Szöveg előfeldolgozása
Ez a cikk az Azure Machine Learning designer egy összetevőjét ismerteti.
A Szöveg előfeldolgozása összetevő használatával tisztíthatja és egyszerűsítheti a szöveget. Támogatja ezeket a gyakori szövegfeldolgozási műveleteket:
- Stop-words eltávolítása
- Meghatározott célsztringek keresése és cseréje reguláris kifejezések használatával
- Lemmatizálás, amely több kapcsolódó szót konvertál egyetlen canonical formára
- Kis- és nagybetűk normalizálása
- Bizonyos karakterosztályok, például számok, speciális karakterek és ismétlődő karakterek sorozatának eltávolítása, például "aaaa"
- E-mailek és URL-címek azonosítása és eltávolítása
A Szöveg előfeldolgozása összetevő jelenleg csak az angol nyelvet támogatja.
Szövegelőfeldolgozás konfigurálása
Adja hozzá az előfeldolgozási szöveg összetevőt a folyamathoz az Azure Machine Learningben. Ezt az összetevőt a Text Analytics alatt találja.
Olyan adathalmaz csatlakoztatása, amely legalább egy szöveget tartalmazó oszlopot tartalmaz.
Válassza ki a nyelvet a Nyelv legördülő listából.
Tisztítandó szövegoszlop: Jelölje ki az előfeldolgozáshoz használni kívánt oszlopot.
Leállító szavak eltávolítása: Válassza ezt a beállítást, ha előre definiált stopword listát szeretne alkalmazni a szövegoszlopra.
A stopword listák nyelvfüggőek és testreszabhatók.
Lemmatizálás: Válassza ezt a beállítást, ha azt szeretné, hogy a szavak a vesszőjükön jelenjenek meg. Ez a beállítás az egyébként hasonló szöveges jogkivonatok egyedi előfordulásainak számának csökkentéséhez hasznos.
A lemmatizálási folyamat erősen nyelvfüggő.
Mondatok észlelése: Válassza ezt a lehetőséget, ha azt szeretné, hogy az összetevő mondathatárjelet szúrjon be az elemzés során.
Ez az összetevő három csőkarakterekből
|||álló sorozatot használ a mondat terminátorának ábrázolásához.Opcionális keresési és csereműveleteket végezhet reguláris kifejezések használatával. A reguláris kifejezés első alkalommal lesz feldolgozva, az összes többi beépített beállítás előtt.
- Egyéni reguláris kifejezés: Határozza meg a keresett szöveget.
- Egyéni cseresztring: Adjon meg egyetlen csereértéket.
Kisbetűssé alakíthatja a kisbetűs kisbetűket: Válassza ezt a beállítást, ha kisbetűssé szeretné alakítani az ASCII-nagybetűket.
Ha a karakterek nincsenek normalizálva, ugyanazt a kis- és nagybetűket tartalmazó szót két különböző szónak tekintjük.
A feldolgozott kimeneti szövegből a következő karaktertípusokat vagy karaktersorozatokat is eltávolíthatja:
Számok eltávolítása: Ezzel a beállítással eltávolíthatja a megadott nyelv összes numerikus karakterét. Az azonosítási számok tartományfüggőek és nyelvfüggőek. Ha a numerikus karakterek egy ismert szó szerves részét képezik, előfordulhat, hogy a szám nem lesz eltávolítva. További információ a műszaki megjegyzésekben.
Speciális karakterek eltávolítása: Ezzel a beállítással eltávolíthatja a nem alfanumerikus speciális karaktereket.
Ismétlődő karakterek eltávolítása: Ezzel a beállítással eltávolíthat további karaktereket minden olyan sorozatból, amely többször ismétlődik. Az "aaaaa" sorozat például "a" értékre csökken.
E-mail-címek eltávolítása: Ezzel a beállítással eltávolíthatja a formátum
<string>@<string>tetszőleges sorozatát.URL-címek eltávolítása: Ezzel a beállítással eltávolíthatja a következő URL-előtagokat tartalmazó sorozatokat:
http,https, ,ftpwww
Igék összevonásainak kibontása: Ez a beállítás csak az igék összehúzódásait használó nyelvekre vonatkozik, jelenleg csak angol nyelven.
Ha például ezt a lehetőséget választja, lecserélheti a "nem maradna ott" kifejezést a "nem maradna ott" kifejezésre.
Fordított perjelek normalizálása perjelekre: Ezt a beállítást választva megfeleltetheti az összes példányt
\\./Speciális karaktereken lévő jogkivonatok felosztása: Válassza ezt a lehetőséget, ha olyan karaktereken szeretné megszakítani a szavakat, mint
&például a ,-és így tovább. Ez a beállítás a speciális karaktereket is csökkentheti, ha kétszer többször ismétlődik.A sztring
MS---WORDpéldául három jogkivonatraMS-, ésWORD.Küldje el a folyamatot.
Technikai megjegyzések
A Studio (klasszikus) és tervezői előfeldolgozási szövegösszetevője különböző nyelvi modelleket használ. A tervező egy többfeladatos CNN-betanított modellt használ a spaCy szolgáltatásból. A különböző modellek különböző jogkivonat-jelölőt és beszédrész-címkézőt adnak, ami eltérő eredményekhez vezet.
Az alábbiakban néhány példát mutatunk be:
| Konfiguráció | Kimeneti eredmény |
|---|---|
| Ha az összes lehetőség ki van választva , a " WC-3 3 3test 4test" esetében a tervező eltávolítja a teljes "3test" szót, mivel ebben a kontextusban a beszéd része tagger számként adja meg a "3test" jogkivonatot, és a beszéd része szerint az összetevő eltávolítja azt. |
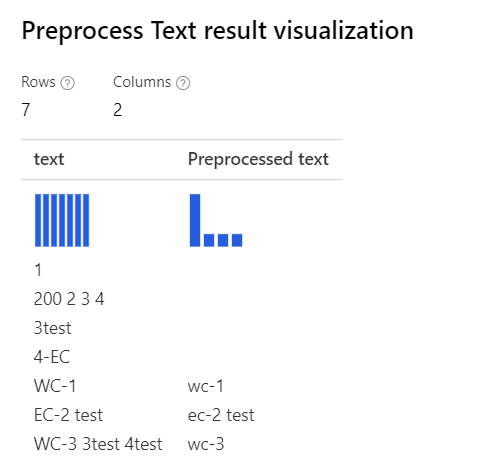
|
Csak Removing number a kiválasztott magyarázat: Az olyan esetekben, mint a "3test", "4-EC", a tervező tokenizer adag nem osztotta ezeket az eseteket, és kezeli őket, mint a teljes jogkivonatok. Így nem távolítja el a számokat ezekben a szavakban. |

|
A testre szabott eredmények kimenete normál kifejezéssel is használható:
| Konfiguráció | Kimeneti eredmény |
|---|---|
| Az összes beállításnál az Egyéni reguláris kifejezés: (\s+)*(-|\d+)(\s+)* Egyéni helyettesítő sztring: \1 \2 \3 |

|
Csak Removing number a kijelölt egyéni reguláris kifejezéssel: (\s+)*(-|\d+)(\s+)* Egyéni helyettesítő sztring: \1 \2 \3 |
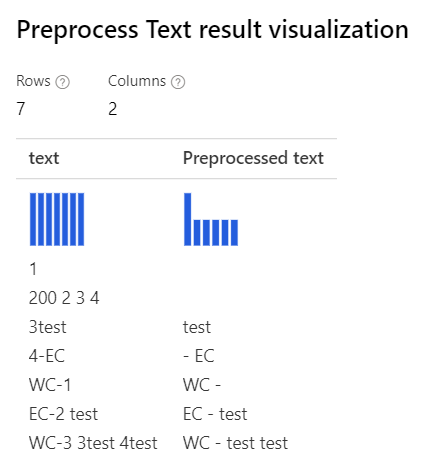
|
Következő lépések
Tekintse meg az Azure Machine Learning számára elérhető összetevőket.
Visszajelzés
Hamarosan elérhető: 2024-ben fokozatosan kivezetjük a GitHub-problémákat a tartalom visszajelzési mechanizmusaként, és lecseréljük egy új visszajelzési rendszerre. További információ: https://aka.ms/ContentUserFeedback.
Visszajelzés küldése és megtekintése a következőhöz: