A Python értelmezhetőségi csomagjának használata az ML-modellek és -előrejelzések magyarázatához (előzetes verzió)
ÉRVÉNYES: Python SDK azureml v1
Python SDK azureml v1
Ebben az útmutatóban megismerheti az Azure Machine Tanulás Python SDK értelmezhetőségi csomagját a következő feladatok végrehajtásához:
Ismertesse a modell teljes viselkedését vagy egyéni előrejelzéseit helyileg a személyes gépen.
Értelmezhetőségi technikák engedélyezése a megtervezett funkciókhoz.
Az Azure-beli teljes modell és egyéni előrejelzések viselkedésének ismertetése.
Magyarázatok feltöltése az Azure Machine Tanulás futtatási előzményekbe.
Vizualizációs irányítópult használatával kezelheti a modell magyarázatait a Jupyter Notebookban és az Azure Machine Tanulás studióban is.
Helyezzen üzembe egy pontozó magyarázót a modell mellett, hogy megfigyelje a magyarázatokat a következtetés során.
Fontos
Ez a funkció jelenleg nyilvános előzetes verzióban érhető el. Ez az előzetes verzió szolgáltatásszintű szerződés nélkül érhető el, és éles számítási feladatokhoz nem javasoljuk. Előfordulhat, hogy néhány funkció nem támogatott, vagy korlátozott képességekkel rendelkezik.
For more information, see Supplemental Terms of Use for Microsoft Azure Previews.
A támogatott értelmezhetőségi technikákról és gépi tanulási modellekről további információt az Azure Machine Tanulás és mintajegyzetfüzetekben található modellértelmezhetőség című témakörben talál.
Az automatizált gépi tanulással betanított modellek értelmezhetőségének engedélyezésével kapcsolatos útmutatásért lásd : Értelmezhetőség: modellmagyarázatok automatizált gépi tanulási modellekhez (előzetes verzió).
Funkció fontossági értékének létrehozása a személyes gépen
Az alábbi példa bemutatja, hogyan használhatja az értelmező csomagot a személyes gépén anélkül, hogy kapcsolatba lép az Azure-szolgáltatásokkal.
Telepítse az
azureml-interpretcsomagot.pip install azureml-interpretMintamodell betanítása egy helyi Jupyter Notebookban.
# load breast cancer dataset, a well-known small dataset that comes with scikit-learn from sklearn.datasets import load_breast_cancer from sklearn import svm from sklearn.model_selection import train_test_split breast_cancer_data = load_breast_cancer() classes = breast_cancer_data.target_names.tolist() # split data into train and test from sklearn.model_selection import train_test_split x_train, x_test, y_train, y_test = train_test_split(breast_cancer_data.data, breast_cancer_data.target, test_size=0.2, random_state=0) clf = svm.SVC(gamma=0.001, C=100., probability=True) model = clf.fit(x_train, y_train)Hívja meg helyileg a magyarázót.
- Egy magyarázó objektum inicializálásához adja át a modellt és néhány betanítási adatot a magyarázó konstruktorának.
- A magyarázatok és vizualizációk informatívabbá tétele érdekében választhatja, hogy besorolás esetén átadja a funkcióneveket és a kimeneti osztályneveket.
Az alábbi kódblokkok bemutatják, hogyan lehet egy magyarázó objektumot példányosítani a következővel
TabularExplainer: ,MimicExplainerésPFIExplainerhelyileg.TabularExplainera három SHAP-magyarázó egyikét hívja meg alatta (TreeExplainervagyDeepExplainerKernelExplainer).TabularExplainerautomatikusan kiválasztja a legmegfelelőbbet a használati esethez, de a három mögöttes magyarázó mindegyiket közvetlenül is meghívhatja.
from interpret.ext.blackbox import TabularExplainer # "features" and "classes" fields are optional explainer = TabularExplainer(model, x_train, features=breast_cancer_data.feature_names, classes=classes)vagy
from interpret.ext.blackbox import MimicExplainer # you can use one of the following four interpretable models as a global surrogate to the black box model from interpret.ext.glassbox import LGBMExplainableModel from interpret.ext.glassbox import LinearExplainableModel from interpret.ext.glassbox import SGDExplainableModel from interpret.ext.glassbox import DecisionTreeExplainableModel # "features" and "classes" fields are optional # augment_data is optional and if true, oversamples the initialization examples to improve surrogate model accuracy to fit original model. Useful for high-dimensional data where the number of rows is less than the number of columns. # max_num_of_augmentations is optional and defines max number of times we can increase the input data size. # LGBMExplainableModel can be replaced with LinearExplainableModel, SGDExplainableModel, or DecisionTreeExplainableModel explainer = MimicExplainer(model, x_train, LGBMExplainableModel, augment_data=True, max_num_of_augmentations=10, features=breast_cancer_data.feature_names, classes=classes)vagy
from interpret.ext.blackbox import PFIExplainer # "features" and "classes" fields are optional explainer = PFIExplainer(model, features=breast_cancer_data.feature_names, classes=classes)
A modell teljes viselkedésének ismertetése (globális magyarázat)
Az összesítő (globális) funkció fontossági értékeinek lekéréséhez tekintse meg az alábbi példát.
# you can use the training data or the test data here, but test data would allow you to use Explanation Exploration
global_explanation = explainer.explain_global(x_test)
# if you used the PFIExplainer in the previous step, use the next line of code instead
# global_explanation = explainer.explain_global(x_train, true_labels=y_train)
# sorted feature importance values and feature names
sorted_global_importance_values = global_explanation.get_ranked_global_values()
sorted_global_importance_names = global_explanation.get_ranked_global_names()
dict(zip(sorted_global_importance_names, sorted_global_importance_values))
# alternatively, you can print out a dictionary that holds the top K feature names and values
global_explanation.get_feature_importance_dict()
Egyéni előrejelzés ismertetése (helyi magyarázat)
A különböző adatpontok egyedi fontossági értékeinek lekérése egy adott példány vagy példánycsoport magyarázatának meghívásával.
Megjegyzés:
PFIExplainer nem támogatja a helyi magyarázatokat.
# get explanation for the first data point in the test set
local_explanation = explainer.explain_local(x_test[0:5])
# sorted feature importance values and feature names
sorted_local_importance_names = local_explanation.get_ranked_local_names()
sorted_local_importance_values = local_explanation.get_ranked_local_values()
Nyers funkcióátalakítások
Dönthet úgy, hogy a nyers, nem lefordított funkciókkal kapcsolatos magyarázatokat választja ahelyett, hogy megtervezett funkciókat szeretne. Ebben a beállításban átadja a funkcióátalakítási folyamatot a magyarázónak a következőben train_explain.py: . Ellenkező esetben a magyarázó a mérnöki funkciókkal kapcsolatos magyarázatokat nyújt.
A támogatott átalakítások formátuma megegyezik a sklearn-pandasban leírtakéval. Általánosságban elmondható, hogy az átalakítások mindaddig támogatottak, amíg egyetlen oszlopon működnek, így egyértelmű, hogy egy-a-többhöz.
A nyers funkciók magyarázatához használja a sklearn.compose.ColumnTransformer beépített transzformátor-csuplok listáját. Az alábbi példa a következőt használja sklearn.compose.ColumnTransformer:
from sklearn.compose import ColumnTransformer
numeric_transformer = Pipeline(steps=[
('imputer', SimpleImputer(strategy='median')),
('scaler', StandardScaler())])
categorical_transformer = Pipeline(steps=[
('imputer', SimpleImputer(strategy='constant', fill_value='missing')),
('onehot', OneHotEncoder(handle_unknown='ignore'))])
preprocessor = ColumnTransformer(
transformers=[
('num', numeric_transformer, numeric_features),
('cat', categorical_transformer, categorical_features)])
# append classifier to preprocessing pipeline.
# now we have a full prediction pipeline.
clf = Pipeline(steps=[('preprocessor', preprocessor),
('classifier', LogisticRegression(solver='lbfgs'))])
# clf.steps[-1][1] returns the trained classification model
# pass transformation as an input to create the explanation object
# "features" and "classes" fields are optional
tabular_explainer = TabularExplainer(clf.steps[-1][1],
initialization_examples=x_train,
features=dataset_feature_names,
classes=dataset_classes,
transformations=preprocessor)
Ha a példát a beépített transzformátor-csuplok listájával szeretné futtatni, használja a következő kódot:
from sklearn.pipeline import Pipeline
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import StandardScaler, OneHotEncoder
from sklearn.linear_model import LogisticRegression
from sklearn_pandas import DataFrameMapper
# assume that we have created two arrays, numerical and categorical, which holds the numerical and categorical feature names
numeric_transformations = [([f], Pipeline(steps=[('imputer', SimpleImputer(
strategy='median')), ('scaler', StandardScaler())])) for f in numerical]
categorical_transformations = [([f], OneHotEncoder(
handle_unknown='ignore', sparse=False)) for f in categorical]
transformations = numeric_transformations + categorical_transformations
# append model to preprocessing pipeline.
# now we have a full prediction pipeline.
clf = Pipeline(steps=[('preprocessor', DataFrameMapper(transformations)),
('classifier', LogisticRegression(solver='lbfgs'))])
# clf.steps[-1][1] returns the trained classification model
# pass transformation as an input to create the explanation object
# "features" and "classes" fields are optional
tabular_explainer = TabularExplainer(clf.steps[-1][1],
initialization_examples=x_train,
features=dataset_feature_names,
classes=dataset_classes,
transformations=transformations)
Funkció fontossági értékeinek létrehozása távoli futtatásokon keresztül
Az alábbi példa bemutatja, hogyan használhatja az osztályt a ExplanationClient modell értelmezhetőségének távoli futtatásokhoz való engedélyezéséhez. Ez fogalmilag hasonló a helyi folyamathoz, kivéve a következőket:
ExplanationClientA távoli futtatáskor használja az értelmező környezet feltöltését.- Töltse le később a környezetet egy helyi környezetben.
Telepítse az
azureml-interpretcsomagot.pip install azureml-interpretHozzon létre egy betanítási szkriptet egy helyi Jupyter Notebookban. For example,
train_explain.py.from azureml.interpret import ExplanationClient from azureml.core.run import Run from interpret.ext.blackbox import TabularExplainer run = Run.get_context() client = ExplanationClient.from_run(run) # write code to get and split your data into train and test sets here # write code to train your model here # explain predictions on your local machine # "features" and "classes" fields are optional explainer = TabularExplainer(model, x_train, features=feature_names, classes=classes) # explain overall model predictions (global explanation) global_explanation = explainer.explain_global(x_test) # uploading global model explanation data for storage or visualization in webUX # the explanation can then be downloaded on any compute # multiple explanations can be uploaded client.upload_model_explanation(global_explanation, comment='global explanation: all features') # or you can only upload the explanation object with the top k feature info #client.upload_model_explanation(global_explanation, top_k=2, comment='global explanation: Only top 2 features')Állítson be egy Azure Machine Tanulás Compute-t számítási célként, és küldje el a betanítási futtatásokat. Útmutatásért tekintse meg az Azure Machine Tanulás számítási fürtök létrehozását és kezelését. A példajegyzetfüzetek is hasznosak lehetnek.
Töltse le a magyarázatot a helyi Jupyter Notebookban.
from azureml.interpret import ExplanationClient client = ExplanationClient.from_run(run) # get model explanation data explanation = client.download_model_explanation() # or only get the top k (e.g., 4) most important features with their importance values explanation = client.download_model_explanation(top_k=4) global_importance_values = explanation.get_ranked_global_values() global_importance_names = explanation.get_ranked_global_names() print('global importance values: {}'.format(global_importance_values)) print('global importance names: {}'.format(global_importance_names))
Vizualizációk
Miután letöltötte a magyarázatokat a helyi Jupyter Notebookban, a magyarázó irányítópulton lévő vizualizációkkal megértheti és értelmezheti a modellt. A Magyarázatok irányítópult widget jupyter notebookba való betöltéséhez használja a következő kódot:
from raiwidgets import ExplanationDashboard
ExplanationDashboard(global_explanation, model, datasetX=x_test)
A vizualizációk mind a megtervezett, mind a nyers funkciók magyarázatát támogatják. A nyers magyarázatok az eredeti adatkészlet funkcióin alapulnak, a megtervezett magyarázatok pedig az adathalmaz funkcióin alapulnak, és a funkciótervezést alkalmazzák.
Amikor megpróbál értelmezni egy modellt az eredeti adatkészlettel kapcsolatban, ajánlott nyers magyarázatokat használni, mivel minden funkció fontossága megfelel az eredeti adatkészlet egy oszlopának. Az egyik olyan forgatókönyv, amikor a megtervezett magyarázatok hasznosak lehetnek, ha egy kategorikus funkció egyes kategóriáinak hatását vizsgálják. Ha egy kategorikus funkcióra alkalmazunk egy egyszeri kódolást, akkor az eredményül kapott magyarázatok kategóriánként eltérő fontossági értéket tartalmaznak, egy pedig egy gyakori elérésű, beépített funkcióként. Ez a kódolás akkor lehet hasznos, ha szűkíti az adathalmaz azon részét, amely a leginkább informatív a modell számára.
Megjegyzés:
A megtervezett és nyers magyarázatok egymás után lesznek kiszámítva. Először a modell és a featurizációs folyamat alapján jön létre egy mérnökalapú magyarázat. Ezután a nyers magyarázat ezen a mérnöki magyarázaton alapul az ugyanazon nyers jellemzőből származó mérnöki funkciók fontosságának összesítésével.
Adathalmaz-kohorszok létrehozása, szerkesztése és megtekintése
A felső menüszalagon a modell és az adatok általános statisztikái láthatók. Az adatokat adathalmaz-kohorszokba vagy alcsoportokba szeletelheti és szeletelheti, hogy megvizsgálhassa vagy összehasonlíthassa a modell teljesítményét és magyarázatait ezen definiált alcsoportokban. Az adathalmaz statisztikáinak és magyarázatainak az alcsoportok közötti összehasonlításával képet kaphat arról, hogy miért fordulnak elő lehetséges hibák az egyik csoportban a másikkal szemben.

A modell teljes viselkedésének ismertetése (globális magyarázat)
A magyarázó irányítópult első három lapja átfogó elemzést nyújt a betanított modellről az előrejelzések és magyarázatok mellett.
A modell teljesítménye
Értékelje ki a modell teljesítményét az előrejelzési értékek eloszlásának és a modell teljesítménymetrikáinak eloszlásával. A modell további vizsgálatához tekintse meg a teljesítmény összehasonlító elemzését az adathalmaz különböző kohorszaiban vagy alcsoportjaiban. Az y és az x érték mentén válassza ki a szűrőket a különböző dimenziók közötti vágáshoz. Megtekintheti az olyan metrikákat, mint a pontosság, a pontosság, a visszahívás, a hamis pozitív ráta (FPR) és a hamis negatív ráta (FNR).

Adathalmaz-kezelő
Az adathalmaz statisztikáinak megismeréséhez válasszon ki különböző szűrőket az X, az Y és a színtengelyek mentén, hogy különböző dimenziók mentén szeletelje az adatokat. A fenti adathalmaz-kohorszok létrehozásával elemezheti az adathalmaz-statisztikákat olyan szűrőkkel, mint az előrejelzett eredmény, az adathalmaz funkciói és a hibacsoportok. A gráf jobb felső sarkában található fogaskerék ikonnal módosíthatja a gráftípusokat.

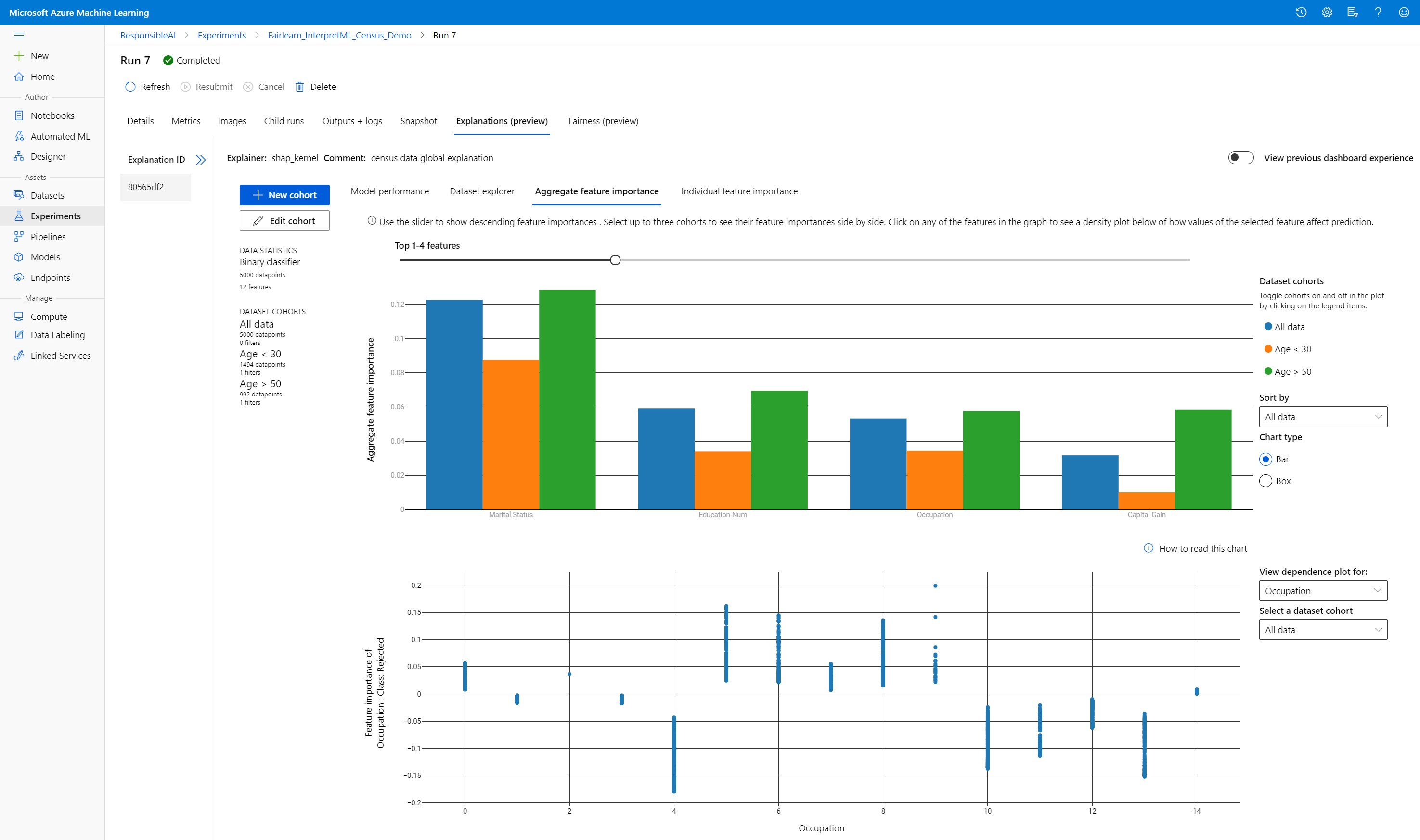
A funkció fontosságának összesítése
Ismerje meg azokat a legfontosabb funkciókat, amelyek hatással vannak az általános modell-előrejelzésekre (más néven globális magyarázat). A csúszkával csökkenő funkció-fontossági értékeket jeleníthet meg. Legfeljebb három kohorsz közül választhat, ha egymás mellett szeretné látni a funkció fontossági értékeit. A gráf bármelyik funkciósávját kiválasztva megtekintheti, hogy a kiválasztott funkcióhatással kapcsolatos modell előrejelzésének értékei az alábbi függőségi diagramon hogyan befolyásolják a modell előrejelzését.

Az egyes előrejelzések ismertetése (helyi magyarázat)
A magyarázat lap negyedik lapja lehetővé teszi az egyes adatpontok és azok egyes funkcióinak fontosságát. Bármely adatponthoz betöltheti az egyes funkciók fontossági diagramját, ha a fő pontdiagramon az egyes adatpontok valamelyikére kattint, vagy kiválaszt egy adott adatpontot a jobb oldali panelvarázslóban.
| Rajzolás | Leírás |
|---|---|
| Az egyéni funkciók fontossága | Az egyes előrejelzések legfontosabb funkcióit jeleníti meg. Segít az alapul szolgáló modell helyi viselkedésének szemléltetésében egy adott adatponton. |
| Lehetőségelemzés | Lehetővé teszi a kiválasztott valós adatpont funkcióértékeinek módosítását, és megfigyelheti az előrejelzési érték változásait azáltal, hogy hipotetikus adatpontot hoz létre az új funkcióértékekkel. |
| Egyéni feltételes várakozás (ICE) | Lehetővé teszi a funkcióértékek minimális értékről maximális értékre történő módosítását. Segít bemutatja, hogyan változik az adatpont előrejelzése egy funkció módosításakor. |

Megjegyzés:
Ezek számos közelítésen alapuló magyarázatok, és nem az előrejelzések "oka". Az ok-okozati következtetés szigorú matematikai megbízhatósága nélkül nem javasoljuk a felhasználóknak, hogy valós döntéseket hozzanak a What-If eszköz funkcióinak zavarai alapján. Ez az eszköz elsősorban a modell megértésére és a hibakeresésre használható.
Vizualizáció az Azure Machine Tanulás Studióban
Ha végrehajtja a távoli értelmezhetőségi lépéseket (a létrehozott magyarázatokat feltölti az Azure Machine-Tanulás futtatási előzményekbe), megtekintheti a vizualizációkat az Azure Machine Tanulás Studio magyarázó irányítópultján. Ez az irányítópult az irányítópult widget egyszerűbb verziója, amely a Jupyter Notebookban jön létre. A What-If datapoint- és ICE-diagramok le vannak tiltva, mivel az Azure Machine Tanulás studióban nincs olyan aktív számítás, amely valós idejű számításokat hajthat végre.
Ha az adathalmaz, a globális és a helyi magyarázatok elérhetők, az adatok feltöltik az összes lapot. Ha azonban csak egy globális magyarázat érhető el, az Egyéni funkció fontossága lap le lesz tiltva.
Kövesse az alábbi útvonalak egyikét az Azure Machine Tanulás Studióban található magyarázó irányítópult eléréséhez:
Kísérletek panel (előzetes verzió)
- A bal oldali panelEn válassza a Kísérletek lehetőséget az Azure Machine-Tanulás futtatott kísérletek listájának megtekintéséhez.
- Válasszon ki egy adott kísérletet a kísérlet összes futtatásának megtekintéséhez.
- Jelöljön ki egy futtatási lehetőséget, majd a Magyarázatok lapot a magyarázó vizualizáció irányítópultjához.
Modellek panel
- Ha az eredeti modellt az Azure Machine Tanulás modellek üzembe helyezésének lépéseit követve regisztrálta, a bal oldali panelEn a Modellek lehetőséget választva megtekintheti.
- Válasszon ki egy modellt, majd a Magyarázatok lapra a magyarázatok irányítópultjának megtekintéséhez.

Értelmezhetőség következtetési időpontban
Az eredeti modellel együtt üzembe helyezheti a magyarázót, és következtetési időpontban használhatja, hogy minden új adatponthoz megadja az egyes jellemzők fontossági értékeit (helyi magyarázat). Könnyebb pontozási magyarázókat is kínálunk az értelmezhetőségi teljesítmény következtetési időben történő javításához, amely jelenleg csak az Azure Machine Tanulás SDK-ban támogatott. A könnyebb súlyozású pontozási magyarázó üzembe helyezésének folyamata hasonló a modell üzembe helyezéséhez, és a következő lépéseket tartalmazza:
Hozzon létre egy magyarázó objektumot. Használhatja például a következőt
TabularExplainer:from interpret.ext.blackbox import TabularExplainer explainer = TabularExplainer(model, initialization_examples=x_train, features=dataset_feature_names, classes=dataset_classes, transformations=transformations)Hozzon létre egy pontozó magyarázót a magyarázó objektummal.
from azureml.interpret.scoring.scoring_explainer import KernelScoringExplainer, save # create a lightweight explainer at scoring time scoring_explainer = KernelScoringExplainer(explainer) # pickle scoring explainer # pickle scoring explainer locally OUTPUT_DIR = 'my_directory' save(scoring_explainer, directory=OUTPUT_DIR, exist_ok=True)A pontozási magyarázó modellt használó rendszerkép konfigurálása és regisztrálása.
# register explainer model using the path from ScoringExplainer.save - could be done on remote compute # scoring_explainer.pkl is the filename on disk, while my_scoring_explainer.pkl will be the filename in cloud storage run.upload_file('my_scoring_explainer.pkl', os.path.join(OUTPUT_DIR, 'scoring_explainer.pkl')) scoring_explainer_model = run.register_model(model_name='my_scoring_explainer', model_path='my_scoring_explainer.pkl') print(scoring_explainer_model.name, scoring_explainer_model.id, scoring_explainer_model.version, sep = '\t')Opcionális lépésként lekérheti a pontozási magyarázót a felhőből, és tesztelheti a magyarázatokat.
from azureml.interpret.scoring.scoring_explainer import load # retrieve the scoring explainer model from cloud" scoring_explainer_model = Model(ws, 'my_scoring_explainer') scoring_explainer_model_path = scoring_explainer_model.download(target_dir=os.getcwd(), exist_ok=True) # load scoring explainer from disk scoring_explainer = load(scoring_explainer_model_path) # test scoring explainer locally preds = scoring_explainer.explain(x_test) print(preds)Helyezze üzembe a rendszerképet egy számítási célon az alábbi lépések végrehajtásával:
Szükség esetén regisztrálja az eredeti előrejelzési modellt az Azure Machine Tanulás modellek üzembe helyezésének lépéseit követve.
Pontozófájl létrehozása.
%%writefile score.py import json import numpy as np import pandas as pd import os import pickle from sklearn.externals import joblib from sklearn.linear_model import LogisticRegression from azureml.core.model import Model def init(): global original_model global scoring_model # retrieve the path to the model file using the model name # assume original model is named original_prediction_model original_model_path = Model.get_model_path('original_prediction_model') scoring_explainer_path = Model.get_model_path('my_scoring_explainer') original_model = joblib.load(original_model_path) scoring_explainer = joblib.load(scoring_explainer_path) def run(raw_data): # get predictions and explanations for each data point data = pd.read_json(raw_data) # make prediction predictions = original_model.predict(data) # retrieve model explanations local_importance_values = scoring_explainer.explain(data) # you can return any data type as long as it is JSON-serializable return {'predictions': predictions.tolist(), 'local_importance_values': local_importance_values}Az üzembe helyezési konfiguráció meghatározása.
Ez a konfiguráció a modell követelményeitől függ. Az alábbi példa egy olyan konfigurációt határoz meg, amely egy processzormagot és egy GB memóriát használ.
from azureml.core.webservice import AciWebservice aciconfig = AciWebservice.deploy_configuration(cpu_cores=1, memory_gb=1, tags={"data": "NAME_OF_THE_DATASET", "method" : "local_explanation"}, description='Get local explanations for NAME_OF_THE_PROBLEM')Hozzon létre egy környezeti függőségeket tartalmazó fájlt.
from azureml.core.conda_dependencies import CondaDependencies # WARNING: to install this, g++ needs to be available on the Docker image and is not by default (look at the next cell) azureml_pip_packages = ['azureml-defaults', 'azureml-core', 'azureml-telemetry', 'azureml-interpret'] # specify CondaDependencies obj myenv = CondaDependencies.create(conda_packages=['scikit-learn', 'pandas'], pip_packages=['sklearn-pandas'] + azureml_pip_packages, pin_sdk_version=False) with open("myenv.yml","w") as f: f.write(myenv.serialize_to_string()) with open("myenv.yml","r") as f: print(f.read())Hozzon létre egy egyéni dockerfile-t a g++ telepítésével.
%%writefile dockerfile RUN apt-get update && apt-get install -y g++Telepítse a létrehozott lemezképet.
Ez a folyamat körülbelül öt percet vesz igénybe.
from azureml.core.webservice import Webservice from azureml.core.image import ContainerImage # use the custom scoring, docker, and conda files we created above image_config = ContainerImage.image_configuration(execution_script="score.py", docker_file="dockerfile", runtime="python", conda_file="myenv.yml") # use configs and models generated above service = Webservice.deploy_from_model(workspace=ws, name='model-scoring-service', deployment_config=aciconfig, models=[scoring_explainer_model, original_model], image_config=image_config) service.wait_for_deployment(show_output=True)
Tesztelje az üzembe helyezést.
import requests # create data to test service with examples = x_list[:4] input_data = examples.to_json() headers = {'Content-Type':'application/json'} # send request to service resp = requests.post(service.scoring_uri, input_data, headers=headers) print("POST to url", service.scoring_uri) # can covert back to Python objects from json string if desired print("prediction:", resp.text)Takarítsd ki.
Üzembe helyezett webszolgáltatás törléséhez használja a következőt
service.delete(): .
Hibaelhárítás
A ritka adatok nem támogatottak: A modellmagyarázat irányítópultja nagy számú funkcióval jelentősen leáll/lelassul, ezért jelenleg nem támogatjuk a ritka adatformátumot. Emellett általános memóriaproblémák merülnek fel nagy adatkészletekkel és számos funkcióval.
Támogatott magyarázatok funkcióinak mátrixa
| Támogatott magyarázat lap | Nyers jellemzők (sűrű) | Nyers funkciók (ritka) | Megtervezett funkciók (sűrű) | Mérnöki funkciók (ritkán) |
|---|---|---|---|---|
| A modell teljesítménye | Támogatott (nem előrejelzés) | Támogatott (nem előrejelzés) | Támogatott | Támogatott |
| Adathalmaz-kezelő | Támogatott (nem előrejelzés) | Nem támogatott. Mivel a ritka adatok nincsenek feltöltve, és a felhasználói felületen problémák merülnek fel a ritka adatok megjelenítésében. | Támogatott | Nem támogatott. Mivel a ritka adatok nincsenek feltöltve, és a felhasználói felületen problémák merülnek fel a ritka adatok megjelenítésében. |
| A funkció fontosságának összesítése | Támogatott | Támogatott | Támogatott | Támogatott |
| Az egyéni funkciók fontossága | Támogatott (nem előrejelzés) | Nem támogatott. Mivel a ritka adatok nincsenek feltöltve, és a felhasználói felületen problémák merülnek fel a ritka adatok megjelenítésében. | Támogatott | Nem támogatott. Mivel a ritka adatok nincsenek feltöltve, és a felhasználói felületen problémák merülnek fel a ritka adatok megjelenítésében. |
A modellmagyarázatokkal nem támogatott előrejelzési modellek: Az értelmezhetőség, a legjobb modell magyarázata nem érhető el autoML-előrejelzési kísérletekhez, amelyek a következő algoritmusokat javasolják a legjobb modellként: TCNForecaster, AutoArima, Prophet, ExponenciálisSmoothing, Average, Naive, Szezonális átlag és Szezonális Naive. Az AutoML előrejelzési regressziós modelljei támogatják a magyarázatokat. A magyarázó irányítópulton azonban az "Egyéni funkció fontossága" lap nem támogatott az előrejelzéshez az adatfolyamok összetettsége miatt.
Az adatindex helyi magyarázata: A magyarázó irányítópult nem támogatja az eredeti érvényesítési adatkészlet sorazonosítójának helyi fontossági értékeit, ha az adathalmaz nagyobb, mint 5000 adatpont, mivel az irányítópult véletlenszerűen lecsökkenti az adatokat. Az irányítópult azonban az egyes adatpontokhoz tartozó nyers adathalmaz-funkcióértékeket jeleníti meg az Egyéni funkció fontossága lapon. A felhasználók a nyers adathalmaz funkcióértékeinek megfeleltetésével visszaképezhetik a helyi fontosságokat az eredeti adathalmazra. Ha az érvényesítési adatkészlet mérete kisebb, mint 5000 minta, az
indexAzure Machine Tanulás Studio szolgáltatása megfelel az érvényesítési adatkészlet indexének.A What-if/ICE diagramok nem támogatottak a studióban: A What-If és az Individual Conditional Expectation (ICE) diagramok nem támogatottak az Azure Machine Tanulás Studióban a Magyarázatok lap alatt, mivel a feltöltött magyarázatnak aktív számításra van szüksége az előrejelzések és a perturbálási funkciók valószínűségének újraszámításához. A Jupyter-jegyzetfüzetekben jelenleg támogatott, ha vezérlőként fut az SDK használatával.
További lépések
Az Azure Machine Tanulás modellértelmezhetőségének technikái
Tekintse meg az Azure Machine Tanulás értelmezhetőségi mintajegyzetfüzeteit