Az Apache Hive memóriahiány miatti hibáinak kijavítása az Azure HDInsightban
Megtudhatja, hogyan háríthat el egy Apache Hive memóriahiányos (OOM) hibát nagy táblák feldolgozásakor a Hive memóriabeállításainak konfigurálásával.
Apache Hive-lekérdezés futtatása nagy táblákon
Egy ügyfél Hive-lekérdezést futtatott:
SELECT
COUNT (T1.COLUMN1) as DisplayColumn1,
…
…
….
FROM
TABLE1 T1,
TABLE2 T2,
TABLE3 T3,
TABLE5 T4,
TABLE6 T5,
TABLE7 T6
where (T1.KEY1 = T2.KEY1….
…
…
A lekérdezés néhány árnyalata:
- A T1 egy nagy tábla, a TABLE1 aliasa, amely számos KARAKTERLÁNC oszloptípussal rendelkezik.
- Más táblák nem olyan nagyok, de sok oszlopuk van.
- Minden tábla csatlakozik egymáshoz, bizonyos esetekben több oszlopmal a TABLE1-ben és másokban.
A Hive-lekérdezés 26 percet vett igénybe egy 24 csomópontos A3 HDInsight-fürtön. Az ügyfél a következő figyelmeztető üzeneteket észlelte:
Warning: Map Join MAPJOIN[428][bigTable=?] in task 'Stage-21:MAPRED' is a cross product
Warning: Shuffle Join JOIN[8][tables = [t1933775, t1932766]] in Stage 'Stage-4:MAPRED' is a cross product
Az Apache Tez végrehajtási motor használatával. Ugyanez a lekérdezés 15 percig futott, majd a következő hibát eredményezte:
Status: Failed
Vertex failed, vertexName=Map 5, vertexId=vertex_1443634917922_0008_1_05, diagnostics=[Task failed, taskId=task_1443634917922_0008_1_05_000006, diagnostics=[TaskAttempt 0 failed, info=[Error: Failure while running task:java.lang.RuntimeException: java.lang.OutOfMemoryError: Java heap space
at
org.apache.hadoop.hive.ql.exec.tez.TezProcessor.initializeAndRunProcessor(TezProcessor.java:172)
at org.apache.hadoop.hive.ql.exec.tez.TezProcessor.run(TezProcessor.java:138)
at
org.apache.tez.runtime.LogicalIOProcessorRuntimeTask.run(LogicalIOProcessorRuntimeTask.java:324)
at
org.apache.tez.runtime.task.TezTaskRunner$TaskRunnerCallable$1.run(TezTaskRunner.java:176)
at
org.apache.tez.runtime.task.TezTaskRunner$TaskRunnerCallable$1.run(TezTaskRunner.java:168)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:415)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1628)
at
org.apache.tez.runtime.task.TezTaskRunner$TaskRunnerCallable.call(TezTaskRunner.java:168)
at
org.apache.tez.runtime.task.TezTaskRunner$TaskRunnerCallable.call(TezTaskRunner.java:163)
at java.util.concurrent.FutureTask.run(FutureTask.java:262)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1145)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:615)
at java.lang.Thread.run(Thread.java:745)
Caused by: java.lang.OutOfMemoryError: Java heap space
A hiba nagyobb virtuális gép (például D12) használatakor is megmarad.
Memóriakihasználtság hiba hibakeresése
Támogatási és mérnöki csapataink közösen megállapították, hogy a memóriakihasználtsági hibát okozó problémák egyike az Apache JIRA-ban ismertetett ismert probléma:
"Amikor a hive.auto.convert.join.noconditionaltask = true akkor ellenőrizzük a noconditionaltask.size értéket, és ha a térképillesztésben a táblák mérete kisebb, mint a noconditionaltask.size, a terv létrehoz egy Térkép illesztést, a probléma az, hogy a számítás nem veszi figyelembe a különböző hashTable-implementáció által bevezetett többletterhelést eredményként, ha a bemeneti méretek összege kisebb, mint a noconditionaltask mérete egy kis margós lekérdezések által, az OOM-t fogja érinteni."
A hive-site.xml fájlban lévő hive.auto.convert.join.noconditionaltask értéke igaz:
<property>
<name>hive.auto.convert.join.noconditionaltask</name>
<value>true</value>
<description>
Whether Hive enables the optimization about converting common join into mapjoin based on the input file size.
If this parameter is on, and the sum of size for n-1 of the tables/partitions for a n-way join is smaller than the
specified size, the join is directly converted to a mapjoin (there is no conditional task).
</description>
</property>
Valószínű, hogy a térképcsatlakozás okozta a Java-halomterület memóriahiba miatt. Amint azt a HDInsightban a Hadoop Yarn memóriabeállításai című blogbejegyzés ismerteti, a Tez végrehajtási motor használatakor a felhasznált halomtér valójában a Tez-tárolóhoz tartozik. Tekintse meg a Tez tárolómemóriát leíró alábbi ábrát.
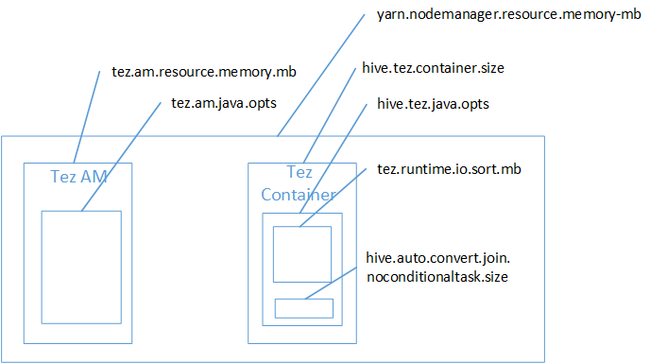
Ahogy a blogbejegyzés is sugallja, a következő két memóriabeállítás határozza meg a halom tárolómemóriáit: hive.tez.container.size és hive.tez.java.opts. Tapasztalatunk szerint a memóriakivétel nem jelenti azt, hogy a tároló mérete túl kicsi. Ez azt jelenti, hogy a Java-halom mérete (hive.tez.java.opts) túl kicsi. Így amikor nem látja a memóriát, megpróbálhatja növelni hive.tez.java.opts. Szükség esetén előfordulhat, hogy növelnie kell a hive.tez.container.size értéket. A java.opts beállításnak a container.size körülbelül 80%-ának kell lennie.
Feljegyzés
A hive.tez.java.opts beállításnak mindig kisebbnek kell lennie, mint a hive.tez.container.size.
Mivel egy D12-gép 28 GB memóriával rendelkezik, úgy döntöttünk, hogy 10 GB-os tárolóméretet (10240 MB) használunk, és 80%-ot rendelünk a java.opts szolgáltatáshoz:
SET hive.tez.container.size=10240
SET hive.tez.java.opts=-Xmx8192m
Az új beállításokkal a lekérdezés 10 perc alatt sikeresen lefutott.
Következő lépések
Az OOM-hiba nem feltétlenül jelenti azt, hogy a tároló mérete túl kicsi. Ehelyett úgy kell konfigurálnia a memóriabeállításokat, hogy a halomméret növekedjen, és a tároló memóriaméretének legalább 80%-a legyen. A Hive-lekérdezések optimalizálásáról az Apache Hadoop apache Hive-lekérdezéseinek optimalizálása a HDInsightban című témakörben olvashat.
Visszajelzés
Hamarosan elérhető: 2024-ben fokozatosan kivezetjük a GitHub-problémákat a tartalom visszajelzési mechanizmusaként, és lecseréljük egy új visszajelzési rendszerre. További információ: https://aka.ms/ContentUserFeedback.
Visszajelzés küldése és megtekintése a következőhöz: