStream
.format("cloudFiles")
.option("cloudFiles.format", "json")
.load("/databricks-datasets/retail-org/sales_orders")
)
A folyamat során definiált materializált nézetek és streamelési táblák lekérdezése
Az alábbi példa négy adatkészletet határoz meg:
- Egy JSON-adatokat betöltő
ordersnevű streamelési tábla. - CSV-adatokat betöltő materializált nézet, amelynek neve
customers. - A
customer_ordersésordersadathalmazok rekordjait összekapcsoló,customersnevű materializált nézet dátumra veti a rendelési időbélyeget, és kiválasztja acustomer_id,order_number,stateésorder_datemezőket. - Egy
daily_orders_by_statenevű materializált nézet, amely összesíti az egyes államok rendeléseinek napi számát.
Megjegyzés:
A folyamat nézeteinek vagy tábláinak lekérdezésekor közvetlenül megadhatja a katalógust és a sémát, vagy használhatja a folyamatban konfigurált alapértelmezett beállításokat. Ebben a példában a orders, customersés customer_orders táblák a folyamathoz konfigurált alapértelmezett katalógusból és sémából vannak megírva és olvasva.
Az örökölt közzétételi mód a LIVE sémával kérdezi le a folyamatban definiált egyéb materializált nézeteket és streamtáblákat. Az új folyamatokban a LIVE sémaszintaxisa csendben figyelmen kívül lesz hagyva. Lásd: LIVE séma (régi változat).
from pyspark import pipelines as dp
from pyspark.sql.functions import col
@dp.table()
@dp.expect_or_drop("valid_date", "order_datetime IS NOT NULL AND length(order_datetime) > 0")
def orders():
return (spark.readStream
.format("cloudFiles")
.option("cloudFiles.format", "json")
.load("/databricks-datasets/retail-org/sales_orders")
)
@dp.materialized_view()
def customers():
return spark.read.format("csv").option("header", True).load("/databricks-datasets/retail-org/customers")
@dp.materialized_view()
def customer_orders():
return (spark.read.table("orders")
.join(spark.read.table("customers"), "customer_id")
.select("customer_id",
"order_number",
"state",
col("order_datetime").cast("int").cast("timestamp").cast("date").alias("order_date"),
)
)
@dp.materialized_view()
def daily_orders_by_state():
return (spark.read.table("customer_orders")
.groupBy("state", "order_date")
.count().withColumnRenamed("count", "order_count")
)
Táblák létrehozása for ciklusban
A Python for ciklusokkal programozott módon hozhat létre több táblát. Ez akkor lehet hasznos, ha számos adatforrással vagy céladatkészletkel rendelkezik, amelyek csak néhány paramétertől függően változnak, így kevesebb teljes kóddal kell karbantartani és kevesebb kódredundanciát eredményezni.
A for ciklus soros sorrendben értékeli ki a logikát, de ha az adathalmazok tervezése befejeződött, a folyamat párhuzamosan futtatja a logikát.
Fontos
Ha ezt a mintát használja adathalmazok definiálásához, győződjön meg arról, hogy a for ciklusnak átadott értékek listája mindig additív. Ha egy folyamatban lévő munkafolyamatban korábban meghatározott adathalmazt kihagy egy későbbi folyamatfuttatásból, akkor az adathalmazt automatikusan eltávolítják a célsémából.
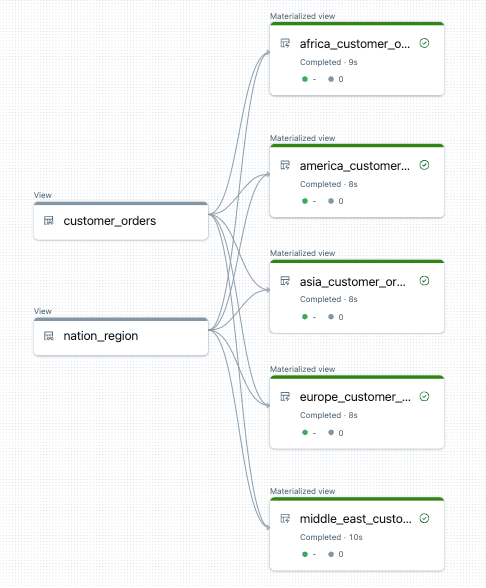
Az alábbi példa öt táblát hoz létre, amelyek régiónként szűrik az ügyfélrendeléseket. Itt a régiónév a cél materializált nézeteinek nevének beállítására és a forrásadatok szűrésére szolgál. Az ideiglenes nézetek a végleges materializált nézetek létrehozásához használt forrástáblákból származó illesztések definiálására szolgálnak.
from pyspark import pipelines as dp
from pyspark.sql.functions import collect_list, col
@dp.temporary_view()
def customer_orders():
orders = spark.read.table("samples.tpch.orders")
customer = spark.read.table("samples.tpch.customer")
return (orders.join(customer, orders.o_custkey == customer.c_custkey)
.select(
col("c_custkey").alias("custkey"),
col("c_name").alias("name"),
col("c_nationkey").alias("nationkey"),
col("c_phone").alias("phone"),
col("o_orderkey").alias("orderkey"),
col("o_orderstatus").alias("orderstatus"),
col("o_totalprice").alias("totalprice"),
col("o_orderdate").alias("orderdate"))
)
@dp.temporary_view()
def nation_region():
nation = spark.read.table("samples.tpch.nation")
region = spark.read.table("samples.tpch.region")
return (nation.join(region, nation.n_regionkey == region.r_regionkey)
.select(
col("n_name").alias("nation"),
col("r_name").alias("region"),
col("n_nationkey").alias("nationkey")
)
)
# Extract region names from region table
region_list = spark.read.table("samples.tpch.region").select(collect_list("r_name")).collect()[0][0]
# Iterate through region names to create new region-specific materialized views
for region in region_list:
@dp.materialized_view(name=f"{region.lower().replace(' ', '_')}_customer_orders")
def regional_customer_orders(region_filter=region):
customer_orders = spark.read.table("customer_orders")
nation_region = spark.read.table("nation_region")
return (customer_orders.join(nation_region, customer_orders.nationkey == nation_region.nationkey)
.select(
col("custkey"),
col("name"),
col("phone"),
col("nation"),
col("region"),
col("orderkey"),
col("orderstatus"),
col("totalprice"),
col("orderdate")
).filter(f"region = '{region_filter}'")
)
Az alábbiakban egy példa látható a folyamat adatfolyam-grafikonjára:
Hibaelhárítás: for hurok számos táblát hoz létre ugyanazokkal az értékekkel
A Python-kód kiértékelésére használt lusta végrehajtási modell megköveteli, hogy a logika közvetlenül hivatkozik az egyes értékekre a @dp.materialized_view() által dekorált függvény meghívásakor.
Az alábbi példa két helyes módszert mutat be a táblák for hurokkal való definiálásához. Mindkét példában a tables listából származó összes táblanévre kifejezetten hivatkozik a @dp.materialized_view()által dekorált függvény.
from pyspark import pipelines as dp
# Create a parent function to set local variables
def create_table(table_name):
@dp.materialized_view(name=table_name)
def t():
return spark.read.table(table_name)
tables = ["t1", "t2", "t3"]
for t_name in tables:
create_table(t_name)
# Call `@dp.materialized_view()` within a for loop and pass values as variables
tables = ["t1", "t2", "t3"]
for t_name in tables:
@dp.materialized_view(name=t_name)
def create_table(table_name=t_name):
return spark.read.table(table_name)
Az alábbi példa nem helyesen hivatkozik a értékekre. Ez a példa különböző nevű táblákat hoz létre, de az összes tábla betölti az adatokat a for ciklus utolsó értékéből:
from pyspark import pipelines as dp
# Don't do this!
tables = ["t1", "t2", "t3"]
for t_name in tables:
@dp.materialized(name=t_name)
def create_table():
return spark.read.table(t_name)
Rekordok végleges törlése materializált nézetből vagy streamelési táblából
Ha véglegesen törölni szeretné a rekordokat egy materializált nézetből vagy streamelőtáblából, és engedélyezve van a törlési vektorok használata, például a GDPR-megfelelőség érdekében, további műveleteket kell végrehajtani az objektum alapjául szolgáló Delta-táblákon. A rekordok materializált nézetből való törlésének biztosításához lásd: Rekordok végleges törlése materializált nézetben, engedélyezett törlési vektorokkal. A rekordok streamelési táblából való törlésének biztosításához lásd: Rekordok végleges törlése streamelési táblából.