Shiny az Azure Databricksben
A Shiny egy CRAN-en elérhető R-csomag, amely interaktív R-alkalmazások és irányítópultok készítésére szolgál. A Shiny az Azure Databricks-fürtökön üzemeltetett RStudio Serveren belül is használható. A Shiny-alkalmazásokat közvetlenül egy Azure Databricks-jegyzetfüzetből is fejlesztheti, üzemeltetheti és megoszthatja.
A Shiny használatának megkezdéséhez tekintse meg a Shiny-oktatóanyagokat. Ezeket az oktatóanyagokat azure Databricks-jegyzetfüzetekben futtathatja.
Ez a cikk bemutatja, hogyan futtathat Shiny-alkalmazásokat az Azure Databricksen, és hogyan használhatja az Apache Sparkot a Shiny-alkalmazásokban.
Shiny inside R notebooks
Ismerkedés a Shinyvel az R-jegyzetfüzetekben
A Shiny csomag a Databricks Runtime részét képezi. A Shiny-alkalmazásokat interaktívan fejlesztheti és tesztelheti az Azure Databricks R-jegyzetfüzetekben, hasonlóan az üzemeltetett RStudio-hoz.
A kezdéshez hajtsa végre az alábbi lépéseket:
R-jegyzetfüzet létrehozása.
Importálja a Shiny-csomagot, és futtassa a példaalkalmazást
01_helloaz alábbiak szerint:library(shiny) runExample("01_hello")Ha az alkalmazás készen áll, a kimenet tartalmazza a Shiny alkalmazás URL-címét kattintható hivatkozásként, amely új lapot nyit meg. Ha meg szeretné osztani ezt az alkalmazást más felhasználókkal, olvassa el a Shiny-alkalmazás URL-címének megosztása című témakört.

Feljegyzés
- A naplóüzenetek a parancs eredményében jelennek meg, hasonlóan a példában látható alapértelmezett naplóüzenethez (
Listening on http://0.0.0.0:5150). - A Shiny alkalmazás leállításához kattintson a Mégse gombra.
- A Shiny alkalmazás a jegyzetfüzet R-folyamatát használja. Ha leválasztja a jegyzetfüzetet a fürtről, vagy megszakítja az alkalmazást futtató cellát, a Shiny alkalmazás leáll. Nem futtathat más cellákat, amíg a Shiny alkalmazás fut.
Shiny-alkalmazások futtatása a Databricks Git-mappákból
A Databricks Git-mappákba bejelentkezett Shiny-alkalmazásokat futtathatja.
Futtassa az alkalmazást.
library(shiny) runApp("006-tabsets")
Shiny-alkalmazások futtatása fájlokból
Ha a Shiny-alkalmazáskód egy verziókövetés által felügyelt projekt része, futtathatja a jegyzetfüzetben.
Feljegyzés
Az abszolút elérési utat kell használnia, vagy be kell állítania a munkakönyvtárat.setwd()
Tekintse meg a kódot egy adattárból a következőhöz hasonló kód használatával:
%sh git clone https://github.com/rstudio/shiny-examples.git cloning into 'shiny-examples'...Az alkalmazás futtatásához írja be a következőhöz hasonló kódot egy másik cellába:
library(shiny) runApp("/databricks/driver/shiny-examples/007-widgets/")
Shiny-alkalmazás URL-címének megosztása
Az alkalmazás indításakor létrehozott Shiny-alkalmazás URL-címe megosztható más felhasználókkal. Minden Olyan Azure Databricks-felhasználó megtekintheti és kezelheti az alkalmazást, aki rendelkezik a FÜRT ENGEDÉLYÉVEL, mindaddig, amíg az alkalmazás és a fürt fut.
Ha az alkalmazás által futtatott fürt leáll, az alkalmazás már nem érhető el. A fürt beállításai között letilthatja az automatikus leállítást .
Ha egy másik fürtön csatolja és futtatja a Shiny alkalmazást futtató jegyzetfüzetet, a Shiny URL-címe megváltozik. Ha ugyanazon a fürtön újraindítja az alkalmazást, a Shiny másik véletlenszerű portot is választhat. A stabil URL-cím biztosításához megadhatja a shiny.port beállítást, vagy ha ugyanazon a fürtön újraindítja az alkalmazást, megadhatja az port argumentumot.
Shiny a üzemeltetett RStudio-kiszolgálón
Követelmények
Fontos
Az RStudio Server Pro használatával le kell tiltania a proxyalapú hitelesítést.
Győződjön meg arról, hogy auth-proxy=1 nincs benne /etc/rstudio/rserver.conf.
A Shiny használatának első lépései a üzemeltetett RStudio Serveren
Nyissa meg az RStudio-t az Azure Databricksben.
Az RStudio-ban importálja a Shiny-csomagot, és futtassa a példaalkalmazást
01_helloaz alábbiak szerint:> library(shiny) > runExample("01_hello") Listening on http://127.0.0.1:3203Megjelenik egy új ablak, amely megjeleníti a Shiny alkalmazást.

Shiny-alkalmazás futtatása R-szkriptből
Ha fényes alkalmazást szeretne futtatni egy R-szkriptből, nyissa meg az R-szkriptet az RStudio szerkesztőben, és kattintson a jobb felső sarokban található Alkalmazás futtatása gombra.

Az Apache Spark használata Shiny-alkalmazásokban
Az Apache Sparkot a Shiny-alkalmazásokban SparkR vagy Sparklyr használatával is használhatja.
A SparkR és a Shiny használata jegyzetfüzetben
library(shiny)
library(SparkR)
sparkR.session()
ui <- fluidPage(
mainPanel(
textOutput("value")
)
)
server <- function(input, output) {
output$value <- renderText({ nrow(createDataFrame(iris)) })
}
shinyApp(ui = ui, server = server)
Sparklyr és Shiny használata jegyzetfüzetben
library(shiny)
library(sparklyr)
sc <- spark_connect(method = "databricks")
ui <- fluidPage(
mainPanel(
textOutput("value")
)
)
server <- function(input, output) {
output$value <- renderText({
df <- sdf_len(sc, 5, repartition = 1) %>%
spark_apply(function(e) sum(e)) %>%
collect()
df$result
})
}
shinyApp(ui = ui, server = server)
library(dplyr)
library(ggplot2)
library(shiny)
library(sparklyr)
sc <- spark_connect(method = "databricks")
diamonds_tbl <- spark_read_csv(sc, path = "/databricks-datasets/Rdatasets/data-001/csv/ggplot2/diamonds.csv")
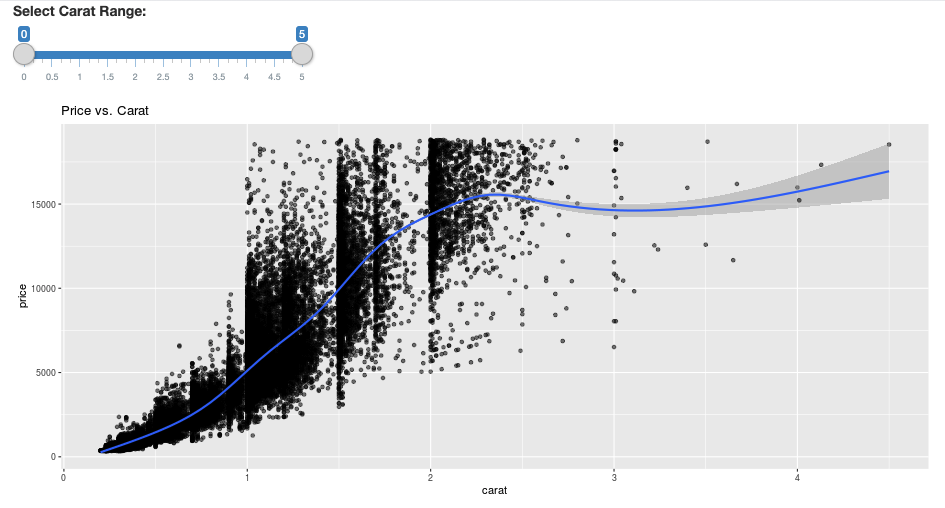
# Define the UI
ui <- fluidPage(
sliderInput("carat", "Select Carat Range:",
min = 0, max = 5, value = c(0, 5), step = 0.01),
plotOutput('plot')
)
# Define the server code
server <- function(input, output) {
output$plot <- renderPlot({
# Select diamonds in carat range
df <- diamonds_tbl %>%
dplyr::select("carat", "price") %>%
dplyr::filter(carat >= !!input$carat[[1]], carat <= !!input$carat[[2]])
# Scatter plot with smoothed means
ggplot(df, aes(carat, price)) +
geom_point(alpha = 1/2) +
geom_smooth() +
scale_size_area(max_size = 2) +
ggtitle("Price vs. Carat")
})
}
# Return a Shiny app object
shinyApp(ui = ui, server = server)
Gyakori kérdések (GYIK)
- Miért szürkítve jelenik meg a Shiny-alkalmazásom egy idő után?
- Miért tűnik el egy idő után a Shiny-megjelenítő ablakom?
- Miért nem térnek vissza a hosszú Spark-feladatok?
- Hogyan kerülhetem el az időtúllépést?
- Az alkalmazásom közvetlenül az indítás után összeomlik, de a kód helyesnek tűnik. Mi történik?
- Hány kapcsolat fogadható el egy Shiny-alkalmazáshivatkozáshoz a fejlesztés során?
- Használhatom a Shiny-csomag más verzióját, mint a Databricks Runtime-ban telepített verziót?
- Hogyan fejleszthetek egy Shiny-alkalmazást, amely közzétehető egy Shiny-kiszolgálón, és hozzáférhetek az Azure Databricks adataihoz?
- Fejleszthetek Shiny-alkalmazást egy Azure Databricks-jegyzetfüzetben?
- Hogyan menthetem az üzemeltetett RStudio-kiszolgálón kifejlesztett Shiny-alkalmazásokat?
Miért szürkítve jelenik meg a Shiny-alkalmazásom egy idő után?
Ha nincs interakció a Shiny alkalmazással, az alkalmazáshoz való kapcsolat körülbelül 4 perc elteltével bezárul.
Az újracsatlakozáshoz frissítse a Shiny alkalmazás oldalát. Az irányítópult állapota alaphelyzetbe áll.
Miért tűnik el egy idő után a Shiny-megjelenítő ablakom?
Ha a Shiny viewer ablaka néhány percig üresjárat után eltűnik, az a "szürke kiszürkített" forgatókönyvvel megegyező időtúllépésnek köszönhető.
Miért nem térnek vissza a hosszú Spark-feladatok?
Ennek oka az üresjárati időtúllépés is. A korábban említett időtúllépéseknél hosszabb ideig futó Spark-feladatok nem tudják megjeleníteni az eredményt, mert a kapcsolat a feladat visszatérése előtt bezárul.
Hogyan kerülhetem el az időtúllépést?
A Szolgáltatáskérésben van egy áthidaló megoldás: Az ügyfél által küldött életben tartás üzenet megakadályozza a TCP időtúllépését néhány terheléselosztón a GitHubon. A megkerülő megoldás szívveréseket küld a WebSocket-kapcsolat életben tartásához, amikor az alkalmazás tétlen. Ha azonban az alkalmazást hosszú ideig futó számítások blokkolják, ez a megkerülő megoldás nem működik.
A Shiny nem támogatja a hosszú ideig futó feladatokat. A Shiny blogbejegyzés azt javasolja, hogy ígéretek és határidős műveletek használatával futtasson hosszú feladatokat aszinkron módon, és ne tiltsa le az alkalmazást. Íme egy példa, amely szívverésekkel tartja életben a Shiny alkalmazást, és egy hosszú ideig futó Spark-feladatot futtat egy
futureszerkezetben.# Write an app that uses spark to access data on Databricks # First, install the following packages: install.packages(‘future’) install.packages(‘promises’) library(shiny) library(promises) library(future) plan(multisession) HEARTBEAT_INTERVAL_MILLIS = 1000 # 1 second # Define the long Spark job here run_spark <- function(x) { # Environment setting library("SparkR", lib.loc = "/databricks/spark/R/lib") sparkR.session() irisDF <- createDataFrame(iris) collect(irisDF) Sys.sleep(3) x + 1 } run_spark_sparklyr <- function(x) { # Environment setting library(sparklyr) library(dplyr) library("SparkR", lib.loc = "/databricks/spark/R/lib") sparkR.session() sc <- spark_connect(method = "databricks") iris_tbl <- copy_to(sc, iris, overwrite = TRUE) collect(iris_tbl) x + 1 } ui <- fluidPage( sidebarLayout( # Display heartbeat sidebarPanel(textOutput("keep_alive")), # Display the Input and Output of the Spark job mainPanel( numericInput('num', label = 'Input', value = 1), actionButton('submit', 'Submit'), textOutput('value') ) ) ) server <- function(input, output) { #### Heartbeat #### # Define reactive variable cnt <- reactiveVal(0) # Define time dependent trigger autoInvalidate <- reactiveTimer(HEARTBEAT_INTERVAL_MILLIS) # Time dependent change of variable observeEvent(autoInvalidate(), { cnt(cnt() + 1) }) # Render print output$keep_alive <- renderPrint(cnt()) #### Spark job #### result <- reactiveVal() # the result of the spark job busy <- reactiveVal(0) # whether the spark job is running # Launch a spark job in a future when actionButton is clicked observeEvent(input$submit, { if (busy() != 0) { showNotification("Already running Spark job...") return(NULL) } showNotification("Launching a new Spark job...") # input$num must be read outside the future input_x <- input$num fut <- future({ run_spark(input_x) }) %...>% result() # Or: fut <- future({ run_spark_sparklyr(input_x) }) %...>% result() busy(1) # Catch exceptions and notify the user fut <- catch(fut, function(e) { result(NULL) cat(e$message) showNotification(e$message) }) fut <- finally(fut, function() { busy(0) }) # Return something other than the promise so shiny remains responsive NULL }) # When the spark job returns, render the value output$value <- renderPrint(result()) } shinyApp(ui = ui, server = server)A kezdeti oldalbetöltés óta egy 12 órás korlát van érvényben, amely után a kapcsolat – még ha aktív is – megszakad. Ezekben az esetekben frissítenie kell a Shiny alkalmazást az újracsatlakozáshoz. A mögöttes WebSocket-kapcsolat azonban bármikor bezárható számos tényező miatt, beleértve a hálózati instabilitást vagy a számítógép alvó üzemmódját. A Databricks javasolja a Shiny-alkalmazások újraírását, így nem igényelnek hosszú élettartamú kapcsolatot, és nem támaszkodnak túlzottan a munkamenet állapotára.
Az alkalmazásom közvetlenül az indítás után összeomlik, de a kód helyesnek tűnik. Mi történik?
Az Azure Databricks shiny alkalmazásaiban megjeleníthető adatok teljes mennyisége 50 MB-os korlátot jelent. Ha az alkalmazás teljes adatmérete meghaladja ezt a korlátot, az azonnal összeomlik az indítás után. Ennek elkerülése érdekében a Databricks javasolja az adatméret csökkentését, például a megjelenített adatok lebélyegzésével vagy a képek felbontásának csökkentésével.
Hány kapcsolat fogadható el egy Shiny-alkalmazáshivatkozáshoz a fejlesztés során?
A Databricks legfeljebb 20-et javasol.
Használhatom a Shiny-csomag más verzióját, mint a Databricks Runtime-ban telepített verziót?
Igen. Lásd : Az R-csomagok verziójának javítása.
Hogyan fejleszthetek egy Shiny-alkalmazást, amely közzétehető egy Shiny-kiszolgálón, és hozzáférhetek az Azure Databricks adataihoz?
Bár az Azure Databricksen végzett fejlesztés és tesztelés során természetesen hozzáférhet az adatokhoz a SparkR vagy a Sparklyr használatával, a Shiny-alkalmazások önálló üzemeltetési szolgáltatásban való közzététele után az Azure Databricks adatai és táblái közvetlenül nem érhetők el.
Ahhoz, hogy az alkalmazás az Azure Databricksen kívül működjön, át kell írnia, hogyan férhet hozzá az adatokhoz. Van néhány lehetőség:
- A JDBC/ODBC használatával küldhet lekérdezéseket egy Azure Databricks-fürtnek.
- Használja a Databricks Connectet.
- Közvetlenül hozzáférhet az objektumtároló adataihoz.
A Databricks azt javasolja, hogy az Azure Databricks-megoldások csapatával együttműködve keresse meg a meglévő adat- és elemzési architektúra legjobb megközelítését.
Fejleszthetek Shiny-alkalmazást egy Azure Databricks-jegyzetfüzetben?
Igen, létrehozhat egy Shiny-alkalmazást egy Azure Databricks-jegyzetfüzetben.
Hogyan menthetem az üzemeltetett RStudio-kiszolgálón kifejlesztett Shiny-alkalmazásokat?
Mentheti az alkalmazáskódot a DBFS-en , vagy ellenőrizheti a kódot a verziókövetésben.