Megjegyzés
Az oldalhoz való hozzáféréshez engedély szükséges. Megpróbálhat bejelentkezni vagy módosítani a címtárat.
Az oldalhoz való hozzáféréshez engedély szükséges. Megpróbálhatja módosítani a címtárat.
Megtudhatja, hogyan vezényelheti a jegyzetfüzeteket, és hogyan modulárisíthatja a kódot a jegyzetfüzetekben. Tekintse meg a példákat, és tudja meg, mikor érdemes alternatív módszereket használni a jegyzetfüzetek orkesztrációjához.
Vezénylési és kód modularizálási módszerek
Az alábbi táblázat a jegyzetfüzetek vezényléséhez és a kód modularizálásához elérhető módszereket hasonlítja össze a jegyzetfüzetekben.
| Módszer | Használati eset | Jegyzetek |
|---|---|---|
| Lakeflow-feladatok | Jegyzetfüzet vezérlése (ajánlott) | Jegyzetfüzetek irányítására ajánlott módszer. A tevékenységfüggőségekkel, ütemezéssel és eseményindítókkal rendelkező összetett munkafolyamatokat támogatja. Robusztus és méretezhető megközelítést biztosít az éles számítási feladatokhoz, de beállításra és konfigurálásra van szükség. |
| dbutils.notebook.run() | Jegyzetfüzet-koordinálás | Használja dbutils.notebook.run(), ha a Feladatok nem támogatják a használati esetet, például a jegyzetfüzetek dinamikus paraméterkészleten való hurkolását.Minden híváshoz új rövid ideig futó feladatot indít el, amely növelheti a többletterhelést, és nem rendelkezik speciális ütemezési funkciókkal. |
| Munkaterület fájlok | Kód modularizálása (ajánlott) | A kód modularizálásához ajánlott módszer. A kódot modularizálja a munkaterületen tárolt újrafelhasználható kódfájlokká. Támogatja a verziókövetést tárakkal és a fejlesztői környezetekkel való integrációt a jobb hibakeresés és az egységtesztelés érdekében. További beállításokat igényel a fájlelérési utak és függőségek kezeléséhez. |
| %run | Kód modularizálása | Használja %run, ha nem fér hozzá a munkaterület fájljaihoz.Más jegyzetfüzetekből származó függvények vagy változók importálása közvetlen futtatással. A prototípus-készítéshez hasznos, de a szorosan összekapcsolt kódot nehezebb karbantartani. Nem támogatja a paraméterátadást vagy a verziókövetést. |
%run és dbutils.notebook.run()
A %run parancs lehetővé teszi, hogy egy másik jegyzetfüzetet is belefoglaljunk egy jegyzetfüzetbe. A %run használatával modulárissá teheti a kódot, ha a támogató függvényeket külön jegyzetfüzetbe helyezi. Az elemzés lépéseit megvalósító jegyzetfüzetek összefűzésére is használható. A %run használata során a rendszer azonnal végrehajtja a meghívott jegyzetfüzetet, és a benne definiált függvények és változók elérhetővé válnak a hívó jegyzetfüzetben.
A dbutils.notebook API kiegészíti a %run, mivel lehetővé teszi paraméterek átadását és egy jegyzetfüzetből származó értékek visszaadát. Ez lehetővé teszi, hogy összetett munkafolyamatokat és csővezetékeket hozzon létre függőségekkel. Lekérheti például a címtárban lévő fájlok listáját, és átadhatja a neveket egy másik jegyzetfüzetnek, ami %runesetén lehetetlen. Feltételes munkafolyamatokat is létrehozhat a visszatérési értékek alapján.
Ellentétben %runa dbutils.notebook.run() metódus egy új feladatot indít el a jegyzetfüzet futtatásához.
A dbutils API-khoz hasonlóan ezek a metódusok is csak Python és Scala nyelven érhetők el. Az dbutils.notebook.run() segítségével azonban meghívhat egy R-jegyzetfüzetet.
Használja a %run a jegyzetfüzet importálásához
Ebben a példában az első jegyzetfüzet meghatároz egy függvényt, reverse amely a második jegyzetfüzetben érhető el, miután a %run varázsutasítást használja a shared-code-notebook végrehajtásához.

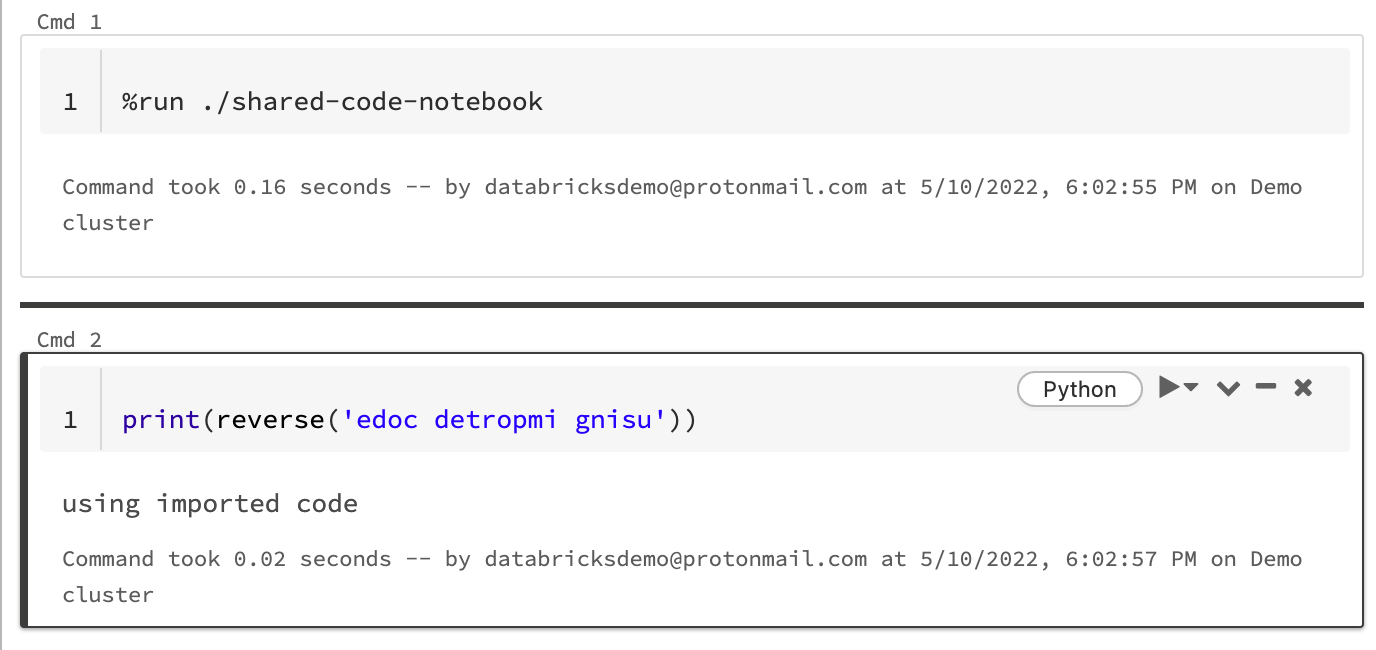
Mivel mindkét jegyzetfüzet ugyanabban a könyvtárban található a munkaterületen, a ././shared-code-notebook előtagot használhatja, hogy jelezze, az elérési utat a jelenleg futó jegyzetfüzethez képest kell feloldani. A jegyzetfüzeteket rendezheti könyvtárakba, például %run ./dir/notebook, vagy használhat abszolút elérési utat, például %run /Users/username@organization.com/directory/notebook.
Megjegyzés
-
%runegy külön cellában kell lennie, mert a teljes jegyzetfüzetet soron belül futtatja. - „Nem lehet használatával futtatni egy Python fájlt, és
%runimportálni a fájlban definiált entitásokat egy jegyzetfüzetbe.” Ha Python fájlból szeretne importálni, olvassa el a A kód fájlokkal való modularizálása című témakört. Vagy csomagolja a fájlt egy Python könyvtárba, hozzon létre egy Azure Databricks library az adott Python könyvtárból, és telepítse a könyvtárat abba a fürtbe, amelyet a jegyzetfüzet futtatásához használ. - Ha widgeteket tartalmazó jegyzetfüzetet futtat
%run, a megadott jegyzetfüzet alapértelmezés szerint a widget alapértelmezett értékeivel fut. Ön is átadhat értékeket a widgeteknek; lásd: Databricks widgetek használata %run.
Új feladat indítása a dbutils.notebook.run használatával
Futtasson egy jegyzetfüzetet, és adja vissza a kilépési értékét. A metódus elindít egy rövid élettartamú feladatot, amely azonnal lefut.
Az API-ban dbutils.notebook elérhető metódusok a következők run : és exit. A paramétereknek és a visszatérési értékeknek sztringeknek kell lenniük.
run(path: String, timeout_seconds: int, arguments: Map): String
A timeout_seconds paraméter szabályozza a futtatás időtúllépését (a 0 azt jelenti, hogy nincs időtúllépés). A hívás run kivételt eredményez, ha az nem fejeződik be a megadott időn belül. Ha Azure Databricks több mint 10 percig leállt, a jegyzetfüzet futtatása timeout_seconds függetlenül meghiúsul.
A arguments paraméter beállítja a céljegyzetfüzet widgetértékét. Pontosabban, ha a futtatott jegyzetfüzetben van egy A nevű widget, és a ("A": "B") hívásnál az argumentumok részeként egy kulcs-érték párt run() ad meg, akkor a A widget értékének lekérésekor az visszaadja a "B"-t. A widgetek létrehozásához és használatához szükséges utasításokat a Databricks widgetek oldalán találja.
Megjegyzés
- A
argumentsparaméter csak latin karaktereket fogad el (ASCII-karakterkészlet). A nem ASCII-karakterek használata hibát ad vissza. - Az
dbutils.notebookAPI-val létrehozott feladatoknak legalább 30 nap alatt be kell fejeződniük.
run Használat
Python
dbutils.notebook.run("notebook-name", 60, {"argument": "data", "argument2": "data2", ...})
Scala
dbutils.notebook.run("notebook-name", 60, Map("argument" -> "data", "argument2" -> "data2", ...))
Strukturált adatok átadása jegyzetfüzetek között
Ez a szakasz bemutatja, hogyan továbbíthat strukturált adatokat a jegyzetfüzetek között.
Python
# Example 1 - returning data through temporary views.
# You can only return one string using dbutils.notebook.exit(), but since called notebooks reside in the same JVM, you can
# return a name referencing data stored in a temporary view.
## In callee notebook
spark.range(5).toDF("value").createOrReplaceGlobalTempView("my_data")
dbutils.notebook.exit("my_data")
## In caller notebook
returned_table = dbutils.notebook.run("LOCATION_OF_CALLEE_NOTEBOOK", 60)
global_temp_db = spark.conf.get("spark.sql.globalTempDatabase")
display(table(global_temp_db + "." + returned_table))
# Example 2 - returning data through DBFS.
# For larger datasets, you can write the results to DBFS and then return the DBFS path of the stored data.
## In callee notebook
dbutils.fs.rm("/tmp/results/my_data", recurse=True)
spark.range(5).toDF("value").write.format("parquet").save("dbfs:/tmp/results/my_data")
dbutils.notebook.exit("dbfs:/tmp/results/my_data")
## In caller notebook
returned_table = dbutils.notebook.run("LOCATION_OF_CALLEE_NOTEBOOK", 60)
display(spark.read.format("parquet").load(returned_table))
# Example 3 - returning JSON data.
# To return multiple values, you can use standard JSON libraries to serialize and deserialize results.
## In callee notebook
import json
dbutils.notebook.exit(json.dumps({
"status": "OK",
"table": "my_data"
}))
## In caller notebook
import json
result = dbutils.notebook.run("LOCATION_OF_CALLEE_NOTEBOOK", 60)
print(json.loads(result))
Scala
// Example 1 - returning data through temporary views.
// You can only return one string using dbutils.notebook.exit(), but since called notebooks reside in the same JVM, you can
// return a name referencing data stored in a temporary view.
/** In callee notebook */
sc.parallelize(1 to 5).toDF().createOrReplaceGlobalTempView("my_data")
dbutils.notebook.exit("my_data")
/** In caller notebook */
val returned_table = dbutils.notebook.run("LOCATION_OF_CALLEE_NOTEBOOK", 60)
val global_temp_db = spark.conf.get("spark.sql.globalTempDatabase")
display(table(global_temp_db + "." + returned_table))
// Example 2 - returning data through DBFS.
// For larger datasets, you can write the results to DBFS and then return the DBFS path of the stored data.
/** In callee notebook */
dbutils.fs.rm("/tmp/results/my_data", recurse=true)
sc.parallelize(1 to 5).toDF().write.format("parquet").save("dbfs:/tmp/results/my_data")
dbutils.notebook.exit("dbfs:/tmp/results/my_data")
/** In caller notebook */
val returned_table = dbutils.notebook.run("LOCATION_OF_CALLEE_NOTEBOOK", 60)
display(sqlContext.read.format("parquet").load(returned_table))
// Example 3 - returning JSON data.
// To return multiple values, use standard JSON libraries to serialize and deserialize results.
/** In callee notebook */
// Import jackson json libraries
import com.fasterxml.jackson.module.scala.DefaultScalaModule
import com.fasterxml.jackson.module.scala.experimental.ScalaObjectMapper
import com.fasterxml.jackson.databind.ObjectMapper
// Create a json serializer
val jsonMapper = new ObjectMapper with ScalaObjectMapper
jsonMapper.registerModule(DefaultScalaModule)
// Exit with json
dbutils.notebook.exit(jsonMapper.writeValueAsString(Map("status" -> "OK", "table" -> "my_data")))
/** In caller notebook */
// Import jackson json libraries
import com.fasterxml.jackson.module.scala.DefaultScalaModule
import com.fasterxml.jackson.module.scala.experimental.ScalaObjectMapper
import com.fasterxml.jackson.databind.ObjectMapper
// Create a json serializer
val jsonMapper = new ObjectMapper with ScalaObjectMapper
jsonMapper.registerModule(DefaultScalaModule)
val result = dbutils.notebook.run("LOCATION_OF_CALLEE_NOTEBOOK", 60)
println(jsonMapper.readValue[Map[String, String]](result))
Hibakezelés
Ez a szakasz a hibák kezelését mutatja be.
Python
# Errors throw a WorkflowException.
def run_with_retry(notebook, timeout, args = {}, max_retries = 3):
num_retries = 0
while True:
try:
return dbutils.notebook.run(notebook, timeout, args)
except Exception as e:
if num_retries > max_retries:
raise e
else:
print("Retrying error", e)
num_retries += 1
run_with_retry("LOCATION_OF_CALLEE_NOTEBOOK", 60, max_retries = 5)
Scala
// Errors throw a WorkflowException.
import com.databricks.WorkflowException
// Since dbutils.notebook.run() is just a function call, you can retry failures using standard Scala try-catch
// control flow. Here, we show an example of retrying a notebook a number of times.
def runRetry(notebook: String, timeout: Int, args: Map[String, String] = Map.empty, maxTries: Int = 3): String = {
var numTries = 0
while (true) {
try {
return dbutils.notebook.run(notebook, timeout, args)
} catch {
case e: WorkflowException if numTries < maxTries =>
println("Error, retrying: " + e)
}
numTries += 1
}
"" // not reached
}
runRetry("LOCATION_OF_CALLEE_NOTEBOOK", timeout = 60, maxTries = 5)
Több jegyzetfüzet egyidejű futtatása
Egyszerre több jegyzetfüzetet is futtathat standard Scala és Python szerkezetek, például szálak (Scala, Python) és határidős (Scala, Python). A példajegyzetfüzetek bemutatják, hogyan használhatók ezek a szerkezetek.
- Töltse le a következő négy jegyzetfüzetet. A jegyzetfüzetek a Scalában vannak megírva.
- Importálja a jegyzetfüzeteket a munkaterület egyetlen mappájába.
- Futtassa az egyidejűleg futtatott jegyzetfüzetet.