Mély tanulás és gépi tanulás az Azure Machine Learningben
Ez a cikk ismerteti a mély tanulást és a gépi tanulást, valamint azt, hogy ezek hogyan illeszkednek a mesterséges intelligencia szélesebb kategóriájába. Megismerheti az Azure Machine Learningre épülő mélytanulási megoldásokat, például a csalások észlelését, a hang- és arcfelismerést, a hangulatelemzést és az idősor-előrejelzést.
A megoldásokhoz tartozó algoritmusok kiválasztásával kapcsolatos útmutatásért tekintse meg a Machine Learning-algoritmusok csalólapját.
Az Azure Machine Learning alapmodelljei előre betanított mélytanulási modellek, amelyek finomhangolhatók adott használati esetekhez. További információ az Alapmodellekről (előzetes verzió) az Azure Machine Learningben, valamint az Alapmodellek használata az Azure Machine Learningben (előzetes verzió).
Mély tanulás, gépi tanulás és AI
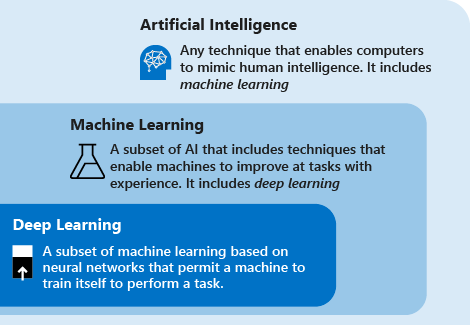
A mély tanulás és a gépi tanulás és az AI megértéséhez vegye figyelembe az alábbi definíciókat:
A mély tanulás a mesterséges neurális hálózatokon alapuló gépi tanulás egy részhalmaza. A tanulási folyamat mély, mert a mesterséges neurális hálózatok struktúrája több bemenetből, kimenetből és rejtett rétegekből áll. Mindegyik réteg egységekből épül fel, amelyek a bemenetet olyan információvá alakítják át, amelyet a következő réteg egy adott prediktív feladat elvégzéséhez fel tud használni. Ennek a struktúrának köszönhetően a gép saját adatfeldolgozással tanulhat.
A gépi tanulás a mesterséges intelligencia olyan részhalmaza, amely olyan technikákat (például mély tanulást) használ, amelyek lehetővé teszik, hogy a gépek tapasztalatot használjanak a feladatok javítására. A tanulási folyamat a következő lépéseken alapul:
- Adatok becsatornázása algoritmusba. (Ebben a lépésben további információkat adhat meg a modellnek, például a funkciók kinyerésével.)
- Ez az adat egy modell betanítása.
- Tesztelje és telepítse a modellt.
- Használja az üzembe helyezett modellt egy automatizált prediktív feladat végrehajtásához. (Más szóval hívja meg és használja az üzembe helyezett modellt a modell által visszaadott előrejelzések fogadásához.)
A mesterséges intelligencia (AI) egy olyan technika, amely lehetővé teszi a számítógépek számára az emberi intelligencia utánzását. A gépi tanulást is magában foglalja.
A Generatív AI a mesterséges intelligencia azon részhalmaza, amely technikákat (például mély tanulást) használ új tartalmak létrehozásához. A generatív mesterséges intelligenciával például képeket, szöveget vagy hangot hozhat létre. Ezek a modellek nagy előre betanított ismereteket használnak a tartalom létrehozásához.
Gépi tanulással és mélytanulási technikákkal olyan számítógépes rendszereket és alkalmazásokat hozhat létre, amelyek olyan feladatokat végeznek, amelyek gyakran kapcsolódnak az emberi intelligenciához. Ezek a feladatok közé tartozik a képfelismerés, a beszédfelismerés és a nyelvi fordítás.
A mélytanulás és a gépi tanulás technikái
Most, hogy áttekintette a gépi tanulást és a mély tanulást, hasonlítsuk össze a két technikát. A gépi tanulásban az algoritmusnak el kell mondania, hogyan készíthet pontos előrejelzést további információk felhasználásával (például funkciókinyeréssel). A mély tanulás során az algoritmus megtanulhatja, hogyan készíthet pontos előrejelzést saját adatfeldolgozásával, a mesterséges neurális hálózati struktúra révén.
Az alábbi táblázat részletesebben hasonlítja össze a két technikát:
| Minden gépi tanulás | Csak mély tanulás | |
|---|---|---|
| Adatpontok száma | Kis mennyiségű adatot használhat előrejelzések készítéséhez. | Nagy mennyiségű betanítási adatot kell használnia az előrejelzések létrehozásához. |
| Hardverfüggőségek | Alacsony szintű gépeken is használható. Nincs szükség nagy számítási teljesítményre. | A csúcskategóriás gépektől függ. Nagy számú mátrix-szorzási műveletet hajt végre. A GPU hatékonyan optimalizálhatja ezeket a műveleteket. |
| Featurizálási folyamat | A funkciók pontos azonosítását és létrehozását igényli a felhasználók számára. | Megtanulja a magas szintű funkciókat az adatokból, és önállóan hoz létre új funkciókat. |
| Tanulási megközelítés | A tanulási folyamatot kisebb lépésekre osztja. Ezután egyesíti az egyes lépések eredményeit egy kimenetben. | Végighalad a tanulási folyamaton a probléma végpontok közötti megoldásával. |
| Végrehajtási idő | Viszonylag kevés időt vesz igénybe a betanítása, néhány másodperctől néhány óráig. | A betanítása általában hosszú időt vesz igénybe, mivel egy mélytanulási algoritmus több réteget is magában foglal. |
| Hozam | A kimenet általában numerikus érték, például pontszám vagy besorolás. | A kimenet több formátumot is tartalmazhat, például szöveget, pontszámot vagy hangot. |
Mi az a tudásátadás?
A mélytanulási modellek betanítása gyakran nagy mennyiségű betanítási adatot, csúcskategóriás számítási erőforrásokat (GPU, TPU) és hosszabb betanítási időt igényel. Olyan helyzetekben, amikor ezek közül egyik sem érhető el, a betanítási folyamatot a transzfertanulásnak nevezett technikával gyorsítheti.
A tanulás átadása olyan technika, amely az egyik probléma megoldásából nyert tudást egy másik, de kapcsolódó problémára alkalmazza.
A neurális hálózatok struktúrája miatt az első rétegcsoport általában alacsonyabb szintű szolgáltatásokat tartalmaz, míg a végső rétegcsoport olyan magasabb szintű szolgáltatásokat tartalmaz, amelyek közelebb állnak a szóban forgó tartományhoz. Az új tartományban vagy problémában való használatra szánt végső rétegek újbóli felhasználásával jelentősen csökkentheti az új modell betanításához szükséges időt, adatokat és számítási erőforrásokat. Ha például már rendelkezik olyan modellel, amely felismeri az autókat, a transzfertanítással újra felhasználhatja ezt a modellt a teherautók, motorkerékpárok és más típusú járművek felismeréséhez.
Megtudhatja, hogyan alkalmazhat átviteli tanulást képbesoroláshoz nyílt forráskódú keretrendszer használatával az Azure Machine Learningben: Mélytanulási PyTorch-modell betanítása átviteltanítással.
Mélytanulási használati esetek
A mesterséges neurális hálózati struktúra miatt a mély tanulás kiválóan alkalmas a strukturálatlan adatok, például képek, hangok, videók és szövegek mintáinak azonosítására. Ezért a mély tanulás gyorsan átalakít számos iparágat, köztük az egészségügyet, az energiát, a pénzügyet és a közlekedést. Ezek az iparágak most újragondolják a hagyományos üzleti folyamatokat.
A mélytanulás néhány leggyakoribb alkalmazását az alábbi bekezdések ismertetik. Az Azure Machine Learningben használhat egy nyílt forráskódú keretrendszerből létrehozott modellt, vagy létrehozhatja a modellt a megadott eszközökkel.
Elnevezett entitás felismerése
Az elnevezett entitások felismerése egy olyan mélytanulási módszer, amely bemenetként egy szövegrészt vesz igénybe, és egy előre megadott osztályba alakítja át. Ez az új információ lehet irányítószám, dátum, termékazonosító. Az információk ezután egy strukturált sémában tárolhatók a címek listájának létrehozásához, vagy egy identitásérvényesítési motor viszonyítási alapjaként.
Objektumészlelés
A mély tanulást számos objektumészlelési használati esetben alkalmazták. Az objektumészlelés a képeken lévő objektumok (például autók vagy személyek) azonosítására szolgál, és adott helyet biztosít minden objektumnak egy határolókerettel.
Az objektumészlelést már használják olyan iparágakban, mint a játék, a kiskereskedelem, a turizmus és az önvezető autók.
Képfelirat létrehozása
A képfelismeréshez hasonlóan egy adott kép feliratozásához a rendszernek létre kell hoznia egy feliratot, amely leírja a kép tartalmát. Ha képes észlelni és címkézni az objektumokat a fényképeken, a következő lépés a címkék leíró mondattá alakítása.
A képfeliratozási alkalmazások általában konvolúciós neurális hálózatokat használnak a képek objektumainak azonosítására, majd egy ismétlődő neurális hálózat használatával konzisztens mondatokká alakítják a címkéket.
Gépi fordítás
A gépi fordítás szavakat vagy mondatokat használ egy nyelvről, és automatikusan lefordítja őket egy másik nyelvre. A gépi fordítás már régóta elérhető, de a mély tanulás két konkrét területen is lenyűgöző eredményeket ér el: a szöveg automatikus fordítását (és a beszéd szöveggé fordítását) és a képek automatikus fordítását.
A megfelelő adatátalakítással a neurális hálózat képes megérteni a szöveg, a hang és a vizuális jeleket. A gépi fordítással azonosíthatók a hangrészletek nagyobb hangfájlokban, és átírhatók a beszélt szó vagy kép szövegként.
Szövegelemzés
A mélytanulási módszereken alapuló szövegelemzés magában foglalja a nagy mennyiségű szöveges adat (például orvosi dokumentumok vagy költségbevételek) elemzését, a minták felismerését, valamint a rendszerezett és tömör információk létrehozását.
A vállalatok mély tanulással végeznek szövegelemzést a bennfentes kereskedelem és a kormányzati előírásoknak való megfelelés észleléséhez. Egy másik gyakori példa a biztosítási csalás: a szövegelemzést gyakran használták nagy mennyiségű dokumentum elemzésére, hogy felismerjék a biztosítási jogcímek csalásának esélyét.
Mesterséges neurális hálózatok
A mesterséges neurális hálózatokat csatlakoztatott csomópontok rétegei alkotják. A mélytanulási modellek nagy számú réteggel rendelkező neurális hálózatokat használnak.
Az alábbi szakaszok a legnépszerűbb mesterséges neurális hálózati topológiákat ismertetik.
Feedforward neurális hálózat
A feedforward neurális hálózat a mesterséges neurális hálózat legegyszerűbb típusa. A feedforward hálózaton az információk csak egy irányba mozognak a bemeneti rétegről a kimeneti rétegre. A feedforward neurális hálózatok rejtett rétegek sorozatán keresztül alakítják át a bemeneteket. Minden réteg neuronokból áll, és minden réteg teljes mértékben kapcsolódik a rétegben lévő összes neuronhoz. Az utolsó teljesen csatlakoztatott réteg (a kimeneti réteg) a generált előrejelzéseket jelöli.
Visszacsatolt neurális hálózat (RNN)
Az ismétlődő neurális hálózatok széles körben használt mesterséges neurális hálózatok. Ezek a hálózatok mentik egy réteg kimenetét, és visszatáplálást a bemeneti rétegbe a réteg eredményének előrejelzéséhez. Az ismétlődő neurális hálózatok kiváló tanulási képességekkel rendelkeznek. Ezeket széles körben használják olyan összetett feladatokhoz, mint az idősorok előrejelzése, a kézírás tanulása és a nyelv felismerése.
Konvolúciós neurális hálózat (CNN)
A konvolúciós neurális hálózat egy különösen hatékony mesterséges neurális hálózat, és egyedi architektúrát mutat be. A rétegek három dimenzióban vannak rendszerezve: szélesség, magasság és mélység. Az egyik réteg neuronjai nem a következő rétegben lévő összes neuronhoz csatlakoznak, hanem csak a réteg neuronjainak egy kis régiójához. A végső kimenet a valószínűségi pontszámok egyetlen vektorára csökken, a mélységi dimenzió mentén rendezve.
A konvolúciós neurális hálózatokat olyan területeken használták, mint a videofelismerés, a képfelismerés és az ajánlórendszerek.
Generatív kontradiktórius hálózat (GAN)
A generatív adversarial-hálózatok olyan generatív modellek, amelyek a valósághű tartalmak, például képek létrehozására vannak betanítve. Ez két hálózatból áll, úgynevezett generátorból és diszkriminatívból. Mindkét hálózat be van tanítva egyszerre. A betanítás során a generátor véletlenszerű zajt használ a valós adatokhoz szorosan hasonlító új szintetikus adatok létrehozásához. A diszkriminatív a generátor kimenetét veszi bemenetként, és valós adatokkal állapítja meg, hogy a létrehozott tartalom valós vagy szintetikus-e. Minden hálózat verseng egymással. A generátor olyan szintetikus tartalmat próbál létrehozni, amely megkülönböztethetetlen a valós tartalomtól, és a diszkriminatív megpróbálja helyesen besorolni a bemeneteket valós vagy szintetikusként. A kimenet ezután a két hálózat súlyának frissítésére szolgál, hogy jobban elérjék a céljukat.
A generatív támadó hálózatok olyan problémák megoldására szolgálnak, mint a képek fordítása és az életkor előrehaladtával.
Transzformátorok
A transzformátorok olyan modellarchitektúrák, amelyek olyan sorozatokat tartalmazó problémák megoldására alkalmasak, mint a szöveg- vagy idősoradatok. Kódoló- és dekóderrétegekből állnak. A kódoló egy bemenetet használ, és egy olyan numerikus ábrázolásba képezi le, amely olyan információkat tartalmaz, mint a környezet. A dekódoló a kódolótól származó információkat használva kimenetet hoz létre, például lefordított szöveget. A kódolókat és dekódereket tartalmazó más architektúráktól eltérő transzformátorok a figyelem alrétegei. A figyelem az a gondolat, hogy egy bemenet adott részeire összpontosítsunk a kontextusuk fontossága alapján a sorozat más bemeneteihez képest. Egy hírcikk összegzésekor például nem minden mondat releváns a fő gondolat leírásához. A cikk kulcsszavaira összpontosítva az összegzés egyetlen mondatban, a címsorban végezhető el.
A transzformátorok olyan természetes nyelvi feldolgozási problémák megoldására szolgálnak, mint a fordítás, a szöveggenerálás, a kérdések megválaszolása és a szövegösszesítés.
A transzformátorok néhány jól ismert implementációja a következők:
- Kétirányú kódoló-reprezentációk transzformátorokból (BERT)
- Generatív előre betanított transzformátor 2 (GPT-2)
- Generatív előre betanított transzformátor 3 (GPT-3)
Következő lépések
Az alábbi cikkek további lehetőségeket mutatnak be a nyílt forráskódú mélytanulási modellek Azure Machine Learningben való használatára: