N-Gram-szolgáltatások kinyerve a szövegösszetevő referenciaanyagából
Ez a cikk az Azure Machine Learning designer egy összetevőjét ismerteti. Az N-Gram-szolgáltatások kinyerése a Szöveg összetevőből a strukturálatlan szöveges adatok featurizálásához.
Az N-Gram-szolgáltatások kinyerése szövegösszetevőből való konfigurálása
Az összetevő az alábbi forgatókönyveket támogatja az n-gram szótár használatához:
Hozzon létre egy új n-gram szótárat egy szabad szöveg oszlopából.
A szabad szövegoszlopok formázásához használjon meglévő szöveges funkciókat .
N grammot használó modell pontszáma vagy üzembe helyezése.
Új n-gram szótár létrehozása
Adja hozzá az N-Gram-szolgáltatások kinyerése a Szöveg összetevőből a folyamathoz, és csatlakoztassa a feldolgozni kívánt szöveget tartalmazó adatkészletet.
A Szöveg oszlop használatával válasszon ki egy sztring típusú oszlopot, amely tartalmazza a kinyerni kívánt szöveget. Mivel az eredmények részletesek, egyszerre csak egyetlen oszlopot dolgozhat fel.
Állítsa a Szókincs módot létrehozásra, hogy jelezze, hogy új listát hoz létre az n-gram funkciókról.
Állítsa be az N-Gramm méretet a kinyerni és tárolni kívánt n-gramm maximális méretének jelzésére.
Ha például 3 értéket ad meg, az unigramok, a bigramok és a trigramok létrejönnek.
A súlyozási függvény meghatározza, hogyan hozhatja létre a dokumentum funkcióvektorát, és hogyan nyerhet ki szókincset a dokumentumokból.
Bináris súly: Bináris jelenléti értéket rendel hozzá a kinyert n-grammhoz. Minden n-gram értéke 1, ha létezik a dokumentumban, és 0 egyéb esetben.
TF súly: Kifejezés gyakorisági (TF) pontszámot rendel a kinyert n-grammhoz. Az egyes n-grammok értéke az előfordulási gyakorisága a dokumentumban.
IDF-súly: Inverz dokumentum gyakorisági (IDF) pontszámot rendel a kinyert n-grammhoz. Az egyes n-grammok értéke a korpusz méretének naplója, amely a teljes korpusz előfordulási gyakoriságával van elosztva.
IDF = log of corpus_size / document_frequencyTF-IDF súly: A kinyert n-grammhoz hozzárendel egy kifejezés gyakorisági/inverz dokumentumfrekvencia-pontszámot (TF/IDF). Az egyes n-grammok értéke a TF-pontszám és az IDF-pontszám szorzata.
Állítsa be a szavak minimális hosszát az n-grammban lévő bármely szóban használható betűk minimális számára.
A Maximális szóhossz beállításával megadhatja, hogy hány betű használható egyetlen szóban egy n-grammban.
Alapértelmezés szerint szónként vagy jogkivonatonként legfeljebb 25 karakter adható meg.
A Minimális n-gram dokumentum abszolút gyakorisága beállításával megadhatja az n-gramok szótárába való belefoglalásához szükséges minimális előfordulásokat.
Ha például az alapértelmezett 5 értéket használja, az n-grammnak legalább ötször meg kell jelennie a korpuszban, hogy szerepeljen az n-gram szótárban.
Állítsa a maximális n-gramm dokumentumarányt az adott n-grammot tartalmazó sorok számának maximális arányára a teljes korpusz sorainak számával szemben.
Az 1 arány például azt jelzi, hogy még ha minden sorban egy adott n-gramm is szerepel, az n-gram hozzáadható az n-gram szótárhoz. Jellemzőbb, hogy egy minden sorban előforduló szó zajos szónak minősül, és el lesz távolítva. A tartományfüggő zajszavak kiszűréséhez próbálja meg csökkenteni ezt az arányt.
Fontos
Az egyes szavak előfordulási gyakorisága nem egységes. Dokumentumonként eltérő. Ha például egy adott termékhez kapcsolódó ügyfél megjegyzéseit elemzi, a terméknév nagyon magas gyakoriságú és zajos szóhoz közeli lehet, de más kontextusokban is jelentős kifejezés lehet.
Válassza az n-gram funkcióvektorok normalizálása lehetőséget a funkcióvektorok normalizálásához. Ha ez a beállítás engedélyezve van, minden n-gram-tulajdonságvektor az L2-normával van osztva.
Küldje el a folyamatot.
Meglévő n-gram szótár használata
Adja hozzá az N-Gram-szolgáltatások kinyerése a Szöveg összetevőből a folyamathoz, és csatlakoztassa a feldolgozni kívánt szöveget tartalmazó adathalmazt az Adathalmaz portjához.
A Szöveg oszlop használatával jelölje ki azt a szövegoszlopot, amely a featurálni kívánt szöveget tartalmazza. Alapértelmezés szerint az összetevő kiválasztja a sztring összes oszlopát. A legjobb eredmény érdekében egyszerre egyetlen oszlopot kell feldolgozni.
Adja hozzá a korábban létrehozott n-gram szótárat tartalmazó mentett adatkészletet, és csatlakoztassa a bemeneti szókincsporthoz . Az N-Gram-szolgáltatások kinyerése szövegösszetevőből származó felsőbb rétegbeli példány eredménykincs-kimenetét is csatlakoztathatja.
A Szókincs módban válassza a ReadOnly update (Olvasási frissítés ) lehetőséget a legördülő listából.
A ReadOnly beállítás a bemeneti szókincs bemeneti korpuszát jelöli. Ahelyett, hogy a kifejezésfrekvenciákat az új szöveges adatkészletből (a bal oldali bemeneten) számítanák ki, a bemeneti szókincs n-gram súlyait a rendszer az aktuális módon alkalmazza.
Tipp.
Ez a beállítás szövegosztályozó pontozásakor használható.
Az összes többi beállításhoz tekintse meg az előző szakaszban található tulajdonságleírásokat.
Küldje el a folyamatot.
N grammot használó következtetési folyamat létrehozása valós idejű végpont üzembe helyezéséhez
Egy betanítási folyamat, amely az N-Gramm kinyerési funkciót tartalmazza szövegből és pontszámmodellből a tesztadatkészlet előrejelzéséhez, a következő struktúrában épül fel:
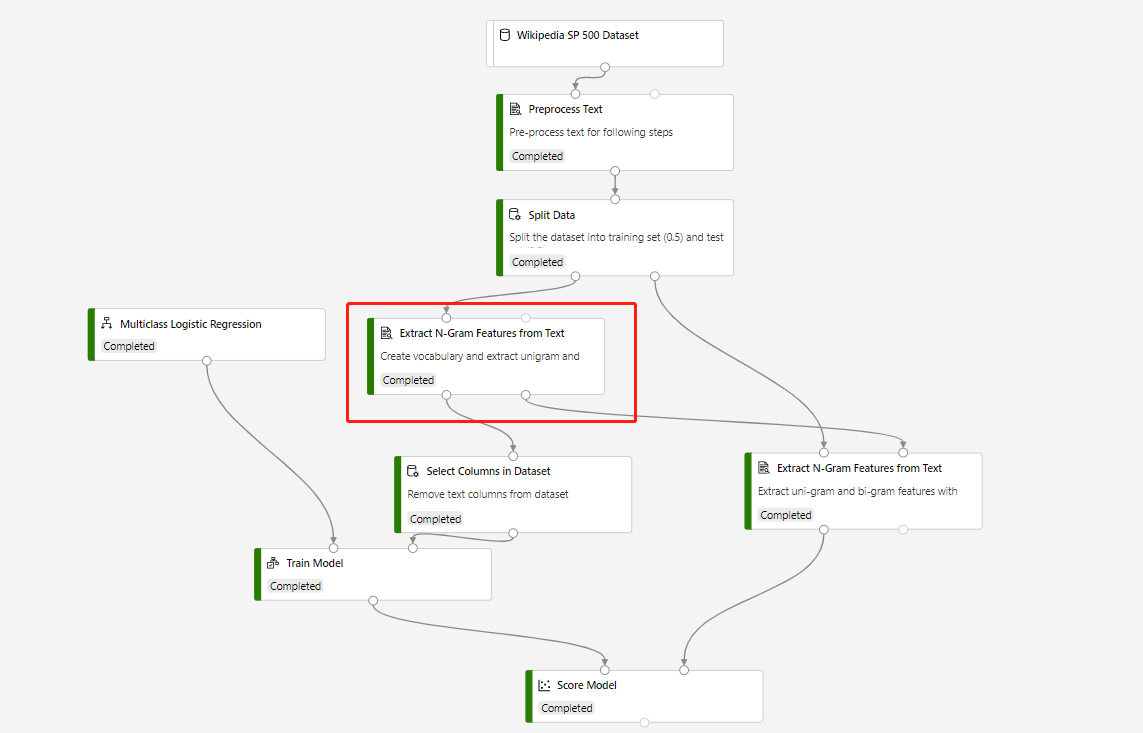
A körkörös N-Gramm kinyerés funkció szövegből funkciójának szókincsmódja a Létrehozás, a Score Model összetevőhöz csatlakozó összetevő szókincsmódja pedig ReadOnly.
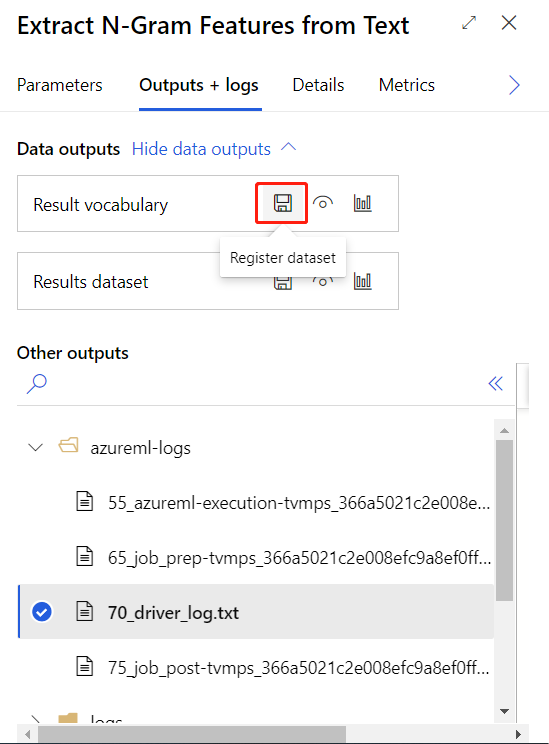
A fenti betanítási folyamat sikeres elküldése után a körkörös összetevő kimenetét adathalmazként regisztrálhatja.
Ezután valós idejű következtetési folyamatot hozhat létre. A következtetési folyamat létrehozása után manuálisan kell módosítania a következtetési folyamatot, például a következőket:
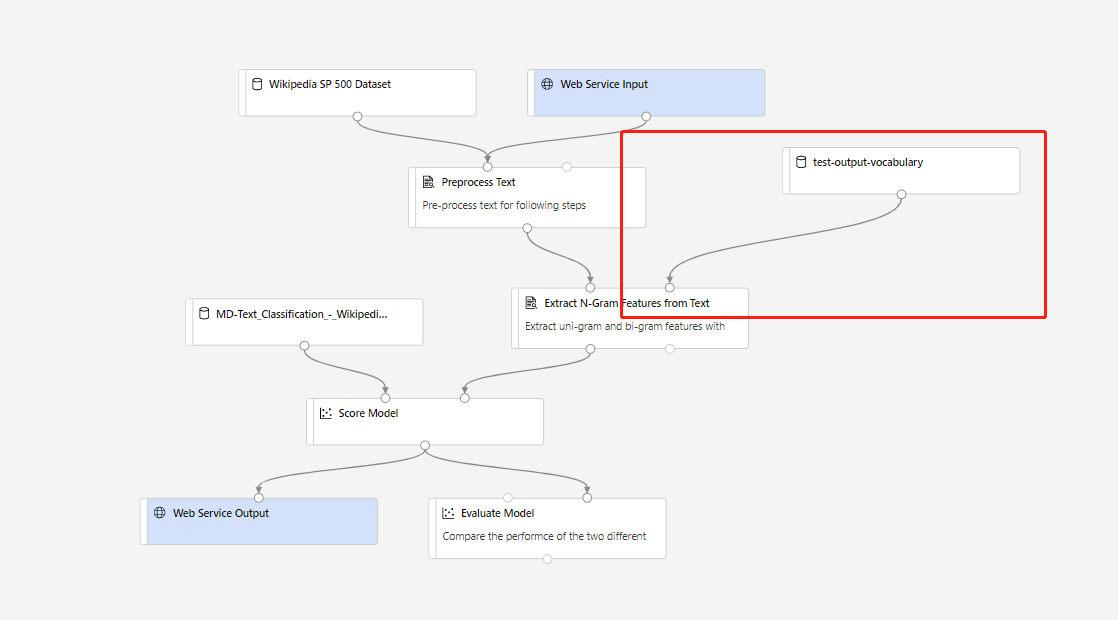
Ezután küldje el a következtetési folyamatot, és helyezzen üzembe egy valós idejű végpontot.
Results (Eredmények)
Az N-Gram-szolgáltatások kinyerése a Szöveg összetevőből kétféle kimenetet hoz létre:
Eredményadatkészlet: Ez a kimenet az elemzett szöveg és a kinyert n-gramm együttes összegzése. A Szöveg oszlop beállításban nem kiválasztott oszlopok át lesznek adva a kimenetnek. Az elemzett szöveg minden egyes oszlopához az összetevő a következő oszlopokat hozza létre:
- N-gram előfordulások mátrixa: Az összetevő létrehoz egy oszlopot az összes korpuszban található minden n-grammhoz, és minden oszlopban hozzáad egy pontszámot, amely jelzi az adott sor n-gramjának súlyát.
Eredményszótár: A szókincs tartalmazza a tényleges n-gram szótárat, valamint az elemzés részeként létrehozott gyakorisági pontszámokat. Az adathalmazt más bemenetekkel vagy későbbi frissítéssel is mentheti újra. A szókészletet a modellezéshez és a pontozáshoz is felhasználhatja.
Eredményszókincs
A szókincs tartalmazza az n-gram szótárat az elemzés során generált gyakorisági pontszámokkal. A DF- és IDF-pontszámok a többi beállítástól függetlenül jönnek létre.
- Azonosító: Minden egyes egyedi n-gramhoz létrehozott azonosító.
- NGram: Az n-gram. A szóközöket vagy más szóelválasztókat az aláhúzásjel helyettesíti.
- DF: Az eredeti korpusz n-grammjának kifejezésfrekvencia-pontszáma.
- IDF: Az n-gram inverz dokumentumfrekvencia-pontszáma az eredeti korpuszban.
Ezt az adatkészletet manuálisan is frissítheti, de hibákat okozhat. Példa:
- Hiba akkor jelentkezik, ha az összetevő ismétlődő sorokat talál ugyanazzal a kulccsal a bemeneti szókincsben. Győződjön meg arról, hogy a szókészlet két sora sem rendelkezik ugyanazzal a szóval.
- A szókincs-adatkészletek bemeneti sémájának pontosan meg kell egyeznie, beleértve az oszlopneveket és az oszloptípusokat.
- Az azonosító oszlopnak és a DF oszlopnak egész szám típusúnak kell lennie.
- Az IDF oszlopnak lebegtetés típusúnak kell lennie.
Feljegyzés
Ne csatlakoztassa közvetlenül az adatkimenetet a Modell betanítása összetevőhöz. A szabad szöveges oszlopokat el kell távolítania, mielőtt betáplálják őket a Betanított modellbe. Ellenkező esetben a szabad szöveges oszlopok kategorikus funkciókként lesznek kezelve.
Következő lépések
Tekintse meg az Azure Machine Learning számára elérhető összetevőket.