Kötegelt végpontok futtatása az Azure Data Factoryből
ÉRVÉNYES: Azure CLI ml-bővítmény v2 (aktuális)Python SDK azure-ai-ml v2 (aktuális)
Azure CLI ml-bővítmény v2 (aktuális)Python SDK azure-ai-ml v2 (aktuális)
A big data olyan szolgáltatást igényel, amely képes folyamatok vezénylésére és üzembe helyezésére a nyers adatok hatalmas tárolóinak végrehajtható üzleti elemzésekké való finomításához. Az Azure Data Factory által felügyelt felhőszolgáltatás kezeli ezeket az összetett hibrid extract-transform-load (ETL), a extract-load-transform (ELT) és az adatintegrációs projekteket.
Az Azure Data Factory lehetővé teszi olyan folyamatok létrehozását, amelyek több adatátalakítás vezénylésére és egyetlen egységként való kezelésére képesek. A Batch-végpontok kiválóan alkalmasak arra, hogy az ilyen feldolgozási munkafolyamatok egyik lépésévé váljanak.
Ebből a cikkből megtudhatja, hogyan használhat kötegelt végpontokat az Azure Data Factory-tevékenységekben a webes meghívási tevékenységre és a REST API-ra támaszkodva.
Tipp.
Amikor adatfolyamokat használ a Fabricben, közvetlenül az Azure Machine Learning-tevékenységgel hívhatja meg a kötegvégpontot. Javasoljuk, hogy amikor csak lehetséges, használja a Fabricet az adatvezényléshez, hogy kihasználhassa a legújabb képességeket. Az Azure Data Factory Azure Machine Learning-tevékenysége csak az Azure Machine Learning V1-ből származó eszközökkel használható. További információ: Azure Machine Learning-modellek futtatása a Fabricből kötegelt végpontok (előzetes verzió) használatával.
Előfeltételek
Batch-végpontként üzembe helyezett modell. Használja a kötegtelepítésekben az MLflow-modellek használatával létrehozott szívállapot-osztályozót.
Egy Azure Data Factory-erőforrás. Adat-előállító létrehozásához kövesse a gyorsútmutató lépéseit : Adat-előállító létrehozása az Azure Portal használatával.
Az adat-előállító létrehozása után keresse meg az Azure Portalon, és válassza a Launch studio (Stúdió indítása) lehetőséget:


Hitelesítés kötegelt végpontokon
Az Azure Data Factory a webes meghívási tevékenység használatával meghívhatja a kötegelt végpontok REST API-jait. A Batch-végpontok támogatják a Microsoft Entra-azonosítót az engedélyezéshez, és az API-knak küldött kérések megfelelő hitelesítést igényelnek. További információ: Webes tevékenység az Azure Data Factoryben és az Azure Synapse Analyticsben.
Szolgáltatásnévvel vagy felügyelt identitással végezhet hitelesítést kötegelt végpontokon. Azt javasoljuk, hogy felügyelt identitást használjon, mert leegyszerűsíti a titkos kódok használatát.
Az Azure Data Factory által felügyelt identitással kommunikálhat a kötegvégpontokkal. Ebben az esetben csak azt kell meggyőződnie, hogy az Azure Data Factory-erőforrás felügyelt identitással lett üzembe helyezve.
Ha nem rendelkezik Azure Data Factory-erőforrással, vagy az már felügyelt identitás nélkül lett üzembe helyezve, akkor ezt az eljárást követve hozza létre: Rendszer által hozzárendelt felügyelt identitás.
Figyelemfelhívás
Az Azure Data Factoryben az üzembe helyezés után nem módosítható az erőforrás-identitás. Ha a létrehozás után módosítania kell egy erőforrás identitását, újra létre kell hoznia az erőforrást.
Az üzembe helyezés után adjon hozzáférést az Azure Machine Learning-munkaterületen létrehozott erőforrás felügyelt identitásához. Lásd: Hozzáférés biztosítása. Ebben a példában a szolgáltatásnévnek a következőre van szüksége:
- A munkaterület engedélye kötegtelepítések olvasására és műveletek végrehajtására.
- Olvasási/írási engedélyek az adattárakban.
- Olvasási engedélyek az adatbevitelként megjelölt felhőbeli helyeken (tárfiókokban).
A folyamat ismertetése
Ebben a példában létrehoz egy folyamatot az Azure Data Factoryben, amely meghívhat egy adott kötegvégpontot bizonyos adatokon keresztül. A folyamat REST használatával kommunikál az Azure Machine Learning-kötegvégpontokkal. A kötegvégpontok REST API-jának használatáról további információt a Batch-végpontok feladat- és bemeneti adatainak létrehozása című témakörben talál.
A folyamat a következőképpen néz ki:

A folyamat a következő tevékenységeket tartalmazza:
Batch-Endpoint futtatása: Olyan webes tevékenység, amely a batch-végpont URI-jának használatával hívja meg. Átadja a bemeneti adatok URI-jának helyét, ahol az adatok találhatók, és a várt kimeneti fájlt.
Várjon a feladatra: Ez egy huroktevékenység, amely ellenőrzi a létrehozott feladat állapotát, és megvárja a befejezést, befejezettként vagy sikertelenként. Ez a tevékenység a következő tevékenységeket használja:
- Állapot ellenőrzése: Webes tevékenység, amely lekérdezi a Batch-Endpoint-tevékenység futtatása során válaszként visszaadott feladaterőforrás állapotát.
- Várakozás: A feladat állapotának lekérdezési gyakoriságát vezérlő várakozási tevékenység. Az alapértelmezett érték 120 (2 perc).
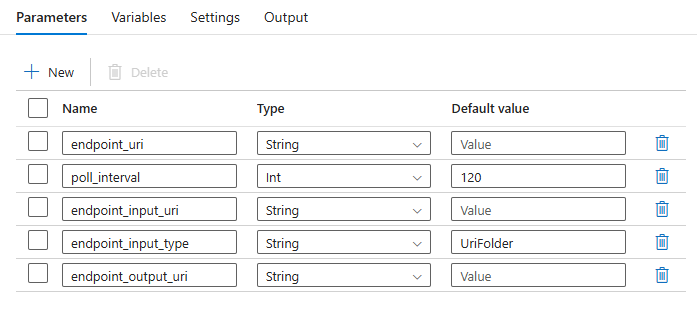
A folyamathoz a következő paramétereket kell konfigurálnia:
| Paraméter | Leírás | Mintaérték |
|---|---|---|
endpoint_uri |
A végpont pontozási URI-ja | https://<endpoint_name>.<region>.inference.ml.azure.com/jobs |
poll_interval |
A feladat állapotának ellenőrzése előtt várandó másodpercek száma. Alapértelmezett érték: 120. |
120 |
endpoint_input_uri |
A végpont bemeneti adatai. Több adatbeviteli típus is támogatott. Győződjön meg arról, hogy a feladat végrehajtásához használt felügyelt identitás hozzáfér a mögöttes helyhez. Másik lehetőségként, ha adattárakat használ, győződjön meg arról, hogy a hitelesítő adatok ott vannak feltüntetve. | azureml://datastores/.../paths/.../data/ |
endpoint_input_type |
A megadott bemeneti adatok típusa. Jelenleg a kötegvégpontok támogatják a mappákat (UriFolder) és a fájlokat (UriFile). Alapértelmezett érték: UriFolder. |
UriFolder |
endpoint_output_uri |
A végpont kimeneti adatfájlja. A Machine Learning-munkaterülethez csatolt adattár kimeneti fájljának elérési útjának kell lennie. Más típusú URI-k nem támogatottak. Használhatja az alapértelmezett Azure Machine Learning-adattárat, melynek neve workspaceblobstore. |
azureml://datastores/workspaceblobstore/paths/batch/predictions.csv |

Figyelmeztetés
Ne feledje, hogy endpoint_output_uri egy még nem létező fájl elérési útjának kell lennie. Ellenkező esetben a feladat meghiúsul azzal a hibával , hogy az elérési út már létezik.
A folyamat létrehozása
A folyamat meglévő Azure Data Factoryben való létrehozásához és kötegelt végpontok meghívásához kövesse az alábbi lépéseket:
Győződjön meg arról, hogy a kötegelt végpontot futtató számítás rendelkezik az Azure Data Factory által bemenetként biztosított adatok csatlakoztatásához szükséges engedélyekkel. A végpontot meghívó entitás továbbra is hozzáférést biztosít.
Ebben az esetben ez az Azure Data Factory. Azonban ahhoz a számításhoz, amelyen a kötegelt végpont fut, engedéllyel kell rendelkeznie az Azure Data Factory által biztosított tárfiók csatlakoztatásához. További részletekért tekintse meg a Tárolási szolgáltatások elérése című témakört.
Nyissa meg az Azure Data Factory Studiót. Válassza a ceruza ikont a Szerző panel megnyitásához, majd a Gyári erőforrások területen válassza a pluszjelet.
Válassza a Folyamat>importálása folyamatsablonból lehetőséget.
Válasszon ki egy .zip fájlt.
- A felügyelt identitások használatához válassza ki ezt a fájlt.
- A szolgáltatás elvének használatához válassza ki ezt a fájlt.
A folyamat előnézete megjelenik a portálon. Kattintson a Sablon használata lehetőségre.
A folyamat Run-BatchEndpoint néven jön létre.
Konfigurálja a kötegtelepítés paramétereit:
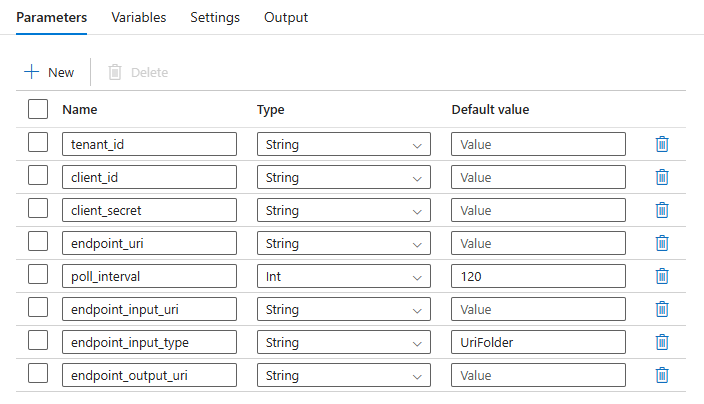
Figyelmeztetés
A feladat elküldése előtt győződjön meg arról, hogy a batch-végpont rendelkezik alapértelmezett üzembe helyezéssel. A létrehozott folyamat meghívja a végpontot. Létre kell hozni és konfigurálni kell egy alapértelmezett üzembe helyezést.
Tipp.
A legjobb újrafelhasználhatóság érdekében használja a létrehozott folyamatot sablonként, és hívja meg más Azure Data Factory-folyamatokból a Folyamat végrehajtása tevékenységgel. Ebben az esetben ne konfigurálja a belső folyamat paramétereit, hanem adja át őket paraméterként a külső folyamatból, ahogyan az az alábbi képen látható:
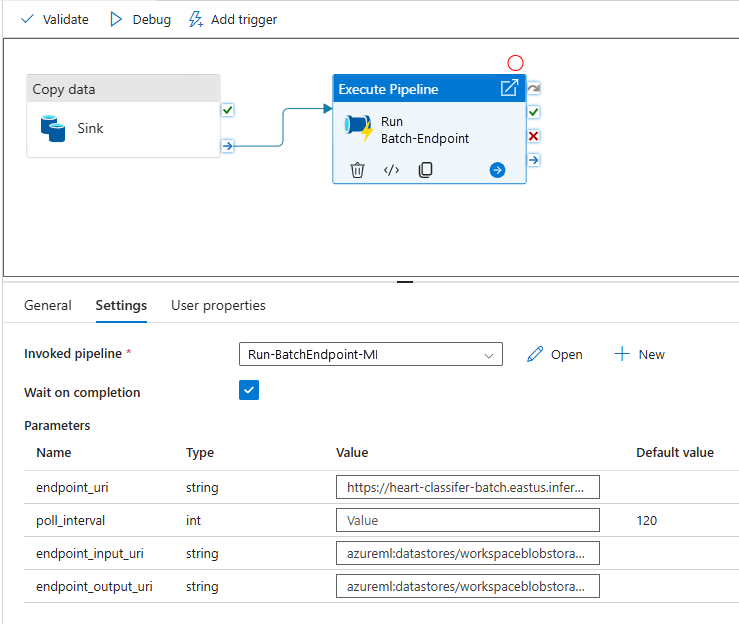
A folyamat készen áll a használatra.
Korlátozások
Azure Machine Learning-kötegek üzembe helyezésekor vegye figyelembe a következő korlátozásokat:
Adatbemenetek
- Bemenetként csak Azure Machine Learning-adattárak vagy Azure Storage-fiókok (Azure Blob Storage, Azure Data Lake Storage Gen1, Azure Data Lake Storage Gen2) támogatottak. Ha a bemeneti adatok egy másik forrásban találhatóak, használja az Azure Data Factory Copy tevékenység a kötegelt feladat végrehajtása előtt, hogy az adatokat egy kompatibilis tárolóba süllyesztse.
- A Batch-végpontfeladatok nem tárják fel a beágyazott mappákat. Nem használhatók beágyazott mappastruktúrákkal. Ha az adatok több mappában vannak elosztva, el kell simítanod a struktúrát.
- Győződjön meg arról, hogy az üzemelő példányban megadott pontozószkript képes kezelni az adatokat, mivel az várhatóan be lesz adva a feladatba. Ha a modell MLflow, a támogatott fájltípusokra vonatkozó korlátozásokról lásd : MLflow-modellek üzembe helyezése kötegelt telepítésekben.
Adatkimenetek
- Csak a regisztrált Azure Machine Learning-adattárak támogatottak. Javasoljuk, hogy regisztrálja azt a tárfiókot, amelyet az Azure Data Factory használ adattárként az Azure Machine Learningben. Így visszaírhatja ugyanazt a tárfiókot, ahol olvas.
- Kimenetek esetében csak az Azure Blob Storage-fiókok támogatottak. Az Azure Data Lake Storage Gen2 például nem támogatott kimenetként a kötegelt üzembe helyezési feladatokban. Ha az adatokat egy másik helyre vagy fogadóba kell kiadnia, használja az Azure Data Factory Copy tevékenység a kötegelt feladat futtatása után.