Azure Machine Learning-adatkészletek verziója és nyomon követése
A KÖVETKEZŐKRE VONATKOZIK: Python SDK azureml v1
Python SDK azureml v1
Ebben a cikkben megtudhatja, hogyan futtathatja és követheti nyomon az Azure Machine Learning-adatkészleteket a reprodukálhatóság érdekében. Az adathalmaz verziószámozása könyvjelzőket tartalmaz az adatok bizonyos állapotaiban, így az adathalmaz egy adott verzióját alkalmazhatja későbbi kísérletekhez.
Előfordulhat, hogy az Azure Machine Learning-erőforrásokat az alábbi tipikus forgatókönyvekben szeretné verziószámba venni:
- Amikor új adatok válnak elérhetővé újratanításra
- Ha különböző adatelőkészítési vagy szolgáltatástervezési módszereket alkalmaz
Előfeltételek
A Pythonhoz készült Azure Machine Learning SDK. Ez az SDK tartalmazza az azureml-datasets csomagot
Egy Azure Machine Learning-munkaterület. Hozzon létre egy új munkaterületet, vagy kérjen le egy meglévő munkaterületet ezzel a kódmintával:
import azureml.core from azureml.core import Workspace ws = Workspace.from_config()
Adathalmaz-verziók regisztrálása és lekérése
A regisztrált adathalmazok verziószámozottak, újrafelhasználhatók és megoszthatók a kísérletekben és a munkatársaival. Több adathalmazt is regisztrálhat ugyanazzal a névvel, és lekérhet egy adott verziót név és verziószám alapján.
Adathalmaz-verzió regisztrálása
Ez a kódminta az create_new_version titanic_ds adathalmaz paraméterét állítja be az adathalmaz Trueúj verziójának regisztrálásához. Ha a munkaterületen nincs regisztrálva meglévő titanic_ds adatkészlet, a kód létrehoz egy új adatkészletet a névvel titanic_ds, és a verziószámát 1-esre állítja.
titanic_ds = titanic_ds.register(workspace = workspace,
name = 'titanic_ds',
description = 'titanic training data',
create_new_version = True)
Adathalmaz lekérése név szerint
Alapértelmezés szerint a Dataset get_by_name() osztály metódus a munkaterületen regisztrált adathalmaz legújabb verzióját adja vissza.
Ez a kód az titanic_ds adathalmaz 1. verzióját adja vissza.
from azureml.core import Dataset
# Get a dataset by name and version number
titanic_ds = Dataset.get_by_name(workspace = workspace,
name = 'titanic_ds',
version = 1)
Ajánlott verziószámozási eljárás
Adathalmaz-verzió létrehozásakor nem hoz létre további adatmásolatot a munkaterülettel. Mivel az adathalmazok a tárolási szolgáltatásban lévő adatokra hivatkoznak, egyetlen igazságforrással rendelkezik, amelyet a tárolási szolgáltatás kezel.
Fontos
Ha az adathalmaz által hivatkozott adatok felülíródnak vagy törlődnek, az adathalmaz egy adott verziójára irányuló hívás nem módosítja a módosítást.
Amikor adatokat tölt be egy adatkészletből, a rendszer mindig betölti az adathalmaz által hivatkozott aktuális adattartalmat. Ha meg szeretné győződni arról, hogy minden adathalmaz-verzió reprodukálható, javasoljuk, hogy ne módosítsa az adathalmaz verziója által hivatkozott adattartalmakat. Amikor új adatok érkeznek, mentse az új adatfájlokat egy külön adatmappába, majd hozzon létre egy új adathalmaz-verziót az új mappából származó adatok belefoglalásához.
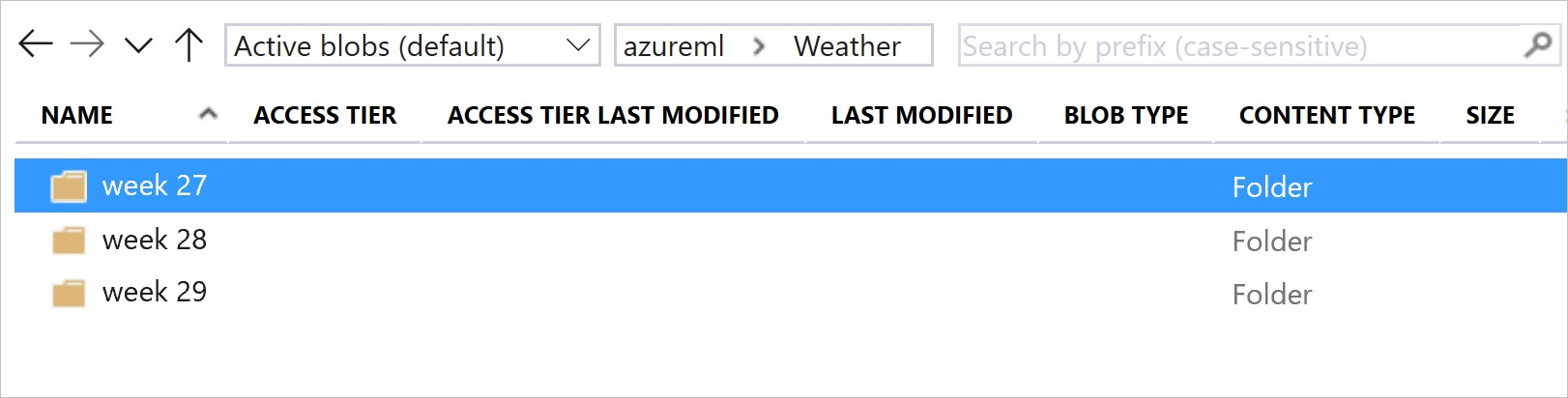
Ez a kép és mintakód az adatmappák strukturálásának és a mappákra hivatkozó adathalmaz-verziók létrehozásának ajánlott módját mutatja be:
from azureml.core import Dataset
# get the default datastore of the workspace
datastore = workspace.get_default_datastore()
# create & register weather_ds version 1 pointing to all files in the folder of week 27
datastore_path1 = [(datastore, 'Weather/week 27')]
dataset1 = Dataset.File.from_files(path=datastore_path1)
dataset1.register(workspace = workspace,
name = 'weather_ds',
description = 'weather data in week 27',
create_new_version = True)
# create & register weather_ds version 2 pointing to all files in the folder of week 27 and 28
datastore_path2 = [(datastore, 'Weather/week 27'), (datastore, 'Weather/week 28')]
dataset2 = Dataset.File.from_files(path = datastore_path2)
dataset2.register(workspace = workspace,
name = 'weather_ds',
description = 'weather data in week 27, 28',
create_new_version = True)
Ml-folyamat kimeneti adatkészletének verziója
Az egyes ML-folyamatlépések bemenete és kimeneteként adatkészletet használhat. A folyamatok újrafuttatásakor az egyes folyamatlépések kimenete új adathalmaz-verzióként lesz regisztrálva.
A Machine Learning-folyamatok minden egyes lépés kimenetét feltöltik egy új mappába a folyamat újrafuttatásakor. A verziószámozott kimeneti adathalmazok ezután reprodukálhatók lesznek. További információkért látogasson el a folyamatokban lévő adathalmazokra.
from azureml.core import Dataset
from azureml.pipeline.steps import PythonScriptStep
from azureml.pipeline.core import Pipeline, PipelineData
from azureml.core. runconfig import CondaDependencies, RunConfiguration
# get input dataset
input_ds = Dataset.get_by_name(workspace, 'weather_ds')
# register pipeline output as dataset
output_ds = PipelineData('prepared_weather_ds', datastore=datastore).as_dataset()
output_ds = output_ds.register(name='prepared_weather_ds', create_new_version=True)
conda = CondaDependencies.create(
pip_packages=['azureml-defaults', 'azureml-dataprep[fuse,pandas]'],
pin_sdk_version=False)
run_config = RunConfiguration()
run_config.environment.docker.enabled = True
run_config.environment.python.conda_dependencies = conda
# configure pipeline step to use dataset as the input and output
prep_step = PythonScriptStep(script_name="prepare.py",
inputs=[input_ds.as_named_input('weather_ds')],
outputs=[output_ds],
runconfig=run_config,
compute_target=compute_target,
source_directory=project_folder)
Adatok nyomon követése a kísérletekben
Az Azure Machine Learning a kísérlet során bemeneti és kimeneti adatkészletekként követi nyomon az adatokat. Ezekben az esetekben az adatok bemeneti adatkészletként lesznek nyomon követve:
Objektumként
DatasetConsumptionConfigazinputsobjektum vagyargumentsparaméterScriptRunConfighasználatával, a kísérletfeladat elküldésekorAmikor a szkript meghív bizonyos metódusokat –
get_by_name()vagyget_by_id()például . Az adathalmazhoz rendelt név a munkaterületen való regisztráláskor a megjelenített név
Ezekben a forgatókönyvekben az adatok kimeneti adathalmazként lesznek nyomon követve:
Adjon át egy
OutputFileDatasetConfigobjektumot a kísérletfeladat elküldésekor aoutputsparaméteren keresztülarguments.OutputFileDatasetConfigaz objektumok a folyamatlépések között is megőrizhetik az adatokat. További információ: Adatok áthelyezése az ML-folyamat lépései közöttRegisztráljon egy adatkészletet a szkriptben. Az adatkészlethez a munkaterületen való regisztráláskor hozzárendelt név a megjelenített név. Ebben a kódmintában
training_dsa megjelenített név:training_ds = unregistered_ds.register(workspace = workspace, name = 'training_ds', description = 'training data' )Gyermekfeladat beküldése egy nem regisztrált adatkészlettel a szkriptben. Ez a beküldés névtelen mentett adatkészletet eredményez
Adathalmazok nyomon követése kísérletfeladatokban
Minden Machine Learning-kísérlethez nyomon követheti a kísérletobjektum Job bemeneti adatkészleteit. Ez a kódminta a metódust használja a get_details() kísérlet futtatásához használt bemeneti adatkészletek nyomon követésére:
# get input datasets
inputs = run.get_details()['inputDatasets']
input_dataset = inputs[0]['dataset']
# list the files referenced by input_dataset
input_dataset.to_path()
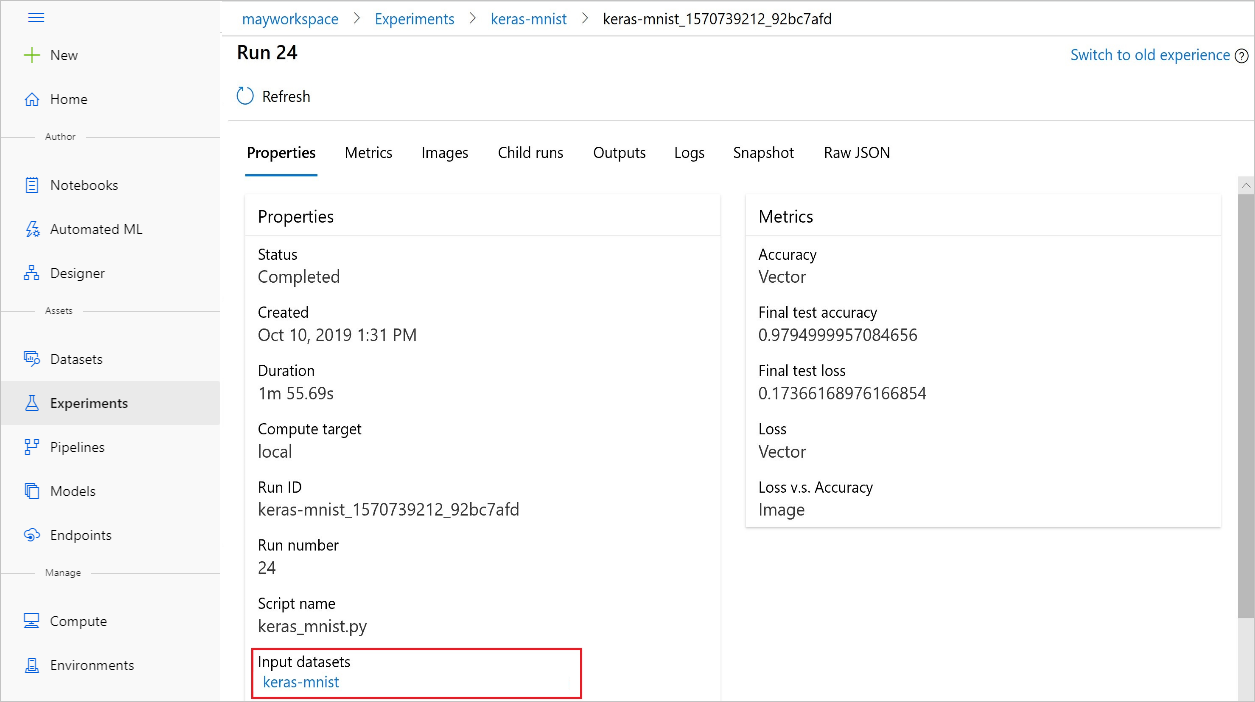
Az Azure Machine Learning Studióval végzett kísérletekből is megtalálhatja input_datasets azokat.
Ez a képernyőkép bemutatja, hol található egy kísérlet bemeneti adathalmaza az Azure Machine Learning Studióban. Ebben a példában kezdje a Kísérletek panelen, és nyissa meg a Kísérlet adott futtatásához tartozó Tulajdonságok lapot. keras-mnist
Ez a kód adatkészletekkel regisztrálja a modelleket:
model = run.register_model(model_name='keras-mlp-mnist',
model_path=model_path,
datasets =[('training data',train_dataset)])
A regisztráció után megtekintheti az adathalmazban pythonnal vagy a studióval regisztrált modellek listáját.
A Thia képernyőképe az Adathalmazok panelEn, az Eszközök területen látható. Jelölje ki az adathalmazt, majd válassza a Modellek lapot az adathalmazban regisztrált modellek listájához.
