Mi az Az Apache Spark™ a HDInsightban az AKS-en? előzetes verziója?
Fontos
Ez a szolgáltatás jelenleg előzetes kiadásban elérhető. A Microsoft Azure Előzetes verzió kiegészítő használati feltételei további jogi feltételeket tartalmaznak, amelyek a bétaverzióban, előzetes verzióban vagy egyébként még nem általánosan elérhető Azure-funkciókra vonatkoznak. Erről az adott előzetes verzióról az Azure HDInsight az AKS előzetes verziójában tájékozódhat. Ha kérdése vagy funkciójavaslata van, küldjön egy kérést az AskHDInsightban a részletekkel együtt, és kövessen minket további frissítésekért az Azure HDInsight-közösségről.
Az Apache Spark™ egy párhuzamos feldolgozási keretrendszer, amely támogatja a memórián belüli feldolgozást a big data elemzési alkalmazások teljesítményének növelése érdekében.
Az Apache Spark™ primitíveket biztosít a memórián belüli fürtszámításhoz. A Spark-feladatokkal az adatok betölthetők és gyorsítótárazhatók a memóriába, majd ismétlődő jelleggel lekérdezhetők. A memóriabeli számítástechnika gyorsabb, mint a lemezalapú alkalmazások, például a Hadoop, amelyek hadoop elosztott fájlrendszeren (HDFS) keresztül osztják meg az adatokat. Az Apache Spark lehetővé teszi a Scala- és Python-programozási nyelvekkel való integrációt, hogy az elosztott adathalmazokat, például a helyi gyűjteményeket manipulálhassa. Nem kell mindent térképként rendszerezni és csökkenteni a műveletek számát.
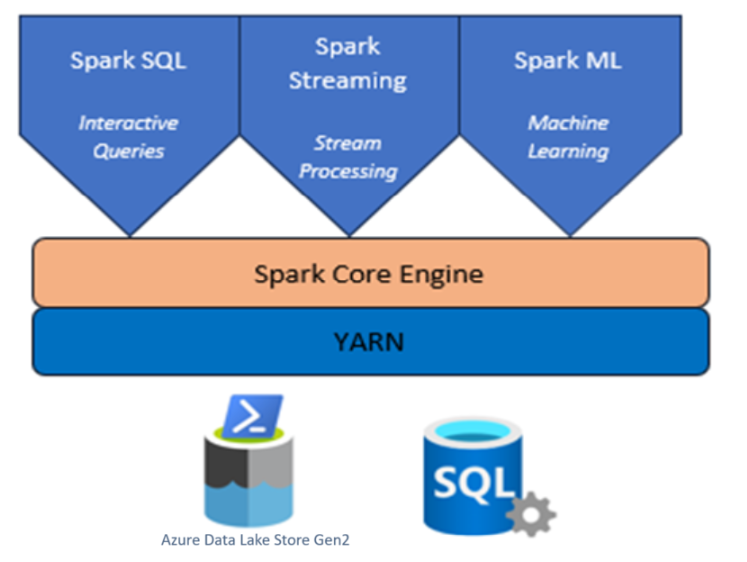
Apache Spark-fürt HDInsighttal az AKS-en
Az Azure HDInsight egy felügyelt, teljes körű, nyílt forráskódú elemzési szolgáltatás vállalatok részére.
Az Apache Spark™ az Azure HDInsight on AKS-ben a Microsoft Azure felügyelt spark szolgáltatása. Az Apache Spark az Azure HDInsightban az AKS-ben tárolhatja és feldolgozhatja az adatokat az Azure-ban. A HDInsight Spark-fürtöi kompatibilisek az Azure Data Lake Storage Gen2-vel, és lehetővé teszik a Spark-feldolgozás alkalmazását a meglévő adattárakon.
Az AKS-en futó HDInsighthoz készült Apache Spark-keretrendszer lehetővé teszi a gyors adatelemzést és a fürt-számítástechnikát memóriabeli feldolgozással. A Jupyter Notebook lehetővé teszi az adatokkal való interakciót, a kód markdown szöveggel való kombinálását és egyszerű vizualizációk használatát.
Apache Spark az AKS-en a HDInsightban, amely több összetevőből áll podként.
Fürtvezérlők
A fürtvezérlők felelősek a megfelelő szolgáltatás telepítéséért és felügyeletéért. A spark-fürtökben különböző vezérlők vannak telepítve és felügyelve.
Apache Spark-szolgáltatás összetevői
Zookeeper szolgáltatás: Három csomópontos Zookeeper-fürt, amely elosztott koordinátorként vagy magas rendelkezésre állású tárolóként szolgál más szolgáltatásokhoz.
Yarn szolgáltatás: Hadoop Yarn-fürt, a Spark-feladatok Yarn-alkalmazásokként lesznek ütemezve a fürtben.
Ügyfélfelületek: Az AKS HDInsightban található Apache Spark-fürtöi különböző ügyfélfelületeket biztosítanak. A Livy Server, a Jupyter Notebook, a Spark History Server Spark-szolgáltatásokat biztosít a HDInsight számára az AKS-felhasználók számára.
Referencia
- Az Apache, az Apache Spark, a Spark és a társított nyílt forráskód projektnevek az Apache Software Foundation (ASF) védjegyei.