Modell hiperparaméter-finomhangolása (v2)
ÉRVÉNYES: Azure CLI ml-bővítmény v2 (aktuális)Python SDK azure-ai-ml v2 (aktuális)
Azure CLI ml-bővítmény v2 (aktuális)Python SDK azure-ai-ml v2 (aktuális)
Automatizálja a hatékony hiperparaméter-finomhangolást az Azure Machine Learning SDK v2 és CLI v2 használatával a SweepJob típussal.
- A próbaparaméter keresési helyének meghatározása
- A takarítási feladat mintavételezési algoritmusának megadása
- Adja meg az optimalizálni kívánt célt
- Korai megszüntetési szabályzat megadása alacsony teljesítményű feladatokhoz
- A takarítási feladat korlátainak meghatározása
- Kísérlet indítása a megadott konfigurációval
- A betanítási feladatok megjelenítése
- Válassza ki a modellhez legjobb konfigurációt
Mi a hiperparaméter finomhangolása?
A hiperparaméterek állítható paraméterek, amelyek lehetővé teszik a modell betanítási folyamatának szabályozását. Neurális hálózatok esetén például ön dönti el a rejtett rétegek számát és az egyes rétegek csomópontjainak számát. A modell teljesítménye nagymértékben függ a hiperparamétertől.
A hiperparaméter-finomhangolás, más néven hiperparaméter-optimalizálás a legjobb teljesítményt eredményező hiperparaméterek konfigurációjának megkeresése. A folyamat általában számítási szempontból költséges és manuális.
Az Azure Machine Learning lehetővé teszi a hiperparaméterek hangolásának automatizálását és kísérletek párhuzamos futtatását a hiperparaméterek hatékony optimalizálása érdekében.
A keresési terület meghatározása
A hiperparaméterek finomhangolása az egyes hiperparaméterekhez definiált értékek tartományának feltárásával.
A hiperparaméterek lehetnek különállóak vagy folyamatosak, és egy paraméterkifejezés által leírt értékek eloszlásával rendelkezik.
Diszkrét hiperparaméterek
A különálló hiperparaméterek a különálló értékek között vannak megadva Choice . Choice lehet:
- egy vagy több vesszővel tagolt érték
- objektum
range listtetszőleges objektum
from azure.ai.ml.sweep import Choice
command_job_for_sweep = command_job(
batch_size=Choice(values=[16, 32, 64, 128]),
number_of_hidden_layers=Choice(values=range(1,5)),
)
Ebben az esetben batch_size az egyik érték [16, 32, 64, 128] és number_of_hidden_layers az egyik érték [1, 2, 3, 4].
A következő speciális diszkrét hiperparaméterek is megadhatóak eloszlás használatával:
QUniform(min_value, max_value, q)- Olyan értéket ad vissza, mint a round(Uniform(min_value, max_value) / q) * qQLogUniform(min_value, max_value, q)- Olyan értéket ad vissza, mint a round(exp(Uniform(min_value, max_value)) / q) * qQNormal(mu, sigma, q)- Olyan értéket ad vissza, mint a round(Normal(mu, sigma) /q) * qQLogNormal(mu, sigma, q)- Olyan értéket ad vissza, mint a round(exp(Normal(mu, sigma)) / q) * q
Folyamatos hiperparaméterek
A folyamatos hiperparaméterek eloszlásként vannak megadva folyamatos értéktartományon keresztül:
Uniform(min_value, max_value)- A min_value és a max_value között egyenletesen elosztott értéket ad visszaLogUniform(min_value, max_value)- Az exp(Uniform(min_value, max_value)) szerint rajzolt értéket ad vissza, hogy a visszatérési érték logaritmusa egységesen el legyen osztvaNormal(mu, sigma)- Olyan valós értéket ad vissza, amely normál esetben a középértékkel és a szórási szigmával van elosztvaLogNormal(mu, sigma)- Az exp(Normal(mu, sigma)) szerint rajzolt értéket ad vissza, hogy a visszatérési érték logaritmusa normál eloszlású legyen
Példa egy paramétertérdefinícióra:
from azure.ai.ml.sweep import Normal, Uniform
command_job_for_sweep = command_job(
learning_rate=Normal(mu=10, sigma=3),
keep_probability=Uniform(min_value=0.05, max_value=0.1),
)
Ez a kód egy keresési területet határoz meg két paraméterrel – learning_rate és keep_probability. learning_rate normális eloszlása 10 középértékkel és 3 szórással rendelkezik. keep_probability egységes eloszlása legalább 0,05 értékkel és 0,1 maximális értékkel rendelkezik.
A parancssori felülethez használhatja a takarítási feladat YAML-sémáját, hogy meghatározza a keresési területet a YAML-ben:
search_space:
conv_size:
type: choice
values: [2, 5, 7]
dropout_rate:
type: uniform
min_value: 0.1
max_value: 0.2
A hiperparaméter helyének mintavételezése
Adja meg a hiperparaméter-térben használandó paraméter-mintavételezési módszert. Az Azure Machine Learning a következő módszereket támogatja:
- Véletlenszerű mintavételezés
- Rácsos mintavételezés
- Bayes-féle mintavételezés
Véletlenszerű mintavételezés
A véletlenszerű mintavételezés támogatja a különálló és folyamatos hiperparamétereket. Támogatja az alacsony teljesítményű feladatok korai megszüntetését. Egyes felhasználók véletlenszerű mintavételezéssel végeznek kezdeti keresést, majd finomítják a keresési területet a találatok javítása érdekében.
Véletlenszerű mintavételezés esetén a rendszer véletlenszerűen választja ki a hiperparaméter-értékeket a megadott keresési területről. A parancsfeladat létrehozása után a takarítási paraméter használatával definiálhatja a mintavételezési algoritmust.
from azure.ai.ml.sweep import Normal, Uniform, RandomParameterSampling
command_job_for_sweep = command_job(
learning_rate=Normal(mu=10, sigma=3),
keep_probability=Uniform(min_value=0.05, max_value=0.1),
batch_size=Choice(values=[16, 32, 64, 128]),
)
sweep_job = command_job_for_sweep.sweep(
compute="cpu-cluster",
sampling_algorithm = "random",
...
)
Sobol
A Sobol a véletlenszerű mintavételezés egy típusa, amelyet a takarítási feladatok típusai támogatnak. A sobol használatával reprodukálhatja az eredményeket a mag használatával, és egyenletesebben fedheti le a keresési területek eloszlását.
A sobol használatához használja a RandomParameterSampling osztályt a mag és a szabály hozzáadásához az alábbi példában látható módon.
from azure.ai.ml.sweep import RandomParameterSampling
sweep_job = command_job_for_sweep.sweep(
compute="cpu-cluster",
sampling_algorithm = RandomParameterSampling(seed=123, rule="sobol"),
...
)
Rácsos mintavételezés
A rácsos mintavételezés támogatja a különálló hiperparamétereket. Használjon rácsos mintavételezést, ha költségvetéssel teljes mértékben kereshet a keresési területen. Támogatja az alacsony teljesítményű feladatok korai megszüntetését.
A rács mintavételezése egyszerű rácskeresést végez az összes lehetséges értéken. A rácsos mintavételezés csak hiperparaméterekkel choice használható. A következő tér például hat mintával rendelkezik:
from azure.ai.ml.sweep import Choice
command_job_for_sweep = command_job(
batch_size=Choice(values=[16, 32]),
number_of_hidden_layers=Choice(values=[1,2,3]),
)
sweep_job = command_job_for_sweep.sweep(
compute="cpu-cluster",
sampling_algorithm = "grid",
...
)
Bayes-féle mintavételezés
A Bayes-mintavételezés a bayesi optimalizálási algoritmuson alapul. A korábbi minták alapján választja ki a mintákat, így az új minták javítják az elsődleges metrikát.
A Bayes-mintavételezést akkor javasoljuk, ha elegendő költségvetése van a hiperparaméter-tér felfedezéséhez. A legjobb eredmény érdekében a finomhangolt hiperparaméterek számának 20-szorosánál nagyobb vagy egyenlő feladatok maximális számát javasoljuk.
Az egyidejű feladatok száma hatással van a finomhangolási folyamat hatékonyságára. Az egyidejű feladatok kisebb száma jobb mintavételezési konvergenciához vezethet, mivel a kisebb mértékű párhuzamosság növeli a korábban befejezett feladatok előnyeit élvező feladatok számát.
A Bayes-mintavételezés csak a keresési területen belüli eloszlásokat támogatjachoiceuniformquniform.
from azure.ai.ml.sweep import Uniform, Choice
command_job_for_sweep = command_job(
learning_rate=Uniform(min_value=0.05, max_value=0.1),
batch_size=Choice(values=[16, 32, 64, 128]),
)
sweep_job = command_job_for_sweep.sweep(
compute="cpu-cluster",
sampling_algorithm = "bayesian",
...
)
A takarítás céljának meghatározása
Határozza meg a takarítási feladat célját az optimalizálni kívánt elsődleges metrika és cél megadásával. A rendszer minden betanítási feladatot kiértékel az elsődleges metrika alapján. A korai megszüntetési szabályzat az elsődleges metrikával azonosítja az alacsony teljesítményű feladatokat.
primary_metric: Az elsődleges metrika nevének pontosan meg kell egyeznie a betanítási szkript által naplózott metrika nevévelgoal: A feladatok kiértékelésekor azMaximizeMinimizeelsődleges metrika maximalizálható vagy minimalizálható.
from azure.ai.ml.sweep import Uniform, Choice
command_job_for_sweep = command_job(
learning_rate=Uniform(min_value=0.05, max_value=0.1),
batch_size=Choice(values=[16, 32, 64, 128]),
)
sweep_job = command_job_for_sweep.sweep(
compute="cpu-cluster",
sampling_algorithm = "bayesian",
primary_metric="accuracy",
goal="Maximize",
)
Ez a minta maximalizálja a "pontosságot".
Naplómetrikák hiperparaméter-finomhangoláshoz
A modell betanítási szkriptjének ugyanazzal a metrikanévvel kell naplóznia az elsődleges metrikát a modell betanítása során, hogy a SweepJob hozzáférhessen a hiperparaméter-finomhangoláshoz.
Naplózza az elsődleges metrikát a betanítási szkriptben a következő mintarészlettel:
import mlflow
mlflow.log_metric("accuracy", float(val_accuracy))
A betanítási szkript kiszámítja és val_accuracy naplózza a "pontosság" elsődleges metrikaként. Minden alkalommal, amikor a metrikát naplózza, a hiperparaméter-finomhangolási szolgáltatás fogadja. Ön határozza meg a jelentés gyakoriságát.
A betanítási feladatok naplózási értékeiről további információt az Azure Machine Learning-betanítási feladatok naplózásának engedélyezése című témakörben talál.
Korai megszüntetési szabályzat megadása
Automatikusan befejezi a rosszul teljesítő feladatokat egy korai felmondási szabályzattal. A korai megszüntetés javítja a számítási hatékonyságot.
A szabályzat alkalmazásakor a következő paramétereket konfigurálhatja:
evaluation_interval: a szabályzat alkalmazásának gyakorisága. Minden alkalommal, amikor a betanítási szkript naplózza az elsődleges metrikák számát egy intervallumként. Azevaluation_interval1-ből egy minden alkalommal alkalmazza a szabályzatot, amikor a betanítási szkript az elsődleges metrikát jelenti. A 2-ből egyevaluation_intervalminden második alkalommal alkalmazza a szabályzatot. Ha nincs megadva,evaluation_intervalalapértelmezés szerint 0 értékre van állítva.delay_evaluation: késlelteti az első szabályzat kiértékelését egy megadott számú időköz esetén. Ez egy opcionális paraméter, amely elkerüli a betanítási feladatok idő előtti leállítását azáltal, hogy lehetővé teszi az összes konfiguráció minimális számú időköz futtatását. Ha meg van adva, a szabályzat a delay_evaluation nagyobb vagy egyenlő evaluation_interval minden többszörösét alkalmazza. Ha nincs megadva,delay_evaluationalapértelmezés szerint 0 értékre van állítva.
Az Azure Machine Learning a következő korai megszüntetési szabályzatokat támogatja:
- Bandit szabályzat
- Medián-leállítási szabályzat
- Csonkítás kiválasztási szabályzata
- Nincs felmondási szabályzat
Bandit szabályzat
A bandit szabályzat a tartalékidő-tényezőn/tartalékidőn és a kiértékelési időközön alapul. A bandit szabályzat akkor fejeződik be egy feladattal, ha az elsődleges metrika nem a legsikeresebb feladat megadott tartalékidő-/tartalékidő-mennyiségén belül van.
Adja meg a következő konfigurációs paramétereket:
slack_factorvagyslack_amount: a legjobban teljesítő betanítási feladat tekintetében engedélyezett tartalékidő.slack_factora megengedett tartalékidőt adja meg arányként.slack_amounta megengedett tartalékidőt abszolút összegként adja meg az arány helyett.Vegyük például a 10. intervallumban alkalmazott Bandit-szabályzatot. Tegyük fel, hogy a 10. intervallumban a legjobban teljesítő feladat egy elsődleges metrika 0,8, amelynek célja az elsődleges metrika maximalizálása. Ha a szabályzat 0,2 értéket ad meg
slack_factor, a rendszer leáll minden olyan betanítási feladat, amelynek legjobb metrikája 10-nél kisebb, mint 0,66 (0,8/(1+slack_factor)).evaluation_interval: (nem kötelező) a szabályzat alkalmazásának gyakoriságadelay_evaluation: (nem kötelező) késlelteti az első szabályzat kiértékelését egy megadott számú időköz esetén
from azure.ai.ml.sweep import BanditPolicy
sweep_job.early_termination = BanditPolicy(slack_factor = 0.1, delay_evaluation = 5, evaluation_interval = 1)
Ebben a példában a korai megszüntetési szabályzatot a rendszer minden időközönként alkalmazza a metrikák jelentésekor, az 5. kiértékelési időköztől kezdve. Minden olyan feladat megszűnik, amelynek legjobb metrikája kisebb, mint (1/(1+0,1) vagy a legjobban teljesítő feladatok 91%-a.
Medián-leállítási szabályzat
A medián-leállítás egy korai megszüntetési szabályzat, amely a feladatok által jelentett elsődleges metrikák átlagán alapul. Ez a szabályzat az összes betanítási feladat átlagát számítja ki, és leállítja azokat a feladatokat, amelyek elsődleges metrikaértéke rosszabb, mint az átlagok mediánja.
Ez a szabályzat a következő konfigurációs paramétereket használja:
evaluation_interval: a szabályzat alkalmazásának gyakorisága (opcionális paraméter).delay_evaluation: késlelteti az első szabályzat kiértékelését egy megadott számú intervallumra (nem kötelező paraméter).
from azure.ai.ml.sweep import MedianStoppingPolicy
sweep_job.early_termination = MedianStoppingPolicy(delay_evaluation = 5, evaluation_interval = 1)
Ebben a példában a korai megszüntetési szabályzat minden 5. kiértékelési időköztől kezdve minden intervallumban érvényesül. A feladat leállítása 5- időközzel történik, ha a legjobb elsődleges metrika rosszabb, mint a futó átlag mediánja az összes betanítási feladat 1:5-ös időközével.
Csonkítás kiválasztási szabályzata
A csonkolás kiválasztása az egyes kiértékelési időközökben a legalacsonyabb teljesítményt nyújtó feladatok százalékos arányát törli. A feladatok összehasonlítása az elsődleges metrikával történik.
Ez a szabályzat a következő konfigurációs paramétereket használja:
truncation_percentage: a legalacsonyabb teljesítményt nyújtó feladatok százalékos aránya az egyes kiértékelési időszakokban. 1 és 99 közötti egész szám.evaluation_interval: (nem kötelező) a szabályzat alkalmazásának gyakoriságadelay_evaluation: (nem kötelező) késlelteti az első szabályzat kiértékelését egy megadott számú időköz eseténexclude_finished_jobs: megadja, hogy kizárja-e a befejezett feladatokat a szabályzat alkalmazásakor
from azure.ai.ml.sweep import TruncationSelectionPolicy
sweep_job.early_termination = TruncationSelectionPolicy(evaluation_interval=1, truncation_percentage=20, delay_evaluation=5, exclude_finished_jobs=true)
Ebben a példában a korai megszüntetési szabályzat minden 5. kiértékelési időköztől kezdve minden intervallumban érvényesül. A feladatok 5. időközzel fejeződnek be, ha az 5. időközi teljesítmény az 5. intervallumban az összes feladat teljesítményének legalacsonyabb 20%-ában van, és kizárja a befejezett feladatokat a szabályzat alkalmazásakor.
Nincs felmondási szabályzat (alapértelmezett)
Ha nincs megadva szabályzat, a hiperparaméter-finomhangolási szolgáltatás lehetővé teszi az összes betanítási feladat végrehajtását.
sweep_job.early_termination = None
Korai felmondási szabályzat kiválasztása
- Az ígéretes feladatok megszüntetése nélkül megtakarítást biztosító konzervatív szabályzatok esetében fontolja meg az 1-5-ös
evaluation_intervaldelay_evaluationmedián leállási szabályzatot. Ezek olyan konzervatív beállítások, amelyek körülbelül 25–35%-os megtakarítást biztosítanak az elsődleges metrika vesztesége nélkül (a kiértékelési adatok alapján). - Az agresszívebb megtakarítás érdekében használja a Bandit Policyt kisebb engedélyezett tartalékidővel vagy csonkolási kijelölési szabályzattal nagyobb csonkítási százalékkal.
A takarítási feladat korlátainak beállítása
A takarítási feladat korlátainak beállításával szabályozhatja az erőforrás-költségvetést.
max_total_trials: Próbafeladatok maximális száma. 1 és 1000 közötti egész számnak kell lennie.max_concurrent_trials: (nem kötelező) Az egyidejűleg futtatható próbafeladatok maximális száma. Ha nincs megadva, max_total_trials feladatok száma párhuzamosan indul el. Ha meg van adva, 1 és 1000 közötti egész számnak kell lennie.timeout: Maximális idő másodpercben a teljes takarítási feladat futtatására engedélyezett. A korlát elérése után a rendszer megszakítja a takarítási feladatot, beleértve az összes próbaverzióját is.trial_timeout: Az egyes próbafeladatok futtatásának maximális időtartama másodpercben. A korlát elérése után a rendszer megszakítja a próbaverziót.
Feljegyzés
Ha max_total_trials és időtúllépés is meg van adva, a hiperparaméter-finomhangolási kísérlet a két küszöbérték közül az első elérésekor fejeződik be.
Feljegyzés
Az egyidejű próbafeladatok száma a megadott számítási célban elérhető erőforrásokon van meghatározva. Győződjön meg arról, hogy a számítási cél rendelkezik a kívánt egyidejűséghez elérhető erőforrásokkal.
sweep_job.set_limits(max_total_trials=20, max_concurrent_trials=4, timeout=1200)
Ez a kód úgy konfigurálja a hiperparaméter-finomhangolási kísérletet, hogy legfeljebb 20 próbafeladatot használjon, és egyszerre négy próbafeladatot futtasson 1200 másodperces időtúllépéssel a teljes takarítási feladathoz.
Hiperparaméter-finomhangolási kísérlet konfigurálása
A hiperparaméter-finomhangolási kísérlet konfigurálásához adja meg a következőket:
- A definiált hiperparaméter keresési területe
- A mintavételezési algoritmus
- A korai felmondási szabályzat
- Az Ön célja
- Erőforráskorlátok
- CommandJob vagy CommandComponent
- Takarítási feladat
A SweepJob hiperparaméteres takarítást futtathat a parancs- vagy parancsösszetevőn.
Feljegyzés
A használt sweep_job számítási célnak elegendő erőforrással kell rendelkeznie az egyidejűségi szint kielégítéséhez. A számítási célokról további információt a Számítási célok című témakörben talál.
Konfigurálja a hiperparaméter finomhangolási kísérletét:
from azure.ai.ml import MLClient
from azure.ai.ml import command, Input
from azure.ai.ml.sweep import Choice, Uniform, MedianStoppingPolicy
from azure.identity import DefaultAzureCredential
# Create your base command job
command_job = command(
code="./src",
command="python main.py --iris-csv ${{inputs.iris_csv}} --learning-rate ${{inputs.learning_rate}} --boosting ${{inputs.boosting}}",
environment="AzureML-lightgbm-3.2-ubuntu18.04-py37-cpu@latest",
inputs={
"iris_csv": Input(
type="uri_file",
path="https://azuremlexamples.blob.core.windows.net/datasets/iris.csv",
),
"learning_rate": 0.9,
"boosting": "gbdt",
},
compute="cpu-cluster",
)
# Override your inputs with parameter expressions
command_job_for_sweep = command_job(
learning_rate=Uniform(min_value=0.01, max_value=0.9),
boosting=Choice(values=["gbdt", "dart"]),
)
# Call sweep() on your command job to sweep over your parameter expressions
sweep_job = command_job_for_sweep.sweep(
compute="cpu-cluster",
sampling_algorithm="random",
primary_metric="test-multi_logloss",
goal="Minimize",
)
# Specify your experiment details
sweep_job.display_name = "lightgbm-iris-sweep-example"
sweep_job.experiment_name = "lightgbm-iris-sweep-example"
sweep_job.description = "Run a hyperparameter sweep job for LightGBM on Iris dataset."
# Define the limits for this sweep
sweep_job.set_limits(max_total_trials=20, max_concurrent_trials=10, timeout=7200)
# Set early stopping on this one
sweep_job.early_termination = MedianStoppingPolicy(
delay_evaluation=5, evaluation_interval=2
)
A command_job függvényt függvénynek nevezzük, így a paraméterkifejezéseket alkalmazhatjuk a takarítási bemenetekre. A sweep függvény ezután konfigurálva van a következővel trial: , sampling-algorithm, objective, limitsés compute. A fenti kódrészletet a parancson vagy CommandComponenten futó hiperparaméteres takarítás mintajegyzetfüzetből vettük. Ebben a mintában a paraméterek és boosting a learning_rate paraméterek hangolva vannak. A feladatok korai leállítását egy MedianStoppingPolicyolyan feladat határozza meg, amelynek elsődleges metrikaértéke rosszabb, mint az összes betanítási feladat átlagának mediánja.( lásd : MedianStoppingPolicy osztályhivatkozás).
A paraméterértékek fogadásának, elemzésének és a hangolandó betanítási szkriptnek való átadásának megtekintéséhez tekintse meg ezt a kódmintát
Fontos
Minden hiperparaméteres takarítási feladat az alapoktól újraindítja a betanítást, beleértve a modell és az összes adatbetöltő újraépítését. Ezt a költséget minimalizálhatja egy Azure Machine Learning-folyamat vagy manuális folyamat használatával, hogy a lehető legtöbb adatelőkészítést végezze el a betanítási feladatok előtt.
Hiperparaméter-finomhangolási kísérlet elküldése
A hiperparaméter finomhangolási konfigurációjának megadása után küldje el a feladatot:
# submit the sweep
returned_sweep_job = ml_client.create_or_update(sweep_job)
# get a URL for the status of the job
returned_sweep_job.services["Studio"].endpoint
Hiperparaméter-finomhangolási feladatok vizualizációja
Az Azure Machine Learning Studióban megjelenítheti az összes hiperparaméter-finomhangolási feladatot. A kísérlet portálon való megtekintéséről további információt a feladatrekordok megtekintése a stúdióban című témakörben talál.
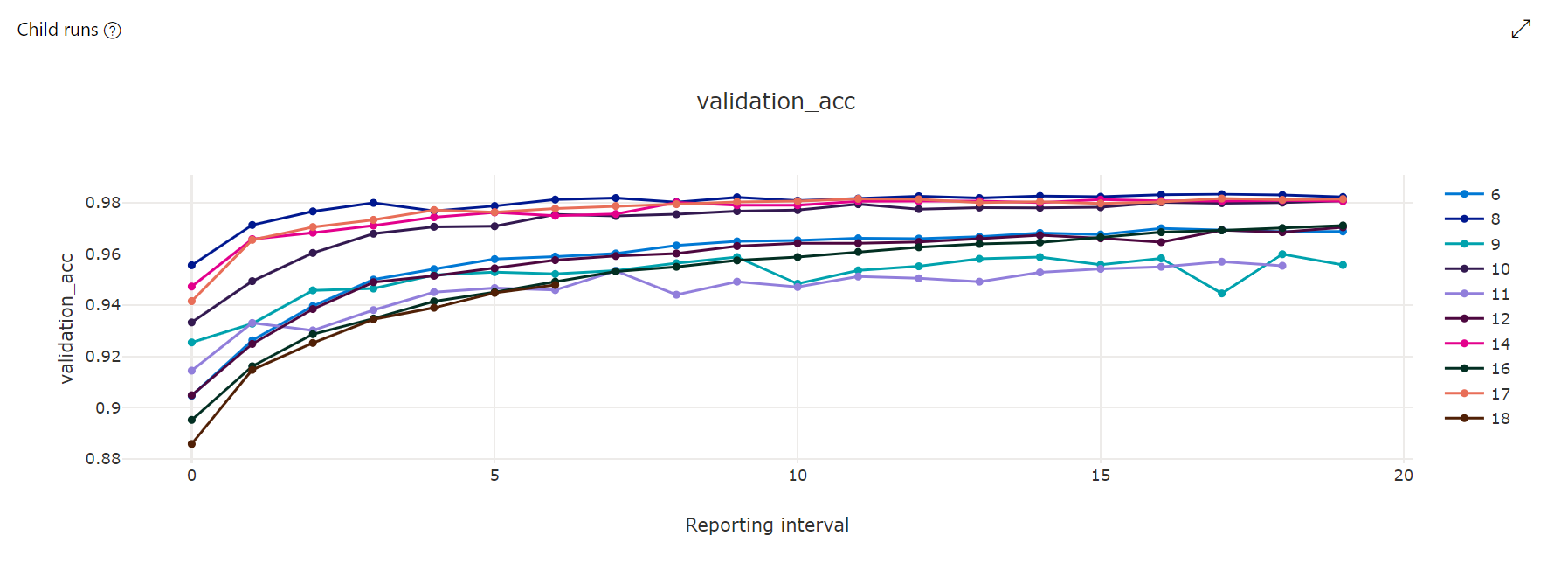
Metrikák diagramja: Ez a vizualizáció nyomon követi az egyes hyperdrive-gyermekfeladatokhoz naplózott metrikákat a hiperparaméter finomhangolásának időtartama alatt. Minden sor egy gyermekfeladatot jelöl, és minden pont a futtatókörnyezet adott iterációjában méri az elsődleges metrikaértéket.
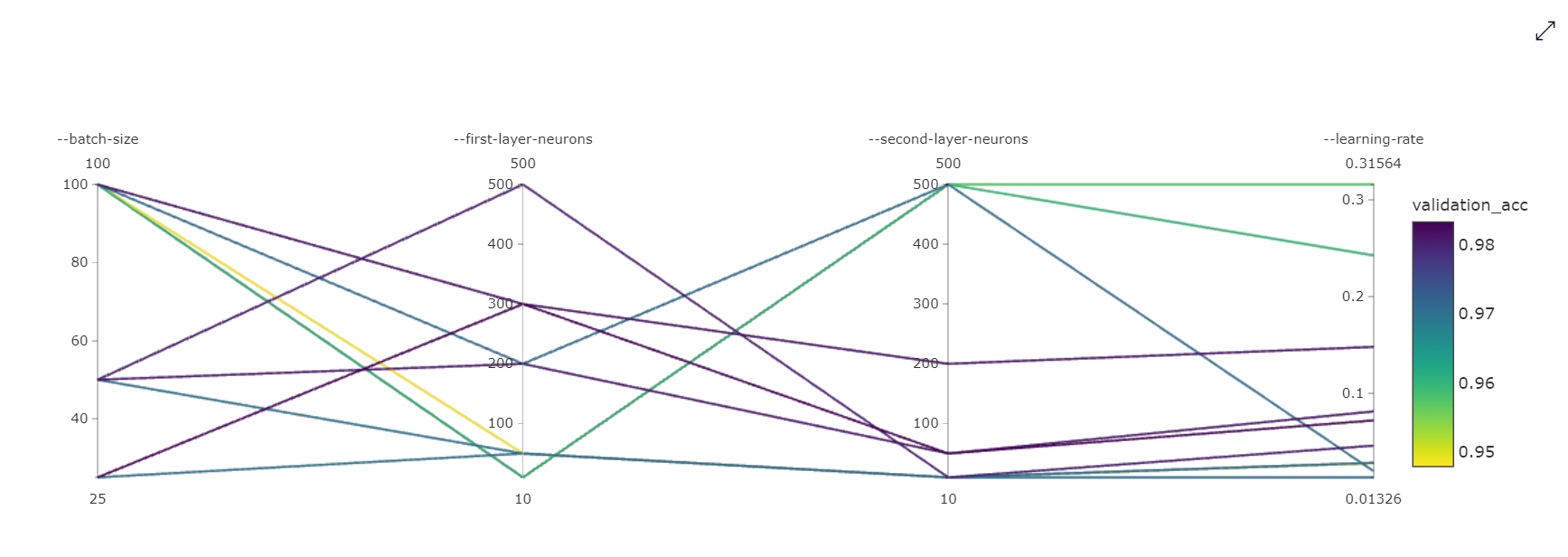
Párhuzamos koordináták diagramja: Ez a vizualizáció az elsődleges metrika teljesítménye és az egyes hiperparaméter-értékek közötti korrelációt mutatja be. A diagram interaktív a tengelyek mozgásával (a tengelyfelirat kijelölésével és húzásával), valamint az értékek egyetlen tengelyen való kiemelésével (egyetlen tengelyen függőlegesen húzva kiemelheti a kívánt értékek tartományát). A párhuzamos koordináták diagramja a diagram jobb szélső részén található tengelyt tartalmazza, amely az adott feladatpéldányhoz beállított hiperparamétereknek megfelelő legjobb metrikaértéket ábrázolja. Ez a tengely azért van megadva, hogy a diagram színátmeneti jelmagyarázatát olvashatóbb módon kivetítse az adatokra.
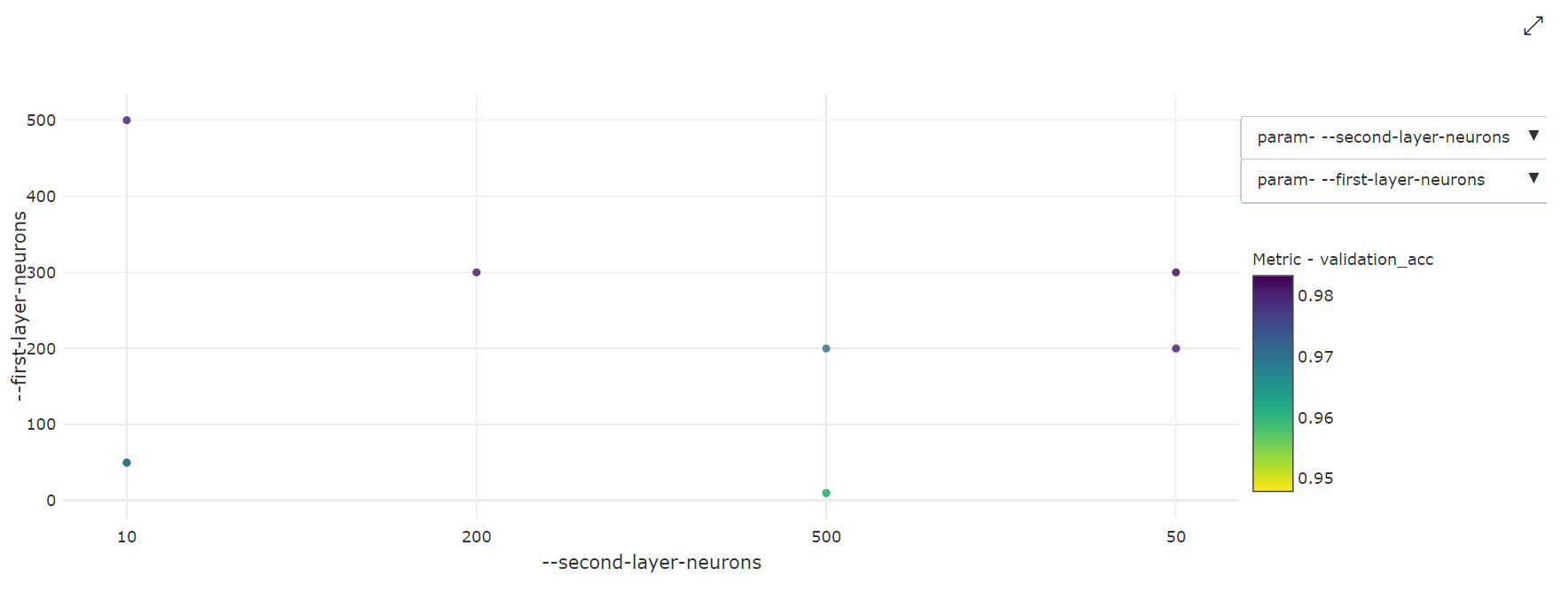
Kétdimenziós pontdiagram: Ez a vizualizáció a két egyedi hiperparaméter és a hozzájuk tartozó elsődleges metrikaérték közötti korrelációt jeleníti meg.
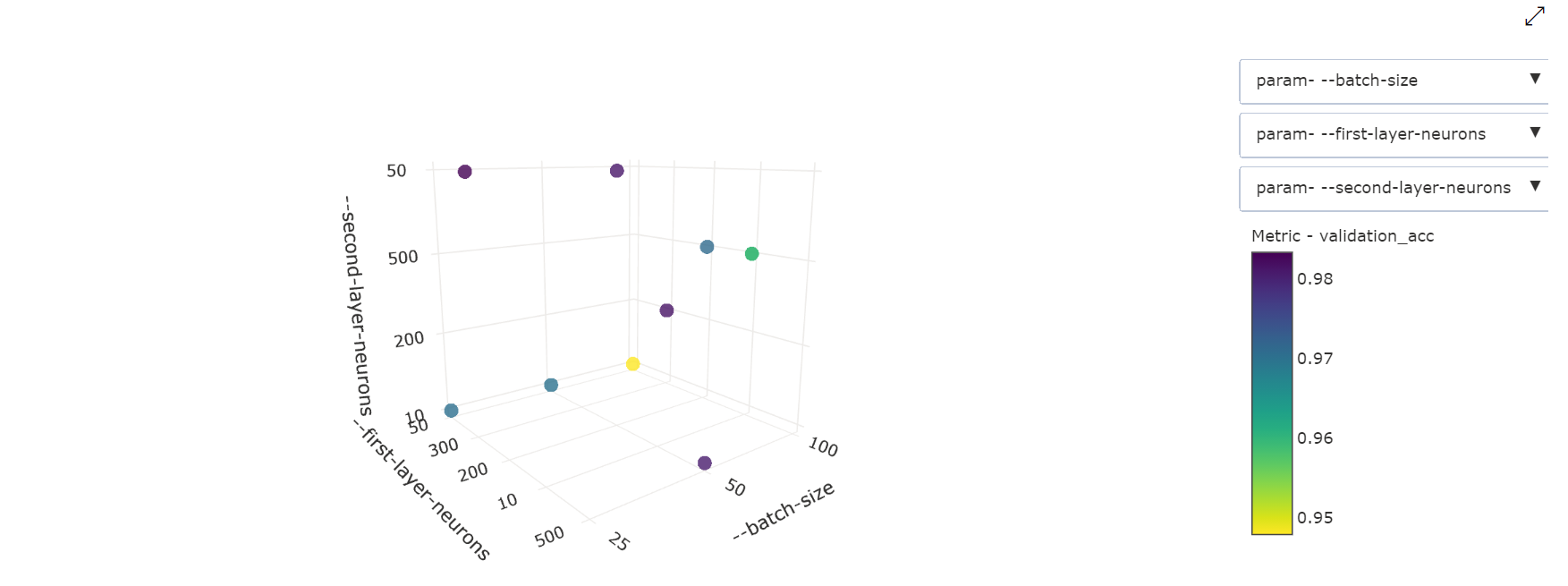
Háromdimenziós pontdiagram: Ez a vizualizáció megegyezik a 2D-vel, de lehetővé teszi a korreláció három hiperparaméter-dimenzióját az elsődleges metrikaértékkel. A diagramot úgy is kijelölheti és húzhatja át, hogy a térközön belül különböző korrelációkat jelenítsen meg.
A legjobb próbafeladat megkeresése
Miután az összes hiperparaméter-finomhangolási feladat befejeződött, kérje le a legjobb próbakimeneteket:
# Download best trial model output
ml_client.jobs.download(returned_sweep_job.name, output_name="model")
A parancssori felülettel letöltheti a legjobb próbafeladat összes alapértelmezett és elnevezett kimenetét, valamint a takarítási feladat naplóit.
az ml job download --name <sweep-job> --all
Opcionálisan a legjobb próbaverziós kimenet letöltése
az ml job download --name <sweep-job> --output-name model