Az Apache Spark és az Apache Hive integrálása a Hive Warehouse-összekötővel az Azure HDInsightban
Az Apache Hive Warehouse Connector (HWC) egy olyan kódtár, amely lehetővé teszi az Apache Spark és az Apache Hive egyszerűbb kezelését. Támogatja az olyan feladatokat, mint az adatok áthelyezése a Spark DataFrames és a Hive-táblák között. Emellett úgy is, hogy a Spark streamelési adatait Hive-táblákba irányítja. A Hive Warehouse Connector úgy működik, mint egy híd a Spark és a Hive között. Emellett a Scala, a Java és a Python programozási nyelvként is használható a fejlesztéshez.
A Hive Warehouse Connector lehetővé teszi, hogy kihasználja a Hive és a Spark egyedi funkcióit a nagy teljesítményű big data-alkalmazások létrehozásához.
Az Apache Hive támogatja az atomi, konzisztens, izolált és tartós (ACID) adatbázis-tranzakciókat. További információ az ACID-ról és a Hive-tranzakciókról: Hive Transactions. A Hive részletes biztonsági vezérlőket is kínál az Apache Ranger és a kis késésű elemzési feldolgozás (LLAP) használatával, amelyek nem érhetők el az Apache Sparkban.
Az Apache Spark egy strukturált streamelési API-val rendelkezik, amely az Apache Hive-ben nem elérhető streamelési képességeket biztosít. A HDInsight 4.0-tól kezdve az Apache Spark 2.3.1> és az Apache Hive 3.1.0 különálló metaadattár-katalógusokkal rendelkezik, ami megnehezíti az együttműködést.
A Hive Warehouse Connector (HWC) megkönnyíti a Spark és a Hive együttes használatát. A HWC-kódtár az LLAP-démonok adatait párhuzamosan tölti be a Spark-végrehajtókba. Ez a folyamat hatékonyabbá és adaptálhatóbbá teszi, mint egy standard JDBC-kapcsolat a Spark és a Hive között. Ez két különböző végrehajtási módot hoz létre a HWC-hez:
- Hive JDBC mód a HiveServer2-n keresztül
- Hive LLAP mód LLAP-démonokkal [Ajánlott]
Alapértelmezés szerint a HWC hive LLAP démonok használatára van konfigurálva. A Hive-lekérdezések (olvasási és írási) a fenti módok és a hozzájuk tartozó API-k használatával történő végrehajtásához lásd a HWC API-kat.

A Hive Warehouse-összekötő által támogatott műveletek némelyike a következő:
- Táblázat leírása
- Táblázat létrehozása ORC formátumú adatokhoz
- Hive-adatok kiválasztása és DataFrame beolvasása
- DataFrame írása a Hive-be kötegben
- Hive-frissítési utasítás végrehajtása
- Táblázatadatok olvasása a Hive-ből, átalakítás a Sparkban, és írása egy új Hive-táblába
- DataFrame- vagy Spark-stream írása a Hive-be a HiveStreaming használatával
A Hive Warehouse-összekötő beállítása
Fontos
- A Spark 2.4 Vállalati biztonságicsomag-fürtökre telepített HiveServer2 interaktív példány nem támogatott a Hive Warehouse-összekötővel való használathoz. Ehelyett egy külön HiveServer2 interaktív fürtöt kell konfigurálnia a HiveServer2 Interaktív számítási feladatok üzemeltetéséhez. A Hive Warehouse Connector egyetlen Spark 2.4-fürtöt használó konfigurációja nem támogatott.
- A Hive Warehouse Connector (HWC) kódtár nem támogatott olyan interaktív lekérdezésfürtökhöz, amelyekben engedélyezve van a Számítási feladatok kezelése (WLM) funkció.
Ha csak Spark-számítási feladatokkal rendelkezik, és HWC-kódtárat szeretne használni, győződjön meg arról, hogy az Interaktív lekérdezésfürt nem rendelkezik engedélyezve a Számítási feladatok kezelése funkcióval (hive.server2.tez.interactive.queuea konfiguráció nincs beállítva a Hive-konfigurációkban).
Olyan forgatókönyv esetén, amelyben a Spark számítási feladatok (HWC) és az LLAP natív számítási feladatai is léteznek, két külön interaktív lekérdezésfürtöt kell létrehoznia megosztott metaadattár-adatbázissal. Egy fürt natív LLAP-számítási feladatokhoz, ahol a WLM-funkció szükség szerint engedélyezhető, a HWC más fürtje pedig csak olyan számítási feladathoz, ahol a WLM-funkciót nem kell konfigurálni. Fontos megjegyezni, hogy a WLM-erőforráscsomagokat mindkét fürtből megtekintheti, még akkor is, ha csak egy fürtben van engedélyezve. Ne módosítsa az erőforrásterveket abban a fürtben, ahol a WLM szolgáltatás le van tiltva, mert az hatással lehet más fürtök WLM-funkcióira. - Bár a Spark támogatja az R számítástechnikai nyelvet az adatelemzés egyszerűsítése érdekében, a Hive Warehouse Connector (HWC) kódtár használata nem támogatott az R-vel. A HWC számítási feladatok végrehajtásához lekérdezéseket hajthat végre a Sparkból a Hive-be a JDBC-stílusú HiveWarehouseSession API-val, amely csak a Scalát, a Java-t és a Pythont támogatja.
- A lekérdezések (olvasási és írási) végrehajtása a HiveServer2-n keresztül JDBC-módban nem támogatott olyan összetett adattípusok esetében, mint a Tömbök/Struct/Map típusok.
- A HWC csak ORC-fájlformátumokban támogatja az írást. A nem ORC írások (pl. parquet és szöveges fájlformátumok) nem támogatottak a HWC-n keresztül.
A Hive Warehouse-összekötőnek külön fürtökre van szüksége a Spark- és interaktív lekérdezési számítási feladatokhoz. Ezeket a fürtöket az Azure HDInsightban az alábbi lépésekkel állíthatja be.
Támogatott fürttípusok > verziók
| HWC-verzió | Spark verzió | InteractiveQuery-verzió |
|---|---|---|
| v1 | Spark 2.4 | HDI 4.0 | Interaktív lekérdezés 3.1 | HDI 4.0 |
| v2 | Spark 3.1 | HDI 5.0 | Interaktív lekérdezés 3.1 | HDI 5.0 |
Fürtök létrehozása
Hozzon létre egy HDInsight Spark 4.0-fürtöt egy tárfiókkal és egy egyéni Azure-beli virtuális hálózattal. A fürt Azure-beli virtuális hálózatban való létrehozásáról további információt a HDInsight hozzáadása meglévő virtuális hálózathoz című témakörben talál.
Hozzon létre egy HDInsight Interactive Query (LLAP) 4.0-fürtöt ugyanazzal a tárfiókkal és Azure-beli virtuális hálózattal, mint a Spark-fürt.
HWC-beállítások konfigurálása
Előzetes információk összegyűjtése
Egy webböngészőből lépjen arra a
https://LLAPCLUSTERNAME.azurehdinsight.net/#/main/services/HIVEhelyre, ahol az LLAPCLUSTERNAME az interaktív lekérdezési fürt neve.Lépjen az Összefoglaló>HiveServer2 interaktív JDBC URL-címre , és jegyezze fel az értéket. Az érték a következőhöz hasonló lehet:
jdbc:hive2://<zookeepername1>.rekufuk2y2ce.bx.internal.cloudapp.net:2181,<zookeepername2>.rekufuk2y2ce.bx.internal.cloudapp.net:2181,<zookeepername3>.rekufuk2y2ce.bx.internal.cloudapp.net:2181/;serviceDiscoveryMode=zooKeeper;zooKeeperNamespace=hiveserver2-interactive.Lépjen a Configs>Advanced>hive-site hive.zookeeper.quorum lapra>, és jegyezze fel az értéket. Az érték a következőhöz hasonló lehet:
<zookeepername1>.rekufuk2y2cezcbowjkbwfnyvd.bx.internal.cloudapp.net:2181,<zookeepername2>.rekufuk2y2cezcbowjkbwfnyvd.bx.internal.cloudapp.net:2181,<zookeepername3>.rekufuk2y2cezcbowjkbwfnyvd.bx.internal.cloudapp.net:2181.Lépjen a Configs>Advanced>General>hive.metastore.uris webhelyre, és jegyezze fel az értéket. Az érték a következőhöz hasonló lehet:
thrift://iqgiro.rekufuk2y2cezcbowjkbwfnyvd.bx.internal.cloudapp.net:9083,thrift://hn*.rekufuk2y2cezcbowjkbwfnyvd.bx.internal.cloudapp.net:9083.Lépjen a Configs>Advanced>hive-interactive-site>hive.llap.daemon.service.hosts webhelyre, és jegyezze fel az értéket. Az érték a következőhöz hasonló lehet:
@llap0.
A Spark-fürt beállításainak konfigurálása
Egy webböngészőből lépjen arra
https://CLUSTERNAME.azurehdinsight.net/#/main/services/SPARK2/configsa helyre, ahol a CLUSTERNAME az Apache Spark-fürt neve.Bontsa ki az egyéni spark2 alapértelmezett értékeket.

Válassza a Tulajdonság hozzáadása... lehetőséget a következő konfigurációk hozzáadásához:
Konfiguráció Érték spark.datasource.hive.warehouse.load.staging.dirHa ADLS Gen2-tárfiókot használ, használja a abfss://STORAGE_CONTAINER_NAME@STORAGE_ACCOUNT_NAME.dfs.core.windows.net/tmp
Ha Azure Blob Storage-fiókot használ, használja a .wasbs://STORAGE_CONTAINER_NAME@STORAGE_ACCOUNT_NAME.blob.core.windows.net/tmp
Állítsa be egy megfelelő HDFS-kompatibilis átmeneti könyvtárra. Ha két különböző fürtje van, az átmeneti könyvtárnak az LLAP-fürt tárfiókjának átmeneti könyvtárában kell lennie, hogy a HiveServer2 hozzáférhessen hozzá. Cserélje leSTORAGE_ACCOUNT_NAMEa fürt által használt tárfiók nevére ésSTORAGE_CONTAINER_NAMEa tároló nevére.spark.sql.hive.hiveserver2.jdbc.urlA HiveServer2 Interactive JDBC URL-címéből korábban beszerzett érték spark.datasource.hive.warehouse.metastoreUriA hive.metastore.uris fájlból korábban beszerzett érték. spark.security.credentials.hiveserver2.enabledtruea YARN-fürt módhoz ésfalsea YARN ügyfélmódhoz.spark.hadoop.hive.zookeeper.quorumA hive.zookeeper.quorumból korábban beszerzett érték. spark.hadoop.hive.llap.daemon.service.hostsA hive.llap.daemon.service.hosts webhelyről korábban beszerzett érték. Mentse a módosításokat, és indítsa újra az összes érintett összetevőt.
HWC vállalati biztonsági csomag (ESP) fürtökhöz való konfigurálása
Az Enterprise Security Package (ESP) olyan nagyvállalati szintű képességeket biztosít, mint az Active Directory-alapú hitelesítés, a többfelhasználós támogatás és a szerepköralapú hozzáférés-vezérlés az Azure HDInsightban található Apache Hadoop-fürtökhöz. Az ESP-vel kapcsolatos további információkért lásd: Vállalati biztonsági csomag használata a HDInsightban.
Az előző szakaszban említett konfigurációkon kívül adja hozzá a következő konfigurációt a HWC esp-fürtökön való használatához.
A Spark-fürt Ambari webes felhasználói felületén lépjen a Spark2>CONFIGS>Egyéni spark2 alapértelmezett beállításaihoz.
Frissítse a következő tulajdonságot.
Konfiguráció Érték spark.sql.hive.hiveserver2.jdbc.url.principalhive/<llap-headnode>@<AAD-Domain>Egy webböngészőből lépjen arra a
https://CLUSTERNAME.azurehdinsight.net/#/main/services/HIVE/summaryhelyre, ahol a CLUSTERNAME az interaktív lekérdezési fürt neve. Kattintson a HiveServer2 Interactive elemre. Megjelenik annak a fő csomópontnak a teljes tartományneve (FQDN), amelyen az LLAP fut a képernyőképen látható módon. Cserélje le<llap-headnode>erre az értékre.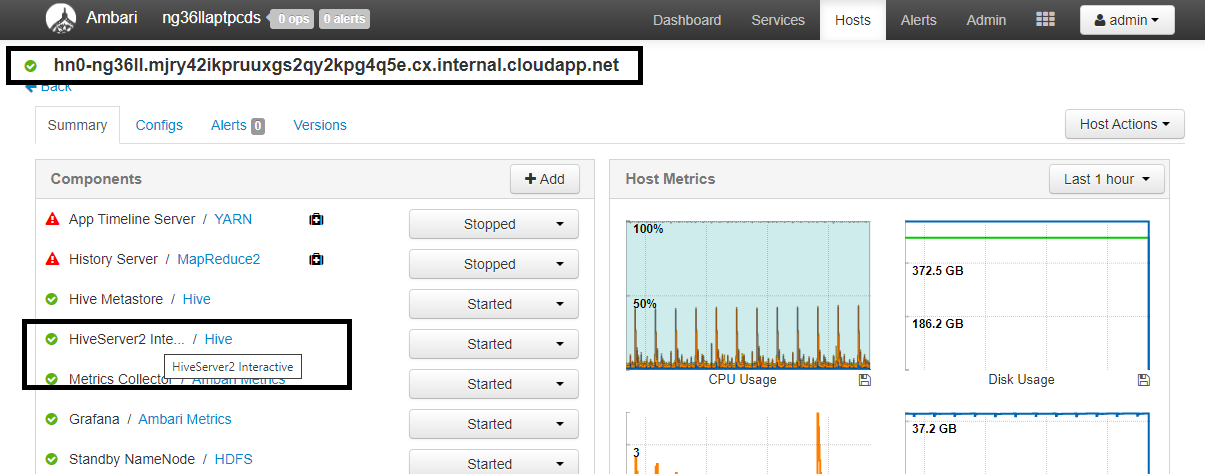
Az ssh paranccsal csatlakozzon az interaktív lekérdezési fürthöz. Keresse meg
default_realma paramétert a/etc/krb5.conffájlban. Cserélje le<AAD-DOMAIN>ezt az értéket nagybetűs sztringként, ellenkező esetben a hitelesítő adatok nem találhatók.
Például:
hive/hn*.mjry42ikpruuxgs2qy2kpg4q5e.cx.internal.cloudapp.net@PKRSRVUQVMAE6J85.D2.INTERNAL.CLOUDAPP.NET.
Mentse a módosításokat, és szükség szerint indítsa újra az összetevőket.
Hive Warehouse-összekötő használata
Az interaktív lekérdezési fürthöz való csatlakozáshoz és a lekérdezések a Hive Warehouse Connector használatával történő végrehajtásához választhat néhány különböző módszer közül. A támogatott módszerek a következő eszközöket tartalmazzák:
Az alábbiakban néhány példa látható a HWC-hez a Sparkból való csatlakozáshoz.
Spark-shell
Így interaktívan futtathatja a Sparkot a Scala-rendszerhéj módosított verzióján keresztül.
Az ssh paranccsal csatlakozzon az Apache Spark-fürthöz. Szerkessze az alábbi parancsot úgy, hogy lecseréli a CLUSTERNAME nevet a fürt nevére, majd írja be a parancsot:
ssh sshuser@CLUSTERNAME-ssh.azurehdinsight.netAz ssh-munkamenetben hajtsa végre a következő parancsot a
hive-warehouse-connector-assemblyverzió megjegyzéséhez:ls /usr/hdp/current/hive_warehouse_connectorSzerkessze az alábbi kódot a
hive-warehouse-connector-assemblyfent azonosított verzióval. Ezután hajtsa végre a parancsot a Spark-rendszerhéj elindításához:spark-shell --master yarn \ --jars /usr/hdp/current/hive_warehouse_connector/hive-warehouse-connector-assembly-<VERSION>.jar \ --conf spark.security.credentials.hiveserver2.enabled=falseA Spark-rendszerhéj elindítása után a Hive Warehouse Connector-példány a következő parancsokkal indítható el:
import com.hortonworks.hwc.HiveWarehouseSession val hive = HiveWarehouseSession.session(spark).build()
Spark-küldés
A Spark-submit segédprogram bármilyen Spark-programot (vagy feladatot) elküldhet a Spark-fürtökre.
A Spark-submit feladat az utasításoknak megfelelően beállítja és konfigurálja a Spark és a Hive Warehouse-összekötőt, végrehajtja a neki átadott programot, majd tisztán felszabadítja a használt erőforrásokat.
Miután a scala/java kódot és a függőségeket egy szerelvény jar-ba építette, az alábbi paranccsal elindíthat egy Spark-alkalmazást. Cserélje le és <APP_JAR_PATH> írja be <VERSION>a tényleges értékeket.
YARN-ügyfél mód
spark-submit \ --class myHwcApp \ --master yarn \ --deploy-mode client \ --jars /usr/hdp/current/hive_warehouse_connector/hive-warehouse-connector-assembly-<VERSION>.jar \ --conf spark.security.credentials.hiveserver2.enabled=false /<APP_JAR_PATH>/myHwcAppProject.jarYARN-fürt mód
spark-submit \ --class myHwcApp \ --master yarn \ --deploy-mode cluster \ --jars /usr/hdp/current/hive_warehouse_connector/hive-warehouse-connector-assembly-<VERSION>.jar \ --conf spark.security.credentials.hiveserver2.enabled=true /<APP_JAR_PATH>/myHwcAppProject.jar
Ez a segédprogram akkor is használható, ha a pySparkban megírtuk a teljes alkalmazást, és fájlba .py (Pythonba) csomagoltuk, hogy a teljes kódot elküldhessük a Spark-fürtnek végrehajtás céljából.
Python-alkalmazások esetén adjon át egy .py fájlt a helyén /<APP_JAR_PATH>/myHwcAppProject.jar, és adja hozzá az alábbi konfigurációs (Python .zip) fájlt a keresési útvonalhoz --py-files.
--py-files /usr/hdp/current/hive_warehouse_connector/pyspark_hwc-<VERSION>.zip
Lekérdezések futtatása Vállalati biztonsági csomag (ESP) fürtökön
A spark-shell vagy a spark-submit indítása előtt használja kinit . Cserélje le a FELHASZNÁLÓNÉV elemet egy tartományi fiók nevére a fürt elérésére vonatkozó engedélyekkel, majd hajtsa végre a következő parancsot:
kinit USERNAME
Adatok védelme Spark ESP-fürtökön
Hozzon létre egy táblázatot
demonéhány mintaadattal a következő parancsok megadásával:create table demo (name string); INSERT INTO demo VALUES ('HDinsight'); INSERT INTO demo VALUES ('Microsoft'); INSERT INTO demo VALUES ('InteractiveQuery');A táblázat tartalmát az alábbi paranccsal tekintheti meg. A szabályzat alkalmazása előtt a táblázat a
demoteljes oszlopot jeleníti meg.hive.executeQuery("SELECT * FROM demo").show()
Alkalmazzon olyan oszlopmaszkolási szabályzatot, amely csak az oszlop utolsó négy karakterét jeleníti meg.
Lépjen a Ranger felügyeleti felhasználói felületére a következő címen
https://LLAPCLUSTERNAME.azurehdinsight.net/ranger/: .Kattintson a fürt Hive szolgáltatására a Hive alatt.
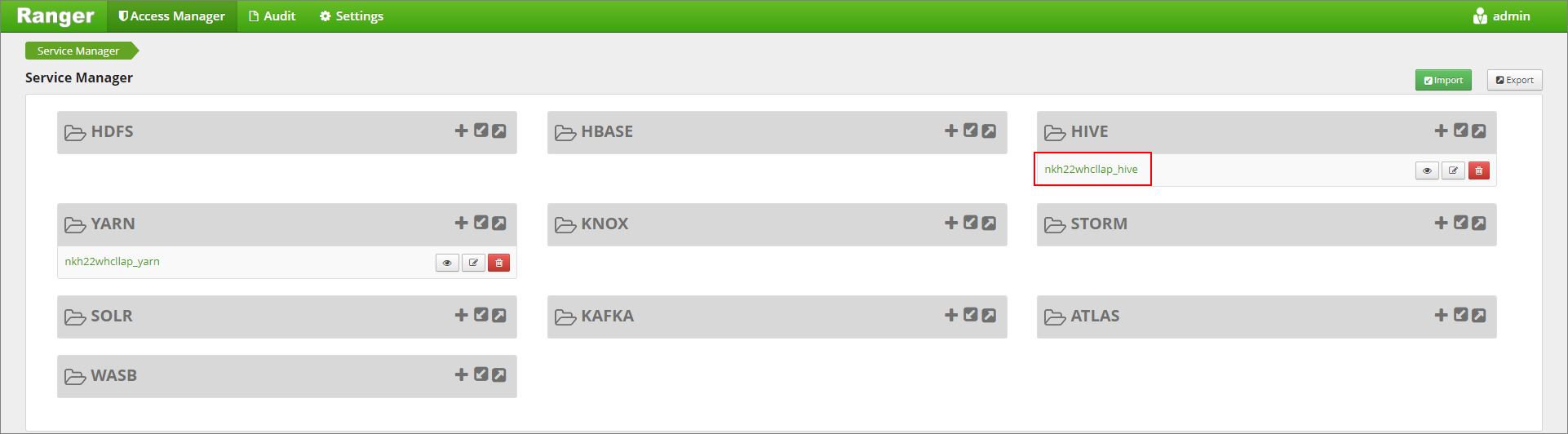
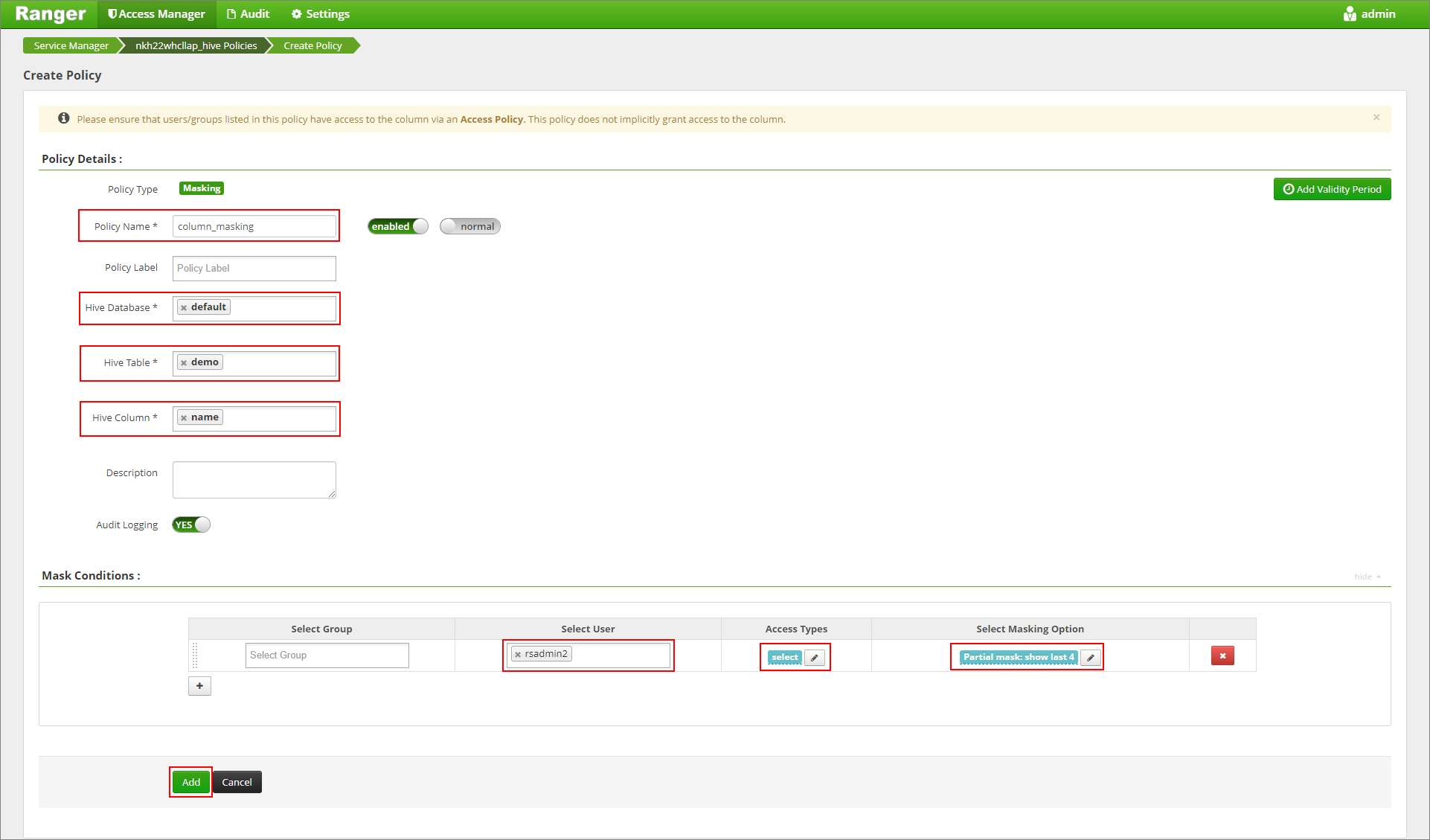
Kattintson a Maszkolás lapra, majd az Új szabályzat hozzáadása parancsra

Adjon meg egy kívánt házirendnevet. Adatbázis kiválasztása: Alapértelmezett, Hive tábla: demo, Hive oszlop: név, Felhasználó: rsadmin2, Hozzáférési típusok: kiválasztás és Részleges maszk: az utolsó 4 megjelenítése a Maszkolás kiválasztása menüből . Kattintson a Hozzáadás gombra.
Tekintse meg újra a tábla tartalmát. A ranger-szabályzat alkalmazása után csak az oszlop utolsó négy karakterét láthatjuk.
