Az első adatelemzési kísérlet létrehozása a Machine Learning Studióban (klasszikus)
ÉRVÉNYES:  Machine Learning Studio (klasszikus)
Machine Learning Studio (klasszikus)  Azure Machine Learning
Azure Machine Learning
Fontos
A (klasszikus) Machine Learning Studio támogatása 2024. augusztus 31-én megszűnik. Javasoljuk, hogy addig térjen át az Azure Machine Learning használatára.
2021. december 1-től kezdve nem fog tudni létrehozni új (klasszikus) Machine Learning Studio-erőforrásokat. 2024. augusztus 31-ig továbbra is használhatja a meglévő (klasszikus) Machine Learning Studio-erőforrásokat.
- A gépi tanulási projektek ML Studióból (klasszikus) Azure Machine Learningbe való áthelyezéséről szóló információk.
- További információ az Azure Machine Learningről
A (klasszikus) ML Studio dokumentációjának kivezetése folyamatban van, és a jövőben nem várható a frissítése.
Ebben a cikkben egy gépi tanulási kísérletet hoz létre a Machine Learning Studióban (klasszikus), amely előrejelzi az autó árát különböző változók, például a make és a műszaki specifikációk alapján.
Ha teljesen új a gépi tanulásban, a kezdőknek készült Adattudomány videósorozat nagyszerű bevezetés a gépi tanulásba a mindennapi nyelv és fogalmak használatával.
Ez a rövid útmutató egy kísérlet alapértelmezett munkafolyamatát követi:
- Modell létrehozása
- A modell betanítása
- A modell pontozása és tesztelése
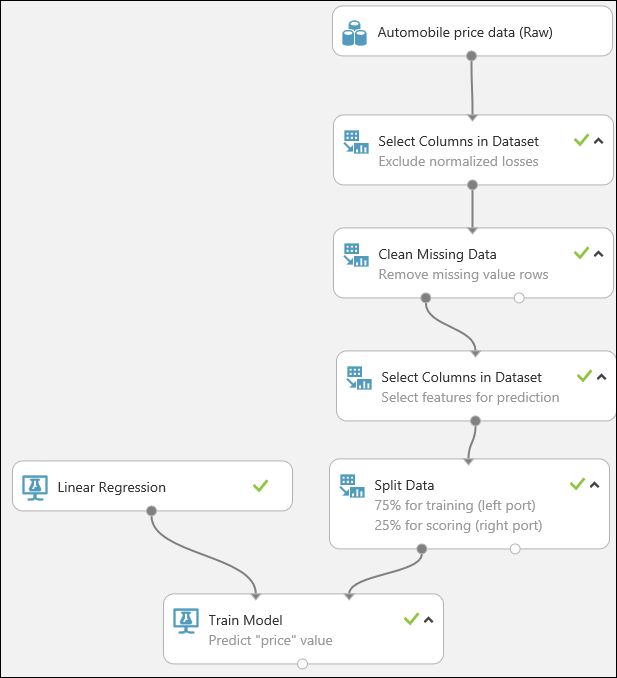
Az adatok lekérése
A gépi tanulásban elsőként az adatokra van szüksége. A Studio (klasszikus) számos mintaadatkészletet tartalmaz, amelyeket használhat, vagy számos forrásból importálhat adatokat. Ebben a példában a munkaterületén megtalálható Automobile price data (Raw) (Nyers autóáradatok) nevű mintahalmazt fogjuk használni. Ebben az adathalmazban számos különböző autót bemutató bejegyzés szerepel. A bejegyzések számos adatot (például márka, típus, műszaki specifikációk, ár) tartalmaznak.
Tipp.
Az Azure AI katalógusban megtalálja az alábbi kísérlet egy működő példányát. Nyissa meg első adatelemzési kísérletét – Autóárak előrejelzése , majd kattintson a Megnyitás a Studióban elemre a kísérlet másolatának letöltéséhez a Machine Learning Studio (klasszikus) munkaterületére.
A következőképpen vonhatja be az adathalmazt a kísérletbe.
Hozzon létre egy új kísérletet a Machine Learning Studio (klasszikus) ablakának alján található +ÚJ gombra kattintva. Válassza a KÍSÉRLET>üres kísérlet lehetőséget.
A kísérlet kap egy alapértelmezett nevet, amelyet a vászon tetején láthat. Jelölje ki ezt a szöveget, és módosítsa valami értelmesebbre, például arra, hogy Autó árának előrejelzése. A névnek nem kell egyedinek lennie.
A kísérletvászontól balra az adathalmazokat és modulokat tartalmazó paletta látható. A paletta tetején található keresőmezőbe gépelje be, hogy automobile. A rendszer megjeleníti az Automobile price data (Raw) (Nyers autóáradatok) nevű adathalmazt. Húzza rá az adathalmazt a kísérletvászonra.
Az adatok megjelenésének megtekintéséhez kattintson az autóadatkészlet alján található kimeneti portra, majd válassza a Vizualizáció lehetőséget.
Tipp.
Az adathalmazok és modulok kis körökkel jelölt bemeneti és kimeneti portokkal rendelkeznek – a bemeneti portok felül, a kimeneti portok alul találhatók. Az adatfolyam létrehozásához a kísérlet során össze fogja kötni az egyik modul kimeneti portját egy másik modul bemeneti portjával. Ha meg szeretné tekinteni, hogyan jelennek meg az adatok az adatfolyam egy adott pontján, kattintson az adathalmaz vagy modul kimeneti portjára.
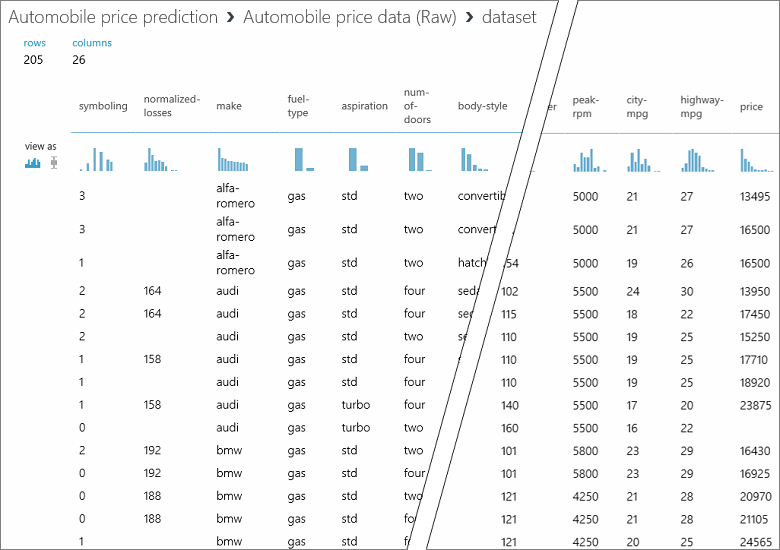
Ebben az adatkészletben minden sor egy autót jelöl, az egyes autókhoz társított változók pedig oszlopokként jelennek meg. A jobb szélső oszlopban (26. oszlop, "ár") előrejelezzük az árat egy adott autó változóinak használatával.
A jobb felső sarokban látható „x” gombra kattintva zárja be a képi megjelenítési ablakot.
Az adatok előkészítése
Az adathalmazok elemzése előtt általában némi előfeldolgozás szükséges. Talán észrevette, hogy az oszlopok számos sorából hiányoztak az értékek. Ahhoz, hogy a modell elemezni tudja az adatokat, el kell távolítani a hiányzó értékeket. Eltávolítjuk a hiányzó értékeket tartalmazó sorokat. A normalized-losses (normalizált veszteségek) című oszlopból ráadásul rendkívül sok érték hiányzik, ezért ezt az oszlopot teljesen kizárjuk a modellből.
Tipp.
A legtöbb modul használatának előfeltétele a bemeneti adatok hiányzó értékeinek törlése.
Először hozzáadunk egy modult, amely teljesen eltávolítja a normalizált veszteségek oszlopot . Ezután hozzáadunk egy másik modult, amely eltávolítja a hiányzó adatokat tartalmazó sorokat.
A modulkatalógus tetején található keresőmezőbe írja be az Oszlopok kijelölése az adathalmazban modult. Ezután húzza a kísérletvászonra. Ezzel a modullal kiválaszthatjuk, hogy melyik adatoszlopokat szeretnénk bevonni a modellbe, vagy éppen kizárni a modellből.
Csatlakoztassa az Automobile price data (Raw) adatkészlet kimeneti portját az Adathalmaz oszlopainak kiválasztása bemeneti portjához.
Kattintson a Select Columns in Dataset (Adathalmaz oszlopainak kijelölése) modulra, majd a Properties (Tulajdonságok) panelen kattintson a Launch column selector (Oszlopválasztó elindítása) elemre.
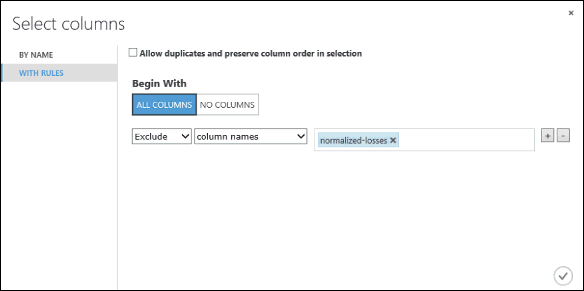
A bal oldalon kattintson a With rules (Szabályokkal) lehetőségre
A Begin With (Kezdés a következővel) területen kattintson az All columns (Minden oszlop) lehetőségre. Ezek a szabályok közvetlenül az Adathalmaz oszlopainak kijelölése parancsot adják át az összes oszlopon (kivéve azokat az oszlopokat, amelyeket ki fogunk zárni).
A legördülő listákból válassza az Exclude (Kizárás) és a column names (oszlopnevek) lehetőséget, majd kattintson a szövegmezőbe. Megjelenik az oszlopnevek listája. Válassza a normalized-losses (normalizált veszteségek) lehetőséget, amely aztán bekerül a szövegdobozba.
Kattintson az OK gombra az oszlopválasztó bezárásához (a jobb alsó sarokban).
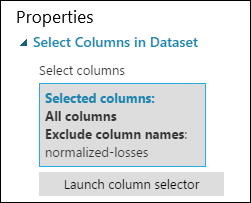
Ekkor a Select Columns in Dataset (Adathalmaz oszlopainak kijelölése) modul Properties (Tulajdonságok) panelje jelzi, hogy a modul a normalized-losses ( normalizált veszteségek) kivételével az adathalmaz összes oszlopát fel fogja dolgozni.
Tipp.
A modulokhoz megjegyzéseket adhat. Ehhez kattintson duplán a kívánt modulra, majd gépelje be a megjegyzés szövegét. Így egyetlen pillantással felmérheti, hogy mire szolgál az adott modul a kísérletben. A jelen esetben kattintson duplán a Select Columns in Dataset (Adathalmaz oszlopainak kijelölése) modulra, és írja be az „Exclude normalized losses” (A normalized-losses oszlop kizárása) szöveget.
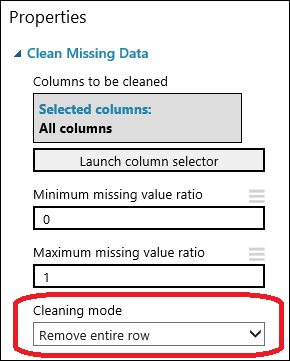
Húzza a Clean Missing Data (Hiányzó adatok törlése) modult a kísérletvászonra, és kösse össze a Select Columns in Dataset (Adathalmaz oszlopainak kijelölése) modullal. A Properties (Tulajdonságok) panel Cleaning mode (Törlés módja) beállításánál válassza a Remove entire row (Teljes sor eltávolítása) lehetőséget. Ezek a beállítások a hiányzó adatok törlésére utasítják a hiányzó értékeket tartalmazó sorok eltávolításával. Kattintson duplán a modulra, és írja be a következő megjegyzést: „Hiányzó értéket tartalmazó sorok törlése”.
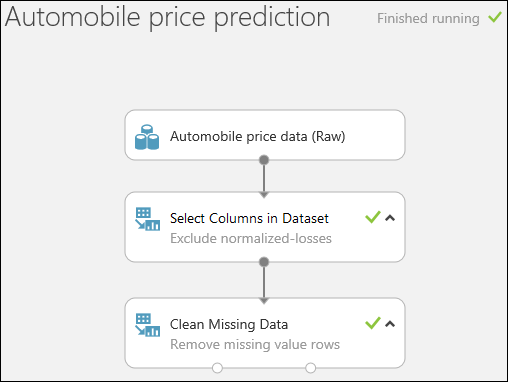
A kísérlet futtatásához kattintson a lap alján található RUN (Futtatás) parancsra.
A kísérlet befejezését követően az összes modulnál megjelenik egy zöld pipa, amely jelzi, hogy az adott modul sikeresen lefutott. A jobb felső sarokban pedig megjelenik a Finished running (Futtatás befejeződött) állapot.
Tipp.
Miért futtattuk a kísérletet most? A kísérlet futtatásával biztosítható, hogy az adatokhoz tartozó oszlopdefiníciók az adatkészletből áthaladnak a Select Columns in Dataset (Adathalmaz oszlopainak kijelölése) modulon és a Clean Missing Data (Hiányzó adatok törlése) modulon. Ez azt jelenti, hogy a Clean Missing Data (Hiányzó adatok törlése) modulhoz kapcsolt modulok is megkapják ugyanezeket az adatokat.
Most már tiszta adatokkal rendelkezünk. Ha szeretné megtekinteni a megtisztított adathalmazt, kattintson a Clean Missing Data (Hiányzó adatok törlése) modul bal oldali kimeneti portjára, és válassza a Visualize (Képi megjelenítés) lehetőséget. Láthatja, hogy a normalized-losses oszlop eltűnt, ahogy a hiányzó értékek is.
Most, hogy megtisztítottuk az adatokat, megadhatjuk, hogy mely jellemzőket szeretnénk felhasználni a prediktív modellben.
Szolgáltatások definiálása
A gépi tanulásban a funkciók az önt érdeklő elemek egyéni mérhető tulajdonságai. Adathalmazunk minden sora egy-egy autót képvisel, az oszlopok pedig az autók különböző jellemzőit tartalmazzák.
A prediktív modellben használandó jellemzők helyes megválasztásához fontos a kísérletezés, illetve a megoldani kívánt probléma jó ismerete. Bizonyos jellemzők ugyanis hasznosabbak a cél előrejelzéséhez, mint mások. Egyes funkciók erős korrelációval rendelkeznek más funkciókkal, és eltávolíthatók. A példánkban például szorosan összefügg a city-mpg (fogyasztás városban) és highway-mpg (fogyasztás autópályán), ezért az egyiket eltávolíthatjuk anélkül, hogy lényegesen befolyásolnánk az előrejelzést.
Ideje, hogy létrehozzuk a modellt az adathalmaz jellemzőinek meghatározott részhalmaza alapján. Később visszatérhet ehhez a lépéshez, és más jellemzőket kiválasztva ismét lefuttathatja a kísérletet, ha kíváncsi rá, hogy úgy jobb eredményeket kap-e. Kezdésként azonban a következő funkciókat próbáljuk ki:
make, body-style, wheel-base, engine-size, horsepower, peak-rpm, highway-mpg, price
Húzzon egy újabb Select Columns in Dataset (Adathalmaz oszlopainak kijelölése) modult a kísérletvászonra. Kösse össze a Clean Missing Data (Hiányzó adatok törlése) modul bal oldali kimeneti portját a Select Columns in Dataset (Adathalmaz oszlopainak kijelölése) modul bemenetével.
Kattintson duplán a modulra, és írja be: „Az előrejelzéshez használatos jellemzők kiválasztása”.
Kattintson a Properties (Tulajdonságok) panel Launch column selector (Oszlopválasztó indítása) elemére.
Kattintson a With rules (Szabályokkal) lehetőségre.
A Begin With (Kezdés a következővel) területen kattintson a No columns (Egyetlen oszlop sem) lehetőségre. A szűrősorban válassza ki az Include (Belefoglalás) és a column names (oszlopnevek) lehetőséget, és jelölje ki az oszlopnevek listáját a szövegmezőben. Ez a szűrő arra utasítja a modult, hogy ne haladjon át egyetlen oszlopon (funkción) a megadottakon kívül.
Kattintson a pipa (OK) gombra.
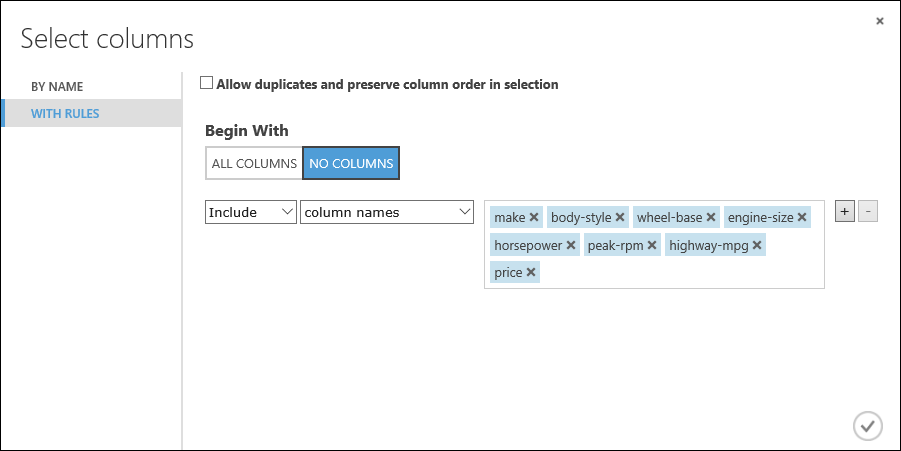
Ez a modul egy szűrt adatkészletet hoz létre, amely csak azokat a funkciókat tartalmazza, amelyeket át szeretnénk adni a következő lépésben használni kívánt tanulási algoritmusnak. Később visszatérhet ide, és más jellemzőkkel is elvégezheti az előrejelzést.
Algoritmus kiválasztása és alkalmazása
Most, hogy előkészítettük az adatokat, a prediktív modell létrehozásához már csak a tanítás és a tesztelés szükséges. A következőkben az adatok segítségével elvégezzük a modell betanítását, majd a modell tesztelésével megállapítjuk, hogy milyen pontossággal képes előre jelezni az árakat.
A besorolás és a regresszió két algoritmus, amelynek segítségével felügyelt gépi tanítás valósítható meg. Besoroláskor a válaszok előrejelzése megadott kategóriakészletből történik (például: színek (vörös, kék vagy zöld)). A rendszer a számok előrejelzésére regressziós módszert használ.
Mivel az árat szeretnénk előre jelezni, ami egy szám, regressziós algoritmust fogunk használni. Ebben a példában lineáris regressziós modellt használunk.
A modell betanításához az árat tartalmazó adathalmazt biztosítunk számára. A modell megvizsgálja adatokat, és összefüggéseket keres az autó tulajdonságai és az ára között. Ezután teszteljük a modellt. Ehhez olyan autók tulajdonságkészletét töltjük be, amelyeket ismerünk, és megnézzük, hogy mennyire sikeresen tudja a modell előre jelezni az ismert árakat.
Az adatok a modell betanítására és tesztelésére is használhatók. Ehhez két halmazra, egy tanítási és egy tesztelési halmazra osztjuk fel az adatokat.
Jelölje ki, majd húzza a kísérletvászonra a Split Data (Adatok felosztása) modult, majd kösse össze a legutóbb használt Select Columns in Dataset (Adathalmaz oszlopainak kijelölése) modullal.
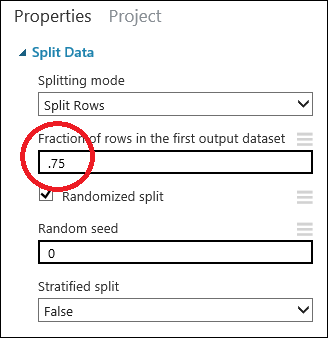
Kattintással jelölje ki a Split Data (Adatok felosztása) modult. Keresse meg a Properties (Tulajdonságok) panelen a vászontól jobbra a Fraction of rows in the first output dataset (Sorok hányadosa az első kimeneti adathalmazban) beállítást, és adja meg a 0,75 értéket. Így az adatok 75 százalékát a modell betanítására, 25 százalékát pedig a modell tesztelésére használhatjuk.
Tipp.
A Random seed (Véletlenszám-generálás kezdőértéke) paraméter módosításával különböző véletlenszerűen kiválasztott mintákat hozhat létre, amelyeket szintén felhasználhat a modell betanítására és tesztelésére. Ez a paraméter szabályozza a pszeudo-véletlenszám-generátor kezdőértékét.
Futtassa a kísérletet. A kísérlet futtatásakor a Select Columns in Dataset (Adathalmaz oszlopainak kijelölése) és a Split Data (Adatok felosztása) modul átadja a következőkben hozzáadott moduloknak az oszlopdefiníciókat.
A tanulási algoritmus kiválasztásához bontsa ki a vászontól balra, a modulpalettán található Machine Learning (Gépi tanulás) kategóriát, majd bontsa ki az Initialize Model (Inicializálási modell) kategóriát is. Itt számos modulkategória közül választhat, amelyek segítségével inicializálható a gépi tanulási algoritmus. Ehhez a kísérlethez válassza a Regression (Regresszió) kategóriában található Linear Regression (Lineáris regresszió) modult, majd húzza a kísérletvászonra. (A modult úgy is megkeresheti, ha a paletta keresőmezőjébe beírja a „linear regression” kifejezést.)
Keresse meg, majd húzza a kísérletvászonra a Train Model (Modell betanítása) modult. Kösse össze a Linear Regression (Lineáris regresszió) modul kimenetét a Train Model (Modell betanítása) modul bal oldali bemenetével, és kösse össze a Split Data (Adatok felosztása) modul adatbetanítási kimenetét (bal oldali port) a Train Model (Modell betanítása) modul jobb oldali bemenetével.
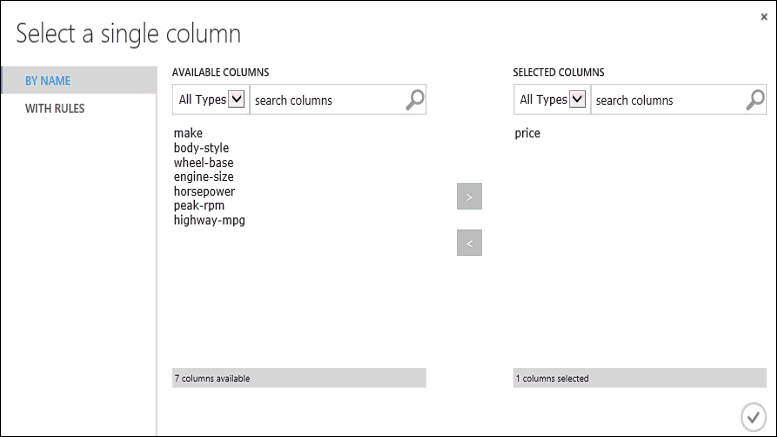
Kattintson a Train Model (Modell betanítása) modulra, kattintson a Properties (Tulajdonságok) panel Launch column selector (Oszlopválasztó indítása) elemére, és válassza ki a price (ár) oszlopot. Az ár az az érték, amelyet a modellünk előre jelez.
Jelölje ki a price (ár) oszlopot az oszlopválasztóban. Ehhez helyezze át az Available columns (Elérhető oszlopok) listáról a Selected columns (Kiválasztott oszlopok) listára.
Futtassa a kísérletet.
Ezzel kapunk egy betanított regressziós modellt, amely képes pontszámot rendelni az új autóadatokhoz, és így előre jelezni az árakat.
Új autóárak előrejelzése
Most, hogy adataink 75 százalékával betanítottuk a modellt, a maradék 25 százalék pontozásával megállapíthatjuk, hogy mennyire működik jól.
Keresse meg, majd húzza a kísérletvászonra a Score Model (Modell pontozása) modult. Kösse össze a Train Model (Modell betanítása) modul kimenetét a Score Model (Modell pontozása) modul bal oldali bemeneti portjával. Kösse össze a Split Data (Adatok felosztása) modul tesztelési adatokat tartalmazó kimenetét (jobb oldali portját) a Score Model (Modell pontozása) modul jobb oldali bemeneti portjával.
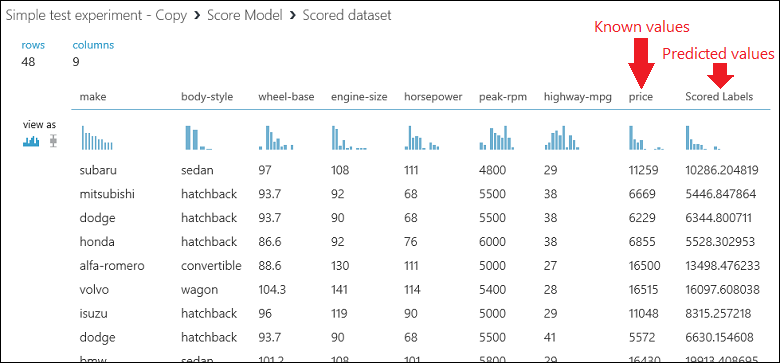
Futtassa a kísérletet, és tekintse meg a Score Model modul kimenetét a Score Model kimeneti portjára kattintva, és válassza a Vizualizáció lehetőséget. A modul megjeleníti az előre jelzett árat, valamint a tesztadatokból ismert tényleges értéket.
Végül teszteljük az eredmény minőségét. Jelölje ki, majd húzza a kísérletvászonra az Evaluate Model (Modell kiértékelése) modult, és kösse össze a Score Model (Modell pontozása) modul kimenetét az Evaluate Model (Modell kiértékelése) bal oldali bemeneti portjával. Az elkészült kísérletnek a következőképpen kell kinéznie:
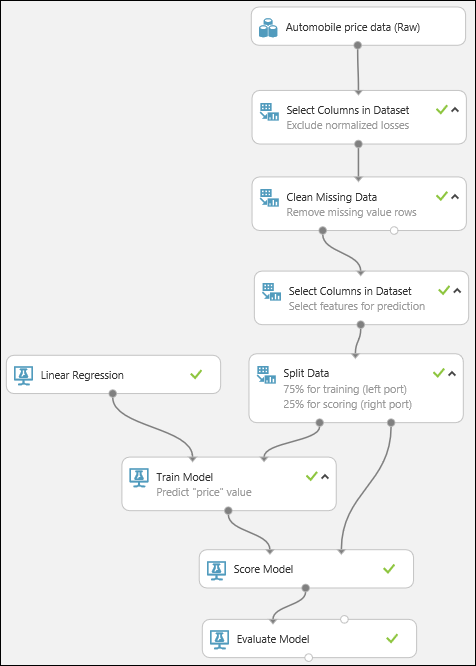
Futtassa a kísérletet.
Az Evaluate Model (Modell kiértékelése) modul eredményének megtekintéséhez kattintson a kimeneti portra, majd válassza a Visualize (Képi megjelenítés) lehetőséget.
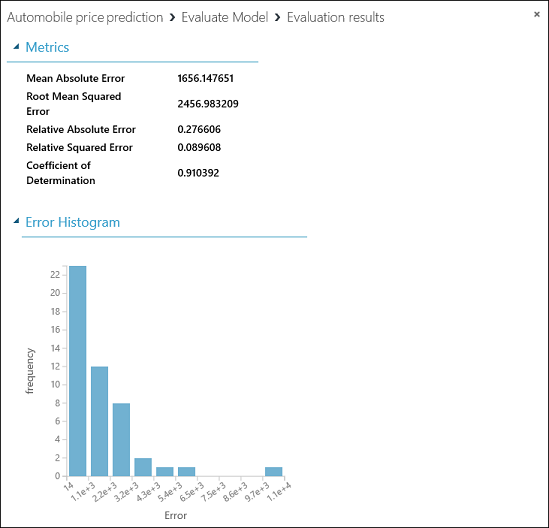
A következő statisztikák tekinthetők meg:
- Mean Absolute Error (átlagos abszolút eltérés, MAE): az abszolút eltérések átlaga (eltérésnek az előre jelzett érték és a tényleges érték közötti különbséget nevezzük).
- Root Mean Squared Error (gyökátlagos négyzetes eltérés, RMSE): a tesztelési adathalmazon végzett előrejelzések eltéréseinek négyzetéből számított átlag négyzetgyöke.
- Relative Absolute Error (relatív abszolút eltérés): a tényleges értékek és az összes tényleges értékek átlaga közötti különbségek abszolút eltérésének átlaga.
- Relative Squared Error (relatív négyzetes eltérés): a négyzetes eltérések átlaga a tényleges értékek és az összes tényleges érték átlaga közötti különbség négyzetes értékéhez viszonyítva.
- Coefficient of Determination (determinációs együttható): ez az R-négyzet értéke néven is ismert statisztikai mérőszám azt mutatja, hogy a modell mennyire illik az adatokhoz.
Az összes hibastatisztikára igaz, hogy minél kisebb az érték, annál jobb a modell. A kisebb értékek azt jelzik, hogy az előrejelzés közelebb van a tényleges értékekhez. A Coefficient of Determination (determinációs együttható) értéke minél közelebb van az egyhez (1,0-hoz), annál pontosabb az előrejelzés.
Az erőforrások eltávolítása
Ha már nincs szüksége a cikk használatával létrehozott erőforrásokra, törölje őket, hogy elkerülje a díjak felmerülését. Ebből a cikkből megtudhatja, hogyan exportálhatja és törölheti a terméken belüli felhasználói adatokat.
Következő lépések
Ebben a rövid útmutatóban egy egyszerű kísérletet hozott létre egy mintaadatkészlet használatával. A modell létrehozásának és üzembe helyezésének folyamatának részletesebb megismeréséhez folytassa a prediktív megoldásokkal kapcsolatos oktatóanyagban.