Örökölt vizualizációk
Ez a cikk az örökölt Azure Databricks-vizualizációkat ismerteti. Az aktuális vizualizációs támogatásért tekintse meg a Databricks-jegyzetfüzetek vizualizációit .
Az Azure Databricks emellett natív módon támogatja a Python és az R vizualizációs kódtárait, és lehetővé teszi külső kódtárak telepítését és használatát is.
Örökölt vizualizáció létrehozása
Ha egy eredménycellából szeretne örökölt vizualizációt létrehozni, kattintson + és válassza az Örökölt vizualizáció lehetőséget.
Az örökölt vizualizációk számos diagramtípust támogatnak:
Örökölt diagramtípus kiválasztása és konfigurálása
Sávdiagram kiválasztásához kattintson a sávdiagram ikonra  :
:
Másik diagramtípus kiválasztásához kattintson ![]() a sávdiagram jobb oldalára, és válassza ki a diagram típusát.
a sávdiagram jobb oldalára, és válassza ki a diagram típusát.
Örökölt diagram eszköztára
A vonal- és oszlopdiagramok rendelkeznek egy beépített eszköztárral, amely számos különböző ügyféloldali műveletet támogat.
Diagram konfigurálásához kattintson az Ábrázolási beállítások... elemre.
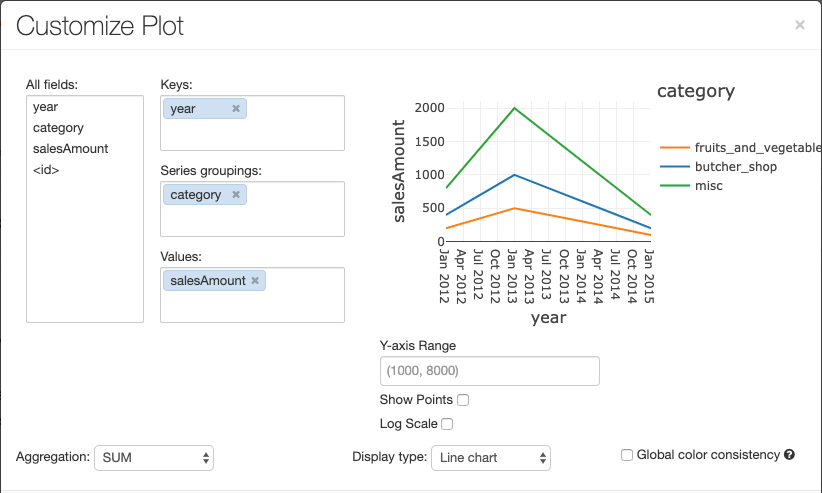
A vonaldiagramok számára több egyéni diagrambeállítás megadható: az Y tengely tartományának beállítása, pontok megjelenítése és elrejtése, vagy az Y tengely megjelenítése logaritmikus skálával.
További információ az örökölt diagramtípusokról:
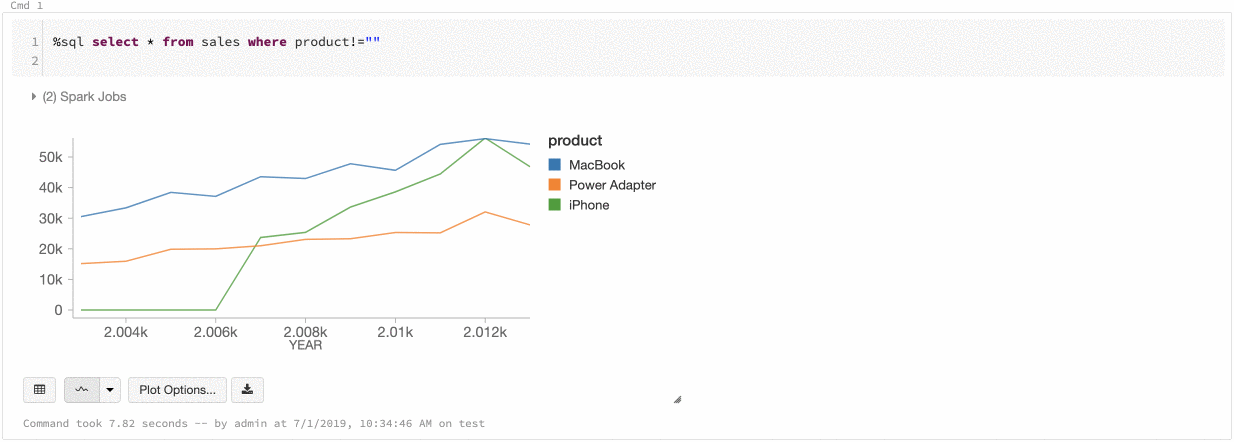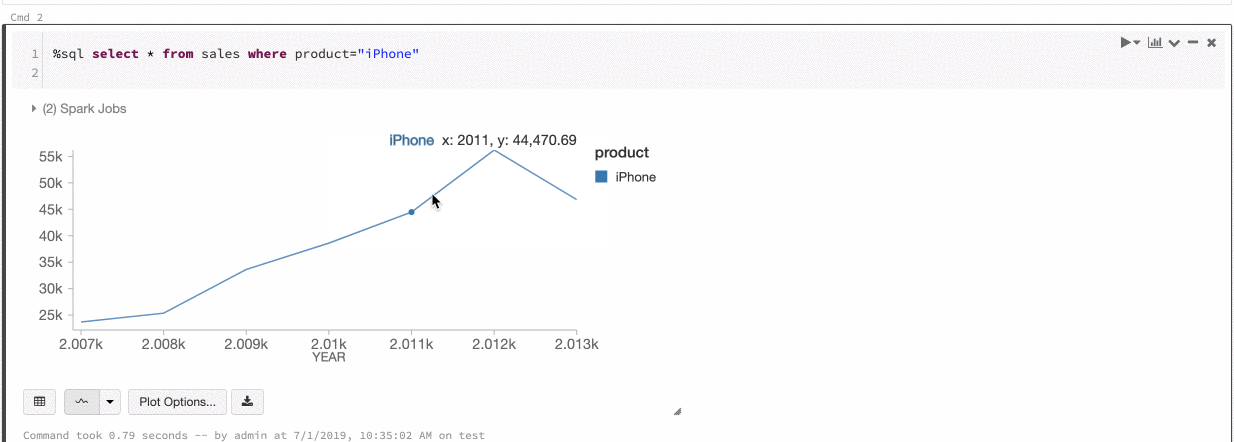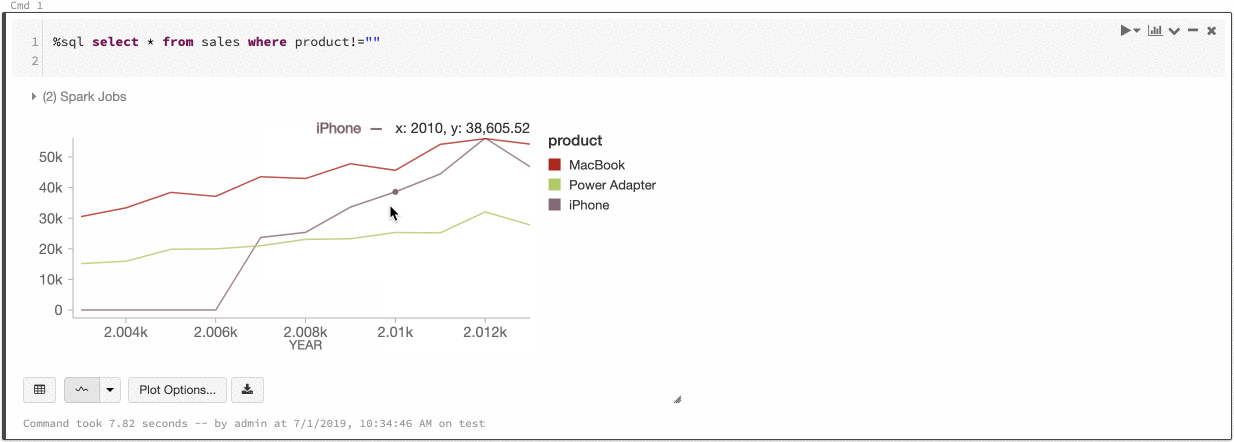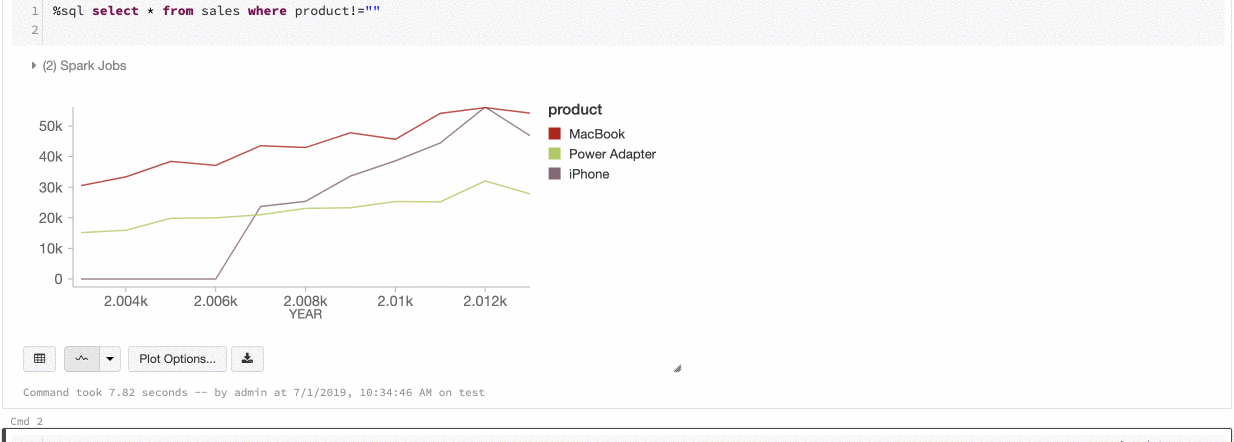
Színkonzisztencia a diagramokban
Az Azure Databricks kétféle színkonzisztenciát támogat az örökölt diagramok között: sorozatkészlet és globális.
A sorozatalapú színkonzisztencia ugyanazt a színt rendeli ugyanahhoz az értékhez, ha azonos értékek sorozatával rendelkezik, de az értékek sorrendje eltér (például: A = ["Apple", "Orange", "Banana"], B = ["Orange", "Banana", "Apple"]). A rendszer rendezi az adatokat az ábrázolás előtt, így minkét jelmagyarázat rendezése ugyanúgy (["Apple", "Banana", "Orange"]) történik, és az azonos értékek ugyanazt a színt kapják. Ha azonban van egy C = ["Orange", "Banana"] sorozata, az nem lenne színkonzisztens az A halmazzal, mert a halmaz nem ugyanaz. A rendezési algoritmus az első színt rendeli a C halmaz „Banana” eleméhez, viszont a második színt az A halmaz „Banana” eleméhez. Ha azt szeretné, hogy ezek a sorozatok színkonzisztensek legyenek, megadhatja, hogy a diagramok globális színkonzisztenciával rendelkezzenek.
A globális színkonzisztencia esetén a rendszer minden értéket mindig ugyanarra a színre képez le, függetlenül attól, hogy milyen értékeket tartalmaz a sorozat. Ha minden diagramhoz engedélyezni szeretné ezt, jelölje be a Globális színkonzisztencia jelölőnégyzetet.
Feljegyzés
Ennek a konzisztenciának elérése érdekében az Azure Databricks közvetlenül az értékekről a színekre kivonatokat ad. Az ütközések elkerülése érdekében (amikor két érték pontosan ugyanazt a színt kapja), a kivonat a színek nagy készletét eredményezi, amivel az jár, hogy a szép megjelenésű vagy könnyen megkülönböztethető színek nem garantálhatók, és sok szín valószínűleg nagyon hasonlóan fog megjelenni.
Gépi tanulási vizualizációk
A hagyományos diagramtípusok mellett az örökölt vizualizációk a következő gépi tanulási betanítási paramétereket és eredményeket támogatják:
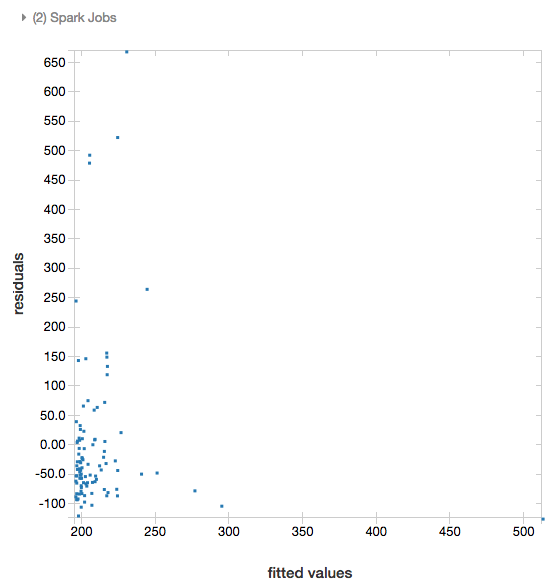
Reziduálisok
Lineáris és logisztikai regressziók esetén egy illesztett és egy reziduális diagramot jeleníthet meg. A diagram beszerzéséhez adja meg a modellt és a DataFrame-et.
Az alábbi példa lineáris regressziót futtat a városi populáción a házak eladási árainak adataira vonatkozóan, majd megjeleníti a reziduálisokat az illesztett adatokkal összevetésben.
# Load data
pop_df = spark.read.csv("/databricks-datasets/samples/population-vs-price/data_geo.csv", header="true", inferSchema="true")
# Drop rows with missing values and rename the feature and label columns, replacing spaces with _
from pyspark.sql.functions import col
pop_df = pop_df.dropna() # drop rows with missing values
exprs = [col(column).alias(column.replace(' ', '_')) for column in pop_df.columns]
# Register a UDF to convert the feature (2014_Population_estimate) column vector to a VectorUDT type and apply it to the column.
from pyspark.ml.linalg import Vectors, VectorUDT
spark.udf.register("oneElementVec", lambda d: Vectors.dense([d]), returnType=VectorUDT())
tdata = pop_df.select(*exprs).selectExpr("oneElementVec(2014_Population_estimate) as features", "2015_median_sales_price as label")
# Run a linear regression
from pyspark.ml.regression import LinearRegression
lr = LinearRegression()
modelA = lr.fit(tdata, {lr.regParam:0.0})
# Plot residuals versus fitted data
display(modelA, tdata)
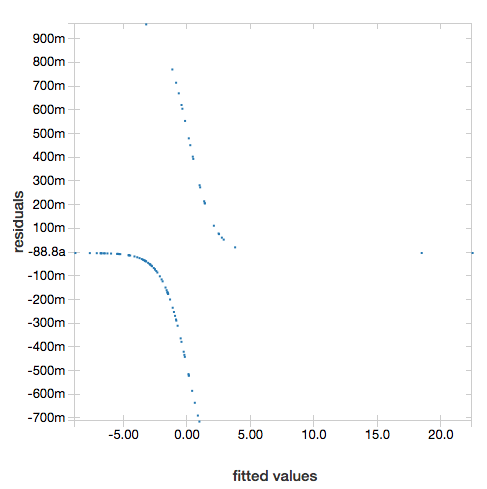
ROC-görbék
Logisztikai regressziók esetén ROC-görbét jeleníthet meg. A diagram beszerzéséhez adja meg a modellt, a metódushoz fit bemenetként megadott előre beírt adatokat és a paramétert "ROC".
Az alábbi példa egy osztályozót fejleszt, amely azt jelzi előre, hogy egy személy =50K vagy >50k évet keres-e <az egyén különböző attribútumaiból. Az Adult adathalmaz népszámlálási adatokból származik, 48 842 személlyel és éves jövedelmükkel kapcsolatos információkból áll.
Az ebben a szakaszban található példakód one-hot kódolást használ.
# This code uses one-hot encoding to convert all categorical variables into binary vectors.
schema = """`age` DOUBLE,
`workclass` STRING,
`fnlwgt` DOUBLE,
`education` STRING,
`education_num` DOUBLE,
`marital_status` STRING,
`occupation` STRING,
`relationship` STRING,
`race` STRING,
`sex` STRING,
`capital_gain` DOUBLE,
`capital_loss` DOUBLE,
`hours_per_week` DOUBLE,
`native_country` STRING,
`income` STRING"""
dataset = spark.read.csv("/databricks-datasets/adult/adult.data", schema=schema)
from pyspark.ml import Pipeline
from pyspark.ml.feature import OneHotEncoder, StringIndexer, VectorAssembler
categoricalColumns = ["workclass", "education", "marital_status", "occupation", "relationship", "race", "sex", "native_country"]
stages = [] # stages in the Pipeline
for categoricalCol in categoricalColumns:
# Category indexing with StringIndexer
stringIndexer = StringIndexer(inputCol=categoricalCol, outputCol=categoricalCol + "Index")
# Use OneHotEncoder to convert categorical variables into binary SparseVectors
encoder = OneHotEncoder(inputCols=[stringIndexer.getOutputCol()], outputCols=[categoricalCol + "classVec"])
# Add stages. These are not run here, but will run all at once later on.
stages += [stringIndexer, encoder]
# Convert label into label indices using the StringIndexer
label_stringIdx = StringIndexer(inputCol="income", outputCol="label")
stages += [label_stringIdx]
# Transform all features into a vector using VectorAssembler
numericCols = ["age", "fnlwgt", "education_num", "capital_gain", "capital_loss", "hours_per_week"]
assemblerInputs = [c + "classVec" for c in categoricalColumns] + numericCols
assembler = VectorAssembler(inputCols=assemblerInputs, outputCol="features")
stages += [assembler]
# Run the stages as a Pipeline. This puts the data through all of the feature transformations in a single call.
partialPipeline = Pipeline().setStages(stages)
pipelineModel = partialPipeline.fit(dataset)
preppedDataDF = pipelineModel.transform(dataset)
# Fit logistic regression model
from pyspark.ml.classification import LogisticRegression
lrModel = LogisticRegression().fit(preppedDataDF)
# ROC for data
display(lrModel, preppedDataDF, "ROC")

A reziduálisok megjelenítéséhez hagyja ki a "ROC" paramétert:
display(lrModel, preppedDataDF)
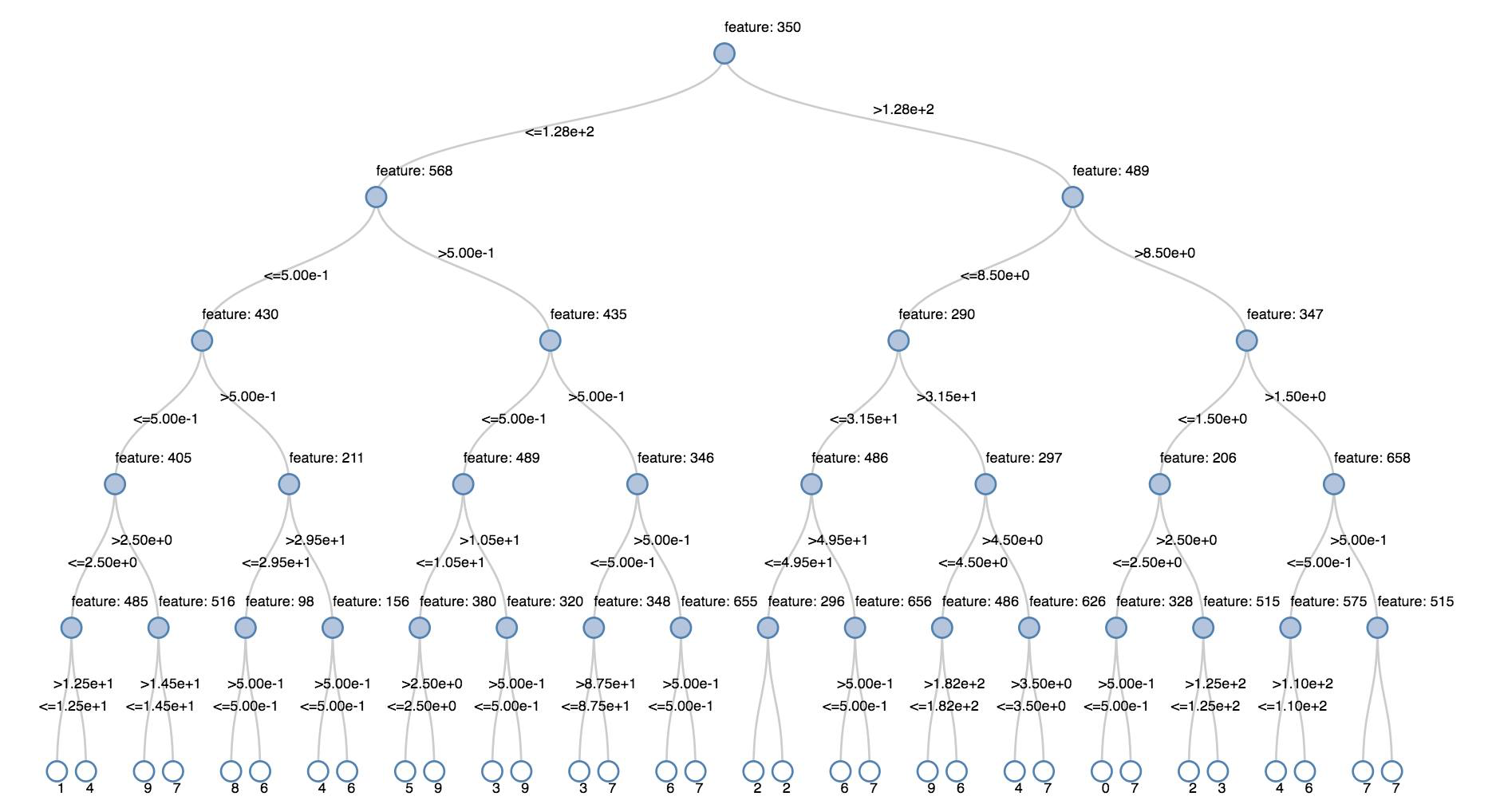
Döntési fák
Az örökölt vizualizációk támogatják a döntési fa megjelenítését.
A vizualizáció beszerzéséhez adja meg a döntési fa modelljét.
Az alábbi példák egy döntési fát tanítanak be a számjegyek (0–9) felismerésére az MNIST kézzel írt számjegyekről készült képeinek adathalmazából, majd megjelenítik a fát.
Python
trainingDF = spark.read.format("libsvm").load("/databricks-datasets/mnist-digits/data-001/mnist-digits-train.txt").cache()
testDF = spark.read.format("libsvm").load("/databricks-datasets/mnist-digits/data-001/mnist-digits-test.txt").cache()
from pyspark.ml.classification import DecisionTreeClassifier
from pyspark.ml.feature import StringIndexer
from pyspark.ml import Pipeline
indexer = StringIndexer().setInputCol("label").setOutputCol("indexedLabel")
dtc = DecisionTreeClassifier().setLabelCol("indexedLabel")
# Chain indexer + dtc together into a single ML Pipeline.
pipeline = Pipeline().setStages([indexer, dtc])
model = pipeline.fit(trainingDF)
display(model.stages[-1])
Scala
val trainingDF = spark.read.format("libsvm").load("/databricks-datasets/mnist-digits/data-001/mnist-digits-train.txt").cache
val testDF = spark.read.format("libsvm").load("/databricks-datasets/mnist-digits/data-001/mnist-digits-test.txt").cache
import org.apache.spark.ml.classification.{DecisionTreeClassifier, DecisionTreeClassificationModel}
import org.apache.spark.ml.feature.StringIndexer
import org.apache.spark.ml.Pipeline
val indexer = new StringIndexer().setInputCol("label").setOutputCol("indexedLabel")
val dtc = new DecisionTreeClassifier().setLabelCol("indexedLabel")
val pipeline = new Pipeline().setStages(Array(indexer, dtc))
val model = pipeline.fit(trainingDF)
val tree = model.stages.last.asInstanceOf[DecisionTreeClassificationModel]
display(tree)
Strukturált streamelési adatkeretek
Egy streamelési lekérdezés eredményének valós idejű megjelenítéséhez a display függvénnyel megjeleníthet egy strukturáltan streamelt adatkeretet Scala vagy Python nyelven.
Python
streaming_df = spark.readStream.format("rate").load()
display(streaming_df.groupBy().count())
Scala
val streaming_df = spark.readStream.format("rate").load()
display(streaming_df.groupBy().count())
A display az alábbi opcionális paramétereket támogatja:
streamName: a streamelési lekérdezés neve.trigger(Scala) ésprocessingTime(Python): a streamelési lekérdezés futtatásának gyakoriságát határozza meg. Ha nincs megadva, a rendszer az előző feldolgozás befejezése után azonnal ellenőrzi, hogy elérhetők-e új adatok. Az éles környezeti költségek csökkentése érdekében a Databricks azt javasolja, hogy mindig állítson be aktiválási időközt. Az alapértelmezett triggerintervallum 500 ms.checkpointLocation: a hely, ahová a rendszer az ellenőrzőpont-információkat írja. Ha nincs megadva, a rendszer automatikusan létrehoz egy ideiglenes ellenőrzőponthelyet a DBFS-ben. Ha azt szeretné, hogy a stream ott folytassa az adatok feldolgozását, ahol abbahagyta, meg kell adnia egy ellenőrzőponthelyet. A Databricks azt javasolja, hogy éles környezetben mindig adja meg acheckpointLocationparamétert.
Python
streaming_df = spark.readStream.format("rate").load()
display(streaming_df.groupBy().count(), processingTime = "5 seconds", checkpointLocation = "dbfs:/<checkpoint-path>")
Scala
import org.apache.spark.sql.streaming.Trigger
val streaming_df = spark.readStream.format("rate").load()
display(streaming_df.groupBy().count(), trigger = Trigger.ProcessingTime("5 seconds"), checkpointLocation = "dbfs:/<checkpoint-path>")
Ezekről a paraméterekről a streamelési lekérdezés indítását ismertető szakaszban talál további információt.
A displayHTML függvény
Az Azure Databricks programozási nyelvi jegyzetfüzetei (Python, R és Scala) a displayHTML függvénnyel támogatják a HTML-grafikákat; a függvénynek bármilyen HTML-, CSS- vagy JavaScript-kódot átadhat. A függvény támogatja az interaktív grafikákat is a JavaScript-kódtárak, például a D3 használatával.
Példák a displayHTML használatára:
Feljegyzés
A displayHTML iframe kiszolgálása a databricksusercontent.com tartományból történik, és az iframe tesztkörnyezet magában foglalja az allow-same-origin attribútumot. A databricksusercontent.com címnek elérhetőnek kell lennie a böngészőből. Ha a vállalati hálózat letiltotta, hozzá kell adni egy engedélyezési listához.
Képek
A képadattípusokat tartalmazó oszlopok gazdag HTML-formátumban jelennek meg. Az Azure Databricks megpróbálja renderelni a Spark ImageSchema-nak DataFramemegfelelő oszlopok miniatűrjeit.
A miniatűrök renderelése a függvényen keresztül spark.read.format('image') sikeresen beolvasott képek esetében működik. A más módon létrehozott képértékek esetén az Azure Databricks az 1, 3 vagy 4 csatornás képek (amelyekben az egyes csatornák egyetlen bájtból állnak) renderelését támogatja, az alábbi korlátozásokkal:
- Egycsatornás képek: A
modemezőnek 0-val kell egyenlőnek lennie. Aheight,widthésnChannelsmezőnek pontosan kell leírnia adatamezőben található bináris képadatokat. - Háromcsatornás képek: A
modemezőnek 16-tal kell egyenlőnek lennie. Aheight,widthésnChannelsmezőnek pontosan kell leírnia adatamezőben található bináris képadatokat. Adatamezőnek képpontadatokat kell tartalmaznia hárombájtos adattömbökben az egyes képpontok csatornasorrendjével(blue, green, red). - Négycsatornás képek: A
modemezőnek 24-gyel kell egyenlőnek lennie. Aheight,widthésnChannelsmezőnek pontosan kell leírnia adatamezőben található bináris képadatokat. Adatamezőnek képpontadatokat kell tartalmaznia négybájtos adattömbökben az egyes képpontok csatornasorrendjével(blue, green, red, alpha).
Példa
Tételezzük fel, hogy van egy képeket tartalmazó mappája:

Ha beolvassa a képeket egy DataFrame-be, majd megjeleníti a DataFrame-et, az Azure Databricks megjeleníti a képek miniatűrjeit:
image_df = spark.read.format("image").load(sample_img_dir)
display(image_df)

Vizualizációk Python nyelven
Ebben a szakaszban:
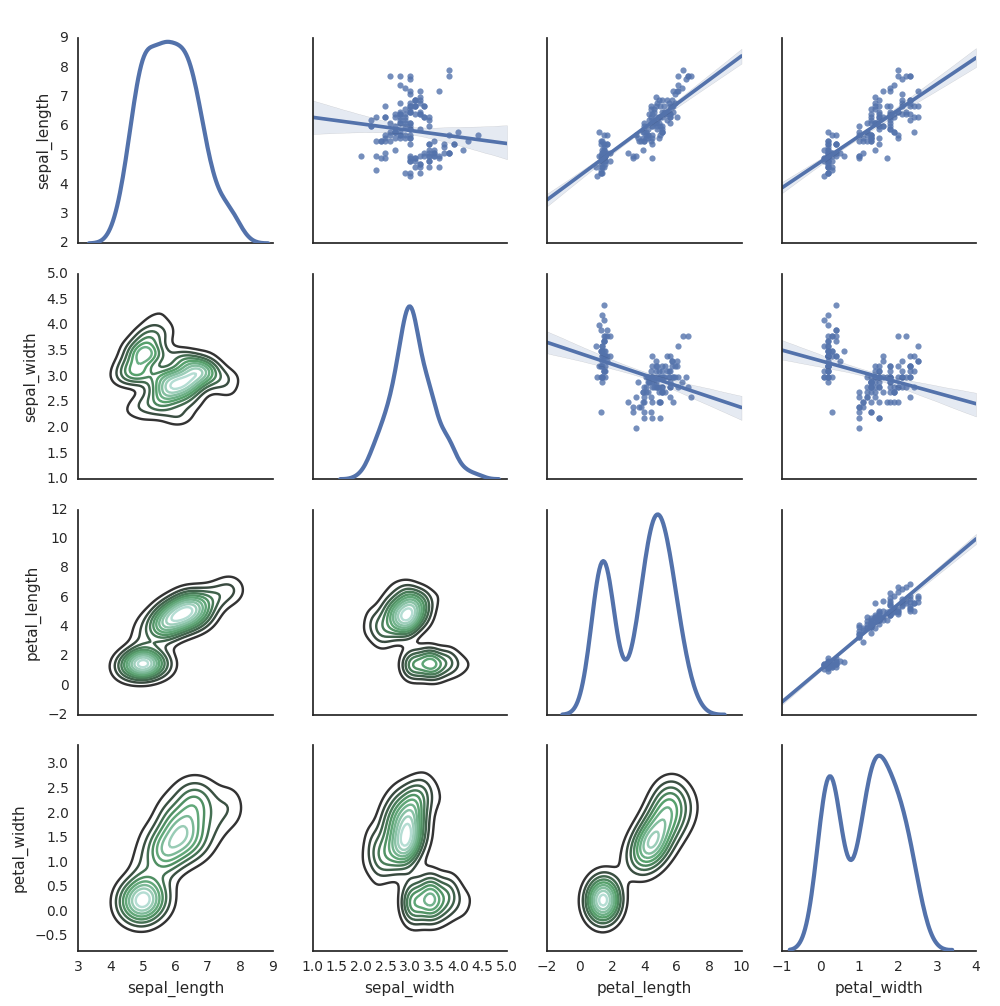
Seaborn
Egyéb Python-kódtárakat is használhat ábrázolások létrehozásához. A Databricks Runtime magában foglalja a seaborn vizualizációs kódtárat. Seaborn-ábrázolás létrehozásához importálja a kódtárat, hozzon létre egy ábrázolást, és adja át a display függvénynek.
import seaborn as sns
sns.set(style="white")
df = sns.load_dataset("iris")
g = sns.PairGrid(df, diag_sharey=False)
g.map_lower(sns.kdeplot)
g.map_diag(sns.kdeplot, lw=3)
g.map_upper(sns.regplot)
display(g.fig)
Egyéb Python-kódtárak
Vizualizációk R nyelven
Az adatok R nyelven történő ábrázolásához az alábbiak szerint használja a display függvényt:
library(SparkR)
diamonds_df <- read.df("/databricks-datasets/Rdatasets/data-001/csv/ggplot2/diamonds.csv", source = "csv", header="true", inferSchema = "true")
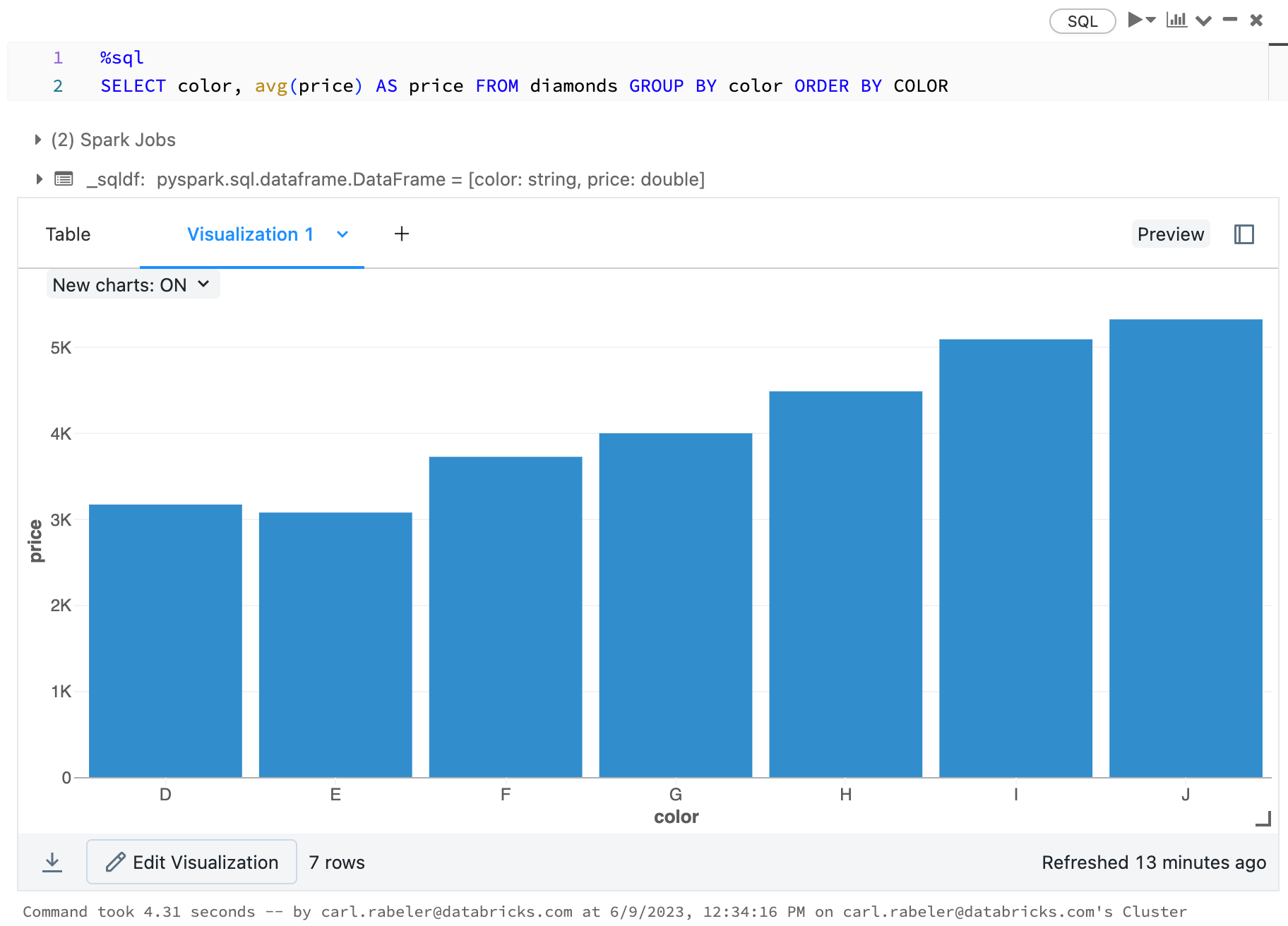
display(arrange(agg(groupBy(diamonds_df, "color"), "price" = "avg"), "color"))
Használja az R alapértelmezett plot függvényét.
fit <- lm(Petal.Length ~., data = iris)
layout(matrix(c(1,2,3,4),2,2)) # optional 4 graphs/page
plot(fit)
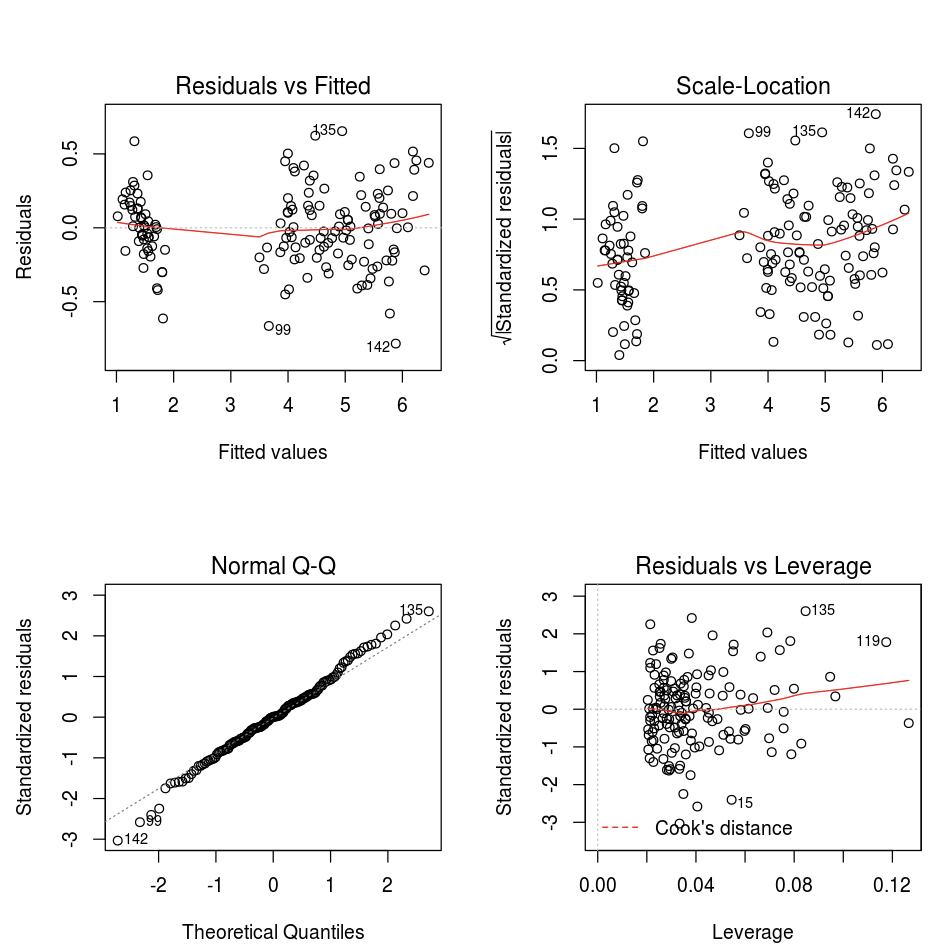
Emellett használhat bármilyen R nyelvű vizualizációs csomagot. Az R-jegyzetfüzet .png fájlként rögzíti az eredményül kapott ábrázolást, és beágyazva jeleníti meg.
Ebben a szakaszban:
Lattice
A Lattice csomag a hálógráfokat támogatja, amelyek egy változót vagy változók közötti viszonyt jelenítenek meg, egy vagy több más változóra vonatkozó feltételhez kötve.
library(lattice)
xyplot(price ~ carat | cut, diamonds, scales = list(log = TRUE), type = c("p", "g", "smooth"), ylab = "Log price")
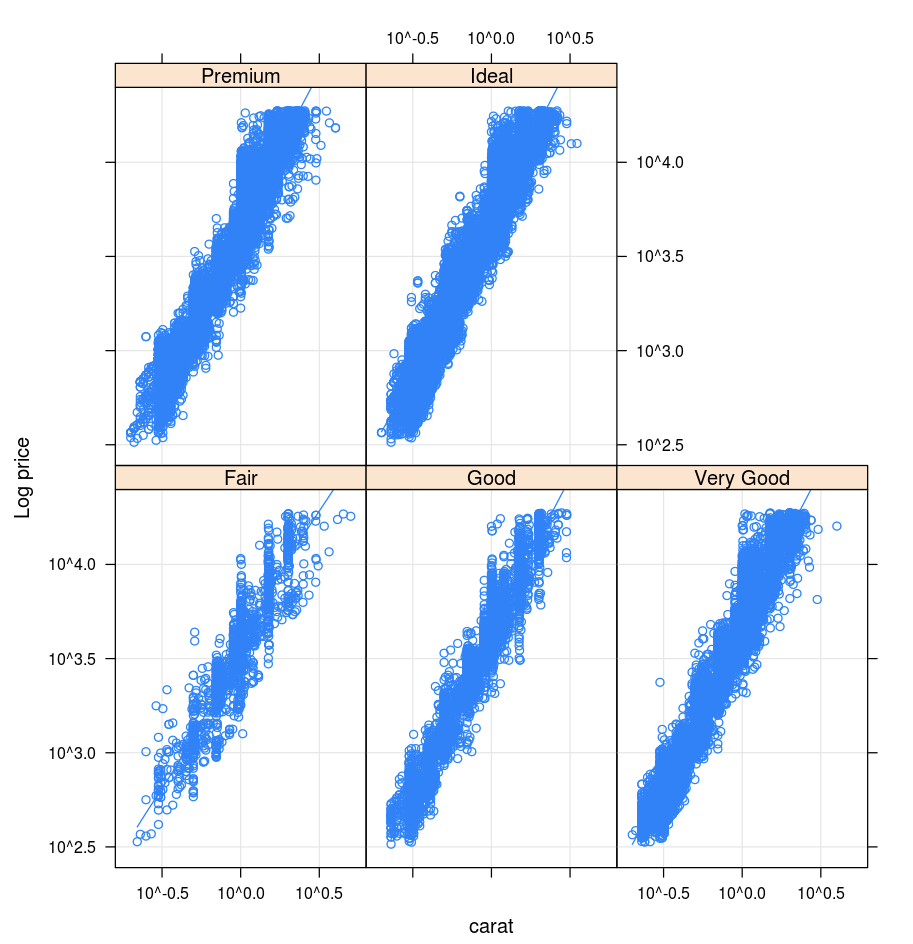
DandEFA
A DandEFA csomag a pitypangábrázolásokat támogatja.
install.packages("DandEFA", repos = "https://cran.us.r-project.org")
library(DandEFA)
data(timss2011)
timss2011 <- na.omit(timss2011)
dandpal <- rev(rainbow(100, start = 0, end = 0.2))
facl <- factload(timss2011,nfac=5,method="prax",cormeth="spearman")
dandelion(facl,bound=0,mcex=c(1,1.2),palet=dandpal)
facl <- factload(timss2011,nfac=8,method="mle",cormeth="pearson")
dandelion(facl,bound=0,mcex=c(1,1.2),palet=dandpal)
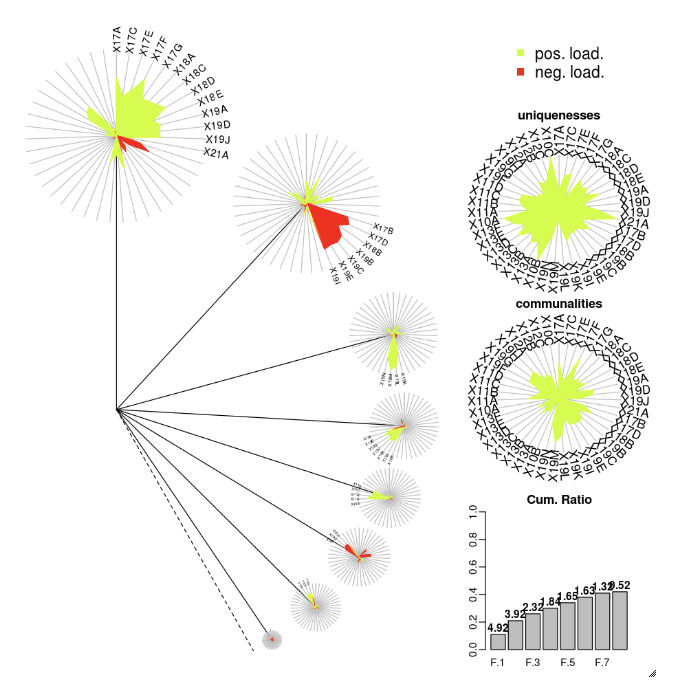
Plotly
A Plotly R csomag az R htmlwidgetjeire támaszkodik. A telepítési utasításokat és a jegyzetfüzetet a htmlwidgets című témakörben találja.
Egyéb R-kódtárak
Vizualizációk Scala nyelven
Az adatok Scala nyelven történő ábrázolásához az alábbiak szerint használja a display függvényt:
val diamonds_df = spark.read.format("csv").option("header","true").option("inferSchema","true").load("/databricks-datasets/Rdatasets/data-001/csv/ggplot2/diamonds.csv")
display(diamonds_df.groupBy("color").avg("price").orderBy("color"))
Mélybe merülő jegyzetfüzetek Pythonhoz és Scalához
A Python-vizualizációk részletes bemutatása a jegyzetfüzetben található:
A Scala-vizualizációk részletes bemutatása a jegyzetfüzetben található: