R-szkript összetevő végrehajtása
Ez a cikk azt ismerteti, hogyan futtathat R-kódot az Azure Machine Learning-tervező folyamatában az R-szkript végrehajtása összetevővel.
Az R-vel olyan feladatokat végezhet, amelyeket a meglévő összetevők nem támogatnak, például:
- Egyéni adatátalakítások létrehozása
- Saját metrikák használata az előrejelzések kiértékeléséhez
- Modellek létrehozása a tervezőben nem önálló összetevőként implementált algoritmusok használatával
R-verzió támogatása
Az Azure Machine Learning designer az R CRAN (átfogó R Archive Network) terjesztését használja. A jelenleg használt verzió a CRAN 3.5.1.
Támogatott R-csomagok
Az R-környezet több mint 100 csomaggal van előtelepítve. A teljes listát az Előre telepített R-csomagok című szakaszban találja.
A telepített csomagok megtekintéséhez az alábbi kódot bármely R-szkript végrehajtása összetevőhöz hozzáadhatja.
azureml_main <- function(dataframe1, dataframe2){
print("R script run.")
dataframe1 <- data.frame(installed.packages())
return(list(dataset1=dataframe1, dataset2=dataframe2))
}
Megjegyzés
Ha a folyamat több olyan R-szkript-összetevőt tartalmaz, amelyeknek olyan csomagokra van szükségük, amelyek nem szerepelnek az előre telepített listában, telepítse a csomagokat az egyes összetevőkben.
R-csomagok telepítése
További R-csomagok telepítéséhez használja a metódust install.packages() . A csomagok minden R-szkript-összetevőhöz telepítve vannak. A rendszer nem osztja meg őket más R-szkript-összetevők között.
Megjegyzés
Nem ajánlott R-csomagot telepíteni a szkriptcsomagból. Javasoljuk, hogy a csomagokat közvetlenül a szkriptszerkesztőben telepítse.
Adja meg a CRAN-adattárat a csomagok telepítésekor, például install.packages("zoo",repos = "https://cloud.r-project.org"): .
Figyelmeztetés
Az Excute R Script összetevő nem támogatja a natív fordítást igénylő csomagok telepítését, például qdap a JAVA-t drc és a C++-t igénylő csomagokat. Ennek az az oka, hogy ezt az összetevőt egy előre telepített, nem rendszergazdai engedéllyel rendelkező környezetben hajtja végre a rendszer.
Ne telepítsen előre beépített/windowsos csomagokat, mivel a tervező összetevői az Ubuntu-on futnak. Ha ellenőrizni szeretné, hogy egy csomag előre készült-e a Windowsra, nyissa meg a CRAN-t , keressen rá a csomagra, töltsön le egy bináris fájlt az operációs rendszernek megfelelően, és jelölje be a Build: part (Beépített: rész) elemet a DESCRIPTION fájlban. Az alábbiakban egy példa látható: 
Ez a minta a Zoo telepítését mutatja be:
# R version: 3.5.1
# The script MUST contain a function named azureml_main,
# which is the entry point for this component.
# Note that functions dependent on the X11 library,
# such as "View," are not supported because the X11 library
# is not preinstalled.
# The entry point function MUST have two input arguments.
# If the input port is not connected, the corresponding
# dataframe argument will be null.
# Param<dataframe1>: a R DataFrame
# Param<dataframe2>: a R DataFrame
azureml_main <- function(dataframe1, dataframe2){
print("R script run.")
if(!require(zoo)) install.packages("zoo",repos = "https://cloud.r-project.org")
library(zoo)
# Return datasets as a Named List
return(list(dataset1=dataframe1, dataset2=dataframe2))
}
Megjegyzés
A csomag telepítése előtt ellenőrizze, hogy létezik-e már, hogy ne ismételje meg a telepítést. Az ismétlődő telepítések miatt a webszolgáltatás kérései időtúllépést okozhatnak.
Hozzáférés a regisztrált adatkészlethez
A munkaterület regisztrált adathalmazaihoz való hozzáféréshez tekintse meg az alábbi mintakódot:
azureml_main <- function(dataframe1, dataframe2){
print("R script run.")
run = get_current_run()
ws = run$experiment$workspace
dataset = azureml$core$dataset$Dataset$get_by_name(ws, "YOUR DATASET NAME")
dataframe2 <- dataset$to_pandas_dataframe()
# Return datasets as a Named List
return(list(dataset1=dataframe1, dataset2=dataframe2))
}
R-szkript végrehajtásának konfigurálása
Az R-szkript végrehajtása összetevő kiindulási pontként mintakódot tartalmaz.
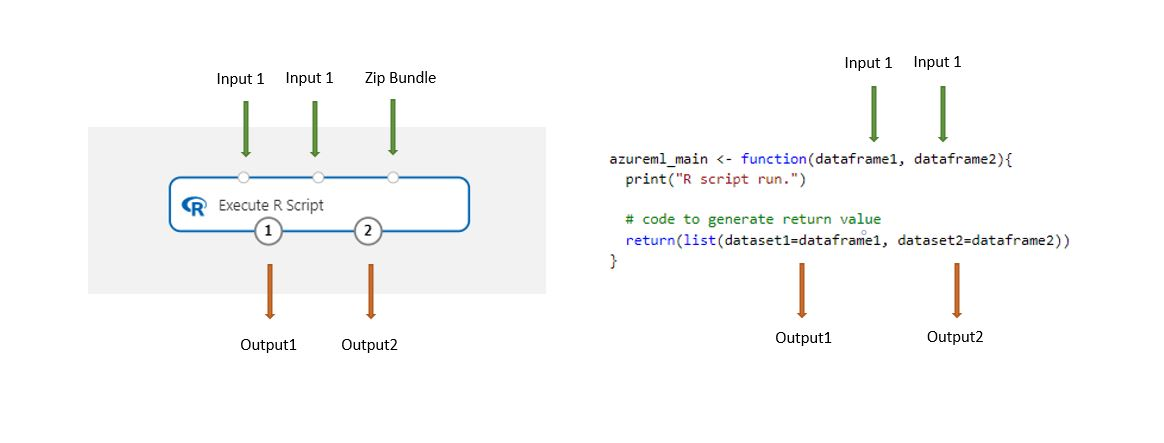
A tervezőben tárolt adathalmazok automatikusan R-adatkeretté alakulnak, amikor ezzel az összetevővel töltik be.
Adja hozzá az R-szkript végrehajtása összetevőt a folyamathoz.
Csatlakoztassa azokat a bemeneteket, amelyekre a szkriptnek szüksége van. A bemenetek nem kötelezőek, és tartalmazhatnak adatokat és további R-kódot.
Dataset1: Hivatkozzon az első bemenetre a következőként
dataframe1: . A bemeneti adatkészletet CSV-, TSV- vagy ARFF-fájlként kell formázni. Vagy csatlakoztathat egy Azure Machine Learning-adatkészletet.Dataset2: A második bemenetre a következőként hivatkozzon
dataframe2: . Ezt az adatkészletet CSV-, TSV- vagy ARFF-fájlként vagy Azure Machine Learning-adatkészletként is meg kell formázni.Szkriptcsomag: A harmadik bemenet .zip fájlokat fogad el. A tömörített fájlok több fájlt és több fájltípust tartalmazhatnak.
Az R-szkript szövegmezőbe írja be vagy illessze be az érvényes R-szkriptet.
Megjegyzés
Legyen óvatos a szkript írásakor. Győződjön meg arról, hogy nincsenek szintaxishibák, például be nem jelentett változók vagy nem importált összetevők vagy függvények használata. A cikk végén különös figyelmet kell fordítani az előre telepített csomaglistára. Ha olyan csomagokat szeretne használni, amelyek nem szerepelnek a listában, telepítse őket a szkriptbe. Például:
install.packages("zoo",repos = "https://cloud.r-project.org").Az első lépésekhez az R-szkript szövegmezője előre fel van töltve mintakóddal, amelyet szerkesztheti vagy lecserélhet.
# R version: 3.5.1 # The script MUST contain a function named azureml_main, # which is the entry point for this component. # Note that functions dependent on the X11 library, # such as "View," are not supported because the X11 library # is not preinstalled. # The entry point function MUST have two input arguments. # If the input port is not connected, the corresponding # dataframe argument will be null. # Param<dataframe1>: a R DataFrame # Param<dataframe2>: a R DataFrame azureml_main <- function(dataframe1, dataframe2){ print("R script run.") # If a .zip file is connected to the third input port, it's # unzipped under "./Script Bundle". This directory is added # to sys.path. # Return datasets as a Named List return(list(dataset1=dataframe1, dataset2=dataframe2)) }A belépési pont függvénynek tartalmaznia kell a és a bemeneti argumentumokat
Param<dataframe1>Param<dataframe2>, még akkor is, ha ezeket az argumentumokat nem használják a függvényben.Megjegyzés
Az R-szkript végrehajtása összetevőnek átadott adatokra a és azként hivatkozik
dataframe1dataframe2, amely különbözik az Azure Machine Learning-tervezőtől (a tervező hivatkozása a következő:dataset1,dataset2). Győződjön meg arról, hogy a bemeneti adatokra helyesen hivatkozik a szkript.Megjegyzés
Előfordulhat, hogy a meglévő R-kódnak kisebb módosításokra van szüksége a tervezőfolyamatban való futtatáshoz. A CSV formátumban megadott bemeneti adatokat például explicit módon adatkészletté kell konvertálni, mielőtt a kódban használná. Az R nyelvben használt adat- és oszloptípusok is különböznek a tervezőben használt adatoktól és oszloptípusoktól.
Ha a szkript nagyobb, mint 16 KB, használja a Szkriptcsomag portot az olyan hibák elkerüléséhez, mint a CommandLine, amely túllépi a 16597 karakteres korlátot.
- Csomagolja be a szkriptet és más egyéni erőforrásokat egy zip-fájlba.
- Töltse fel a zip-fájlt Fájladatkészletként a studióba.
- Húzza az adathalmaz-összetevőt a tervező szerzői lapjának bal oldali összetevőpaneljének Adathalmazok listájából.
- Csatlakoztassa az adathalmaz-összetevőt az Execute R Script összetevő Script Bundle portjához.
A szkriptcsomagban lévő szkriptet a következő mintakód használja:
azureml_main <- function(dataframe1, dataframe2){ # Source the custom R script: my_script.R source("./Script Bundle/my_script.R") # Use the function that defined in my_script.R dataframe1 <- my_func(dataframe1) sample <- readLines("./Script Bundle/my_sample.txt") return (list(dataset1=dataframe1, dataset2=data.frame("Sample"=sample))) }Véletlenszerű mag esetén adjon meg egy értéket, amelyet az R-környezetben használjon véletlenszerű magértékként. Ez a paraméter egyenértékű az R-kódban való hívással
set.seed(value).Küldje el a folyamatot.
Results (Eredmények)
Az R-szkript összetevői több kimenetet is visszaadhatnak, de R-adatkeretként kell megadni őket. A tervező automatikusan adatkeretekké alakítja az adatkereteket, hogy kompatibilis legyen más összetevőkkel.
Az R-ből származó szabványos üzenetek és hibák visszakerülnek az összetevő naplójába.
Ha az R-szkriptben kell kinyomtatnia az eredményeket, a nyomtatott eredményeket 70_driver_log az összetevő jobb oldali paneljén, az Outputs+logs (Kimenetek+naplók ) lapon találja.
Mintaparancsfájlok
A folyamat sokféleképpen bővíthető egyéni R-szkriptek használatával. Ez a szakasz mintakódot biztosít a gyakori feladatokhoz.
R-szkript hozzáadása bemenetként
Az R-szkript végrehajtása összetevő bemenetként támogatja az tetszőleges R-szkriptfájlokat. A használatukhoz fel kell töltenie őket a munkaterületre a .zip fájl részeként.
Ha R-kódot tartalmazó .zip fájlt szeretne feltölteni a munkaterületre, lépjen az Adathalmazok eszközoldalra. Válassza az Adathalmaz létrehozása lehetőséget, majd válassza a Helyi fájlból és a Fájl adathalmaz típusa lehetőséget.
Ellenőrizze, hogy a tömörített fájl megjelenik-e a My Datasets (Saját adathalmazok ) kategóriában a bal oldali összetevőfa Adathalmazok kategóriájában.
Csatlakoztassa az adatkészletet a Script Bundle bemeneti porthoz.
A .zip fájl összes fájlja elérhető a folyamatfuttatás ideje alatt.
Ha a szkriptcsomagfájl könyvtárstruktúrát tartalmaz, a struktúra megmarad. A kódot azonban módosítania kell, hogy a ./Script Bundle könyvtárat előre az elérési útra terjessze.
Adatok feldolgozása
Az alábbi minta bemutatja, hogyan méretezheti és normalizálhatja a bemeneti adatokat:
# R version: 3.5.1
# The script MUST contain a function named azureml_main,
# which is the entry point for this component.
# Note that functions dependent on the X11 library,
# such as "View," are not supported because the X11 library
# is not preinstalled.
# The entry point function MUST have two input arguments.
# If the input port is not connected, the corresponding
# dataframe argument will be null.
# Param<dataframe1>: a R DataFrame
# Param<dataframe2>: a R DataFrame
azureml_main <- function(dataframe1, dataframe2){
print("R script run.")
# If a .zip file is connected to the third input port, it's
# unzipped under "./Script Bundle". This directory is added
# to sys.path.
series <- dataframe1$width
# Find the maximum and minimum values of the width column in dataframe1
max_v <- max(series)
min_v <- min(series)
# Calculate the scale and bias
scale <- max_v - min_v
bias <- min_v / dis
# Apply min-max normalizing
dataframe1$width <- dataframe1$width / scale - bias
dataframe2$width <- dataframe2$width / scale - bias
# Return datasets as a Named List
return(list(dataset1=dataframe1, dataset2=dataframe2))
}
.zip fájl beolvasása bemenetként
Ez a minta bemutatja, hogyan használhat adatkészletet egy .zip fájlban az R-szkript végrehajtása összetevő bemeneteként.
- Hozza létre az adatfájlt CSV formátumban, és nevezze elmydatafile.csv.
- Hozzon létre egy .zip fájlt, és adja hozzá a CSV-fájlt az archívumhoz.
- Töltse fel a tömörített fájlt az Azure Machine Learning-munkaterületre.
- Csatlakoztassa az eredményül kapott adatkészletet az R-szkript végrehajtása összetevő ScriptBundle bemenetéhez.
- Az alábbi kód használatával olvassa be a CSV-adatokat a tömörített fájlból.
azureml_main <- function(dataframe1, dataframe2){
print("R script run.")
mydataset<-read.csv("./Script Bundle/mydatafile.csv",encoding="UTF-8");
# Return datasets as a Named List
return(list(dataset1=mydataset, dataset2=dataframe2))
}
Sorok replikálása
Ez a minta bemutatja, hogyan replikálhat pozitív rekordokat egy adatkészletben a minta kiegyensúlyozásához:
azureml_main <- function(dataframe1, dataframe2){
data.set <- dataframe1[dataframe1[,1]==-1,]
# positions of the positive samples
pos <- dataframe1[dataframe1[,1]==1,]
# replicate the positive samples to balance the sample
for (i in 1:20) data.set <- rbind(data.set,pos)
row.names(data.set) <- NULL
# Return datasets as a Named List
return(list(dataset1=data.set, dataset2=dataframe2))
}
R-objektumok átadása R-szkriptösszetevők között
A belső szerializálási mechanizmussal R-objektumokat adhat át az R-szkript végrehajtása összetevő példányai között. Ez a példa feltételezi, hogy a nevű A R-objektumot két R-szkript végrehajtása összetevő között szeretné áthelyezni.
Adja hozzá az első Execute R Script összetevőt a folyamathoz. Ezután írja be a következő kódot az R-szkript szövegmezőbe, hogy szerializált objektumot
Ahozzon létre oszlopként az összetevő kimeneti adattáblájában:azureml_main <- function(dataframe1, dataframe2){ print("R script run.") # some codes generated A serialized <- as.integer(serialize(A,NULL)) data.set <- data.frame(serialized,stringsAsFactors=FALSE) return(list(dataset1=data.set, dataset2=dataframe2)) }Az egész szám típusra való explicit átalakítás azért történik, mert a szerializációs függvény R
Rawformátumban adja ki az adatokat, amit a tervező nem támogat.Adja hozzá az R-szkript végrehajtása összetevő egy második példányát, és csatlakoztassa az előző összetevő kimeneti portjához.
Írja be a következő kódot az R-szkript szövegmezőbe, hogy kinyerje az objektumot
Aa bemeneti adattáblából.azureml_main <- function(dataframe1, dataframe2){ print("R script run.") A <- unserialize(as.raw(dataframe1$serialized)) # Return datasets as a Named List return(list(dataset1=dataframe1, dataset2=dataframe2)) }
Előre telepített R-csomagok
Jelenleg az alábbi előre telepített R-csomagok érhetők el:
| Csomag | Verzió |
|---|---|
| askpass | 1.1 |
| assertthat | 0.2.1 |
| backports | 1.1.4 |
| base | 3.5.1 |
| base64enc | 0.1-3 |
| BH | 1.69.0-1 |
| bindr | 0.1.1 |
| bindrcpp | 0.2.2 |
| bitops | 1.0-6 |
| boot | 1.3-22 |
| broom | 0.5.2 |
| callr | 3.2.0 |
| kalap jel | 6.0-84 |
| caTools | 1.17.1.2 |
| cellranger | 1.1.0 |
| osztály | 7.3-15 |
| cli | 1.1.0 |
| clipr | 0.6.0 |
| cluster | 2.0.7-1 |
| codetools | 0.2-16 |
| colorspace | 1.4-1 |
| compiler | 3.5.1 |
| crayon | 1.3.4 |
| curl | 3.3 |
| data.table | 1.12.2 |
| adathalmazok | 3.5.1 |
| DBI | 1.0.0 |
| dbplyr | 1.4.1 |
| digest | 0.6.19 |
| dplyr | 0.7.6 |
| e1071 | 1.7-2 |
| evaluate | 0.14 |
| fansi | 0.4.0 |
| forcats | 0.3.0 |
| foreach | 1.4.4 |
| foreign | 0.8-71 |
| Fs | 1.3.1 |
| gdata | 2.18.0 |
| Generikus | 0.0.2 |
| ggplot2 | 3.2.0 |
| glmnet | 2.0-18 |
| glue | 1.3.1 |
| gower | 0.2.1 |
| gplots | 3.0.1.1 |
| Grafikák | 3.5.1 |
| grDevices | 3.5.1 |
| grid | 3.5.1 |
| gtable | 0.3.0 |
| gtools | 3.8.1 |
| haven | 2.1.0 |
| highr | 0,8 |
| hms | 0.4.2 |
| htmltools | 0.3.6 |
| httr | 1.4.0 |
| ipred | 0.9-9 |
| iterators | 1.0.10 |
| jsonlite | 1.6 |
| KernSmooth | 2.23-15 |
| knitr | 1,23 |
| labeling | 0.3 |
| lattice | 0.20-38 |
| lava | 1.6.5 |
| lazyeval | 0.2.2 |
| lubridate | 1.7.4 |
| magrittr | 1.5 |
| markdown | 1 |
| MASS | 7.3-51.4 |
| Mátrix | 1.2-17 |
| methods | 3.5.1 |
| mgcv | 1.8-28 |
| mime | 0.7 |
| ModelMetrics | 1.2.2 |
| modelr | 0.1.4 |
| munsell | 0.5.0 |
| nlme | 3.1-140 |
| nnet | 7.3-12 |
| numDeriv | 2016.8-1.1 |
| openssl | 1.4 |
| parallel | 3.5.1 |
| pillar | 1.4.1 |
| pkgconfig | 2.0.2 |
| plogr | 0.2.0 |
| plyr | 1.8.4 |
| prettyunits | 1.0.2 |
| processx | 3.3.1 |
| prodlim | 2018.04.18 |
| progress | 1.2.2 |
| Ps | 1.3.0 |
| purrr | 0.3.2 |
| quadprog | 1.5-7 |
| quanteda | 0.4-15 |
| R6 | 2.4.0 |
| randomForest | 4.6-14 |
| RColorBrewer | 1.1-2 |
| Rcpp | 1.0.1 |
| RcppRoll | 0.3.0 |
| readr | 1.3.1 |
| readxl | 1.3.1 |
| recipes | 0.1.5 |
| rematch | 1.0.1 |
| reprex | 0.3.0 |
| reshape2 | 1.4.3 |
| reticulate | 1.12 |
| rlang | 0.4.0 |
| rmarkdown | 1.13 |
| ROCR | 1.0-7 |
| rpart | 4.1-15 |
| rstudioapi | 0.1 |
| rvest | 0.3.4 |
| scales | 1.0.0 |
| selectr | 0.4-1 |
| spatial | 7.3-11 |
| splines | 3.5.1 |
| SQUAREM | 2017.10-1 |
| stats | 3.5.1 |
| stats4 | 3.5.1 |
| stringi | 1.4.3 |
| stringr | 1.3.1 |
| survival | 2.44-1.1 |
| sys | 3.2 |
| tcltk | 3.5.1 |
| tibble | 2.1.3 |
| tidyr | 0.8.3 |
| tidyselect | 0.2.5 |
| tidyverse | 1.2.1 |
| timeDate | 3043.102 |
| tinytex | 0.13 |
| tools | 3.5.1 |
| tseries | 0.10-47 |
| TTR | 0.23-4 |
| utf8 | 1.1.4 |
| utils | 3.5.1 |
| vctrs | 0.1.0 |
| viridisLite | 0.3.0 |
| whisker | 0.3-2 |
| withr | 2.1.2 |
| xfun | 0,8 |
| xml2 | 1.2.0 |
| xts | 0.11-2 |
| yaml | 2.2.0 |
| zeallot | 0.1.0 |
| zoo | 1.8-6 |
Következő lépések
Tekintse meg az Azure Machine Learning számára elérhető összetevőket .
Visszajelzés
Hamarosan elérhető: 2024-ben fokozatosan kivezetjük a GitHub-problémákat a tartalom visszajelzési mechanizmusaként, és lecseréljük egy új visszajelzési rendszerre. További információ: https://aka.ms/ContentUserFeedback.
Visszajelzés küldése és megtekintése a következőhöz: