Table API és SQL Apache Flink-fürtökben® a HDInsighton az AKS-en
Fontos
Ez a szolgáltatás jelenleg előzetes kiadásban elérhető. A Microsoft Azure Előzetes verzió kiegészítő használati feltételei további jogi feltételeket tartalmaznak, amelyek a bétaverzióban, előzetes verzióban vagy egyébként még nem általánosan elérhető Azure-funkciókra vonatkoznak. Erről az adott előzetes verzióról az Azure HDInsight az AKS előzetes verziójában tájékozódhat. Ha kérdése vagy funkciójavaslata van, küldjön egy kérést az AskHDInsightban a részletekkel együtt, és kövessen minket további frissítésekért az Azure HDInsight-közösségről.
Az Apache Flink két relációs API-t tartalmaz – a Table API-t és az SQL-t – az egyesített stream- és kötegelt feldolgozáshoz. A Table API egy nyelvvel integrált lekérdezési API, amely lehetővé teszi a relációs operátorok lekérdezéseinek összetételét, például a kiválasztást, a szűrést és az illesztéseket intuitív módon. Az Flink SQL-támogatása az Apache Calcite-on alapul, amely implementálja az SQL-szabványt.
A Table API és az SQL-felületek zökkenőmentesen integrálhatók egymással és az Flink DataStream API-jával. Könnyedén válthat az összes API és kódtár között, amelyek ezekre épülnek.
Apache Flink SQL
A többi SQL-motorhoz hasonlóan a Flink-lekérdezések is a táblák tetején működnek. Ez eltér a hagyományos adatbázisoktól, mert az Flink nem kezeli helyileg a inaktív adatokat; ehelyett a lekérdezései folyamatosan külső táblákon keresztül működnek.
Az adatfeldolgozási folyamatok forrástáblákkal kezdődnek, és fogadótáblákkal végződnek. A forrástáblák a lekérdezés végrehajtása során futtatott sorokat hoznak létre; ezek a lekérdezés FROM záradékában hivatkozott táblák. A Csatlakozás orok lehetnek HDInsight Kafka, HDInsight HBase, Azure Event Hubs, adatbázisok, fájlrendszerek vagy bármely más rendszer, amelynek összekötője az osztályúton található.
Flink SQL-ügyfél használata AKS-fürtökön a HDInsightban
Ebből a cikkből megtudhatja, hogyan használhatja a PARANCSSOR-t a Secure Shellből az Azure Portalon. Íme néhány gyors példa az első lépésekre.
Az SQL-ügyfél indítása
./bin/sql-client.shInicializálási SQL-fájl átadása az SQL-ügyféllel együtt való futtatáshoz
./sql-client.sh -i /path/to/init_file.sqlKonfiguráció beállítása sql-clientben
SET execution.runtime-mode = streaming; SET sql-client.execution.result-mode = table; SET sql-client.execution.max-table-result.rows = 10000;
SQL DDL
Az Flink SQL a következő CREATE-utasításokat támogatja
- CREATE TABLE
- CREATE DATABASE
- KATALÓGUS LÉTREHOZÁSA
Az alábbi példa szintaxissal definiálhat egy forrástáblát jdbc-összekötővel az MSSQL-hez való csatlakozáshoz, azonosítóval, névvel oszlopként a CREATE TABLE Utasításban
CREATE TABLE student_information (
id BIGINT,
name STRING,
address STRING,
grade STRING,
PRIMARY KEY (id) NOT ENFORCED
) WITH (
'connector' = 'jdbc',
'url' = 'jdbc:sqlserver://servername.database.windows.net;database=dbname;encrypt=true;trustServerCertificate=true;create=false;loginTimeout=30',
'table-name' = 'students',
'username' = 'username',
'password' = 'password'
);
CREATE DATABA Standard kiadás:
CREATE DATABASE students;
KATALÓGUS LÉTREHOZÁSA:
CREATE CATALOG myhive WITH ('type'='hive');
A táblák tetején folyamatos lekérdezéseket futtathat
SELECT id,
COUNT(*) as student_count
FROM student_information
GROUP BY grade;
Írja ki a Fogadó táblába a forrástáblából:
INSERT INTO grade_counts
SELECT id,
COUNT(*) as student_count
FROM student_information
GROUP BY grade;
Függőségek hozzáadása
A JAR utasításokkal felhasználói jar-okat adhat hozzá az osztályúthoz, vagy eltávolíthatja a felhasználói jar-okat az osztályútról, vagy megjelenítheti a hozzáadott jarokat az osztályúton a futtatókörnyezetben.
A Flink SQL a következő JAR-utasításokat támogatja:
- ADD JAR
- JARS MEGJELENÍTÉSE
- JAR ELTÁVOLÍTÁSA
Flink SQL> ADD JAR '/path/hello.jar';
[INFO] Execute statement succeed.
Flink SQL> ADD JAR 'hdfs:///udf/common-udf.jar';
[INFO] Execute statement succeed.
Flink SQL> SHOW JARS;
+----------------------------+
| jars |
+----------------------------+
| /path/hello.jar |
| hdfs:///udf/common-udf.jar |
+----------------------------+
Flink SQL> REMOVE JAR '/path/hello.jar';
[INFO] The specified jar is removed from session classloader.
Hive Metastore apache Flink-fürtökben® a HDInsighton az AKS-en
A katalógusok metaadatokat biztosítanak, például adatbázisokat, táblákat, partíciókat, nézeteket és függvényeket, valamint az adatbázisban vagy más külső rendszerekben tárolt adatok eléréséhez szükséges információkat.
Az AKS-en futó HDInsightban az Flink két katalógusbeállítást támogat:
GenericInMemoryCatalog
A GenericInMemoryCatalog egy katalógus memórián belüli implementációja. Az összes objektum csak az SQL-munkamenet teljes élettartama alatt érhető el.
HiveCatalog
A HiveCatalog két célt szolgál: a tiszta Flink metaadatok állandó tárolójaként, valamint a meglévő Hive-metaadatok olvasásának és írásának felületeként.
Feljegyzés
Az AKS-fürtökön futó HDInsight az Apache Flinkhez készült Hive Metastore integrált lehetőségével rendelkezik. A Hive Metastore-t a fürt létrehozásakor választhatja
Flink-adatbázisok létrehozása és regisztrálása katalógusokban
Ebből a cikkből megtudhatja, hogyan használhatja a parancssori felületet, és hogyan kezdheti el az Flink SQL-ügyfél használatát a Secure Shellből az Azure Portalon.
Munkamenet indítása
sql-client.sh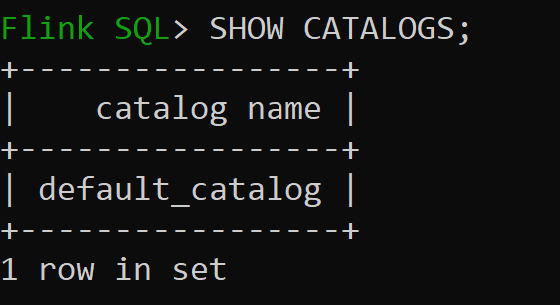
Default_catalog az alapértelmezett memóriabeli katalógus
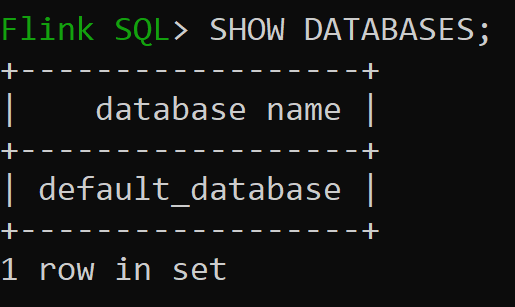
Most nézzük meg a memóriabeli katalógus alapértelmezett adatbázisát
Hozzuk létre a 3.1.2-es verzió Hive-katalógusát, és használjuk
CREATE CATALOG myhive WITH ('type'='hive'); USE CATALOG myhive;Feljegyzés
Az AKS-en futó HDInsight támogatja a Hive 3.1.2-t és a Hadoop 3.3.2-t. A
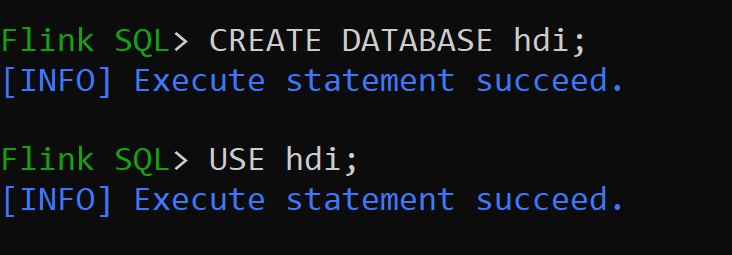
hive-conf-dirbeállítás helye/opt/hive-confHozzuk létre az adatbázist a Hive-katalógusban, és állítsuk be alapértelmezettként a munkamenethez (hacsak nem módosítjuk).
Hive-táblák létrehozása és regisztrálása a Hive-katalógusban
Kövesse a útmutatót a Flink-adatbázisok katalógusba való létrehozásához és regisztrálásához
Hozzuk létre a Hive típusú Hive típusú Flink-táblázatot partíció nélkül
CREATE TABLE hive_table(x int, days STRING) WITH ( 'connector' = 'hive', 'sink.partition-commit.delay'='1 s', 'sink.partition-commit.policy.kind'='metastore,success-file');Adatok beszúrása hive_table
INSERT INTO hive_table SELECT 2, '10'; INSERT INTO hive_table SELECT 3, '20';Adatok olvasása hive_table
Flink SQL> SELECT * FROM hive_table; 2023-07-24 09:46:22,225 INFO org.apache.hadoop.mapred.FileInputFormat[] - Total input files to process : 3 +----+-------------+--------------------------------+ | op | x | days | +----+-------------+--------------------------------+ | +I | 3 | 20 | | +I | 2 | 10 | | +I | 1 | 5 | +----+-------------+--------------------------------+ Received a total of 3 rowsFeljegyzés
A Hive Warehouse Directory az Apache Flink-fürt létrehozása során kiválasztott tárfiók kijelölt tárolójában található, a címtár hive/warehouse/
Lehetővé teszi az összekötő típusú struktúra Flink-táblázatának létrehozását partícióval
CREATE TABLE partitioned_hive_table(x int, days STRING) PARTITIONED BY (days) WITH ( 'connector' = 'hive', 'sink.partition-commit.delay'='1 s', 'sink.partition-commit.policy.kind'='metastore,success-file');
Fontos
Az Apache Flinkben ismert korlátozás van érvényben. A rendszer az utolsó "n" oszlopokat választja ki a partíciókhoz, függetlenül a felhasználó által definiált partícióoszloptól. FLINK-32596 A partíciókulcs hibás lesz, ha az Flink dialektus használatával hozza létre a Hive-táblát.
Referencia
- Apache Flink Table API > SQL
- Az Apache, az Apache Flink, a Flink és a társított nyílt forráskód projektnevek az Apache Software Foundation (ASF) védjegyei.