Apache Spark-streamelési (DStream) példa az Apache Kafkával a HDInsighton
Megtudhatja, hogyan streamelhet adatokat az Apache Spark használatával a HDInsighton futó Apache Kafkába vagy onnan ki a D adatfolyamok használatával. Ez a példa egy Spark-fürtön futó Jupyter-jegyzetfüzetet használ.
Feljegyzés
A dokumentum lépései olyan Azure-erőforráscsoportot hoznak létre, amely Spark on HDInsight- és Kafka on HDInsight-fürtöt is tartalmaz. Mindkét fürt Azure virtuális hálózatban található, így a Spark-fürt közvetlenül kommunikálhat a Kafka-fürttel.
Amikor végzett a dokumentum lépéseivel, ne felejtse el törölni a fürtöket a további díjak elkerülése érdekében.
Fontos
Ez a példa a D adatfolyamok, amely egy régebbi Spark streamelési technológia. Az újabb Spark-streamelési funkciókat használó példáért tekintse meg a Spark strukturált streamelést az Apache Kafka-dokumentummal .
A fürtök létrehozása
A HDInsighton futó Apache Kafka nem biztosít hozzáférést a Kafka-közvetítőkhöz a nyilvános interneten keresztül. A Kafkával folytatott beszélgetéseknek ugyanabban az Azure-beli virtuális hálózatban kell lenniük, mint a Kafka-fürt csomópontjai. Ebben a példában a Kafka és a Spark-fürtök egy Azure-beli virtuális hálózaton találhatók. Az alábbi ábra bemutatja, hogyan zajlik a kommunikáció a fürtök között:
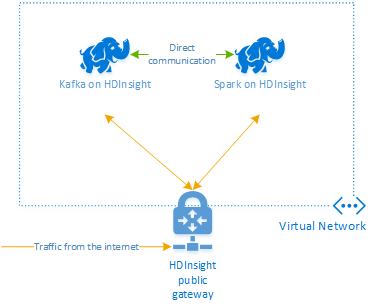
Feljegyzés
Bár maga a Kafka a virtuális hálózaton belüli kommunikációra korlátozódik, a fürt más szolgáltatásai, például az SSH és az Ambari is elérhetők az interneten keresztül. További információ a HDInsighttal elérhető nyilvános portokról: A HDInsight által használt portok és URI-k.
Bár manuálisan is létrehozhat Azure-beli virtuális hálózatot, Kafkát és Spark-fürtöt, egyszerűbben használhat Azure Resource Manager-sablont. Az alábbi lépésekkel üzembe helyezhet egy Azure-beli virtuális hálózatot, Kafkát és Spark-fürtöt az Azure-előfizetésében.
Az alábbi gombbal jelentkezzen be az Azure szolgáltatásba, és nyissa meg a sablont az Azure Portalon.

Figyelmeztetés
A Kafka HDInsighton való rendelkezésre állásának biztosításához a fürtnek legalább négy feldolgozó csomópontot kell tartalmaznia. Ez a sablon létrehoz egy Kafka-fürtöt, amely négy feldolgozó csomópontot tartalmaz.
Ez a sablon létrehoz egy HDInsight 4.0-fürtöt a Kafka és a Spark számára is.
Az egyéni üzembe helyezés szakasz bejegyzéseinek feltöltéséhez használja az alábbi információkat:
Tulajdonság Érték Erőforráscsoport Hozzon létre egy csoportot, vagy válasszon ki egy meglévőt. Hely Válasszon egy Földrajzilag Önhöz közeli helyet. Alapfürt neve Ez az érték a Spark- és Kafka-fürtök alapneve. A hdistreaming beírása például létrehoz egy Spark-hdistreaming nevű Spark-fürtöt és egy kafka-hdistreaming nevű Kafka-fürtöt. Fürt bejelentkezési felhasználóneve A Spark- és Kafka-fürtök rendszergazdai felhasználóneve. Fürt bejelentkezési jelszava A Spark- és Kafka-fürtök rendszergazdai felhasználói jelszava. SSH-felhasználónév A Spark- és Kafka-fürtökhöz létrehozandó SSH-felhasználó. SSH-jelszó A Spark- és Kafka-fürtök SSH-felhasználójának jelszava. 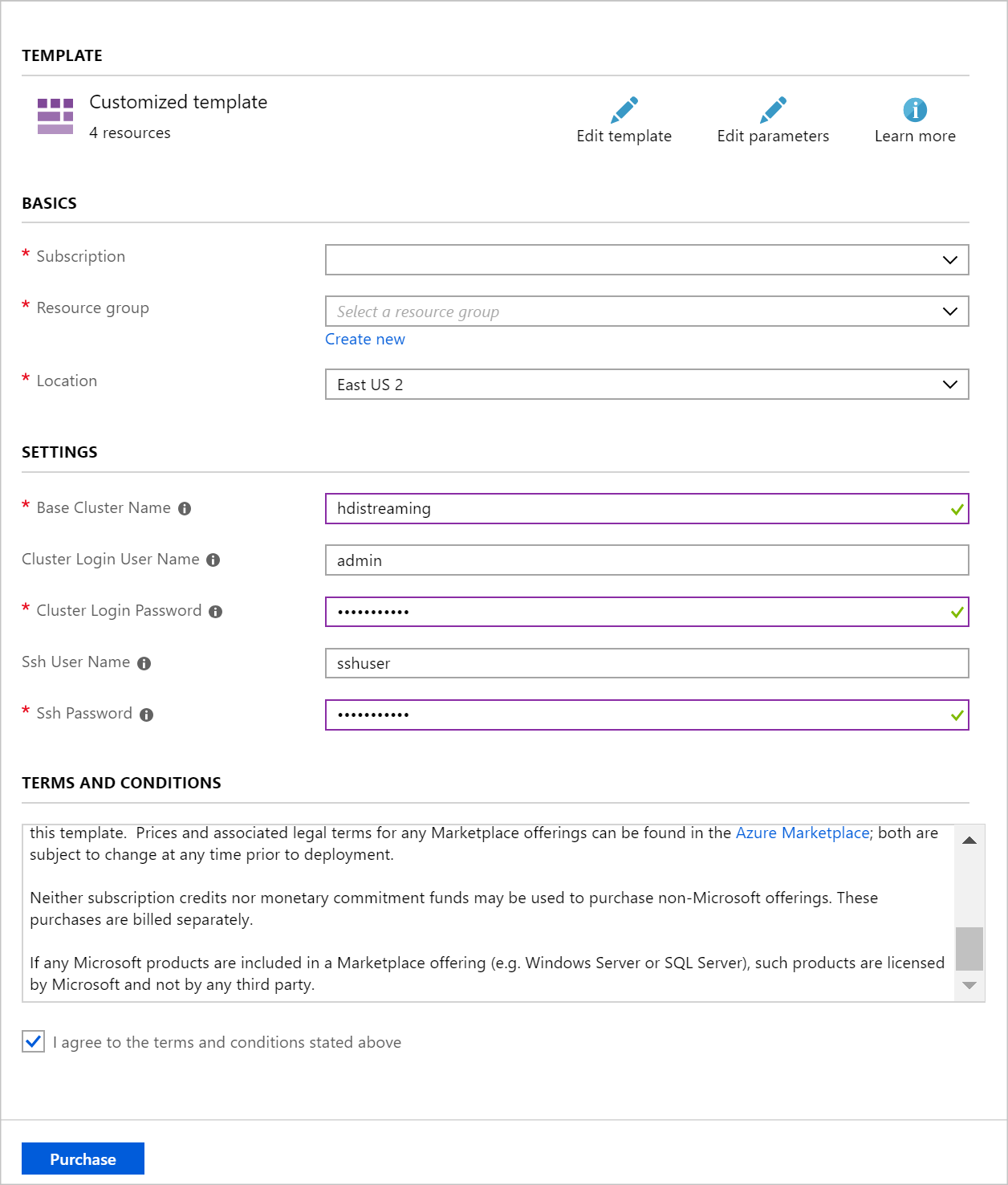
Olvassa át a használati feltételeket, majd válassza az Elfogadom a fenti feltételeket és kikötéseket lehetőséget.
Végül válassza a Vásárlás lehetőséget. A fürtök létrehozása körülbelül 20 percet vesz igénybe.
Az erőforrások létrehozása után megjelenik egy összefoglaló oldal.
Fontos
Figyelje meg, hogy a HDInsight-fürtök neve spark-BA Standard kiadás NAME és kafka-BA Standard kiadás NAME, ahol a BA Standard kiadás NAME a sablonnak megadott név. Ezeket a neveket a későbbi lépésekben használhatja a fürtökhöz való csatlakozáskor.
A jegyzetfüzetek használata
A dokumentumban leírt példa kódja a következő helyen található: https://github.com/Azure-Samples/hdinsight-spark-scala-kafka.
A fürt törlése
Figyelmeztetés
A HDInsight-fürtök számlázása percenként történik, akár használja őket, akár nem. A használat befejezése után mindenképpen törölje a fürtöt. Megtudhatja , hogyan törölhet HDInsight-fürtöt.
Mivel a dokumentum lépései mindkét fürtöt ugyanabban az Azure-erőforráscsoportban hozzák létre, törölheti az erőforráscsoportot az Azure Portalon. A csoport törlése eltávolítja a dokumentum, az Azure Virtual Network és a fürtök által használt tárfiók követésével létrehozott összes erőforrást.
Következő lépések
Ebben a példában megtanulta, hogyan használhatja a Sparkot a Kafkába való olvasásra és írásra. A Kafka használatának egyéb módjait az alábbi hivatkozások segítségével ismerheti meg: