Adatok előkészítése számítógépes látási feladatokhoz automatizált gépi tanulással
ÉRVÉNYES: Azure CLI ml-bővítmény v2 (aktuális)Python SDK azure-ai-ml v2 (aktuális)
Azure CLI ml-bővítmény v2 (aktuális)Python SDK azure-ai-ml v2 (aktuális)
Fontos
Az Azure Machine Learningben az automatizált gépi tanulással rendelkező számítógépes látásmodellek betanításának támogatása egy kísérleti nyilvános előzetes verziójú funkció. Előfordulhat, hogy néhány funkció nem támogatott, vagy korlátozott képességekkel rendelkezik. További információ: Kiegészítő használati feltételek a Microsoft Azure előzetes verziójú termékeihez.
Ebből a cikkből megtudhatja, hogyan készítheti elő a rendszerképadatokat a számítógépes látásmodellek betanításához automatizált gépi tanulással az Azure Machine Learningben.
Ha számítógépes látási feladatokhoz szeretne modelleket létrehozni automatizált gépi tanulással, címkézett képadatokat kell bevinnie a modell betanításához egy MLTable.
A címkézett betanítási adatokból JSONL formátumban hozhat létre MLTable .
Ha a címkézett betanítási adatok más formátumban vannak (például pascal VOC vagy COCO), használhat egy konverziós szkriptet , amely először JSONL-be konvertálja, majd létrehoz egy MLTable. Másik lehetőségként az Azure Machine Learning adatcímkéző eszközével manuálisan címkézheti a képeket, és exportálhatja a címkézett adatokat az AutoML-modell betanításához.
Előfeltételek
- Ismerkedjen meg az AutoML számítógépes látási kísérleteihez használható JSONL-fájlok elfogadott sémáival.
Címkézett adatok lekérése
Ahhoz, hogy számítógépes látásmodelleket taníthasson be az AutoML használatával, először címkézett betanítási adatokat kell kapnia. A képeket fel kell tölteni a felhőbe, és a címkék széljegyzeteinek JSONL formátumban kell lenniük. Az Azure Machine Learning Data Labeling eszközzel címkézheti az adatokat, vagy előre címkézett képadatokkal kezdhet.
Az Azure Machine Learning Adatcímkéző eszköz használata a betanítási adatok címkézéséhez
Ha nem rendelkezik előre megjelölt adatokkal, az Azure Machine Learning adatcímkéző eszközével manuálisan címkézheti a képeket. Ez az eszköz automatikusan létrehozza a betanításhoz szükséges adatokat az elfogadott formátumban.
Segít az adatcímkézési feladatok létrehozásában, kezelésében és monitorozásában
- Képbesorolás (többosztályos és többcímke)
- Objektumészlelés (határolókeret)
- Példányszegmentáció (sokszög)
Ha már rendelkezik a használni kívánt címkézett adatokkal, exportálhatja a címkézett adatokat Azure Machine Learning-adatkészletként , majd elérheti az adathalmazt az Azure Machine Learning Studióban az "Adathalmazok" lapon. Ez az exportált adatkészlet ezután formátum használatával azureml:<tabulardataset_name>:<version> továbbítható bemenetként. Íme egy példa arra, hogyan továbbíthatja a meglévő adatkészletet bemenetként a számítógépes látásmodellek betanításához.
A KÖVETKEZŐRE VONATKOZIK: Azure CLI ml-bővítmény v2 (aktuális)
training_data:
path: azureml:odFridgeObjectsTrainingDataset:1
type: mltable
mode: direct
Előre címkézett betanítási adatok használata a helyi gépről
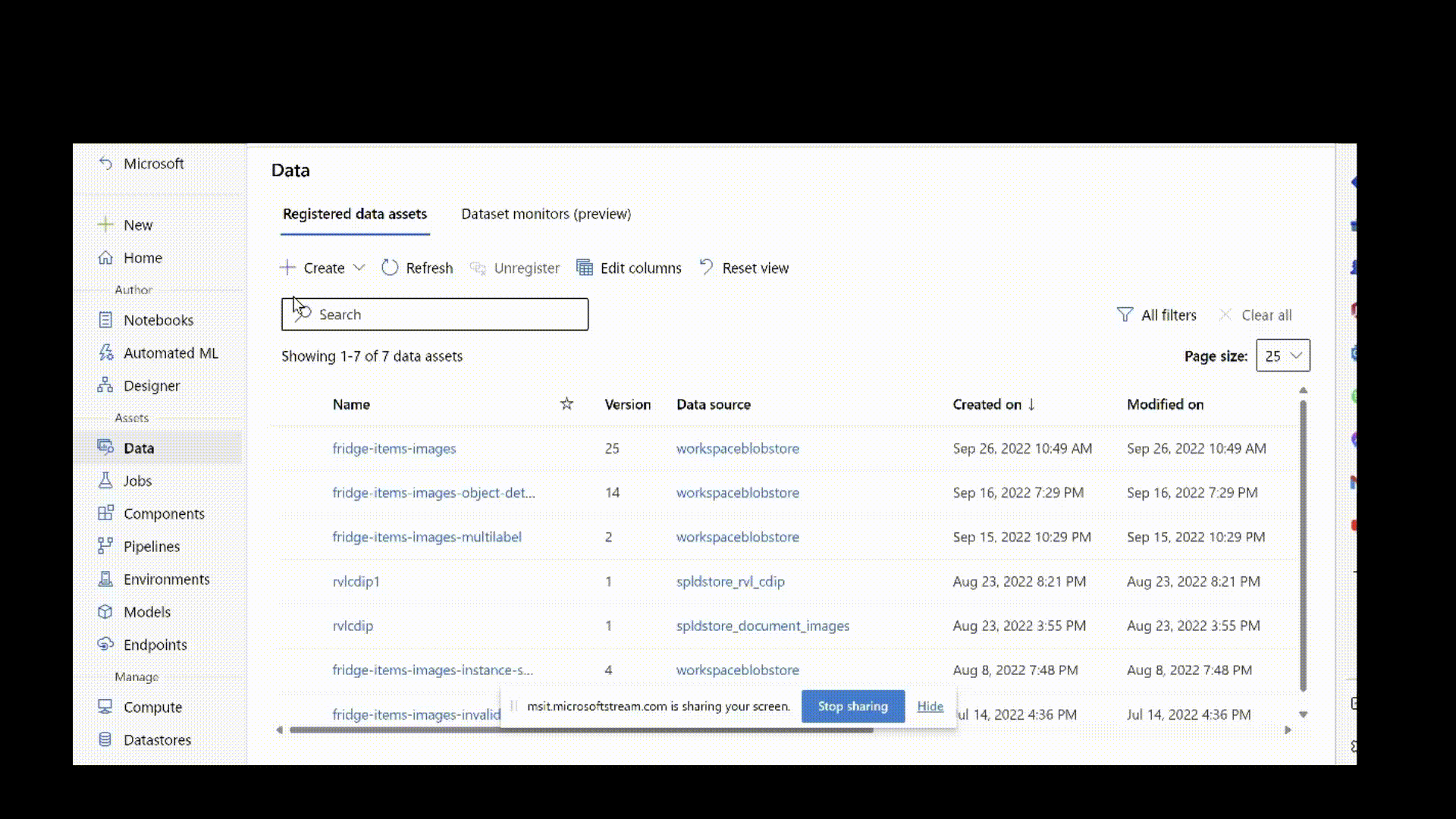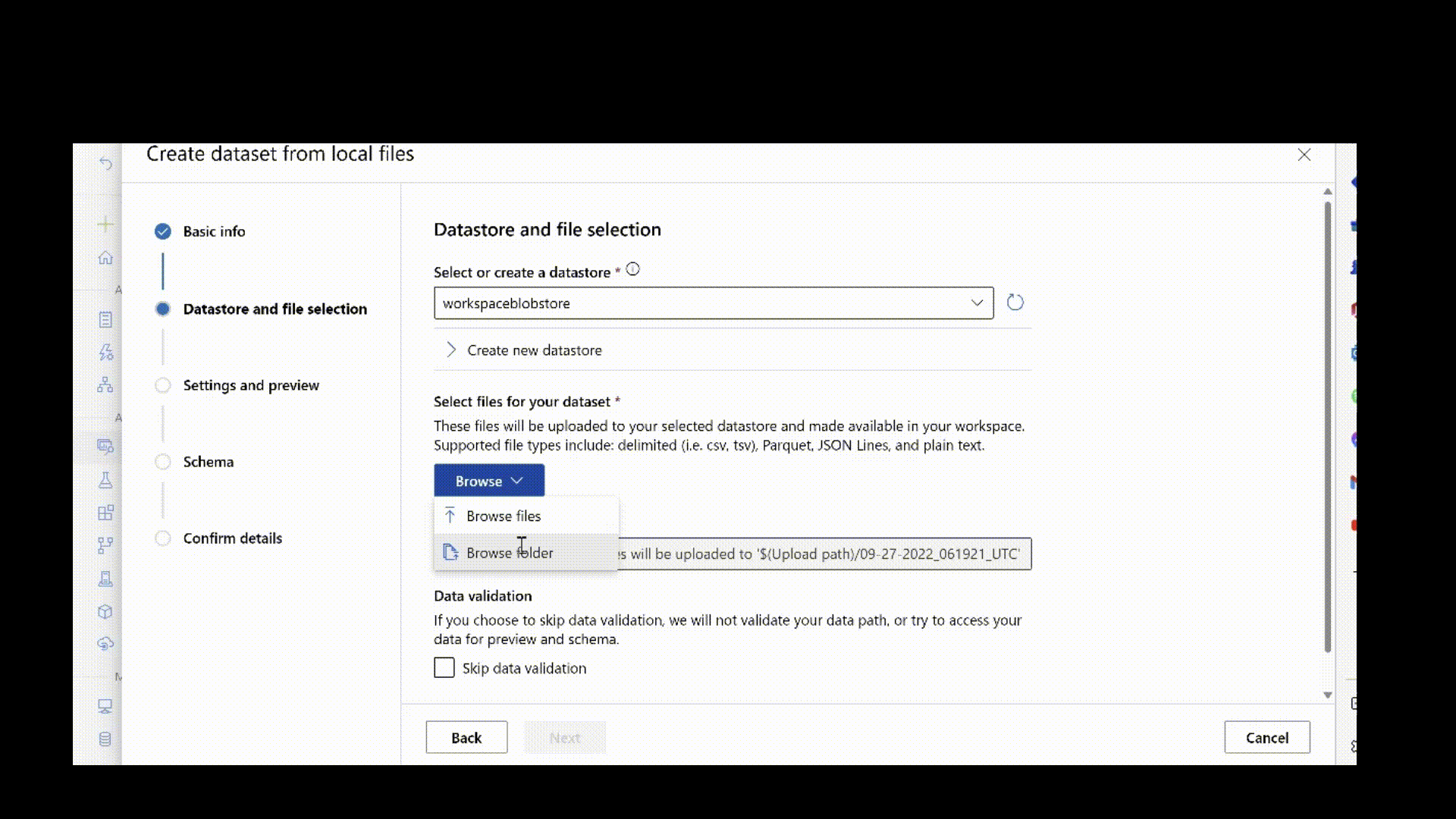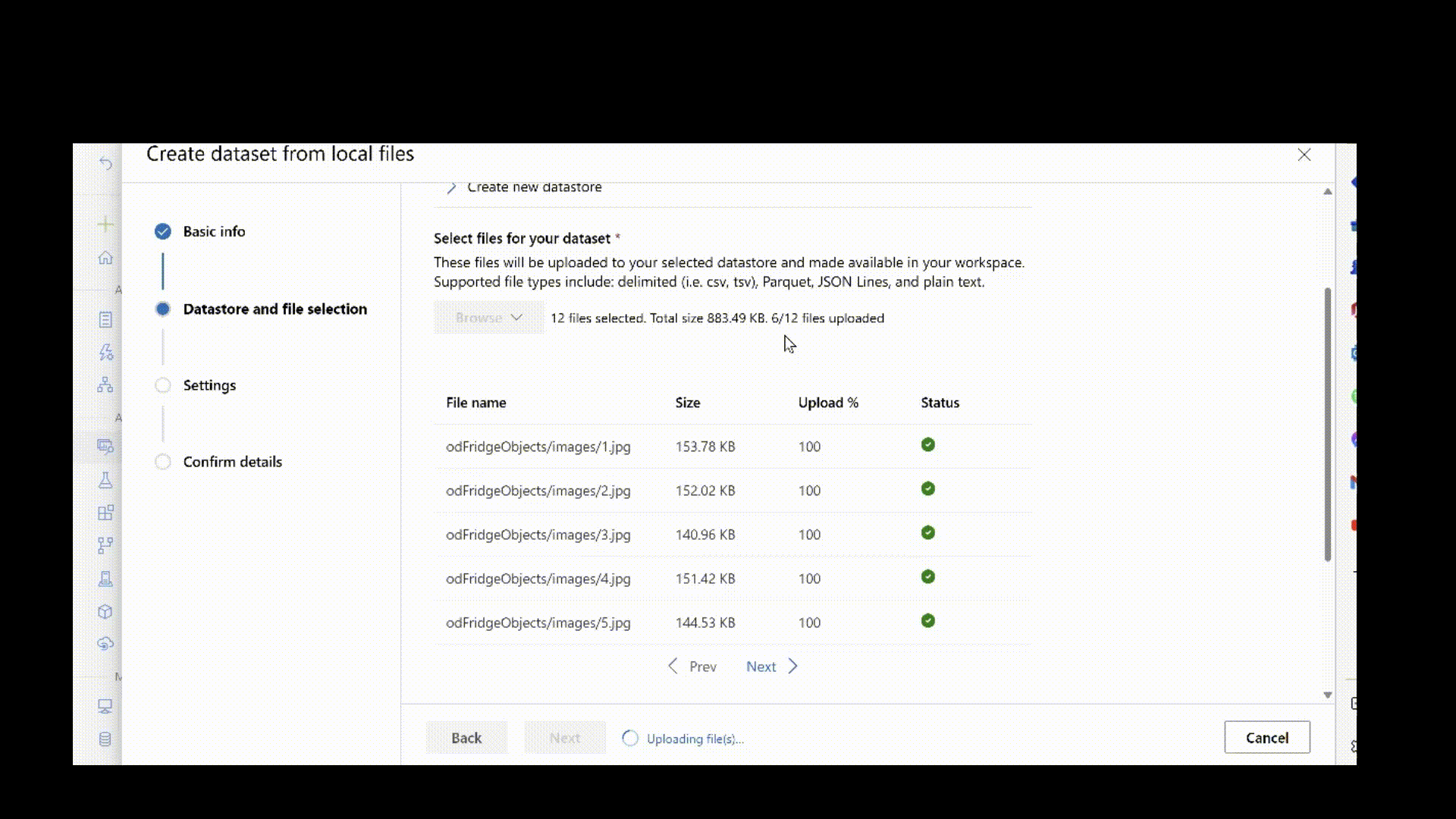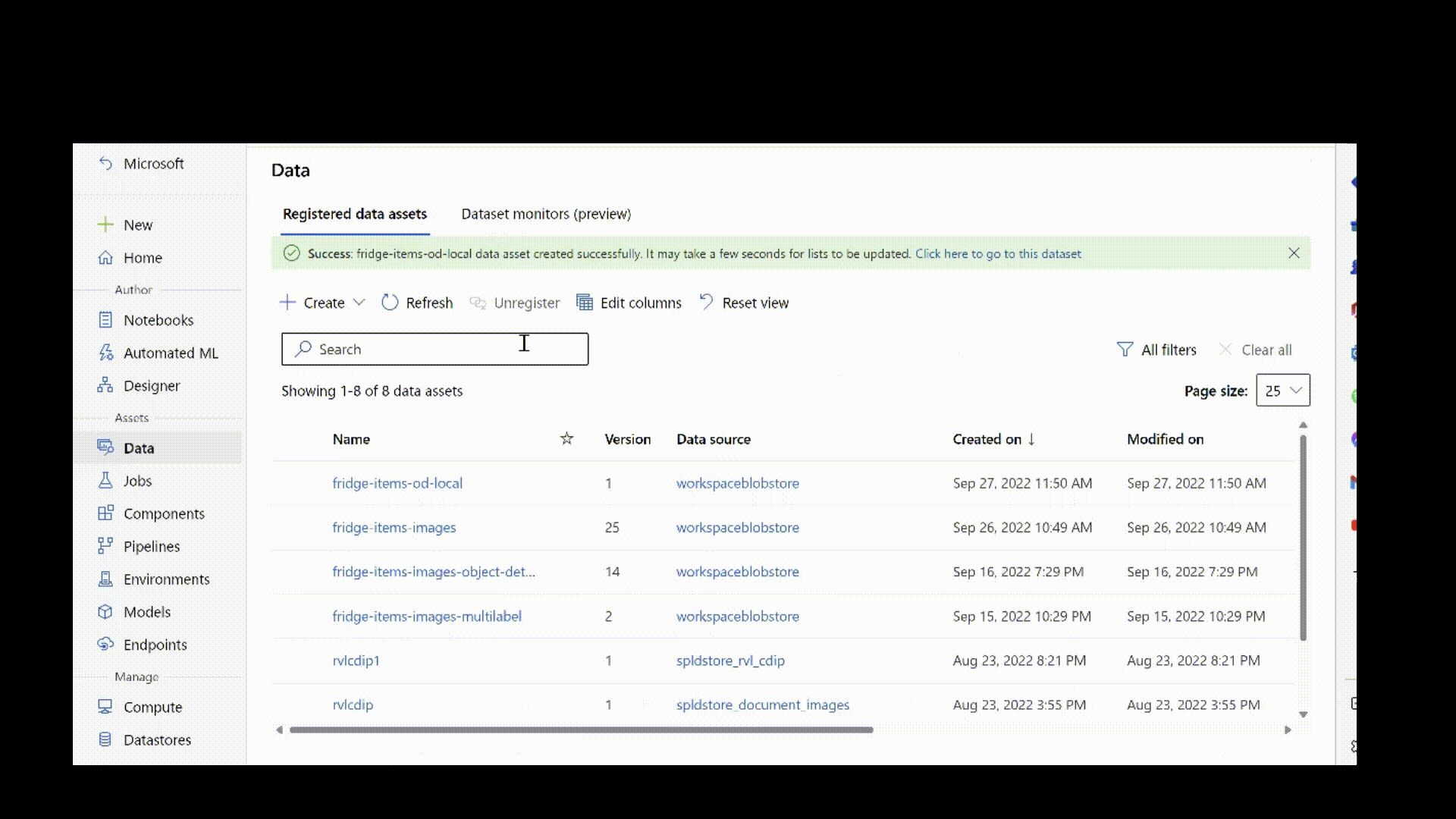
Ha olyan adatokat címkézett meg, amelyeket a modell betanítása érdekében szeretne használni, fel kell töltenie a képeket az Azure-ba. A rendszerképeket feltöltheti az Azure Machine Learning-munkaterület alapértelmezett Azure Blob Storage-tárhelyére, és regisztrálhatja adategységként.
Az alábbi szkript feltölti a rendszerképadatokat a helyi gépen a "./data/odFridgeObjects" útvonalon az Azure Blob Storage adattárba. Ezután létrehoz egy új adategységet "fridge-items-images-object-detection" néven az Azure Machine Learning-munkaterületen.
Ha már létezik "hűtőszekrény-items-images-object-detection" nevű adategység az Azure Machine Learning-munkaterületen, frissíti az adategység verziószámát, és átirányítja az új helyre, ahol a rendszerképadatok fel vannak töltve.
A KÖVETKEZŐRE VONATKOZIK: Azure CLI ml-bővítmény v2 (aktuális)
Hozzon létre egy .yml fájlt az alábbi konfigurációval.
$schema: https://azuremlschemas.azureedge.net/latest/data.schema.json
name: fridge-items-images-object-detection
description: Fridge-items images Object detection
path: ./data/odFridgeObjects
type: uri_folder
A képek adategységként való feltöltéséhez futtassa a következő CLI v2 parancsot a .yml fájl elérési útjával, a munkaterület nevével, az erőforráscsoporttal és az előfizetés azonosítójával.
az ml data create -f [PATH_TO_YML_FILE] --workspace-name [YOUR_AZURE_WORKSPACE] --resource-group [YOUR_AZURE_RESOURCE_GROUP] --subscription [YOUR_AZURE_SUBSCRIPTION]
Ha már rendelkezik az adataival egy meglévő adattárban, és egy adategységet szeretne belőle létrehozni, ezt úgy teheti meg, hogy megadja az adattárban lévő adatok elérési útját ahelyett, hogy a helyi gép elérési útját adja meg. Frissítse a fenti kódot a következő kódrészlettel.
A KÖVETKEZŐRE VONATKOZIK: Azure CLI ml-bővítmény v2 (aktuális)
Hozzon létre egy .yml fájlt az alábbi konfigurációval.
$schema: https://azuremlschemas.azureedge.net/latest/data.schema.json
name: fridge-items-images-object-detection
description: Fridge-items images Object detection
path: azureml://subscriptions/<my-subscription-id>/resourcegroups/<my-resource-group>/workspaces/<my-workspace>/datastores/<my-datastore>/paths/<path_to_image_data_folder>
type: uri_folder
Ezután JSONL formátumban kell lekérnie a címkejegyzeteket. A címkézett adatok sémája a számítógépes látási feladattól függ. Az AutoML számítógépes látási kísérleteihez készült JSONL-fájlok sémáiban további információt kaphat az egyes feladattípusokhoz szükséges JSONL-sémákról.
Ha a betanítási adatok más formátumban vannak (például pascal VOC vagy COCO), az adatok JSONL-zé alakítására szolgáló segédszkriptek a jegyzetfüzet-példákban érhetők el.
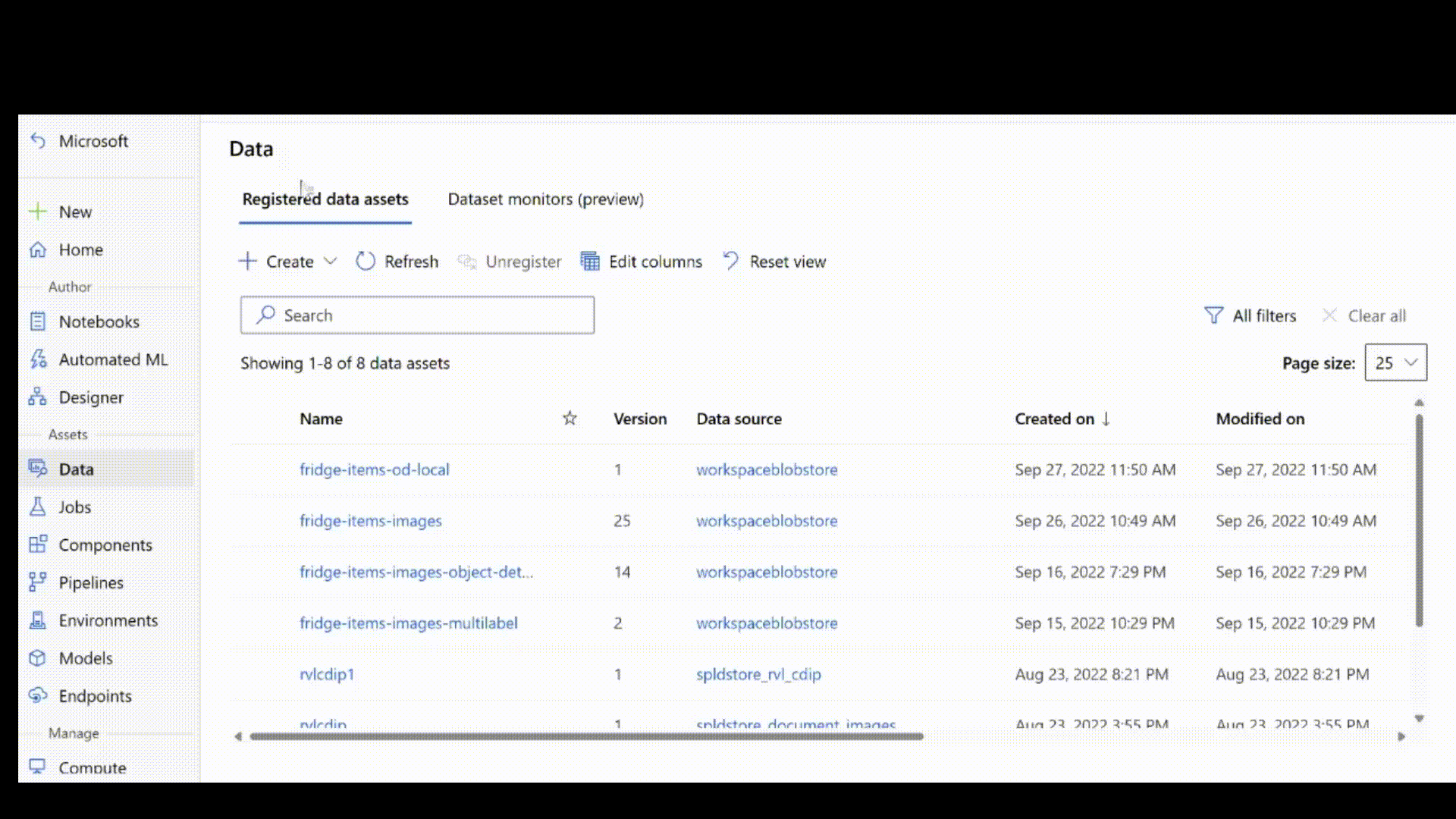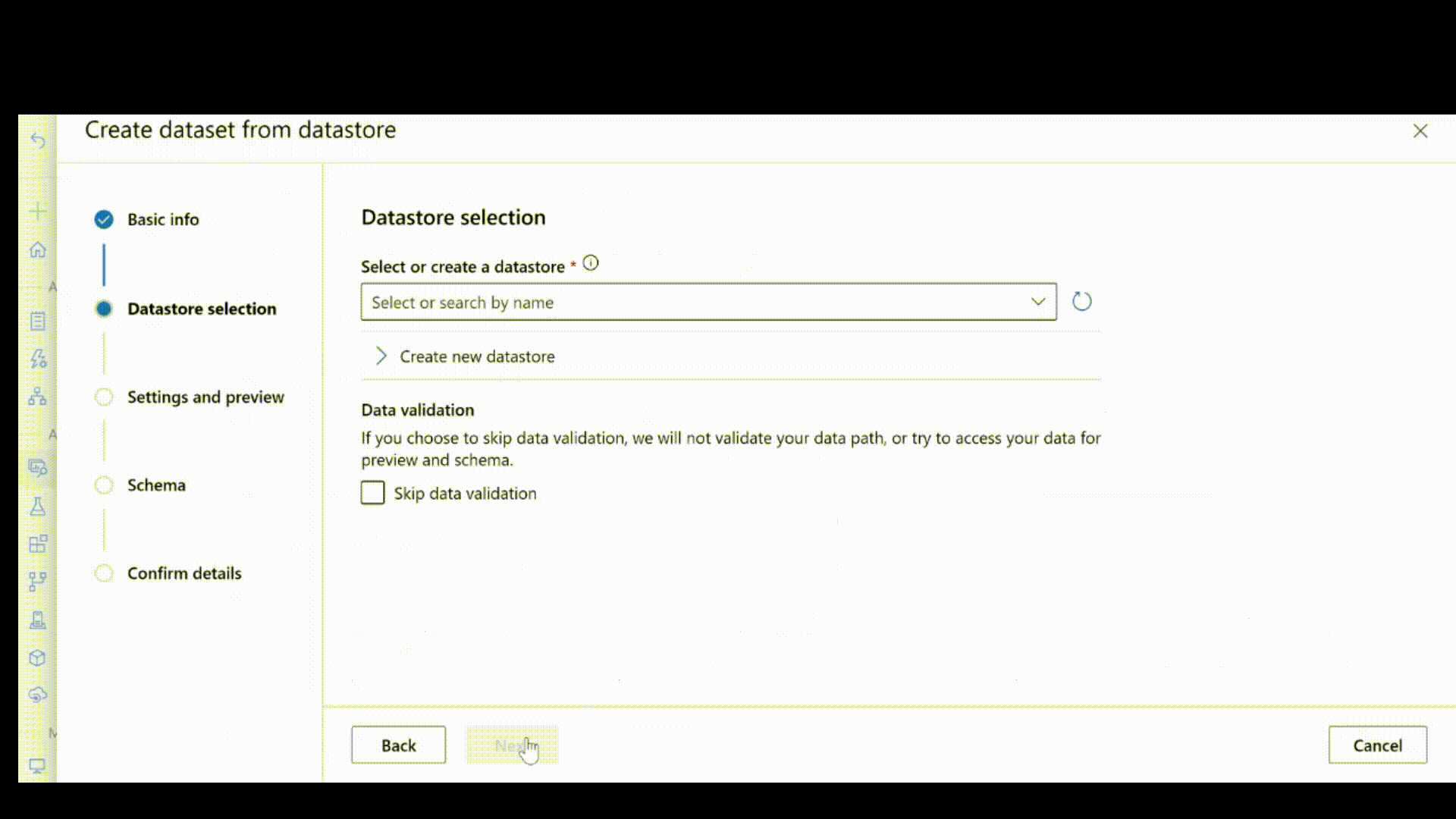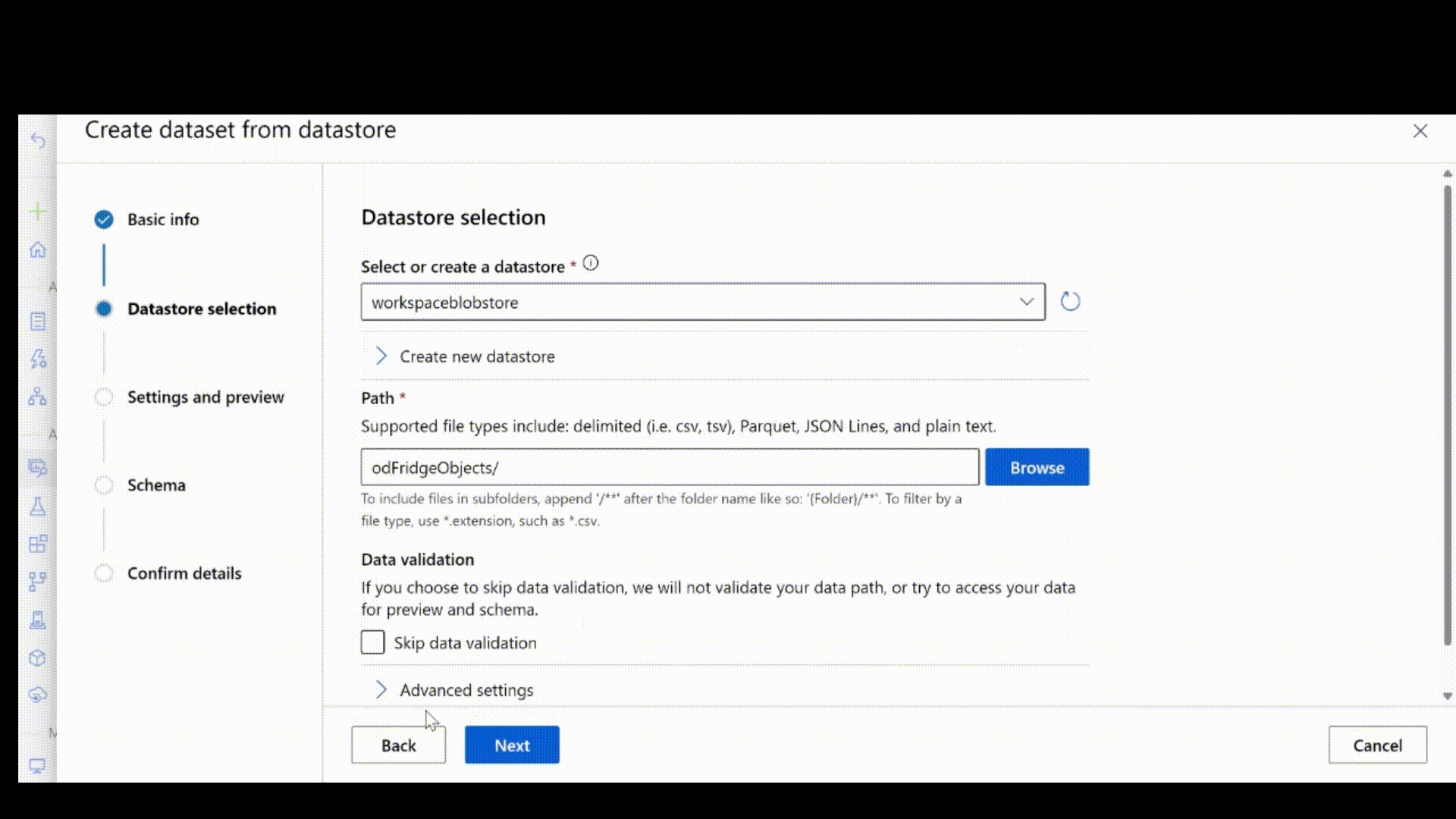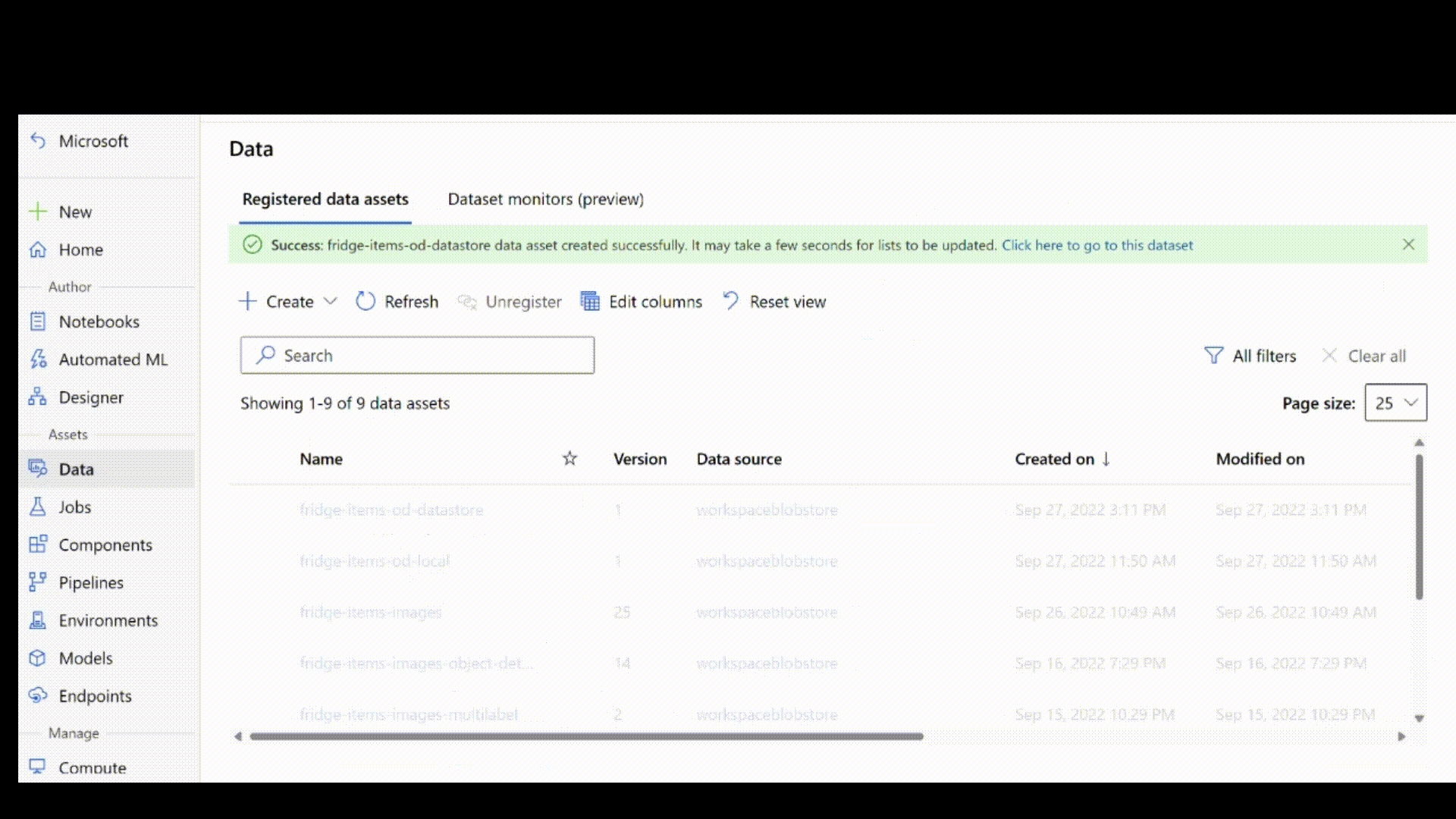
Miután létrehozta a jsonl-fájlt a fenti lépéseket követve, felhasználói felületen regisztrálhatja azt adategységként. Győződjön meg arról, hogy a sémaszakaszban a típust választja stream az animációban látható módon.
Előre felcímkézett betanítási adatok használata az Azure Blob Storage-ból
Ha a címkézett betanítási adatok egy Azure Blob Storage-tárolóban találhatók, akkor közvetlenül onnan érheti el azokat egy, a tárolóra hivatkozó adattár létrehozásával.
MLTable létrehozása
Miután JSONL formátumban megadta a címkézett adatokat, létrehozhatja azokat MLTable az ebben a yaml-kódrészletben látható módon. Az MLtable egy hasznosítható objektumba csomagolja az adatokat a betanításhoz.
paths:
- file: ./train_annotations.jsonl
transformations:
- read_json_lines:
encoding: utf8
invalid_lines: error
include_path_column: false
- convert_column_types:
- columns: image_url
column_type: stream_info
Ezután adatbemenetként továbbíthatja az MLTable AutoML-betanítási feladathoz.
Következő lépések
Visszajelzés
Hamarosan elérhető: 2024-ben fokozatosan kivezetjük a GitHub-problémákat a tartalom visszajelzési mechanizmusaként, és lecseréljük egy új visszajelzési rendszerre. További információ: https://aka.ms/ContentUserFeedback.
Visszajelzés küldése és megtekintése a következőhöz: