Az Apache Hadoop YARN-alkalmazásnaplók elérése a Linux-alapú HDInsightban
Megtudhatja, hogyan érheti el az Apache Hadoop YARN (Még egy másik erőforrás-tárgyaló) alkalmazás naplóit egy Apache Hadoop-fürtön az Azure HDInsightban.
Mi az Apache YARN?
A YARN több programozási modellt is támogat (ezek közé az Apache Hadoop MapReduce-t) úgy, hogy leválasztja az erőforrás-kezelést az alkalmazásütemezésről/monitorozásról. A YARN globális ResourceManager (RM), feldolgozó-csomópontonkénti NodeManagers (NM) és alkalmazásonkénti ApplicationMasters (AM- ) gépeket használ. Az alkalmazásonkénti AM egyezteti az erőforrásokat (CPU, memória, lemez, hálózat) az alkalmazás RM-vel való futtatásához. Az RM az NM-ekkel együttműködve biztosítja ezeket az erőforrásokat, amelyek tárolóként vannak megadva. Az AM felelős az RM által hozzá rendelt tárolók előrehaladásának nyomon követéséért. Egy alkalmazás az alkalmazás jellegétől függően számos tárolót igényelhet.
Minden alkalmazás több alkalmazáskísérletből állhat. Ha egy alkalmazás meghibásodik, lehetséges, hogy újra próbálkozik egy új kísérletként. Minden kísérlet egy tárolóban fut. Bizonyos értelemben a tárolók a YARN-alkalmazások által végzett alapvető munkaegységek kontextusát biztosítják. A tároló kontextusában végzett összes munka azon az egyetlen feldolgozó csomóponton történik, amelyen a tárolót adták. További információért lásd : Hadoop: Yarn-alkalmazások írása vagy Apache Hadoop YARN .
A fürt nagyobb feldolgozási sebességre való skálázásához használhatja az automatikus skálázást , vagy manuálisan skálázhatja a fürtöket néhány különböző nyelv használatával.
YARN idővonal-kiszolgáló
Az Apache Hadoop YARN Timeline Server általános információkat nyújt a befejezett alkalmazásokról
A YARN Timeline Server a következő típusú adatokat tartalmazza:
- Az alkalmazás azonosítója, egy alkalmazás egyedi azonosítója
- Az alkalmazást elindító felhasználó
- Információk az alkalmazás befejezésére tett kísérletekről
- Az adott alkalmazáskísérletek által használt tárolók
YARN-alkalmazások és naplók
Az alkalmazásnaplók (és a kapcsolódó tárolónaplók) kritikus fontosságúak a problémás Hadoop-alkalmazások hibakeresésében. A YARN szép keretrendszert biztosít az alkalmazásnaplók gyűjtéséhez, összesítéséhez és tárolásához a Log Aggregation használatával.
A Naplóösszesítés funkció determinisztikusabbá teszi az alkalmazásnaplók elérését. Egy feldolgozó csomópont összes tárolójában összesíti a naplókat, és feldolgozó csomópontonként egy összesített naplófájlként tárolja őket. A rendszer az alapértelmezett fájlrendszerben tárolja a naplót az alkalmazások befejezése után. Az alkalmazás több száz vagy több ezer tárolót használhat, de az összes tároló naplói egyetlen feldolgozó csomóponton futnak, mindig egyetlen fájlba vannak összesítve. Ezért az alkalmazás csak egy naplót használ feldolgozó csomópontonként. A naplóösszesítés alapértelmezés szerint engedélyezve van a HDInsight-fürtök 3.0-s és újabb verzióiban. Az összesített naplók a fürt alapértelmezett tárolóján találhatók. A következő elérési út a naplók HDFS-elérési útja:
/app-logs/<user>/logs/<applicationId>
Az elérési úton annak a felhasználónak a neve szerepel, user aki elindította az alkalmazást. Ez applicationId a YARN RM által egy alkalmazáshoz hozzárendelt egyedi azonosító.
Az összesített naplók nem olvashatók közvetlenül, mivel tárolónként indexelt bináris formátumban vannak megírva TFile. A YARN-naplók ResourceManager vagy a CLI-eszközök használatával ezeket a naplókat egyszerű szövegként tekintheti meg az alkalmazások vagy tárolók számára.
Yarn-naplók ESP-fürtben
Az Ambariban két konfigurációt kell hozzáadni az egyénihez mapred-site .
Egy webböngészőben keresse meg
https://CLUSTERNAME.azurehdinsight.netCLUSTERNAMEa fürt nevét.Az Ambari felhasználói felületén lépjen a MapReduce2>Configs>Advanced>Custom mapred-site webhelyre.
Adja hozzá a következő tulajdonságok egyikét :
1. beállítás
mapred.acls.enabled=true mapreduce.job.acl-view-job=*2. beállítás
mapreduce.job.acl-view-job=<user1>,<user2>,<user3>Mentse a módosításokat, és indítsa újra az összes érintett szolgáltatást.
YARN CLI-eszközök
Az ssh paranccsal csatlakozzon a fürthöz. Szerkessze a következő parancsot úgy, hogy lecseréli a CLUSTERNAME nevet a fürt nevére, majd írja be a parancsot:
ssh sshuser@CLUSTERNAME-ssh.azurehdinsight.netA jelenleg futó Yarn-alkalmazások összes alkalmazásazonosítójának listázása a következő paranccsal:
yarn topJegyezze fel annak az oszlopnak az
APPLICATIONIDalkalmazásazonosítóját, amelynek naplóit le kell tölteni.YARN top - 18:00:07, up 19d, 0:14, 0 active users, queue(s): root NodeManager(s): 4 total, 4 active, 0 unhealthy, 0 decommissioned, 0 lost, 0 rebooted Queue(s) Applications: 2 running, 10 submitted, 0 pending, 8 completed, 0 killed, 0 failed Queue(s) Mem(GB): 97 available, 3 allocated, 0 pending, 0 reserved Queue(s) VCores: 58 available, 2 allocated, 0 pending, 0 reserved Queue(s) Containers: 2 allocated, 0 pending, 0 reserved APPLICATIONID USER TYPE QUEUE #CONT #RCONT VCORES RVCORES MEM RMEM VCORESECS MEMSECS %PROGR TIME NAME application_1490377567345_0007 hive spark thriftsvr 1 0 1 0 1G 0G 1628407 2442611 10.00 18:20:20 Thrift JDBC/ODBC Server application_1490377567345_0006 hive spark thriftsvr 1 0 1 0 1G 0G 1628430 2442645 10.00 18:20:20 Thrift JDBC/ODBC ServerEzeket a naplókat egyszerű szövegként tekintheti meg az alábbi parancsok egyikének futtatásával:
yarn logs -applicationId <applicationId> -appOwner <user-who-started-the-application> yarn logs -applicationId <applicationId> -appOwner <user-who-started-the-application> -containerId <containerId> -nodeAddress <worker-node-address>A parancsok futtatásakor adja meg az applicationId, a user-who-started-the-application>, <a containerId> és <a worker-node-address> adatokat.<<>
Egyéb mintaparancsok
Töltse le a Yarn-tárolók naplóit az összes alkalmazás-főkiszolgálóhoz az alábbi paranccsal. Ez a lépés szövegformátumban hozza létre a naplófájlt
amlogs.txt.yarn logs -applicationId <application_id> -am ALL > amlogs.txtTöltse le a Yarn tárolónaplóit csak a legújabb alkalmazás főkiszolgálója számára az alábbi paranccsal:
yarn logs -applicationId <application_id> -am -1 > latestamlogs.txtTöltse le a YARN tárolónaplóit az első két alkalmazásminta esetében a következő paranccsal:
yarn logs -applicationId <application_id> -am 1,2 > first2amlogs.txtTöltse le az összes Yarn-tárolónaplót a következő paranccsal:
yarn logs -applicationId <application_id> > logs.txtTöltse le a yarn tárolónaplót egy adott tárolóhoz a következő paranccsal:
yarn logs -applicationId <application_id> -containerId <container_id> > containerlogs.txt
YARN ResourceManager felhasználói felület
A YARN ResourceManager felhasználói felülete a fürt átjárócsomópontján fut. Az Ambari webes felhasználói felületén keresztül érhető el. A YARN-naplók megtekintéséhez kövesse az alábbi lépéseket:
A webböngészőben keresse meg a következőt
https://CLUSTERNAME.azurehdinsight.net: . Cserélje le a CLUSTERNAME kifejezést a HDInsight-fürt nevére.A bal oldali szolgáltatások listájában válassza a YARN lehetőséget.
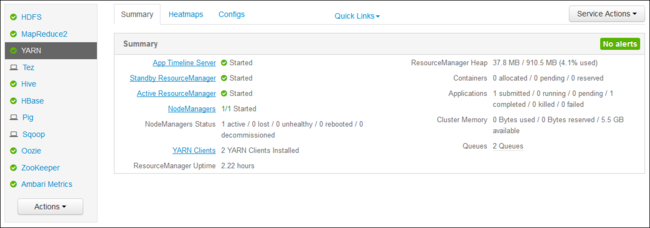
A Gyorshivatkozások legördülő listában válassza ki a fürt egyik fő csomópontját, majd válassza a lehetőséget
ResourceManager Log.
Megjelenik a YARN-naplókra mutató hivatkozások listája.