Mély tanulás AutoML-előrejelzéssel
Ez a cikk az AutoML idősor-előrejelzésének mélytanulási módszereire összpontosít. Az AutoML-betanítási előrejelzési modellek betanítására vonatkozó utasításokat és példákat az AutoML beállítása idősor-előrejelzési cikkünkben találja.
A mély tanulás jelentős hatást gyakorolt többek között a nyelvmodellezéstől a fehérjeátadásig. Az idősorok előrejelzése hasonlóképpen hasznos volt a mélytanulási technológia közelmúltbeli fejlődéséből. A mély neurális hálózati (DNN-) modellek például kiemelkedően szerepelnek a nagy teljesítményű Makridakis előrejelzési verseny negyedik és ötödik iterációjának legjobban teljesítő modelljeiben.
Ebben a cikkben a TCNForecaster modell struktúráját és működését ismertetjük az AutoML-ben, hogy a lehető legjobban alkalmazza a modellt a forgatókönyvre.
A TCNForecaster bemutatása
A TCNForecaster egy időbeli konvolúciós hálózat vagy TCN, amely kifejezetten idősoradatokhoz tervezett DNN-architektúrával rendelkezik. A modell a célmennyiség előzményadatait és a kapcsolódó jellemzőket felhasználva valószínűségi előrejelzéseket készít a célról egy adott előrejelzési horizontig. Az alábbi képen a TCNForecaster architektúra fő összetevői láthatók:
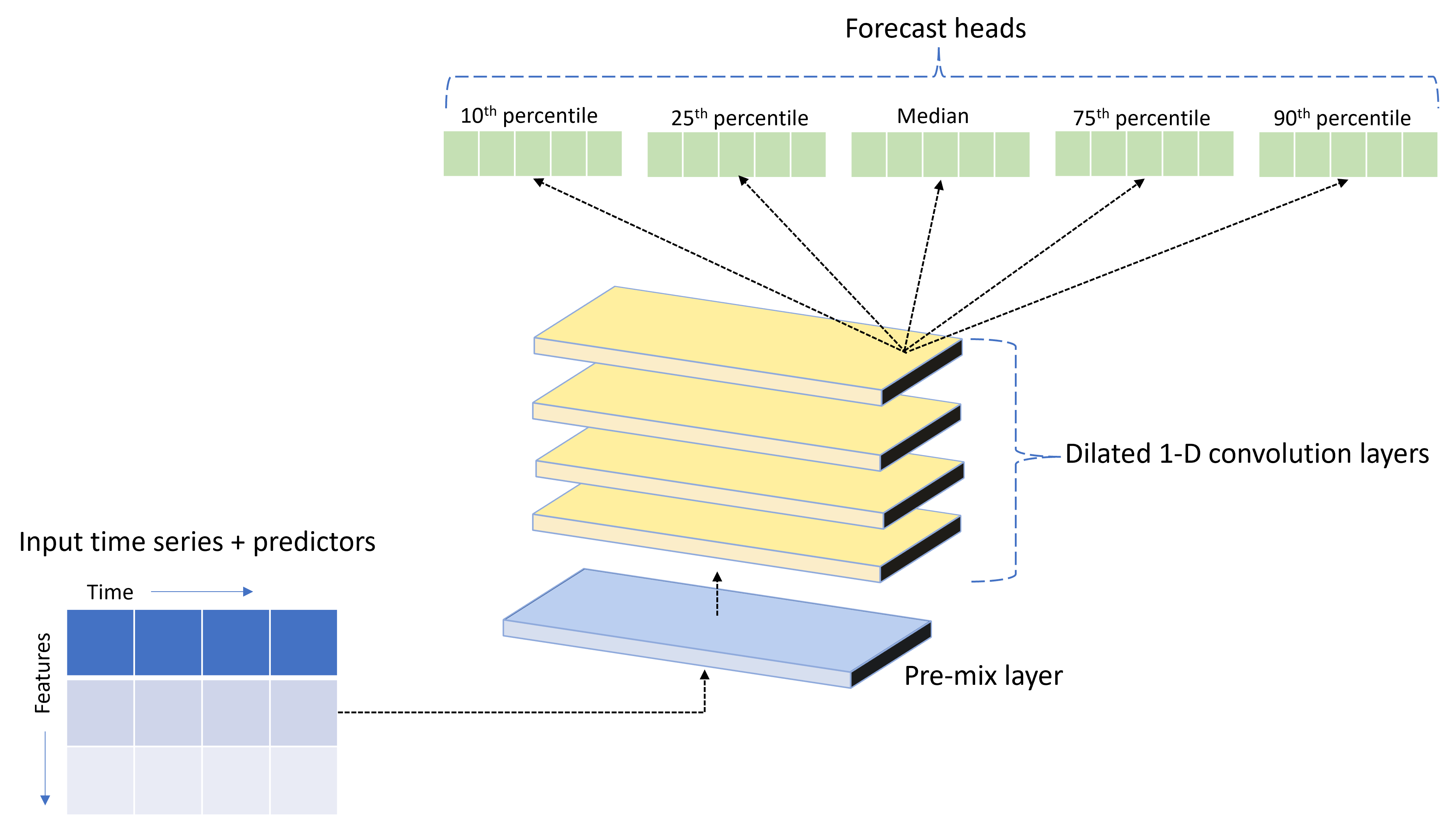
A TCNForecaster a következő fő összetevőkkel rendelkezik:
- Egy előkeverési réteg, amely a bemeneti idősorokat és a jellemzőadatokat egy jelcsatornák tömbjébe keveri, amelyeket a konvolúciós verem feldolgoz.
- Egy halom tág konvolúciós réteg, amely szekvenciálisan dolgozza fel a csatornatömböt; a verem minden rétege feldolgozza az előző réteg kimenetét egy új csatornatömb létrehozásához. A kimenet minden csatornája konvolúciószűrött jeleket tartalmaz a bemeneti csatornákból.
- Előrejelzési fejegységek gyűjteménye, amelyek a konvolúciós rétegekből származó kimeneti jeleket összevonják, és ebből a látens ábrázolásból generálnak előrejelzéseket a célmennyiségről. Az egyes fejegységek az előrejelzési eloszlás kvantilisére vonatkozó előrejelzéseket állítanak elő a horizontig.
Kitágult ok-okozati konvolúció
A TCN központi működése egy kitágult, okozati konvolúció a bemeneti jel idődimenziója mentén. Intuitív módon a konvolúció összevonja a bemenet közeli időpontjaiból származó értékeket. A keverékben az arányok a konvolúció kernele vagy súlyai, míg a keverék pontjainak elválasztása a tágulás. A kimeneti jel a bemenetből jön létre úgy, hogy a kernelt időben csúsztatja a bemenet mentén, és a keveréket minden pozícióban összeadja. Az ok-okozati konvolúció olyan, amelyben a kernel csak a múltbeli bemeneti értékeket keveri össze az egyes kimeneti pontokhoz viszonyítva, megakadályozva, hogy a kimenet "betekintsen" a jövőbe.
A halmozott dilatált konvolúciók lehetővé teszi a TCN-nek, hogy viszonylag kevés kernelsúlyú bemeneti jelekben modellezheti a hosszú időtartamú korrelációkat. Az alábbi képen például három halmozott réteg látható, mindegyik rétegben két súlyú kernellel és exponenciálisan növekvő dilatációs tényezőkkel:
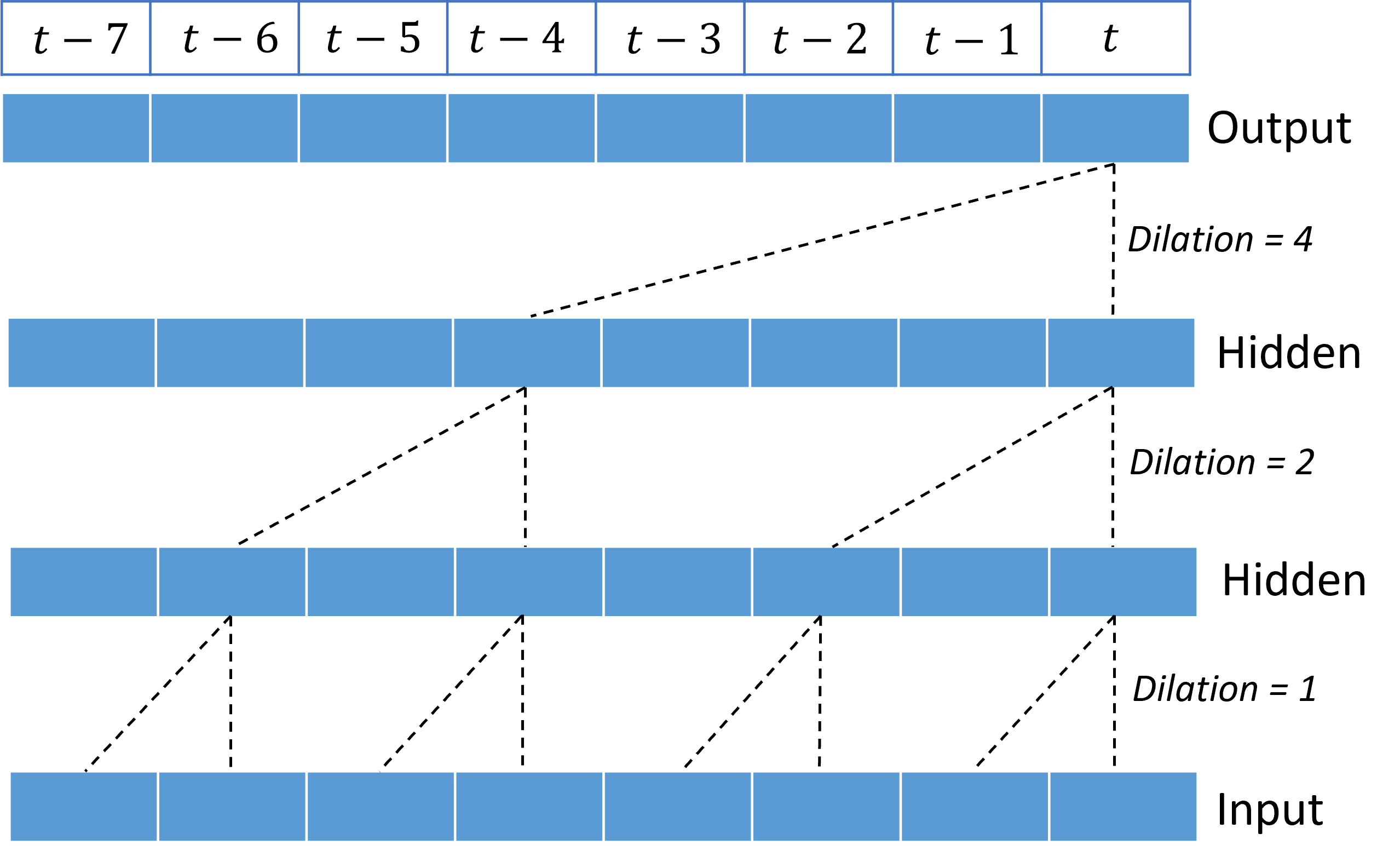
A szaggatott vonalak a hálózaton áthaladó útvonalakat mutatják, amelyek a kimeneten $t$ időpontban végződnek. Ezek az elérési utak a bemenet utolsó nyolc pontját fedik le, ami azt szemlélteti, hogy minden kimeneti pont a bemenet nyolc viszonylag legfrissebb pontjának függvénye. A konvolúciós hálózatok által az előrejelzések készítéséhez használt előzmény hosszát receptív mezőnek nevezzük, amelyet teljes egészében a TCN-architektúra határoz meg.
TCNForecaster architektúra
A TCNForecaster architektúra magja az előkeverés és az előrejelzési fejek közötti konvolúciós rétegek készlete. A verem logikailag ismétlődő egységekre, úgynevezett blokkokra van osztva, amelyek viszont reziduális cellákból állnak. A reziduális sejt okozati konvolúciókat alkalmaz egy meghatározott tágulásnál, valamint normalizálást és nemlineáris aktiválást. Fontos, hogy minden reziduális cella egy úgynevezett reziduális kapcsolattal adja hozzá a kimenetét a bemenethez. Ezek a kapcsolatok hasznosnak bizonyultak a DNN-betanításban, talán azért, mert elősegítik a hálózaton keresztüli hatékonyabb információáramlást. Az alábbi képen egy példahálózat konvolúciós rétegeinek architektúrája látható, amelyben két blokk és három reziduális cella található minden blokkban:
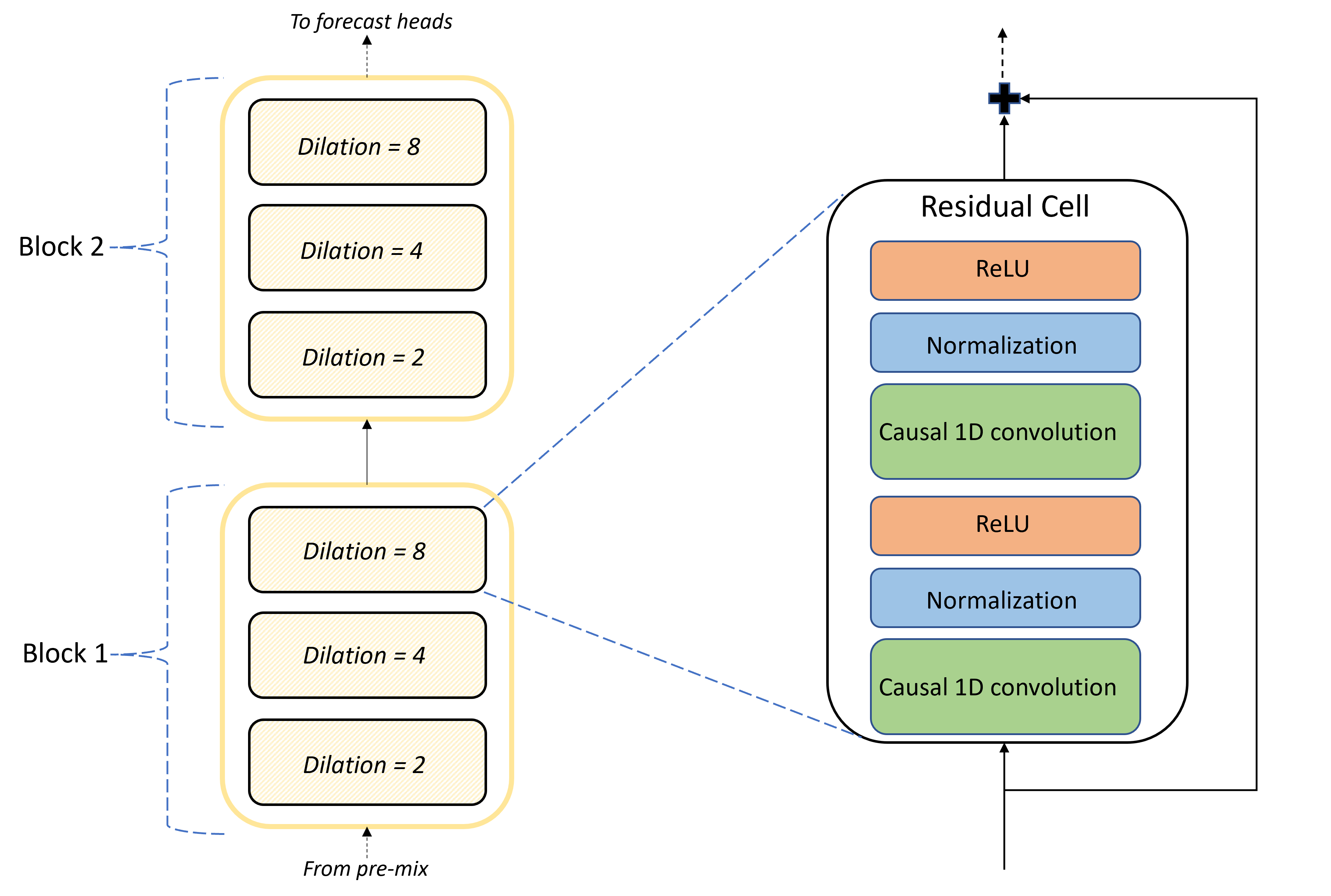
A blokkok és cellák száma, valamint az egyes rétegek jelcsatornáinak száma szabályozza a hálózat méretét. A TCNForecaster architekturális paramétereit az alábbi táblázat foglalja össze:
| Paraméter | Leírás |
|---|---|
| $n_{b}$ | A hálózat blokkjainak száma; más néven a mélység |
| $n_{c}$ | Cellák száma az egyes blokkokban |
| $n_{\text{ch}}$ | Csatornák száma a rejtett rétegekben |
A receptív mező a mélységi paraméterektől függ, és a képlet adja meg,
$t_{\text{rf}} = 4n_{b}\left(2^{n_{c}} - 1\right) + 1.$
Pontosabban definiálhatjuk a TCNForecaster architektúrát képletek tekintetében. Legyen $X$ egy bemeneti tömb, amelyben minden sor tartalmazza a bemeneti adatok funkcióértékeit. A $X$ numerikus és kategorikus funkciótömbökre osztható, $X_{\text{num}}$ és $X_{\text{cat}}$. Ezután a TCNForecastert a képletek adják meg,

ahol $W_{e}$ a kategorikus jellemzők beágyazási mátrixa, $n_{l} = n_{b}n_{c}$ a reziduális cellák teljes száma, a $H_{k}$ a rejtett rétegkimeneteket jelöli, a $f_{q}$ pedig az előrejelzési eloszlás adott kvantiliseinek előrejelzési kimenetei. A megértés érdekében ezeknek a változóknak a dimenziói a következő táblázatban találhatók:
| Változó | Leírás | Dimenziók |
|---|---|---|
| $X$ | Bemeneti tömb | $n_{\text{input}} \times t_{\text{rf}}$ |
| $H_{i}$ | Rejtett rétegkimenet a következőhöz: $i=0,1,\ldots,n_{l}$ | $n_{\text{ch}} \times t_{\text{rf}}$ |
| $f_{q}$ | A kvantilis $q$ előrejelzési kimenete | $h$ |
A táblázatban $n_{\text{input}} = n_{\text{features}} + 1$, a prediktor/funkcióváltozók száma és a célmennyiség. Az előrejelzési fejek egyetlen lépésben generálják az összes előrejelzést a maximális horizontig ($h$), így a TCNForecaster egy közvetlen előrejelzési szolgáltató.
TCNForecaster az AutoML-ben
A TCNForecaster az AutoML opcionális modellje. A használatát a mély tanulás engedélyezését ismertető cikkben találhatja meg.
Ebben a szakaszban azt ismertetjük, hogyan hozza létre az AutoML a TCNForecaster-modelleket az adataival, beleértve az adatok előfeldolgozásának, betanításának és keresésének magyarázatát.
Az adatok előfeldolgozásának lépései
Az AutoML számos előfeldolgozási lépést hajt végre az adatokon a modell betanításának előkészítéséhez. Az alábbi táblázat ezeket a lépéseket ismerteti a végrehajtásuk sorrendjében:
| Lépés | Leírás |
|---|---|
| Hiányzó adatok kitöltése | Hiányzó értékek és megfigyelési rések elnémítása , illetve rövid idősorok kitöltése vagy elvetése |
| Naptárfunkciók létrehozása | Bővítse a bemeneti adatokat a naptárból származó funkciókkal , például a hét napjával és adott ország/régió ünnepnapjával. |
| Kategorikus adatok kódolása | Címkekódoló sztringek és más kategorikus típusok; Ez magában foglalja az összes idősor-azonosító oszlopot. |
| Célátalakítás | A természetes logaritmusfüggvényt a célra is alkalmazhatja bizonyos statisztikai tesztek eredményeitől függően. |
| Normalizálás | A Z-pontszám normalizálja az összes numerikus adatot; a normalizálás funkciónként és idősorcsoportonként történik, az idősor-azonosító oszlopok által meghatározott módon. |
Ezeket a lépéseket az AutoML átalakítási folyamatai tartalmazzák, így a rendszer automatikusan alkalmazza őket, ha a következtetési időpontban szükség van rájuk. Bizonyos esetekben a lépésre irányuló inverz művelet szerepel a következtetési folyamatban. Ha például az AutoML $\log$ átalakítást alkalmazott a célra a betanítás során, a nyers előrejelzések exponenciálisan jelennek meg a következtetési folyamatban.
Oktatás
A TCNForecaster a más alkalmazásokhoz gyakran használt ajánlott DNN-betanítási eljárásokat követi képeken és nyelveken. Az AutoML az előre feldolgozott betanítási adatokat olyan példákra osztja fel, amelyek kötegekre vannak osztva és kombinálva. A hálózat szekvenciálisan dolgozza fel a kötegeket, visszapropagálás és sztochasztikus gradiens ereszkedés használatával optimalizálja a hálózati súlyokat a veszteségfüggvények tekintetében. A betanításhoz a teljes betanítási adatokon keresztül sok áthatlásra lehet szükség; minden egyes bérletet alapidőszaknak nevezünk.
Az alábbi táblázat felsorolja és ismerteti a TCNForecaster betanításának bemeneti beállításait és paramétereit:
| Betanítási bemenet | Description | Érték |
|---|---|---|
| Érvényesítési adatok | A betanításból kimaradt adatok egy része, amely a hálózat optimalizálását és az illesztés mérséklését irányítja. | A felhasználó által biztosított vagy automatikusan létrehozott betanítási adatok, ha nincsenek megadva. |
| Elsődleges metrika | Az egyes betanítási alapidőszakok végén az érvényesítési adatok medián-érték előrejelzéséből kiszámított metrika; a korai leállításhoz és a modell kiválasztásához használatos. | A felhasználó által választott; normalizált gyökér középérték négyzetes hiba vagy normalizált átlagos abszolút hiba. |
| Képzési alapidőszakok | A hálózati súly optimalizálásához futtatandó alapidőszakok maximális száma. | 100; az automatizált korai leállítási logika kisebb számú alapidőszakban megszakíthatja a betanítást. |
| Korai leállítási türelem | A betanítás leállítása előtt az elsődleges metrikafejlesztésre váró alapidőszakok száma. | 20 |
| Loss függvény | A hálózati súlyoptimalizálás célfüggvénye. | A kvantilis veszteség átlaga a 10., 25., 50., 75. és 90. percentilis-előrejelzés szerint. |
| Köteg mérete | Példák száma egy kötegben. Minden példában $n_{\text{input}} \times t_{\text{rf}}$ dimenziók vannak a bemenethez, és $h$ a kimenethez. | Automatikusan meghatározva a betanítási adatokban szereplő példák teljes száma alapján; maximális értéke 1024. |
| Beágyazási dimenziók | A beágyazási terek méretei kategorikus jellemzőkhöz. | Automatikusan állítsa be az egyes funkciókban található egyedi értékek számának negyedik gyökerét, felfelé kerekítve a legközelebbi egész számra. A küszöbértékeket legalább 3, a maximális érték pedig 100-at kell alkalmazni. |
| Hálózati architektúra* | A hálózat méretét és alakját szabályozó paraméterek: mélység, cellák száma és csatornák száma. | A modellkeresés határozza meg. |
| Hálózati súlyok | A jelkeverékeket, kategorikus beágyazásokat, konvolúciós kernelsúlyokat és az előrejelzési értékekhez való leképezéseket szabályozó paraméterek. | Véletlenszerűen inicializálva, majd optimalizálva a veszteségfüggvényre vonatkozóan. |
| Tanulási sebesség* | Azt szabályozza, hogy a hálózati súlyok mekkora mértékben állíthatók be a gradiens ereszkedés egyes iterációiban; dinamikusan csökkent a közel konvergencia. | A modellkeresés határozza meg. |
| Dropout ratio* | A hálózati súlyokra alkalmazott dropout regularization mértékét szabályozza. | A modellkeresés határozza meg. |
A csillaggal (*) jelölt bemeneteket a következő szakaszban ismertetett hiperparaméteres keresés határozza meg.
Modell keresése
Az AutoML modellkeresési módszerekkel keresi meg a következő hiperparaméterek értékeit:
- Hálózati mélység vagy konvolúciós blokkok száma,
- Cellák száma blokkonként,
- Csatornák száma az egyes rejtett rétegekben,
- Kiesési arány a hálózat rendszeresítéséhez,
- Tanulási sebesség.
Ezeknek a paramétereknek az optimális értékei jelentősen eltérhetnek a probléma forgatókönyvétől és a betanítási adatoktól függően, ezért az AutoML több különböző modellt képez be a hiperparaméter-értékek területén belül, és kiválasztja a legjobbat az érvényesítési adatok elsődleges metrikapontszáma alapján.
A modellkeresésnek két fázisa van:
- Az AutoML 12 "tájékozódási pont" modellben végez keresést. A tereptárgyak modelljei statikusak, és úgy vannak kiválasztva, hogy ésszerűen átterjedjenek a hiperparaméteres területre.
- Az AutoML véletlenszerű kereséssel folytatja a keresést a hiperparaméter-térben.
A keresés leáll, ha a leállítási feltételek teljesülnek. A leállítási feltételek az előrejelzés betanítási feladat konfigurációjától függenek, de néhány példa az időkorlátokra, a végrehajtandó keresési kísérletek számának korlátozására és a korai leállítási logikára, ha az érvényesítési metrika nem javul.
Következő lépések
Visszajelzés
Hamarosan elérhető: 2024-ben fokozatosan kivezetjük a GitHub-problémákat a tartalom visszajelzési mechanizmusaként, és lecseréljük egy új visszajelzési rendszerre. További információ: https://aka.ms/ContentUserFeedback.
Visszajelzés küldése és megtekintése a következőhöz: