Algoritmusok kiválasztása az Azure Machine Learninghez
Ha kíváncsi arra, hogy melyik gépi tanulási algoritmust használja, a válasz elsősorban az adatelemzési forgatókönyv két aspektusától függ:
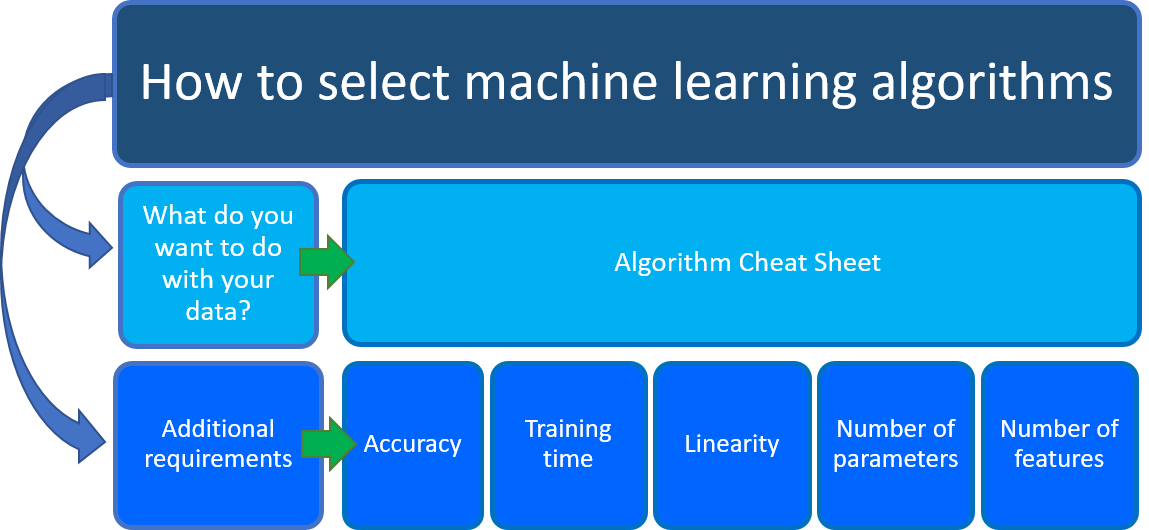
Mit szeretne tenni az adataival? Konkrétan mi az az üzleti kérdés, amelyre a múltbeli adatokból tanulva szeretne választ adni?
Mik az adatelemzési forgatókönyv követelményei? Milyen funkciókat, pontosságot, betanítási időt, linearitást és paramétereket támogat a megoldás?
Feljegyzés
Az Azure Machine Learning-tervező kétféle összetevőt támogat: klasszikus előre összeállított összetevőket (v1) és egyéni összetevőket (v2). Ez a két összetevőtípus NEM kompatibilis.
A klasszikus előre összeállított összetevők elsősorban adatfeldolgozási és hagyományos gépi tanulási feladatokhoz, például regresszióhoz és besoroláshoz használhatók. Ez az összetevőtípus továbbra is támogatott marad, de nem lesznek új összetevők hozzáadva.
Az egyéni összetevők lehetővé teszik, hogy a saját kódját összetevőként csomagolja. Támogatják az összetevők munkaterületek közötti megosztását, valamint a közvetlen létrehozást a Studio, a CLI v2 és az SDK v2-felületeken.
Új projektek esetén határozottan javasoljuk, hogy egyéni összetevőket használjon, amelyek kompatibilisek az AzureML V2-vel, és folyamatosan új frissítéseket kapnak.
Ez a cikk a klasszikus előre összeállított összetevőkre vonatkozik, és nem kompatibilis a CLI v2-vel és az SDK v2-vel.
Az Azure Machine Learning-algoritmus csalilapja
Az Azure Machine Learning-algoritmus csalólapja segít az első szempontban: Mit szeretne tenni az adataival? A csalási lapon keresse meg a elvégezni kívánt feladatot, majd keressen egy Azure Machine Learning-tervező algoritmust a prediktív elemzési megoldáshoz.
Feljegyzés
Letöltheti a Machine Learning-algoritmus csalási lapját.
A tervező olyan algoritmusok átfogó portfólióját biztosítja, mint a többosztályos döntési erdő, a javaslati rendszerek, a neurális hálózati regresszió, a többosztályos neurális hálózat és a K-Means fürtözés. Mindegyik algoritmus más típusú gépi tanulási probléma megoldására lett kialakítva. A teljes listát az algoritmus és az összetevő referenciája , valamint az egyes algoritmusok működésével és a paraméterek az algoritmus optimalizálása érdekében történő finomhangolásával kapcsolatos dokumentációval együtt találja.
Ezzel az útmutatóval együtt tartsa szem előtt az egyéb követelményeket a gépi tanulási algoritmusok kiválasztásakor. Az alábbiakban további szempontokat kell figyelembe venni, például a pontosságot, a betanítási időt, a linearitást, a paraméterek számát és a funkciók számát.
Gépi tanulási algoritmusok összehasonlítása
Egyes algoritmusok konkrét feltételezéseket tesznek az adatok szerkezetéről vagy a kívánt eredményekről. Ha megtalálja az igényeinek megfelelőt, az hasznosabb eredményeket, pontosabb előrejelzéseket vagy gyorsabb betanítási időt biztosíthat.
Az alábbi táblázat összefoglalja az algoritmusok legfontosabb jellemzőit a besorolási, regressziós és fürtözési családokból:
| Algoritmus | Pontosság | Betanítási idő | Linearitás | Paraméterek | Jegyzetek |
|---|---|---|---|---|---|
| Besorolási család | |||||
| Kétosztályos logisztikai regresszió | Jó | Gyors | Igen | 4 | |
| Kétosztályos döntési erdő | Kiváló | Mérsékelt | Nem | 5 | Lassabb pontozási időket jelenít meg. Azt javasoljuk, hogy ne működj együtt az Egy és a Minden osztály között, mert lassabb pontozási időket okoz a szálzárolás a fa előrejelzéseinek halmozása során |
| Kétosztályos emelt szintű döntési fa | Kiváló | Mérsékelt | Nem | 6 | Nagy memóriaigény |
| Kétosztályos neurális hálózat | Jó | Mérsékelt | Nem | 8 | |
| Kétosztályos átlagolt perceptron | Jó | Mérsékelt | Igen | 4 | |
| Kétosztályos támogatási vektorgép | Jó | Gyors | Igen | 5 | Nagy funkciókészletekhez használható |
| Többosztályos logisztikai regresszió | Jó | Gyors | Igen | 4 | |
| Többosztályos döntési erdő | Kiváló | Mérsékelt | Nem | 5 | Lassabb pontozási idők megjelenítése |
| Többosztályos emelt döntési fa | Kiváló | Mérsékelt | Nem | 6 | A pontosság javítása a kisebb lefedettség kis kockázatával |
| Többosztályos neurális hálózat | Jó | Mérsékelt | Nem | 8 | |
| Egy és mindenhez többosztályos | - | - | - | - | A kiválasztott kétosztályos metódus tulajdonságainak megtekintése |
| Regressziós család | |||||
| Lineáris regresszió | Jó | Gyors | Igen | 4 | |
| Döntési erdő regressziója | Kiváló | Mérsékelt | Nem | 5 | |
| Megnövelt döntési fa regressziója | Kiváló | Mérsékelt | Nem | 6 | Nagy memóriaigény |
| Neurális hálózati regresszió | Jó | Mérsékelt | Nem | 8 | |
| Fürtözési család | |||||
| K-közép fürtözés | Kiváló | Mérsékelt | Igen | 8 | Fürtözési algoritmus |
Adatelemzési forgatókönyv követelményei
Ha már tudja, mit szeretne tenni az adataival, meg kell határoznia az adatelemzési forgatókönyv egyéb követelményeit.
Válasszon és esetleg kompromisszumot a következő követelményeknek megfelelően:
- Pontosság
- Betanítási idő
- Linearitás
- Paraméterek száma
- Szolgáltatások száma
Pontosság
A gépi tanulás pontossága a modell hatékonyságát méri a valós eredmények arányaként az összes esethez. A tervezőben a Modell kiértékelése összetevő iparági szabvány szerinti értékelési metrikák készletét számítja ki. Ezzel az összetevővel mérheti a betanított modellek pontosságát.
A lehető legpontosabb válasz nem mindig szükséges. Előfordulhat, hogy a közelítés megfelelő, attól függően, hogy mire szeretné használni. Ha ez a helyzet, előfordulhat, hogy jelentősen meg tudja csökkenteni a feldolgozási időt a közelítőbb módszerekkel való ragasztással. A közelítő módszerek természetesen elkerülik a túlillesztést.
A Modell kiértékelése összetevő háromféleképpen használható:
- Pontszámok létrehozása a betanítási adatokon a modell kiértékeléséhez.
- Hozzon létre pontszámokat a modellen, de hasonlítsa össze ezeket a pontszámokat egy fenntartott tesztelési csoportban lévő pontszámokkal.
- Hasonlítsa össze két különböző, de kapcsolódó modell pontszámait ugyanazzal az adatkészlettel.
A gépi tanulási modellek pontosságának kiértékeléséhez használható metrikák és megközelítések teljes listájáért tekintse meg a Modell kiértékelése összetevőt.
Betanítási idő
A felügyelt tanulásban a betanítás azt jelenti, hogy az előzményadatok használatával olyan gépi tanulási modellt hoz létre, amely minimalizálja a hibákat. A modellek betanítása során szükséges percek vagy órák száma algoritmusok között nagyban eltér. A betanítási idő gyakran szorosan kötődik a pontossághoz; az egyik általában a másikat kíséri.
Emellett egyes algoritmusok jobban érzékenyek az adatpontok számára, mint másokra. Egy adott algoritmust azért választhat, mert időkorlátja van, különösen akkor, ha az adathalmaz nagy.
A tervezőben a gépi tanulási modell létrehozása és használata általában három lépésből áll:
Konfiguráljon egy modellt egy adott algoritmustípus kiválasztásával, majd annak paramétereinek vagy hiperparamétereinek meghatározásával.
Adjon meg egy címkézett és az algoritmussal kompatibilis adatokat tartalmazó adathalmazt. Csatlakoztassa mind az adatokat, mind a modellt a Modell betanítása összetevőhöz.
A betanítás befejezése után használja a betanított modellt az egyik pontozó összetevővel az új adatokra vonatkozó előrejelzések készítéséhez.
Linearitás
A statisztikák és a gépi tanulás linearitása azt jelenti, hogy lineáris kapcsolat van egy változó és egy állandó között az adathalmazban. A lineáris besorolási algoritmusok például feltételezik, hogy az osztályok egyenes vonallal (vagy annak magasabb dimenziós analógjával) elválaszthatók.
Sok gépi tanulási algoritmus használja a linearitást. Az Azure Machine Learning tervezőjében a következők szerepelnek:
A lineáris regressziós algoritmusok feltételezik, hogy az adattrendek egyenes vonalat követnek. Ez a feltételezés bizonyos problémák esetén nem rossz, mások esetében azonban csökkenti a pontosságot. Hátrányaik ellenére a lineáris algoritmusok első stratégiaként népszerűek. Ezek általában algoritmikusan egyszerűek és gyorsan taníthatók.
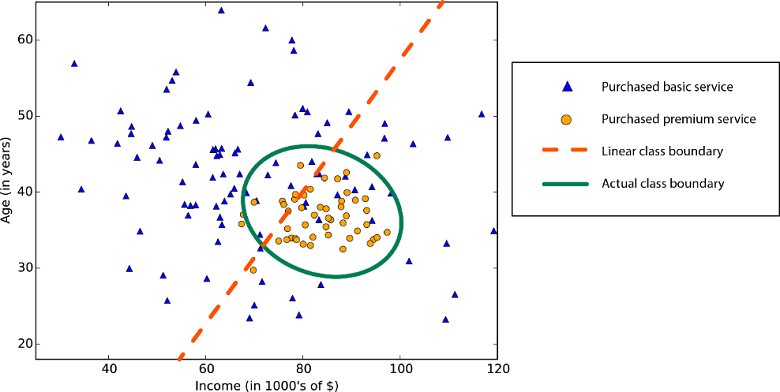
Nemlineáris osztályhatár: Ha lineáris besorolási algoritmusra támaszkodik, az alacsony pontosságot eredményezne.
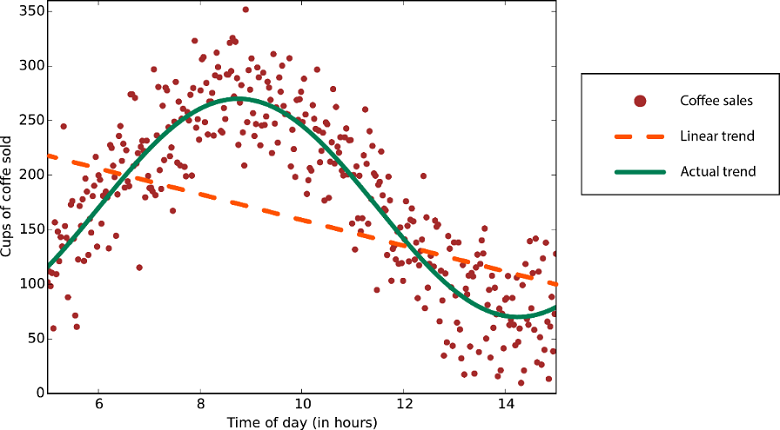
Nemlineáris trenddel rendelkező adatok: Lineáris regressziós módszer használata a szükségesnél sokkal nagyobb hibákat eredményezne.
Paraméterek száma
A paraméterek azok a gombok, amelyeket az adatelemzők az algoritmusok beállításakor kapnak. Ezek olyan számok, amelyek befolyásolják az algoritmus viselkedését, például a hibatűrést vagy az iterációk számát, vagy az algoritmus viselkedésének különböző változatai közötti lehetőségeket. Az algoritmus betanítási ideje és pontossága néha érzékeny lehet a megfelelő beállítások megadására. A nagy számú paraméterrel rendelkező algoritmusok általában a legtöbb próbaverziót és hibát igénylik a jó kombináció megtalálásához.
Másik lehetőségként a modell hiperparamétereinek finomhangolása is szerepel a tervezőben. Ennek az összetevőnek a célja a gépi tanulási modell optimális hiperparamétereinek meghatározása. Az összetevő több modellt fejleszt és tesztel különböző beállítások kombinációjával. Összehasonlítja az összes modell metrikáit a beállítások kombinációinak lekéréséhez.
Bár ez nagyszerű módja annak, hogy a paraméterterületet átfogja, a modell betanításához szükséges idő exponenciálisan nő a paraméterek számával. Ennek az az előnye, hogy sok paraméter általában azt jelzi, hogy egy algoritmus nagyobb rugalmasságot biztosít. Gyakran nagyon jó pontosságot érhet el, feltéve, hogy megtalálja a paraméterbeállítások megfelelő kombinációját.
Szolgáltatások száma
A gépi tanulásban a funkció az elemezni kívánt jelenség számszerűsíthető változója. Bizonyos adattípusok esetében a funkciók száma nagyon nagy lehet az adatpontok számához képest. Ez gyakran előfordul a genetika vagy szöveges adatok esetében.
Számos funkció leállíthat néhány tanulási algoritmust, így a betanítási idő elérhetetlenül hosszú. A támogatási vektorgépek kiválóan alkalmasak a sok funkcióval rendelkező forgatókönyvekre. Emiatt számos alkalmazásban használták őket az információlekéréstől a szöveg- és képbesorolásig. A támogatási vektorgépek a besorolási és regressziós feladatokhoz is használhatók.
A funkcióválasztás a statisztikai tesztek bemenetekre való alkalmazásának folyamatát jelenti egy megadott kimenet alapján. A cél annak meghatározása, hogy mely oszlopok prediktívabbak a kimenetben. A tervező szűrőalapú funkciókijelölési összetevője több funkciókijelölési algoritmus közül választhat. Az összetevő olyan korrelációs módszereket tartalmaz, mint a Pearson-korreláció és a khi-négyzet értékek.
A Permutation Feature Importance összetevővel is kiszámíthatja az adathalmaz funkció-fontossági pontszámainak készletét. Ezek a pontszámok segítenek a modellben használni kívánt legjobb funkciók meghatározásában.