MLflow-modellek naplózása, betöltése, regisztrálása és üzembe helyezése
Az MLflow-modell a gépi tanulási modellek csomagolásának szabványos formátuma, amely számos alsóbb rétegbeli eszközben használható– például kötegelt következtetés az Apache Sparkon vagy valós idejű, REST API-n keresztüli kiszolgálás. A formátum egy konvenciót határoz meg, amely lehetővé teszi, hogy a modelleket különböző ízekbe (python-függvény, pytorch, sklearn stb.) mentse, amelyeket a különböző modellkiszolgáló és következtetési platformok is megérthetnek.
A streamelési modellek naplózásáról és pontozásáról a streamelési modellek mentéséről és betöltéséről olvashat.
Modellek naplózása és betöltése
Amikor naplóz egy modellt, az MLflow automatikusan naplózza és conda.yaml fájlokatrequirements.txt. Ezekkel a fájlokkal újra létrehozhatja a modellfejlesztési környezetet, és újratelepítheti a függőségeket virtualenv az (ajánlott) vagy condaa .
Fontos
Az Anaconda Inc. frissítette anaconda.org csatornákra vonatkozó szolgáltatási feltételeit. Az új szolgáltatási feltételek alapján kereskedelmi licencre lehet szükség, ha az Anaconda csomagolására és terjesztésére támaszkodik. További információért tekintse meg az Anaconda Commercial Edition gyakori kérdéseit . Az Anaconda-csatornák használatára a szolgáltatási feltételek vonatkoznak.
Az 1.18-as verzió előtt naplózott MLflow-modellek (Databricks Runtime 8.3 ML vagy korábbi) alapértelmezés szerint függőségként lettek naplózva a conda defaults csatornával (https://repo.anaconda.com/pkgs/). A licencmódosítás miatt a Databricks leállította a csatorna használatát az defaults MLflow 1.18-s vagy újabb verziójával naplózott modellekhez. Az alapértelmezett naplózott csatorna most conda-forgemár a felügyelt https://conda-forge.org/közösségre mutat .
Ha az MLflow 1.18-a előtt naplózott egy modellt anélkül, hogy kizárta volna a defaults csatornát a modell Conda-környezetéből, előfordulhat, hogy a modell függőségben van a defaults nem kívánt csatornától.
Ha manuálisan szeretné ellenőrizni, hogy egy modell rendelkezik-e ezzel a függőséggel, megvizsgálhatja channel a conda.yaml naplózott modellbe csomagolt fájl értékét. Például egy csatornafüggőséggel rendelkező defaults modell conda.yaml a következőképpen nézhet ki:
channels:
- defaults
dependencies:
- python=3.8.8
- pip
- pip:
- mlflow
- scikit-learn==0.23.2
- cloudpickle==1.6.0
name: mlflow-env
Mivel a Databricks nem tudja megállapítani, hogy az Anaconda-adattár használata engedélyezett-e a modellek kezeléséhez az Anacondával való kapcsolat alatt, a Databricks nem kényszeríti az ügyfeleket semmilyen módosításra. Ha a Anaconda.com adattár használata a Databricks használatával engedélyezett az Anaconda feltételei szerint, nem kell semmilyen lépést tennie.
Ha módosítani szeretné a modell környezetében használt csatornát, újra regisztrálhatja a modellt a modellregisztrációs adatbázisba egy új conda.yamlbeállításjegyzékben. Ezt úgy teheti meg, hogy megadja a csatornát a conda_env paraméterben log_model().
Az API-val kapcsolatos log_model() további információkért tekintse meg az MLflow dokumentációját a modell által használt ízről, például a scikit-learn log_model.
A fájlokról conda.yaml további információt az MLflow dokumentációjában talál.
API-parancsok
A modell MLflow-követő kiszolgálóra való naplózásához használja a következőt mlflow.<model-type>.log_model(model, ...): .
Ha egy korábban naplózott modellt szeretne betölteni következtetésre vagy további fejlesztésre, használja mlflow.<model-type>.load_model(modelpath)modelpath a következő lehetőségek egyikét:
- futtatási relatív elérési út (például
runs:/{run_id}/{model-path}) - Unity Catalog-kötetek elérési útja (például
dbfs:/Volumes/catalog_name/schema_name/volume_name/{path_to_artifact_root}/{model_path}) - MLflow által felügyelt összetevő tárolási útvonala a
dbfs:/databricks/mlflow-tracking/ - regisztrált modell elérési útja (például
models:/{model_name}/{model_stage}).
Az MLflow-modellek betöltésének lehetőségeinek teljes listáját az MLflow dokumentációjában található Összetevők hivatkozása című témakörben találja.
Python MLflow-modellek esetén további lehetőség mlflow.pyfunc.load_model() a modell általános Python-függvényként való betöltésére.
A modell betöltéséhez és az adatpontok pontozásához használhatja az alábbi kódrészletet.
model = mlflow.pyfunc.load_model(model_path)
model.predict(model_input)
Másik lehetőségként exportálhatja a modellt Apache Spark UDF-ként, hogy egy Spark-fürt pontozásához használhassa, akár kötegelt feladatként, akár valós idejű Spark Streaming-feladatként .
# load input data table as a Spark DataFrame
input_data = spark.table(input_table_name)
model_udf = mlflow.pyfunc.spark_udf(spark, model_path)
df = input_data.withColumn("prediction", model_udf())
Naplómodell-függőségek
A modell pontos betöltéséhez győződjön meg arról, hogy a modell függőségei a megfelelő verziókkal vannak betöltve a jegyzetfüzet-környezetbe. A Databricks Runtime 10.5 ML-es vagy újabb verziója esetén az MLflow figyelmezteti, ha a rendszer eltérést észlel az aktuális környezet és a modell függőségei között.
A modellfüggőségek visszaállítását egyszerűsítő további funkciókat a Databricks Runtime 11.0 ML és újabb verziók is tartalmazzák. A Databricks Runtime 11.0 ML-ben és újabb verziókban az ízmodellek esetében pyfunc meghívhatja mlflow.pyfunc.get_model_dependencies a modellfüggőségek lekérését és letöltését. Ez a függvény egy elérési utat ad vissza a függőségi fájlhoz, amelyet aztán a használatával %pip install <file-path>telepíthet. Amikor pySpark UDF-ként tölt be egy modellt, adja meg env_manager="virtualenv" a mlflow.pyfunc.spark_udf hívásban. Ez visszaállítja a modellfüggőségeket a PySpark UDF környezetében, és nem befolyásolja a külső környezetet.
Ezt a funkciót a Databricks Runtime 10.5-ös vagy újabb verziójában is használhatja az MLflow 1.25.0-s vagy újabb verziójának manuális telepítésével:
%pip install "mlflow>=1.25.0"
A modellfüggőségek (Python és nem Python) és az összetevők naplózásáról további információt a naplómodell függőségei című témakörben talál.
Megtudhatja, hogyan naplózhatja a modellfüggőségeket és az egyéni összetevőket a modell kiszolgálásához:
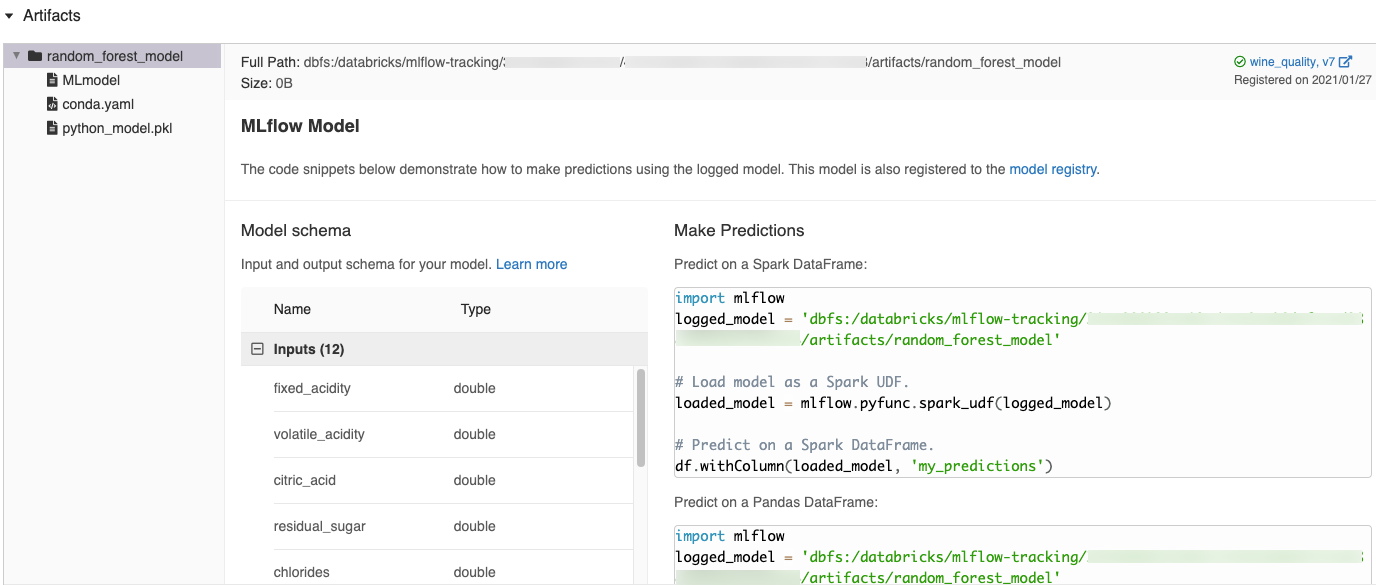
Automatikusan létrehozott kódrészletek az MLflow felhasználói felületén
Amikor egy modellt egy Azure Databricks-jegyzetfüzetbe naplóz, az Azure Databricks automatikusan létrehoz kódrészleteket, amelyeket másolhat és használhat a modell betöltéséhez és futtatásához. A kódrészletek megtekintése:
- Lépjen a modellt létrehozó futtatás futtatási képernyőjére. (Lásd: Jegyzetfüzet-kísérlet megtekintése a Futtatások képernyő megjelenítéséhez.)
- Görgessen az Összetevők szakaszhoz.
- Kattintson a naplózott modell nevére. A jobb oldalon megnyílik egy panel, amelyen a naplózott modell betöltéséhez és előrejelzések készítéséhez használható kód látható a Spark vagy a Pandas DataFrame-eken.
Példák
A naplózási modellekre példákat a Gépi tanulás nyomon követése betanítási példákban talál. A naplózott modell következtetésre való betöltésére példaként tekintse meg a Modell következtetési példáját.
Modellek regisztrálása a Modellregisztrációs adatbázisban
A modellek regisztrálhatók az MLflow-modellregisztrációs adatbázisban, egy központosított modelltárolóban, amely felhasználói felületet és API-készletet biztosít az MLflow-modellek teljes életciklusának kezeléséhez. A Modellregisztrációs adatbázis használatával a Databricks Unity Catalog modelljeinek kezelésére vonatkozó útmutatásért lásd a Modell életciklusának kezelése a Unity Katalógusban című témakört. A munkaterületmodell-beállításjegyzék használatához lásd: Modell életciklusának kezelése a munkaterületmodell-beállításjegyzék használatával (örökölt)
Ha egy modellt az API használatával szeretne regisztrálni, használja a következőt mlflow.register_model("runs:/{run_id}/{model-path}", "{registered-model-name}"): .
Modellek mentése Unity Catalog-kötetekre
Ha helyileg szeretne menteni egy modellt, használja a következőt mlflow.<model-type>.save_model(model, modelpath): . modelpathUnity Catalog-kötetek elérési útjának kell lennie. Ha például Unity Catalog-kötetek helyével dbfs:/Volumes/catalog_name/schema_name/volume_name/my_project_models tárolja a projektmunkát, a modell elérési útját /dbfs/Volumes/catalog_name/schema_name/volume_name/my_project_modelskell használnia:
modelpath = "/dbfs/Volumes/catalog_name/schema_name/volume_name/my_project_models/model-%f-%f" % (alpha, l1_ratio)
mlflow.sklearn.save_model(lr, modelpath)
MLlib-modellek esetében használjon gépi tanulási folyamatokat.
Modellösszetevők letöltése
A naplózott modellösszetevőket (például modellfájlokat, diagramokat és metrikákat) letöltheti egy regisztrált modellhez különböző API-kkal.
from mlflow.store.artifact.models_artifact_repo import ModelsArtifactRepository
model_uri = MlflowClient.get_model_version_download_uri(model_name, model_version)
ModelsArtifactRepository(model_uri).download_artifacts(artifact_path="")
MlflowClient mlflowClient = new MlflowClient();
// Get the model URI for a registered model version.
String modelURI = mlflowClient.getModelVersionDownloadUri(modelName, modelVersion);
// Or download the model artifacts directly.
File modelFile = mlflowClient.downloadModelVersion(modelName, modelVersion);
CLI-parancs példa:
mlflow artifacts download --artifact-uri models:/<name>/<version|stage>
Modellek üzembe helyezése online kiszolgáláshoz
A Mozaik AI-modellkiszolgálóval REST-végpontként üzemeltetheti a Unity Catalog-modellregisztrációs adatbázisban regisztrált gépi tanulási modelleket. Ezek a végpontok automatikusan frissülnek a modellverziók és azok fázisai alapján.
A modelleket az MLflow beépített üzembehelyezési eszközeivel külső kiszolgáló keretrendszerekben is üzembe helyezheti.