Modellelsöprés és kiválasztás az autoML-ben történő előrejelzéshez
Ez a cikk arra összpontosít, hogy az AutoML hogyan keres és választ ki előrejelzési modelleket. Az AutoML előrejelzési módszertanával kapcsolatos általános információkért tekintse meg a metódusok áttekintését ismertető cikket . Az AutoML-betanítási előrejelzési modellek betanítására vonatkozó utasításokat és példákat az AutoML beállítása idősor-előrejelzési cikkünkben találja.
Modell takarítása
Az AutoML központi feladata több modell betanítása és kiértékelése, valamint az adott elsődleges metrika szempontjából a legjobb kiválasztása. Az itt szereplő "modell" szó a modellosztályra ( például ARIMA vagy Random Forest ) és az adott hiperparaméter-beállításokra is vonatkozik, amelyek megkülönböztetik az osztályon belüli modelleket. Az ARIMA például egy matematikai sablonnal és statisztikai feltételezésekkel rendelkező modellosztályra utal. Az ARIMA-modellek betanításához vagy illesztéséhez pozitív egész számok listája szükséges, amelyek meghatározzák a modell pontos matematikai formáját; Ezek a hiperparaméterek. Az ARIMA(1, 0, 1) és az ARIMA(2, 1, 2) osztálya azonos, de különböző hiperparaméterekkel rendelkezik, így külön illeszthetők a betanítási adatokhoz, és kiértékelhetők egymással. Az AutoML különböző modellosztályokon és osztályokon belül keres vagy végez takarítást különböző hiperparaméterekkel.
Az alábbi táblázat azOkat a hiperparaméteres takarítási módszereket mutatja be, amelyeket az AutoML a különböző modellosztályokhoz használ:
| Modellosztálycsoport | Modell típusa | Hiperparaméteres takarítási módszer |
|---|---|---|
| Naiv, szezonális naiv, átlag, szezonális átlag | idősorok | Nincs takarítás az osztályon belül a modell egyszerűsége miatt |
| Exponenciális simítás, ARIMA(X) | idősorok | Rácsos keresés osztályon belüli takarításhoz |
| Próféta | Regresszió | Nincs takarítás az osztályon belül |
| Lineáris SGD, LARS LASSO, Elastic Net, K legközelebbi szomszédok, Döntési fa, Véletlenszerű erdő, Rendkívül randomizált fák, Színátmenet fokozott fák, LightGBM, XGBoost | Regresszió | Az AutoML modellajánlási szolgáltatása dinamikusan vizsgálja a hiperparaméteres szóközöket |
| ElőrejelzésTCN | Regresszió | A modellek statikus listája, majd a hálózati méret, a legördülő lista és a tanulási arány véletlenszerű keresése. |
A különböző modelltípusok leírásáért tekintse meg a metódusok áttekintési cikkének előrejelzési modellekről szóló szakaszát.
Az AutoML által végzett takarítás mértéke az előrejelzési feladat konfigurációjától függ. Megadhatja a leállítási feltételeket időkorlátként, a kísérletek számának korlátjaként vagy a modellek számának megfelelőként. A korai leállítási logika mindkét esetben használható a takarítás leállításához, ha az elsődleges metrika nem javul.
A modell kiválasztása
Az AutoML-előrejelzési modell keresése és kiválasztása a következő három fázisban folytatódik:
- Az idősoros modellek átsöprése és az egyes osztályok legjobb modelljeinek kiválasztása büntetett valószínűségi módszerekkel.
- Ássa át a regressziós modelleket, és rangsorolja őket az 1. fázis legjobb idősorozat-modelljeivel együtt az érvényesítési készletekből származó elsődleges metrikaértékek alapján.
- A rangsorolt modellekből létrehozhat egy együttes modellt, kiszámíthatja az érvényesítési metrikát, és rangsorolhatja a többi modellel.
A 3. fázis végén a legmagasabb rangsorolt metrikaértékkel rendelkező modell lesz a legjobb modell.
Fontos
Az AutoML végső modellkiválasztási fázisa mindig kiszámítja a mintaadatok metrikáit . Vagyis olyan adatok, amelyeket nem használtak a modellekhez. Ez segít megvédeni a túlillesztés ellen.
Az AutoML két érvényesítési konfigurációval rendelkezik: keresztérvényesítési és explicit érvényesítési adatokkal. Keresztérvényesítés esetén az AutoML a bemeneti konfigurációt használja az adatok betanítási és érvényesítési redőkre való felosztásához. Az idősort meg kell őrizni ezekben a felosztásokban, ezért az AutoML úgynevezett gördülő eredetű keresztellenőrzést használ, amely betanítási és érvényesítési adatokra osztja az adatsort egy forrásidőpont használatával. A forrás időben történő csúsztatása generálja a keresztérvényesítési hajtásokat. Minden ellenőrzési hajtás a következő megfigyelési horizontot tartalmazza, közvetlenül az adott hajtás kiindulási helyét követően. Ez a stratégia megőrzi az idősor adatintegritását, és csökkenti az információszivárgás kockázatát.
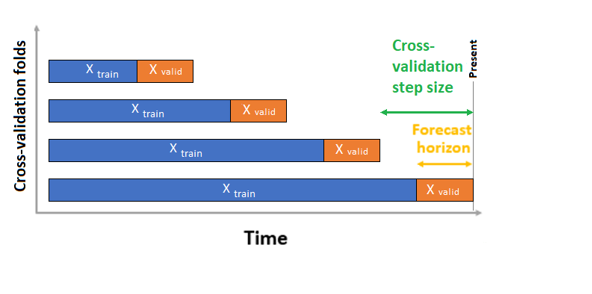
Az AutoML a szokásos keresztérvényesítési eljárást követi, minden hajtáson külön modellt tanít be, és az összes hajtás ellenőrzési metrikáinak átlagolását hajtja végre.
Az előrejelzési feladatok keresztérvényesítése a keresztérvényesítési hajtások számának beállításával és opcionálisan a két egymást követő keresztérvényesítési hajtás közötti időtartamok számának beállításával konfigurálható. További információért tekintse meg az egyéni keresztérvényesítési beállítások útmutatóját, valamint egy példát a keresztérvényesítés előrejelzéshez való konfigurálására.
Saját érvényesítési adatokat is használhat. További információ: Adatmegosztások és keresztérvényesítés konfigurálása az AutoML (SDK v1) szolgáltatásban .
Következő lépések
- További információ az AutoML beállításáról egy idősorozat-előrejelzési modell betanításához.
- Az AutoML-előrejelzéssel kapcsolatos gyakori kérdések tallózása.
- Tudnivalók az autoML idősor-előrejelzési naptárfunkcióiról.
- Ismerje meg , hogyan használja az AutoML a gépi tanulást az előrejelzési modellek létrehozásához.
Visszajelzés
Hamarosan elérhető: 2024-ben fokozatosan kivezetjük a GitHub-problémákat a tartalom visszajelzési mechanizmusaként, és lecseréljük egy új visszajelzési rendszerre. További információ: https://aka.ms/ContentUserFeedback.
Visszajelzés küldése és megtekintése a következőhöz: