Partíció és mintaösszetevő
Ez a cikk az Azure Machine Learning designer egy összetevőjét ismerteti.
A Partíció és a Minta összetevővel mintavételezést végezhet egy adathalmazon, vagy partíciókat hozhat létre az adathalmazból.
A mintavételezés fontos eszköz a gépi tanulásban, mivel lehetővé teszi az adathalmazok méretének csökkentését, ugyanakkor az értékek azonos arányának fenntartását. Ez az összetevő számos olyan kapcsolódó feladatot támogat, amelyek fontosak a gépi tanulásban:
Az adatok osztva több, azonos méretű alszakaszra.
Használhatja a partíciókat keresztérvényesítésre, vagy eseteket rendelhet véletlenszerű csoportokhoz.
Adatok csoportosítása csoportokra, majd adatokkal való munka egy adott csoportból.
Miután véletlenszerűen hozzárendelte az eseteket különböző csoportokhoz, előfordulhat, hogy csak egy csoporthoz társított funkciókat kell módosítania.
Mintavétel.
Kinyerheti az adatok egy százalékát, véletlenszerű mintavételezést alkalmazhat, vagy kiválaszthat egy oszlopot az adathalmaz kiegyensúlyozásához, és rétegzett mintavételezést végezhet az értékein.
Kisebb adatkészlet létrehozása teszteléshez.
Ha sok adattal rendelkezik, előfordulhat, hogy csak az első n sort szeretné használni a folyamat beállításakor, majd váltson a teljes adatkészlet használatára a modell létrehozásakor. A mintavételezéssel kisebb adatkészletet is létrehozhat a fejlesztéshez.
Az összetevő konfigurálása
Ez az összetevő az alábbi módszereket támogatja az adatok partíciókra vagy mintavételezésre való felosztásához. Először válassza ki a metódust, majd adja meg a metódus által igényelt további beállításokat.
- Head
- Mintavételezés
- Hozzárendelés hajtásokhoz
- Hajtás kiválasztása
TOP N-sorok lekérése adatkészletből
Ezzel a móddal csak az első n sorokat szerezheti be. Ez a lehetőség akkor hasznos, ha egy folyamatot kis számú sorban szeretne tesztelni, és nincs szüksége az adatok kiegyensúlyozottságára vagy mintavételére semmilyen módon.
Adja hozzá a partíció és a minta összetevőt a folyamathoz a felületen, és csatlakoztassa az adathalmazt.
Partíció vagy minta mód: Állítsa ezt a beállítást a Head (Fej) értékre.
Kijelölendő sorok száma: Adja meg a visszaadni kívánt sorok számát.
A sorok számának nem negatív egész számnak kell lennie. Ha a kijelölt sorok száma nagyobb, mint az adathalmaz sorainak száma, a rendszer a teljes adatkészletet adja vissza.
Küldje el a folyamatot.
Az összetevő egyetlen adatkészletet ad ki, amely csak a megadott számú sort tartalmazza. A sorok mindig az adathalmaz tetejéről lesznek beolvasva.
Adatminta létrehozása
Ez a beállítás egyszerű véletlenszerű mintavételezést vagy rétegzett véletlenszerű mintavételezést támogat. Ez akkor hasznos, ha kisebb reprezentatív mintaadatkészletet szeretne létrehozni teszteléshez.
Adja hozzá a partíció és a minta összetevőt a folyamathoz, és csatlakoztassa az adathalmazt.
Partíció vagy minta mód: Állítsa ezt a beállítást mintavételezésre.
Mintavételezési sebesség: Adjon meg egy 0 és 1 közötti értéket. Ez az érték a forrásadatkészlet azon sorainak százalékos arányát adja meg, amelyeket a kimeneti adathalmaznak tartalmaznia kell.
Ha például az eredeti adathalmaznak csak a felét szeretné, adja meg
0.5, hogy a mintavételezési arány 50 százalék legyen.A bemeneti adatkészlet sorait a rendszer a megadott aránynak megfelelően elkeveri és szelektíven helyezi el a kimeneti adatkészletben.
Véletlenszerű vetőmag mintavételezéshez: Igény szerint adjon meg egy egész számot, amelyet magértékként szeretne használni.
Ez a beállítás akkor fontos, ha azt szeretné, hogy a sorok minden alkalommal ugyanúgy legyenek elosztva. Az alapértelmezett érték 0, ami azt jelenti, hogy a rendszer órajele alapján egy kezdőmag jön létre. Ez az érték a folyamat minden futtatásakor kissé eltérő eredményeket eredményezhet.
Rétegzett felosztás mintavételezéshez: Válassza ezt a lehetőséget, ha fontos, hogy az adathalmaz sorait egyenletesen osztja el egy kulcsoszlop a mintavételezés előtt.
A mintavételezéshez használt Rétegzési kulcs oszlop esetében válassza ki az adathalmaz osztásához használandó egyetlen rétegoszlopot . Az adathalmaz sorai a következőképpen lesznek felosztva:
Az összes bemeneti sor a megadott rétegoszlop értékei szerint van csoportosítva (rétegzett).
A sorok az egyes csoportokon belül vannak elkeverve.
A rendszer minden csoportot szelektíven ad hozzá a kimeneti adatkészlethez, hogy megfeleljen a megadott aránynak.
Küldje el a folyamatot.
Ezzel a beállítással az összetevő egyetlen adatkészletet ad ki, amely az adatok reprezentatív mintavételezését tartalmazza. Az adathalmaz fennmaradó, nem csomagolt része nem kimenet.
Adatok felosztása partíciókra
Ezt a lehetőséget akkor használja, ha az adathalmazt az adatok részhalmazaira szeretné osztani. Ez a beállítás akkor is hasznos, ha egyéni számú redőt szeretne létrehozni keresztérvényesítéshez, vagy sorokat szeretne több csoportra osztani.
Adja hozzá a partíció és a minta összetevőt a folyamathoz, és csatlakoztassa az adathalmazt.
Partíció vagy minta mód esetén válassza a Hozzárendelés a hajtásokhoz lehetőséget.
Csere használata a particionálásban: Válassza ezt a lehetőséget, ha azt szeretné, hogy a mintául szolgáló sor vissza legyen helyezve a sorok készletébe a lehetséges újrafelhasználáshoz. Ennek eredményeképpen ugyanaz a sor több hajtáshoz is hozzárendelhető.
Ha nem használ csere (az alapértelmezett beállítás), a mintasor nem kerül vissza a sorok készletébe a lehetséges újrafelhasználáshoz. Ennek eredményeképpen minden sor csak egy hajtáshoz rendelhető hozzá.
Véletlenszerű felosztás: Válassza ezt a beállítást, ha azt szeretné, hogy a sorok véletlenszerűen legyenek kiosztva a hajtásokhoz.
Ha nem választja ki ezt a beállítást, a sorok a ciklikus időszeleteléses módszerrel lesznek kiosztva a hajtásokhoz.
Véletlenszerű mag: Igény szerint adjon meg egy egész számot, amelyet magértékként szeretne használni. Ez a beállítás akkor fontos, ha azt szeretné, hogy a sorok minden alkalommal ugyanúgy legyenek elosztva. Ellenkező esetben a 0 alapértelmezett értéke azt jelenti, hogy a rendszer véletlenszerű kezdőmagot használ.
Adja meg a particionáló metódust: Adja meg, hogy az adatok hogyan legyenek felosztva az egyes partíciókra az alábbi beállításokkal:
Partíció egyenlően: Ezzel a beállítással egyenlő számú sort helyezhet el az egyes partíciókban. A kimeneti partíciók számának megadásához írjon be egy egész számot a mezőre egyenlően felosztandó redők számának megadása mezőben.
Partíció testreszabott arányokkal: Ezzel a beállítással vesszővel elválasztott listaként adhatja meg az egyes partíciók méretét.
Tegyük fel például, hogy három partíciót szeretne létrehozni. Az első partíció az adatok 50 százalékát tartalmazza. A fennmaradó két partíció mindegyike az adatok 25 százalékát tartalmazza. A vesszővel elválasztott arányok listájában adja meg a következő számokat: .5, .25, .25.
Az összes partícióméret összegének pontosan 1-nek kell lennie.
Ha 1-nél kisebb számokat ad meg, a rendszer egy további partíciót hoz létre a fennmaradó sorok tárolásához. Ha például a .2 és a .3 értéket adja meg, a rendszer létrehoz egy harmadik partíciót, amely az összes sor fennmaradó 50 százalékát tárolja.
Ha 1-nél több számot ad meg, a folyamat futtatásakor hiba lép fel.
Rétegzett felosztás: Jelölje be ezt a beállítást, ha felosztáskor rétegzni szeretné a sorokat, majd válassza ki a strata oszlopot.
Küldje el a folyamatot.
Ezzel a beállítással az összetevő több adatkészletet ad ki. Az adatkészletek a megadott szabályok szerint vannak particionálva.
Adatok használata előre definiált partícióból
Ezt a lehetőséget akkor használhatja, ha egy adathalmazt több partícióra osztott, és most szeretné betölteni az egyes partíciókat további elemzés vagy feldolgozás céljából.
Adja hozzá a partíció és a minta összetevőt a folyamathoz.
Csatlakoztassa az összetevőt a partíció és a minta egy korábbi példányának kimenetéhez. A példánynak a Folds hozzárendelése beállítással kellett létrehoznia néhány partíciót.
Partíció vagy minta mód: Válassza a Pick Fold lehetőséget.
Adja meg, hogy melyik hajtásból szeretne mintát venni: Válassza ki a használni kívánt partíciót az index beírásával. A partícióindexek 1-alapúak. Ha például az adathalmazt három részre osztotta, a partíciók 1, 2 és 3 indexekkel rendelkeznek.
Ha érvénytelen indexértéket ad meg, a rendszer tervezési időt jelző hibát jelez: "0018-ás hiba: Az adathalmaz érvénytelen adatokat tartalmaz."
Az adathalmaz hajtások szerinti csoportosítása mellett az adathalmazt két csoportra oszthatja: egy célredőre és minden másra. Ehhez adja meg az egyetlen hajtás indexét, majd válassza a kiválasztott hajtás kiegészítésének kiválasztása lehetőséget, hogy a megadott hajtásban lévő adatokon kivegye az adatokat.
Ha több partícióval dolgozik, az egyes partíciók kezeléséhez hozzá kell adnia a Partíció és a Minta összetevő további példányait.
A második sorban lévő Partíció és minta összetevő például a Kiosztás a hajtásokhoz, a harmadik sorban pedig a Pick Fold értékre van állítva.
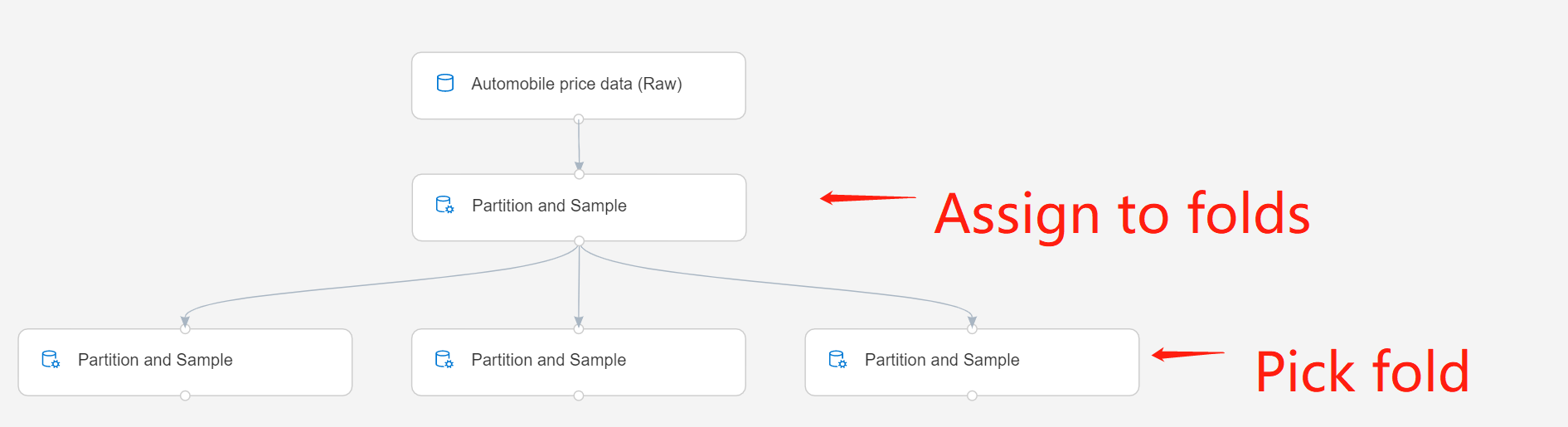
Küldje el a folyamatot.
Ezzel a beállítással az összetevő egyetlen adatkészletet ad ki, amely csak az adott hajtáshoz rendelt sorokat tartalmazza.
Feljegyzés
A hajtásjelöléseket nem tekintheti meg közvetlenül. Csak a metaadatokban vannak jelen.
Következő lépések
Tekintse meg az Azure Machine Learning számára elérhető összetevőket.