Megjegyzés
Az oldalhoz való hozzáféréshez engedély szükséges. Megpróbálhat bejelentkezni vagy módosítani a címtárat.
Az oldalhoz való hozzáféréshez engedély szükséges. Megpróbálhatja módosítani a címtárat.
Feljegyzés
A cikkben szereplő manuális hangolási javaslatok nem vonatkoznak a Unity Catalog által felügyelt táblákra, amelyek automatikus fájlméret-finomhangolást használnak. Új táblák esetén használja a Unity Catalog által felügyelt táblákat az alapértelmezett beállításokkal.
A Databricks Runtime 13.3 és újabb verzióiban a Databricks a táblaelrendezéshez a fürtözés használatát javasolja. Lásd: Táblákhoz folyékony klaszterezés használata.
A Databricks prediktív optimalizálás használatát javasolja a táblák automatikus futtatásáhozOPTIMIZE.VACUUM Lásd: A Unity Catalog által felügyelt táblák prediktív optimalizálása.
A Databricks Runtime 10.4 LTS-ben és újabb verziókban az automatikus tömörítés és az optimalizált írások mindig engedélyezve vannak a MERGE, UPDATE és DELETE műveletekhez. Ez a funkció nem tiltható le.
A célfájl méretének manuális vagy automatikus konfigurálására is van lehetőség írásokhoz és műveletekhez OPTIMIZE . Az Azure Databricks számos beállítást automatikusan hangol, és a megfelelő méretű fájlok keresésével automatikusan javítja a táblázat teljesítményét.
A Unity Catalog által felügyelt táblák esetében a Databricks automatikusan hangolja a konfigurációk többségét, ha SQL Warehouse-t vagy Databricks Runtime 11.3 LTS-t vagy újabb verziót használ.
Ha a Databricks Runtime 10.4 LTS-ről vagy az alábbi verzióról frissít számítási feladatot, olvassa el a Frissítés háttérbeli automatikus tömörítésre című témakört.
Mikor kell futtatni? OPTIMIZE
Az automatikus tömörítés és az optimalizált írások csökkentik a fájlproblémákat, de nem helyettesítik teljesen a OPTIMIZEfájlokat. Különösen az 1 TB-nál nagyobb táblák esetében a Databricks azt javasolja, hogy a fájlok további konszolidálása érdekében ütemezés szerint fusson OPTIMIZE . A Databricks a Liquid Clusteringet javasolja az adatátugrás hatékonyságának növelésére. Ha engedélyezve van a folyékony fürtözés, OPTIMIZE automatikusan átrendezi az adatokat a fürtözési kulcsokkal. Lásd: Táblákhoz folyékony klaszterezés használata.
A Unity Catalog által felügyelt táblák esetében a prediktív optimalizálás automatikusan fut OPTIMIZE a prediktív optimalizálást engedélyező táblákon.
Mi az automatikus optimalizálás az Azure Databricksben?
A kifejezés automatikus optimalizálás néha a beállítások autoOptimize.autoCompact és autoOptimize.optimizeWrite által vezérelt funkcionalitást írja le. Ezt a kifejezést visszavonták az egyes beállítások külön-külön történő leírásának javára. Lásd : Automatikus tömörítés és optimalizált írások.
Automatikus tömörítés
Az automatikus tömörítés a kis méretű fájlokat egyesíti a táblapartíciókban a kis fájlproblémák csökkentése érdekében. Szinkron módon fut az írást végrehajtó fürtön, miután az írás sikeres volt, és csak a korábban nem tömörített fájlokat tömöríti.
Az automatikus tömörítés és a prediktív optimalizálás független funkciók, amelyek külön-külön vagy együtt is használhatók. Az automatikus tömörítés az írást végző fürtön fut, míg a prediktív optimalizálás a kiszolgáló nélküli számítással aszinkron módon futtatja a karbantartási műveleteket.
Az automatikus tömörítés konfigurálásához használja az alábbi beállításokat:
| Setting | Delta | Iceberg | Description |
|---|---|---|---|
| Automatikus tömörítés engedélyezése (táblatulajdonság) | autoOptimize.autoCompact |
autoOptimize.autoCompact |
Lehetővé teszi az automatikus tömörítést a táblázat szintjén. |
| Automatikus tömörítés engedélyezése (Spark-munkamenet) | spark.databricks.delta.autoCompact.enabled |
spark.databricks.iceberg.autoCompact.enabled |
Engedélyezi az automatikus tömörítést a munkamenet szintjén. |
| Kimeneti fájl maximális mérete | spark.databricks.delta.autoCompact.maxFileSize |
spark.databricks.iceberg.autoCompact.maxFileSize |
Szabályozza a kimeneti célfájl méretét. |
| Tömörítést aktiváló minimális fájlok | spark.databricks.delta.autoCompact.minNumFiles |
spark.databricks.iceberg.autoCompact.minNumFiles |
Beállítja az automatikus tömörítés aktiválásához szükséges minimális számú kis fájlt egy partícióban vagy táblában. |
Ezek a beállítások a következő beállításokat fogadják el:
| Beállítások | Működés |
|---|---|
auto (ajánlott) |
Hangolja a célfájl méretét, miközben tiszteletben tartja az egyéb autotuning funkciókat. A Databricks Runtime 10.4 LTS-t vagy újabb verziót igényel. |
legacy |
Alias a következőhöz true: . A Databricks Runtime 10.4 LTS-t vagy újabb verziót igényel. |
true |
A célfájl mérete 128 MB. Nincs dinamikus méretezés. |
false |
Kikapcsolja az automatikus tömörítést. A munkamenet szintjén beállítható úgy, hogy felülbírálja az automatikus tömörítést a számítási feladatban módosított összes tábla esetében. |
Feljegyzés
Az Azure Databricks az autotuning használatát javasolja a kimeneti fájlméret táblázatméret alapján történő szabályozásához. Lásd: Autotune-fájlméret táblázatméret alapján.
Optimalizált írási műveletek
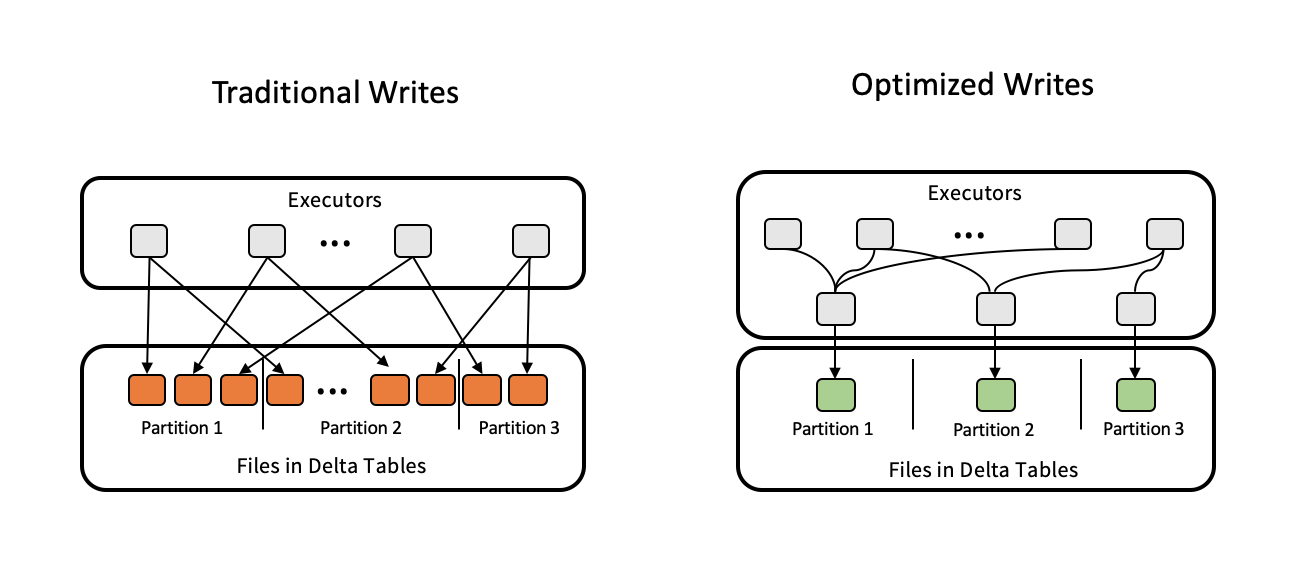
Az optimalizált írások javítják a fájlméretet az adatok írása során, és kihasználják a táblázat későbbi olvasásait.
Az optimalizált írások a particionált táblák esetében a leghatékonyabbak, mivel csökkentik az egyes partíciókra írt kis fájlok számát. Kevesebb nagy fájl írása hatékonyabb, mint sok kis fájl írása, de az írási késés továbbra is nőhet, mivel az adatok össze vannak fonva a megírás előtt.
A következő képen látható az optimalizált írásmód működése:
Feljegyzés
Előfordulhat, hogy fut a kód coalesce(n) vagy repartition(n), közvetlenül az adatok írása előtt, hogy szabályozza a megírt fájlok számát. Az optimalizált írások nem igénylik ezt a mintát.
Az optimalizált írások alapértelmezés szerint engedélyezve vannak a Következő műveletekhez a Databricks Runtime 9.1 LTS és újabb verziókban:
MERGE-
UPDATEalbekérdezésekkel -
DELETEalbekérdezésekkel
Az optimalizált írások az SQL-raktárak használatakor is engedélyezve vannak az CTAS utasításokhoz és a INSERT műveletekhez. A Databricks Runtime 13.3 LTS-ben és újabb verziókban a Unity Katalógusban regisztrált összes tábla optimalizálta a particionált táblákra vonatkozó CTAS utasításokhoz és INSERT műveletekhez engedélyezett írási műveleteket.
Az optimalizált írások a táblázat vagy a munkamenet szintjén engedélyezhetők az alábbi beállításokkal:
- Táblatulajdonság:
autoOptimize.optimizeWrite - SparkSession beállítás:
spark.databricks.delta.optimizeWrite.enabled(Delta) vagyspark.databricks.iceberg.optimizeWrite.enabled(Iceberg)
Ezek a beállítások a következő beállításokat fogadják el:
| Beállítások | Működés |
|---|---|
true |
A célfájl mérete 128 MB. |
false |
Az optimalizált írások kikapcsolása. A munkamenet szintjén beállítható úgy, hogy felülbírálja az automatikus tömörítést a számítási feladatban módosított összes tábla esetében. |
Célfájl méretének beállítása
Ha a táblázat fájljainak méretét szeretné finomhangolni, állítsa a táblázat tulajdonságáttargetFileSize a kívánt méretre. Ha be van állítva, minden adatelrendezési optimalizálási művelet mindent megtesz a megadott méretű fájlok létrehozására, beleértve az optimalizálást, a folyékony fürtözést, az automatikus tömörítést és az optimalizált írásokat.
Feljegyzés
A Unity Catalog által felügyelt táblák és SQL-raktárak, illetve a Databricks Runtime 11.3 LTS és újabb verziók használatakor csak OPTIMIZE a parancsok tartják tiszteletben a targetFileSize beállítást.
| Ingatlan | Description |
|---|---|
delta.targetFileSize (Delta)iceberg.targetFileSize (Jéghegy) |
Típus: Méret bájtban vagy nagyobb egységekben. Leírás: A célfájl mérete. Például 104857600 (bájt) vagy 100mb.Alapértelmezett érték: Nincs |
Meglévő táblák esetén a tulajdonságokat az SQL-parancs ALTER TABLESET TBL PROPERTIESparancsával állíthatja be és törölheti. Ezeket a tulajdonságokat automatikusan is beállíthatja, amikor új táblákat hoz létre Spark-munkamenet-konfigurációkkal. Részletekért tekintse meg a Táblatulajdonságok hivatkozását .
Hangolja be a fájlméretet a tábla mérete alapján
A manuális hangolás szükségességének minimalizálása érdekében az Azure Databricks automatikusan hangolja a táblák fájlméretét a tábla mérete alapján. Az Azure Databricks kisebb fájlméreteket használ a kisebb táblákhoz, a nagyobb táblákhoz pedig nagyobb fájlméreteket, hogy a táblázatban lévő fájlok száma ne nőjön túl nagyra. Az Azure Databricks nem automatikusan hangolja azokat a táblákat, amelyeket adott célmérettel hangolt.
A célfájl mérete a tábla aktuális méretén alapul. 2,56 TB-nál kisebb táblák esetén az automatikusan létrehozott célfájl mérete 256 MB. A 2,56 TB és 10 TB közötti méretű táblák esetében a célméret lineárisan, 256 MB-ról 1 GB-ra nő. 10 TB-nál nagyobb táblák esetén a célfájl mérete 1 GB.
Feljegyzés
Amikor egy tábla célfájlmérete növekszik, a parancs nem optimalizálja újra a OPTIMIZE meglévő fájlokat nagyobb fájlokra. A nagy táblák ezért mindig tartalmazhatnak olyan fájlokat, amelyek kisebbek a célméretnél. Ha ezeket a kisebb fájlokat is nagyobb fájlokra kell optimalizálni, akkor a tábla tulajdonságával konfigurálhat rögzített célfájlméretet a targetFileSize táblához.
Ha egy táblázatot növekményesen ír, a célfájlméretek és -fájlok száma a táblázat méretétől függően közel lesz a következő számokhoz. A táblázatban szereplő fájlszám csak példa. A tényleges eredmények számos tényezőtől függően eltérőek lesznek.
| Tábla mérete | Célfájl mérete | A táblázatban lévő fájlok hozzávetőleges száma |
|---|---|---|
| 10 GB | 256 MB | 40 |
| 1 TB | 256 MB | 4096 |
| 2,56 TB | 256 MB | 10240 |
| 3 TB | 307 MB | 12108 |
| 5 TB (terabájt) | 512 MB | 17339 |
| 7 TB | 716 MB | 20784 |
| 10 terabájt | 1 GB | 24437 |
| 20 TB | 1 GB | 34437 |
| 50 TB | 1 GB | 64437 |
| 100 TB | 1 GB | 114437 |
Adatfájlban írt sorok korlátozása
Időnként előfordulhat, hogy a szűk adatokat tartalmazó táblák olyan hibát tapasztalnak, amely miatt egy adott adatfájl sorainak száma meghaladja a Parquet formátum támogatási korlátait. A hiba elkerülése érdekében az SQL-munkamenet konfigurációjának spark.sql.files.maxRecordsPerFile használatával megadhatja, hogy egy tábla egyetlen fájljába legfeljebb hány rekordot írjon. Nulla vagy negatív érték megadása nem jelent korlátot.
A Databricks Runtime 11.3 LTS-ben és újabb verziókban a DataFrameWriter lehetőséget maxRecordsPerFile is használhatja, ha a DataFrame API-kat használja egy táblába való íráshoz. Ha maxRecordsPerFile meg van adva, a rendszer figyelmen kívül hagyja az SQL-munkamenet-konfiguráció spark.sql.files.maxRecordsPerFile értékét.
Feljegyzés
A Databricks csak akkor javasolja ezt a lehetőséget, ha a fent említett hiba elkerülése érdekében szükséges. Ez a beállítás továbbra is szükséges lehet néhány Unity Catalog által felügyelt, nagyon szűk adattal rendelkező táblához.
Frissítés a háttér automatikus tömörítésére
A háttér automatikus tömörítése a Unity Catalog által felügyelt táblákhoz érhető el a Databricks Runtime 11.3 LTS és újabb verziókban. A háttér automatikus tömörítése nem igényel prediktív optimalizálást. Örökölt számítási feladat vagy tábla áttelepítésekor tegye a következőket:
- Távolítsa el a Spark-konfigurációt
spark.databricks.delta.autoCompact.enabled(Delta) vagyspark.databricks.iceberg.autoCompact.enabled(Iceberg) a fürt vagy a jegyzetfüzet konfigurációs beállításai közül. - Minden táblához futtassa
ALTER TABLE <table_name> UNSET TBLPROPERTIES (delta.autoOptimize.autoCompact)a (Delta) vagyALTER TABLE <table_name> UNSET TBLPROPERTIES (iceberg.autoOptimize.autoCompact)a (Iceberg) parancsot az örökölt automatikus tömörítési beállítások eltávolításához.
Az örökölt konfigurációk eltávolítása után látnia kell, hogy a háttér automatikus tömörítése automatikusan aktiválódik az összes Unity Catalog által felügyelt táblához.