Gépi tanulási folyamatok aktiválása
A KÖVETKEZŐKRE VONATKOZIK: Python SDK azureml v1
Python SDK azureml v1
Ebben a cikkben megtudhatja, hogyan ütemezhet programozott módon egy folyamatot az Azure-ban való futtatásra. Az ütemezést az eltelt idő vagy a fájlrendszer változásai alapján hozhatja létre. Az időalapú ütemezések olyan rutinfeladatok elvégzésére használhatók, mint az adatelsodródás monitorozása. A változásalapú ütemezésekkel reagálhat a rendszertelen vagy kiszámíthatatlan változásokra, például az új adatok feltöltésére vagy a régi adatok szerkesztésére. Az ütemezések létrehozásának elsajátítása után megtudhatja, hogyan kérdezheti le és inaktiválhatja őket. Végül megtanulhatja, hogyan futtathat folyamatokat más Azure-szolgáltatások, az Azure Logic App és az Azure Data Factory használatával. Az Azure Logic App összetettebb logikát vagy viselkedést tesz lehetővé. Az Azure Data Factory-folyamatok lehetővé teszik egy gépi tanulási folyamat meghívását egy nagyobb adatvezénylési folyamat részeként.
Előfeltételek
Azure-előfizetés. Ha nem rendelkezik Azure-előfizetéssel, hozzon létre egy ingyenes fiókot.
Egy Python-környezet, amelyben telepítve van a Pythonhoz készült Azure Machine Learning SDK. További információ: Újrahasználható környezetek létrehozása és kezelése betanításhoz és üzembe helyezéshez az Azure Machine Learning használatával.
Machine Learning-munkaterület közzétett folyamattal. A Gépi tanulási folyamatok létrehozása és futtatása az Azure Machine Learning SDK-val beépített folyamatokat használhatja.
Folyamatok aktiválása a Pythonhoz készült Azure Machine Learning SDK-val
A folyamatok ütemezéséhez szüksége lesz a munkaterületre mutató hivatkozásra, a közzétett folyamat azonosítójára és annak a kísérletnek a nevére, amelyben létre szeretné hozni az ütemezést. Ezeket az értékeket a következő kóddal szerezheti be:
import azureml.core
from azureml.core import Workspace
from azureml.pipeline.core import Pipeline, PublishedPipeline
from azureml.core.experiment import Experiment
ws = Workspace.from_config()
experiments = Experiment.list(ws)
for experiment in experiments:
print(experiment.name)
published_pipelines = PublishedPipeline.list(ws)
for published_pipeline in published_pipelines:
print(f"{published_pipeline.name},'{published_pipeline.id}'")
experiment_name = "MyExperiment"
pipeline_id = "aaaaaaaaa-bbbb-cccc-dddd-eeeeeeeeeeee"
Ütemezés létrehozása
Ha ismétlődően szeretne futtatni egy folyamatot, létre kell hoznia egy ütemezést. Egy Schedule folyamat, egy kísérlet és egy eseményindító társítása. Az eseményindító lehet egyScheduleRecurrence olyan eseményindító, amely leírja a feladatok közötti várakozást, vagy egy adattár elérési útját, amely megadja a változások figyelésére szolgáló könyvtárat. Mindkét esetben szüksége lesz a folyamatazonosítóra és annak a kísérletnek a nevére, amelyben létre szeretné hozni az ütemezést.
A Python-fájl tetején importálja a Schedule következő osztályokat:ScheduleRecurrence
from azureml.pipeline.core.schedule import ScheduleRecurrence, Schedule
Időalapú ütemezés létrehozása
A ScheduleRecurrence konstruktornak van egy kötelező frequency argumentuma, amelynek a következő sztringek egyikének kell lennie: "Minute", "Hour", "Day", "Week" vagy "Month". Ehhez egy egész szám interval argumentumra is szükség van, amely meghatározza, hogy hány frequency egységnek kell eltelte az ütemezés kezdete között. Az opcionális argumentumok lehetővé teszik a kezdési időpontok pontosabb, a ScheduleRecurrence SDK dokumentációjában leírtak szerint történő pontosabb használatát.
Hozzon létre egy Schedule feladatot 15 percenként:
recurrence = ScheduleRecurrence(frequency="Minute", interval=15)
recurring_schedule = Schedule.create(ws, name="MyRecurringSchedule",
description="Based on time",
pipeline_id=pipeline_id,
experiment_name=experiment_name,
recurrence=recurrence)
Változásalapú ütemezés létrehozása
A fájlmódosítások által aktivált folyamatok hatékonyabbak lehetnek, mint az időalapú ütemezések. Ha egy fájl módosítása előtt szeretne tenni valamit, vagy ha új fájlt ad hozzá egy adatkönyvtárhoz, előfeldolgozást végezhet a fájlon. Az adattár módosításait vagy az adattár egy adott könyvtárán belüli módosításokat figyelheti. Ha egy adott könyvtárat figyel, az adott könyvtár alkönyvtárán belüli módosítások nem aktiválnak feladatot.
Feljegyzés
A változásalapú ütemezések csak az Azure Blob Storage monitorozását támogatják.
Fájlreaktív Schedulefájl létrehozásához be kell állítania a datastore paramétert a Schedule.create hívásában. Mappa figyeléséhez állítsa be az argumentumot path_on_datastore .
Az polling_interval argumentum lehetővé teszi, hogy percek alatt megadja az adattár módosításainak ellenőrzésének gyakoriságát.
Ha a folyamat DataPath PipelineParameterrel lett létrehozva, az argumentum beállításával data_path_parameter_name beállíthatja a változót a módosított fájl nevére.
datastore = Datastore(workspace=ws, name="workspaceblobstore")
reactive_schedule = Schedule.create(ws, name="MyReactiveSchedule", description="Based on input file change.",
pipeline_id=pipeline_id, experiment_name=experiment_name, datastore=datastore, data_path_parameter_name="input_data")
Nem kötelező argumentumok ütemezés létrehozásakor
A korábban tárgyalt argumentumokon kívül az argumentumot úgy is beállíthatja status , hogy "Disabled" inaktív ütemezést hozzon létre. Végül lehetővé continue_on_step_failure teszi egy logikai érték átadását, amely felülbírálja a folyamat alapértelmezett meghibásodási viselkedését.
Ütemezett folyamatok megtekintése
A webböngészőben keresse meg az Azure Machine Learninget. A navigációs panel Végpontok szakaszában válassza a Folyamatvégpontok lehetőséget. Ezzel a munkaterületen közzétett folyamatok listájára kerül.
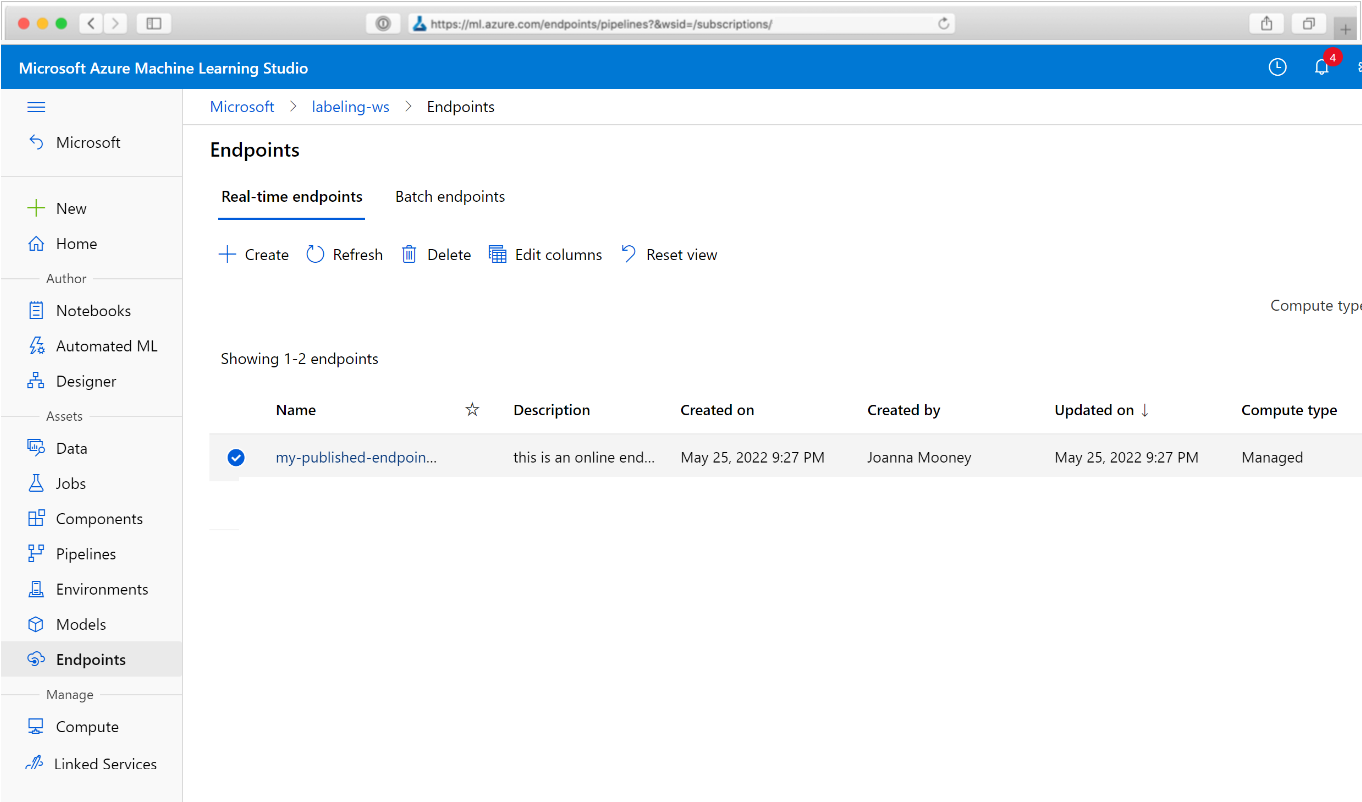
Ezen a lapon a munkaterület összes folyamatával kapcsolatos összefoglaló információk láthatók: nevek, leírások, állapot stb. Részletezés a folyamatba való kattintással. Az eredményül kapott lapon további részletek találhatók a folyamatról, és részletezheti az egyes feladatokat.
A folyamat inaktiválása
Ha közzétett Pipeline , de nem ütemezett, letilthatja a következőkkel:
pipeline = PublishedPipeline.get(ws, id=pipeline_id)
pipeline.disable()
Ha a folyamat ütemezve van, először le kell mondania az ütemezést. Kérje le az ütemezés azonosítóját a portálról vagy a következő futtatásával:
ss = Schedule.list(ws)
for s in ss:
print(s)
Miután megkapta a schedule_id letiltani kívánt beállítást, futtassa a következőt:
def stop_by_schedule_id(ws, schedule_id):
s = next(s for s in Schedule.list(ws) if s.id == schedule_id)
s.disable()
return s
stop_by_schedule_id(ws, schedule_id)
Ha ezután újra fut Schedule.list(ws) , üres listát kell kapnia.
Azure Logic Apps használata összetett triggerekhez
Összetettebb triggerszabályokat vagy viselkedést hozhat létre egy Azure Logic App használatával.
Ahhoz, hogy egy Azure Logic App aktiváljon egy Machine Learning-folyamatot, szüksége lesz a REST-végpontra egy közzétett Machine Learning-folyamathoz. Hozza létre és tegye közzé a folyamatot. Ezután keresse meg a REST-végpontot PublishedPipeline a folyamatazonosító használatával:
# You can find the pipeline ID in Azure Machine Learning studio
published_pipeline = PublishedPipeline.get(ws, id="<pipeline-id-here>")
published_pipeline.endpoint
Logikai alkalmazás létrehozása az Azure-ban
Most hozzon létre egy Azure Logic App-példányt. A logikai alkalmazás üzembe helyezése után az alábbi lépésekkel konfigurálhatja a folyamat eseményindítóját:
Hozzon létre egy rendszer által hozzárendelt felügyelt identitást , amely hozzáférést biztosít az alkalmazásnak az Azure Machine Learning-munkaterülethez.
Lépjen a Logic App Designer nézetre, és válassza az Üres logikai alkalmazás sablont.
A Tervezőben keresse meg a blobot. Válassza ki a Blob hozzáadása vagy módosítása (csak tulajdonságok) eseményindítót, és adja hozzá ezt az eseményindítót a logikai alkalmazáshoz.
Adja meg annak a Blob Storage-fióknak a kapcsolati adatait, amelyeket a blobok hozzáadásának vagy módosításának figyeléséhez szeretne figyelni. Válassza ki a monitorozni kívánt tárolót.
Válassza az Intervallum és gyakoriság lehetőséget az Ön számára megfelelő frissítések lekérdezéséhez.
Feljegyzés
Ez az eseményindító figyeli a kijelölt tárolót, de nem figyeli az almappákat.
Adjon hozzá egy HTTP-műveletet, amely egy új vagy módosított blob észlelésekor fog futni. Válassza az + Új lépés lehetőséget, majd keresse meg és válassza ki a HTTP-műveletet.
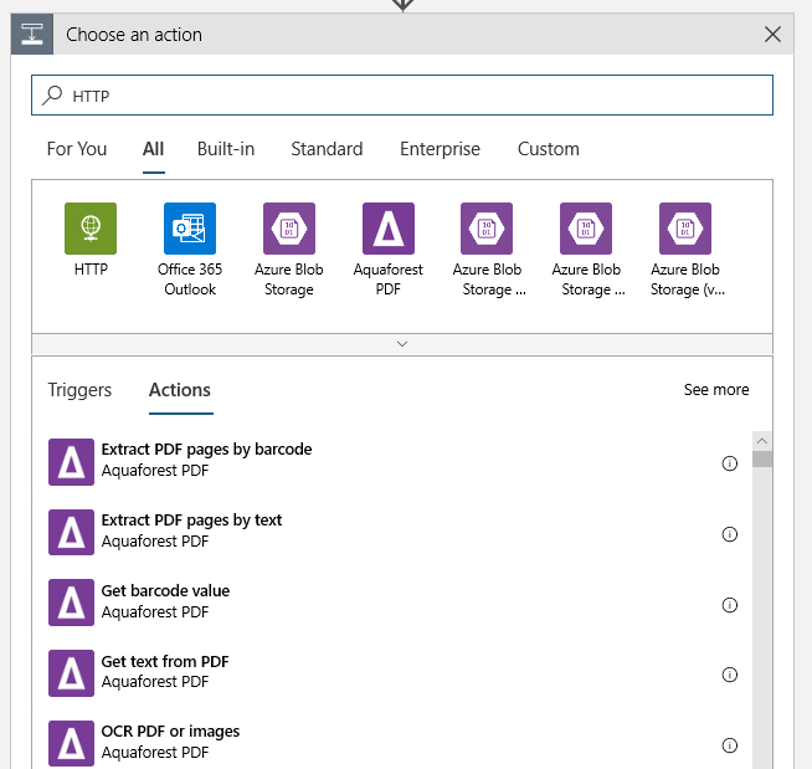
A művelet konfigurálásához használja az alábbi beállításokat:
| Beállítás | Érték |
|---|---|
| HTTP-művelet | POST |
| URI | az előfeltételként talált közzétett folyamat végpontja |
| Hitelesítési módszer | Felügyelt identitás |
Állítsa be az ütemezést az esetleges DataPath PipelineParameterek értékének beállításához:
{ "DataPathAssignments": { "input_datapath": { "DataStoreName": "<datastore-name>", "RelativePath": "@{triggerBody()?['Name']}" } }, "ExperimentName": "MyRestPipeline", "ParameterAssignments": { "input_string": "sample_string3" }, "RunSource": "SDK" }Használja előfeltételként a
DataStoreNamemunkaterülethez hozzáadottt.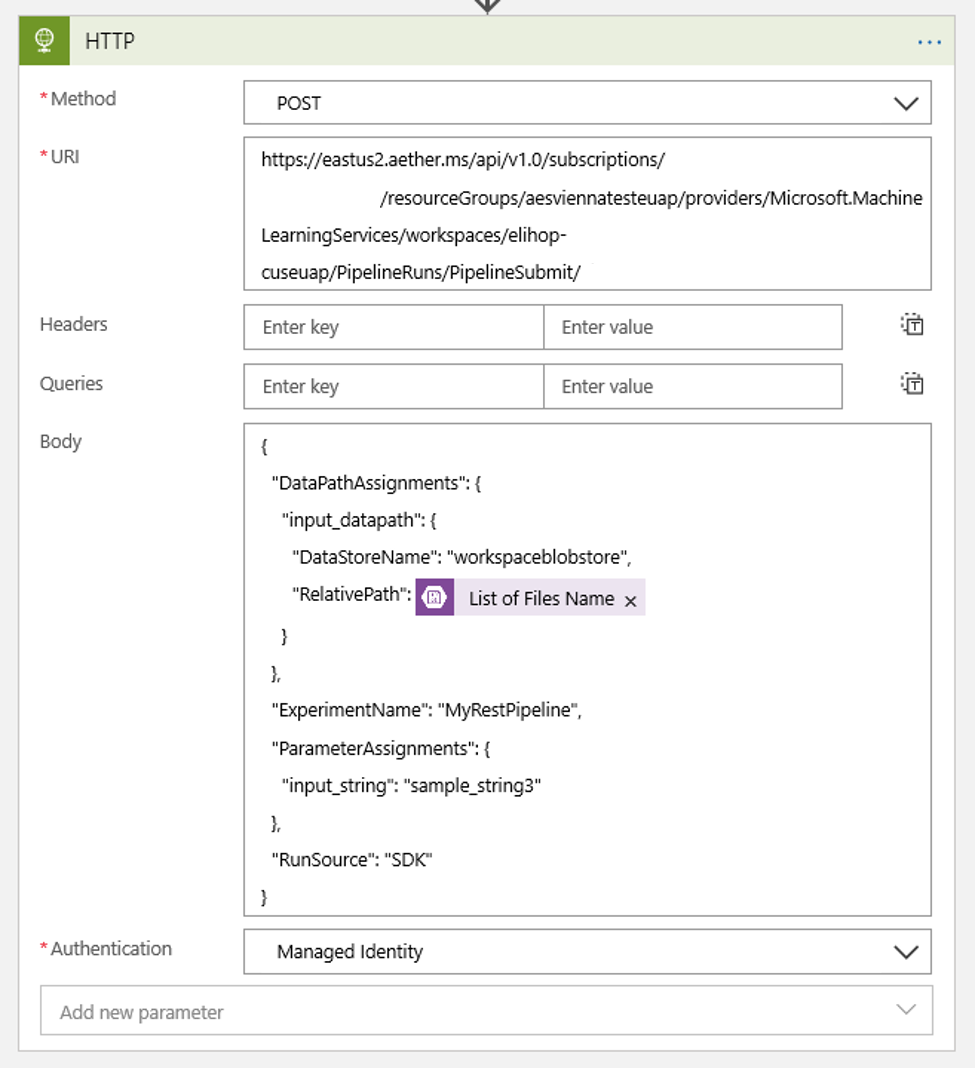
Válassza a Mentés lehetőséget, és az ütemezés készen áll.
Fontos
Ha azure-beli szerepköralapú hozzáférés-vezérlést (Azure RBAC) használ a folyamathoz való hozzáférés kezeléséhez, állítsa be a folyamatforgatókönyv engedélyeit (betanítás vagy pontozás).
Machine Learning-folyamatok meghívása Azure Data Factory-folyamatokból
Egy Azure Data Factory-folyamatban a Machine Learning Végrehajtási folyamat egy Azure Machine Learning-folyamatot futtat. Ezt a tevékenységet a Data Factory szerzői lapján, a Machine Learning kategóriában találja:
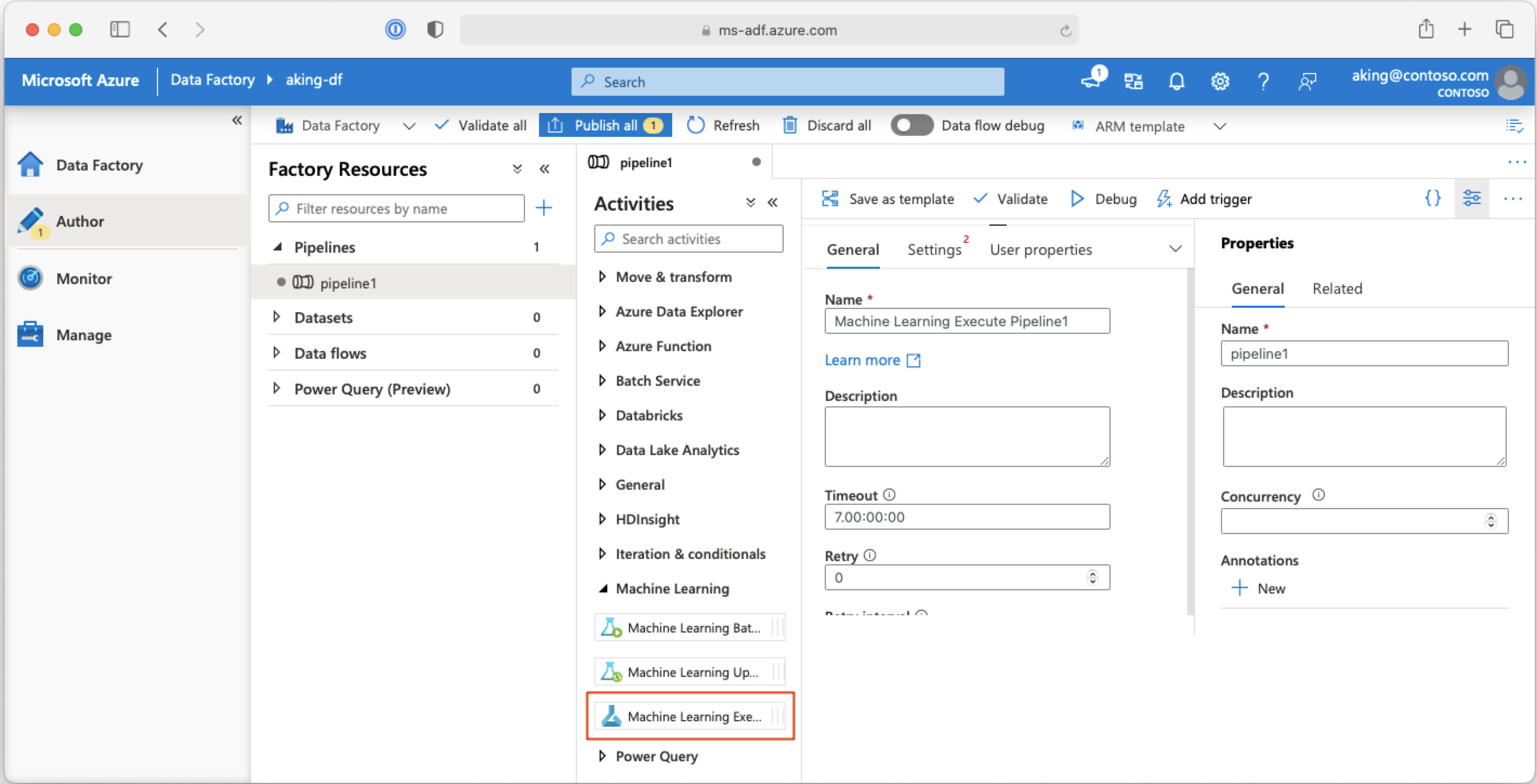
Következő lépések
Ebben a cikkben a Pythonhoz készült Azure Machine Learning SDK-val ütemezte a folyamatokat két különböző módon. Egy ütemezés ismétlődik az eltelt idő alapján. A többi ütemezési feladat, ha egy fájlt módosítanak egy megadott Datastore vagy az adott tár egyik könyvtárában. Látta, hogyan használhatja a portált a folyamat és az egyes feladatok vizsgálatára. Megtanulta, hogyan tilthat le egy ütemezést, hogy a folyamat ne fusson. Végül létrehozott egy Azure Logic App-alkalmazást egy folyamat aktiválásához.
További információk: