Példák az Azure Machine Learning Designer folyamataira és adathalmazaira
Az Azure Machine Learning Designer beépített példái segítségével gyorsan megkezdheti saját gépi tanulási folyamatok készítését. Az Azure Machine Learning designer GitHub-adattára részletes dokumentációt tartalmaz, amely segít megérteni néhány gyakori gépi tanulási forgatókönyvet.
Előfeltételek
- Azure-előfizetés. Ha nem rendelkezik Azure-előfizetéssel, hozzon létre egy ingyenes fiókot
- Egy Azure Machine Learning-munkaterület
Fontos
Ha nem látja a dokumentumban említett grafikus elemeket, például a stúdióban vagy a tervezőben lévő gombokat, előfordulhat, hogy nem rendelkezik a megfelelő szintű engedélyekkel a munkaterülethez. Forduljon az Azure-előfizetés rendszergazdájához, és ellenőrizze, hogy a megfelelő hozzáférési szintet kapta-e. További információk: Felhasználók és szerepkörök kezelése.
Mintafolyamatok használata
A tervező a mintafolyamatok másolatát menti a stúdió-munkaterületre. Szerkesztheti a folyamatot, hogy az igényeihez igazítsa, és sajátként mentse. Használja őket kiindulási pontként a projektek elindításához.
Tervezői minta használata:
Jelentkezzen be a ml.azure.com, és válassza ki a használni kívánt munkaterületet.
Válassza a Tervező lehetőséget.
Válasszon ki egy mintafolyamatot az Új folyamat szakasz alatt.
Válassza a További minták megjelenítése lehetőséget a minták teljes listájához.
A folyamat futtatásához először be kell állítania az alapértelmezett számítási célt a folyamat futtatásához.
A vászontól jobbra található Beállítások panelen válassza a Számítási cél kiválasztása lehetőséget.
A megjelenő párbeszédpanelen válasszon ki egy meglévő számítási célt, vagy hozzon létre egy újat. Válassza a Mentés lehetőséget.
A folyamatfeladat elküldéséhez válassza a vászon tetején található Küldés lehetőséget.
A mintafolyamattól és a számítási beállításoktól függően a feladatok végrehajtása eltarthat egy ideig. Az alapértelmezett számítási beállítások minimális csomópontmérete 0, ami azt jelenti, hogy a tervezőnek üresjárat után kell lefoglalnia az erőforrásokat. Az ismétlődő folyamatfeladatok kevesebb időt vesznek igénybe, mivel a számítási erőforrások már ki vannak foglalva. Emellett a tervező gyorsítótárazott eredményeket használ az egyes összetevőkhöz a hatékonyság további javítása érdekében.
A folyamat futtatása után áttekintheti a folyamatot, és megtekintheti az egyes összetevők kimenetét, hogy többet tudjon meg. Az összetevők kimeneteinek megtekintéséhez kövesse az alábbi lépéseket:
- Kattintson a jobb gombbal arra az összetevőre a vásznon, amelynek a kimenetét látni szeretné.
- Válassza a Vizualizáció lehetőséget.
A mintákat a leggyakoribb gépi tanulási forgatókönyvek kiindulópontjaként használhatja.
Regresszió
Ismerje meg ezeket a beépített regressziós mintákat.
| Mintacím | Leírás |
|---|---|
| Regresszió – Autóárak előrejelzése (alapszintű) | Az autóárak előrejelzése lineáris regresszióval. |
| Regresszió - Automobile Price Prediction (Speciális) | Előrejelezheti az autóárakat döntési erdővel és a döntési fák regresszióinak növelésével. Hasonlítsa össze a modelleket a legjobb algoritmus megtalálásához. |
Osztályozás
Ismerje meg ezeket a beépített besorolási mintákat. A mintákról a minták megnyitásával és az összetevők megjegyzéseinek tervezőben való megtekintésével tudhat meg többet.
| Mintacím | Leírás |
|---|---|
| Bináris besorolás funkcióválasztással – Bevétel-előrejelzés | Előrejelezheti a magas vagy alacsony jövedelmet egy kétosztályos, megnövelt döntési fa használatával. A Pearson-korrelációval válassza ki a funkciókat. |
| Bináris besorolás egyéni Python-szkripttel – Hitelkockázat előrejelzése | Sorolja be a hitelalkalmazásokat magas vagy alacsony kockázatúként. Az adatok súlyozásához használja a Python-szkript végrehajtása összetevőt. |
| Bináris besorolás – Ügyfélkapcsolat előrejelzése | Előrejelezheti az ügyfelek változását kétosztályos emelt szintű döntési fák használatával. Az SMOTE használatával mintaként használhatja az elfogult adatokat. |
| Szövegbesorolás – Wikipedia SP 500-adatkészlet | Többosztályos logisztikai regresszióval sorolja be a vállalattípusokat a Wikipédiából származó cikkekből. |
| Többosztályos besorolás – Betűfelismerés | Bináris osztályozókból álló együttes létrehozása az írott betűk osztályozásához. |
Számítógépes látástechnológia
Fedezze fel ezeket a beépített számítógépes látásmintákat. A mintákról a minták megnyitásával és az összetevők megjegyzéseinek tervezőben való megtekintésével tudhat meg többet.
| Mintacím | Leírás |
|---|---|
| Képbesorolás a DenseNet használatával | A PyTorch DenseNeten alapuló képbesorolási modell létrehozásához használjon számítógépes látáskomponenseket. |
Ajánló
Fedezze fel ezeket a beépített ajánlómintákat. A mintákról a minták megnyitásával és az összetevők megjegyzéseinek tervezőben való megtekintésével tudhat meg többet.
| Mintacím | Leírás |
|---|---|
| Széles és mélyalapú javaslat – Étterembesorolás előrejelzése | Éttermi ajánló motor összeállítása étterem/felhasználói funkciók és értékelések alapján. |
| Javaslat – Filmminősítési tweetek | Filmajánló motor létrehozása film-/felhasználói funkciókból és értékelésekből. |
Segédprogram
További információ a gépi tanulási segédprogramokat és funkciókat bemutató mintákról. A mintákról a minták megnyitásával és az összetevők megjegyzéseinek tervezőben való megtekintésével tudhat meg többet.
| Mintacím | Leírás |
|---|---|
| Bináris besorolás vowpal Wabbit modell használatával – Felnőtt jövedelem előrejelzése | A Vowpal Wabbit egy gépi tanulási rendszer, amely olyan technikákkal tolja le a gépi tanulás határát, mint az online, a kivonatolás, az allreduce, a csökkentés, a learning2search, az aktív és az interaktív tanulás. Ez a minta bemutatja, hogyan használható vowpal Wabbit-modell bináris besorolási modell létrehozásához. |
| Egyéni R-szkript használata – Repülési késés előrejelzése | Testreszabott R-szkripttel előre jelezheti, hogy egy menetrend szerinti utasszállító járat több mint 15 perccel késik-e. |
| Bináris besorolás keresztérvényesítése – Felnőtt jövedelem előrejelzése | Keresztérvényesítéssel bináris osztályozót hozhat létre felnőtt jövedelemhez. |
| A permutáció funkció fontossága | A permutációs funkció fontossága a tesztadatkészlet fontossági pontszámainak kiszámításához. |
| A bináris besorolás paramétereinek finomhangolása – Felnőtt jövedelem előrejelzése | A modell hiperparamétereinek finomhangolásával optimális hiperparamétereket kereshet bináris osztályozó létrehozásához. |
Adathalmazok
Amikor új folyamatot hoz létre az Azure Machine Learning Designerben, a rendszer alapértelmezés szerint több mintaadatkészletet is tartalmaz. Ezeket a mintaadatkészleteket a tervező kezdőlapjának mintafolyamatai használják.
A mintaadatkészletek az Adathalmazok-minták kategóriában érhetők el. Ezt a tervezőben a vászon bal oldalán található összetevő-palettán találja. Ezen adathalmazok bármelyikét használhatja a saját folyamatában a vászonra húzással.
| Adatkészlet neve | Adathalmaz leírása |
|---|---|
| Felnőtt Census Income Binary Classification adatkészlet | Az 1994.évi összeírási adatbázis egy részhalmaza, amely 16 éven felüli dolgozó felnőtteket használ 100-ra korrigált jövedelemindexkel > . Használat: A demográfiai adatokat használó személyek besorolása annak előrejelzéséhez, hogy egy személy évente több mint 50 ezret keres-e. Kapcsolódó kutatás: Kohavi, R., Becker, B., (1996). UCI Machine Learning-adattár. Irvine, CA: University of California, School of Information and Computer Science |
| Autóárak adatai (nyers) | Információk az autók make és modell, beleértve az árat, funkciók, mint például a hengerek száma és MPG, valamint a biztosítási kockázati pontszámot. A kockázati pontszám kezdetben az automatikus árhoz van társítva. Ezt követően a tényleges kockázathoz igazítjuk egy olyan folyamat esetében, amelyet az aktuáriusok szimbólumként ismernek. A +3 érték azt jelzi, hogy az auto kockázatos, és -3 érték, hogy valószínűleg biztonságos. Használat: A kockázati pontszám előrejelzése funkciók szerint, regressziós vagy többváltozós besorolás használatával. Kapcsolódó kutatás: Schlimmer, J.C. (1987). UCI Machine Learning-adattár. Irvine, CA: University of California, School of Information and Computer Science. |
| CRM Appetency Labels Shared | Címkék a KDD Cup 2009 ügyfélkapcsolat előrejelzési kihívás (orange_small_train_appetency.labels). |
| MEGOSZTOTT CRM-forgalom címkéi | Címkék a KDD Cup 2009 ügyfélkapcsolat előrejelzési kihívás (orange_small_train_churn.labels). |
| MEGOSZTOTT CRM-adatkészlet | Ezek az adatok a KDD Cup 2009 ügyfélkapcsolat-előrejelzési kihívásából (orange_small_train.data.zip) származnak. Az adatkészlet 50 ezer ügyfelet tartalmaz az Orange francia távközlési vállalattól. Minden ügyfél 230 anonimizált funkcióval rendelkezik, amelyek közül 190 numerikus, 40 pedig kategorikus. A funkciók nagyon ritkák. |
| A CRM-szelektálás címkéi megosztottak | Címkék a KDD Cup 2009 ügyfélkapcsolat előrejelzési kihívásából (orange_large_train_upselling.labels |
| Repülési késések adatai | Az egyesült államokbeli Közlekedési Minisztérium (On-Time) TranStats adatgyűjtéséből származó, az utasjáratok időalapú teljesítményadatai. Az adathalmaz a 2013. április-októberi időszakra vonatkozik. Mielőtt feltöltené a tervezőt, az adathalmaz a következőképpen lett feldolgozva: - Az adathalmazt úgy szűrték, hogy csak az USA 70 legforgalmasább repülőterére terjedjen ki - A törölt járatok több mint 15 perc késéssel lettek megjelölve - A átirányított járatok kiszűrve lettek - A következő oszlopok lettek kiválasztva: Year, Month, DayofMonth, DayOfWeek, Carrier, OriginAirportID, DestAirportID, CRSDepTime, DepDelay, DepDel15, CRSArrTime, ArrDelay, ArrDel15, Canceled |
| Német hitelkártya UCI-adatkészlet | Az UCI Statlog (német hitelkártya) adatkészlete (Statlog+German+Credit+Data) a german.data fájl használatával. Az adatkészlet alacsony vagy magas hitelkockázatként sorolja be a személyeket egy attribútumkészlettel. Minden példa egy személyt jelöl. 20 funkció létezik, numerikus és kategorikus, valamint bináris címke (a hitelkockázati érték). A magas hitelkockázatú bejegyzések címkéje = 2, az alacsony hitelkockázatú bejegyzések címkéje = 1. Az alacsony kockázati példa magasként való helytelen besorolásának költsége 1, míg a magas kockázatú példák alacsonyként való besorolásának költsége 5. |
| IMDB-filmek címei | Az adatkészlet az X tweetekben értékelt filmekről tartalmaz információkat: IMDB-filmazonosító, filmnév, műfaj és éles év. Az adathalmazban 17K film található. Az adatkészletet az "S" című dokumentumban vezették be. Dooms, T. De Pessemier és L. Martens. MovieTweetings: a Movie Rating Dataset összegyűjtött Twitter. Workshop on Crowdsourcing and Human Computation for Recommender Systems, CrowdRec at RecSys 2013." |
| Filmbesorolások | Az adatkészlet a Movie Tweetings adatkészlet bővített verziója. Az adathalmaz 170 EZER minősítéssel rendelkezik a filmekhez, amelyet jól strukturált tweetekből nyernek ki az X-en. Minden példány egy tweetet jelöl, és egy rekord: felhasználói azonosító, IMDB-filmazonosító, értékelés, időbélyeg, a tweethez tartozó kedvencek száma és a tweet újrapróbálkozóinak száma. Az adatkészletet A. Said, S. Dooms, B. Loni és D. Tikk for Recommender Systems Challenge 2014 tette elérhetővé. |
| Időjárási adatkészlet | A NOAA óránkénti szárazföldi időjárási megfigyelései (egyesített adatok 201304 és 201310 között). Az időjárási adatok a repülőtéri időjárási állomásokról származó megfigyeléseket fedik le, amelyek a 2013. április-október közötti időszakra terjednek ki. Mielőtt feltöltené a tervezőt, az adathalmaz a következőképpen lett feldolgozva: - A meteorológiai állomás azonosítóit a megfelelő repülőtéri azonosítókra képezték le - A 70 legforgalmasságú repülőtérhez nem tartozó időjárási állomásokat szűrték ki – A Dátum oszlop külön Év, Hónap és Nap oszlopra lett felosztva - A következő oszlopok lettek kiválasztva: AirportID, Year, Month, Day, Time, TimeZone, SkyCondition, Láthatóság, WeatherType, DryBulbFarenheit, DryBulbCelsius, WetBulbFarenheit, WetBulbCelsius, DewPointFarenheit, DewPointCelsius, RelativeHumidity, WindSpeed, WindDirection, ValueForWindCharacter, StationPressure, PressureTendency, PressureChange, SeaLevelPressure, RecordType, HourlyPrecip, Altimeter |
| Wikipedia SP 500-adatkészlet | Az adatok a Wikipédiából származnakhttps://www.wikipedia.org/ az egyes S&P 500-vállalatok cikkei alapján, XML-adatokként tárolva. Mielőtt feltöltené a tervezőt, az adathalmaz a következőképpen lett feldolgozva: - Szöveges tartalom kinyerés minden egyes vállalathoz – Wikiformázás eltávolítása – Nem alfanumerikus karakterek eltávolítása – Az összes szöveg kisbetűssé alakításához - Ismert vállalati kategóriák lettek hozzáadva Vegye figyelembe, hogy egyes vállalatoknál nem található cikk, ezért a rekordok száma kevesebb, mint 500. |
| Éttermi funkciók adatai | Metaadatok az éttermekről és azok jellemzőiről, például az ételtípusról, az étkezési stílusról és a helyszínről. Használat: Ezt az adatkészletet a másik két éttermi adatkészlettel együtt használva betanítsa és tesztelje az ajánlórendszert. Kapcsolódó kutatás: Bache, K. and Lichman, M. (2013). UCI Machine Learning-adattár. Irvine, CA: University of California, School of Information and Computer Science. |
| Éttermi értékelések | A felhasználók által az éttermeknek adott értékeléseket tartalmazza 0 és 2 közötti skálán. Használat: Ezt az adatkészletet a másik két éttermi adatkészlettel együtt használva betanítsa és tesztelje az ajánlórendszert. Kapcsolódó kutatás: Bache, K. and Lichman, M. (2013). UCI Machine Learning-adattár. Irvine, CA: University of California, School of Information and Computer Science. |
| Étterem ügyféladatai | Az ügyfelek metaadatainak készlete, beleértve a demográfiai adatokat és a beállításokat. Használat: Ezt az adatkészletet a másik két éttermi adatkészlettel együtt használva betanítsa és tesztelje az ajánlórendszert. Kapcsolódó kutatás: Bache, K. and Lichman, M. (2013). UCI Machine Learning Repository Irvine, CA: University of California, School of Information and Computer Science. |
Az erőforrások eltávolítása
Fontos
A létrehozott erőforrásokat más Azure Machine Learning-oktatóanyagok és útmutatók előfeltételeiként használhatja.
Minden törlése
Ha nem tervez semmit, amit létrehozott, törölje a teljes erőforráscsoportot, hogy ne járjon költségekkel.
Az Azure Portalon válassza ki az erőforráscsoportokat az ablak bal oldalán.
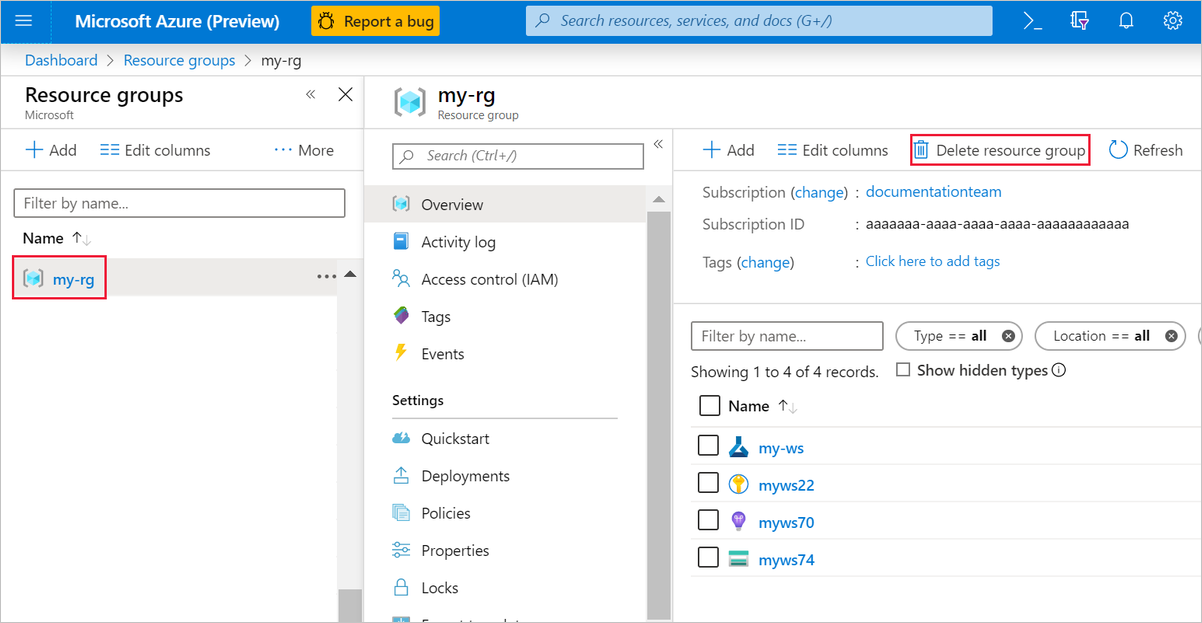
A listában válassza ki a létrehozott erőforráscsoportot.
Válassza az Erőforráscsoport törlése elemet.
Az erőforráscsoport törlése a tervezőben létrehozott összes erőforrást is törli.
Egyes objektumok törlése
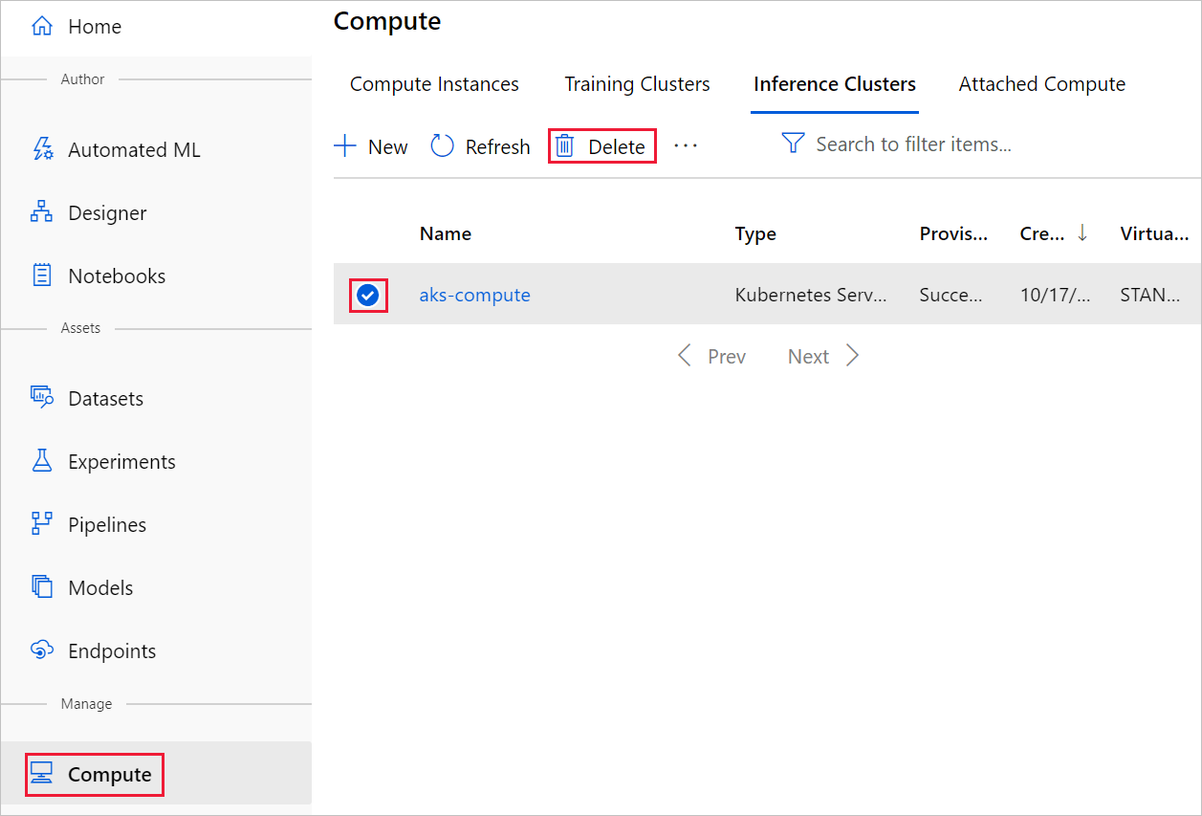
Abban a tervezőben, ahol létrehozta a kísérletet, törölje az egyes objektumokat a kijelöléssel, majd a Törlés gombra kattintva.
Az itt létrehozott számítási cél automatikusan nulla csomópontra skálázódik automatikusan, ha nincs használatban. Ez a művelet a díjak minimalizálása érdekében történik. Ha törölni szeretné a számítási célt, hajtsa végre az alábbi lépéseket:
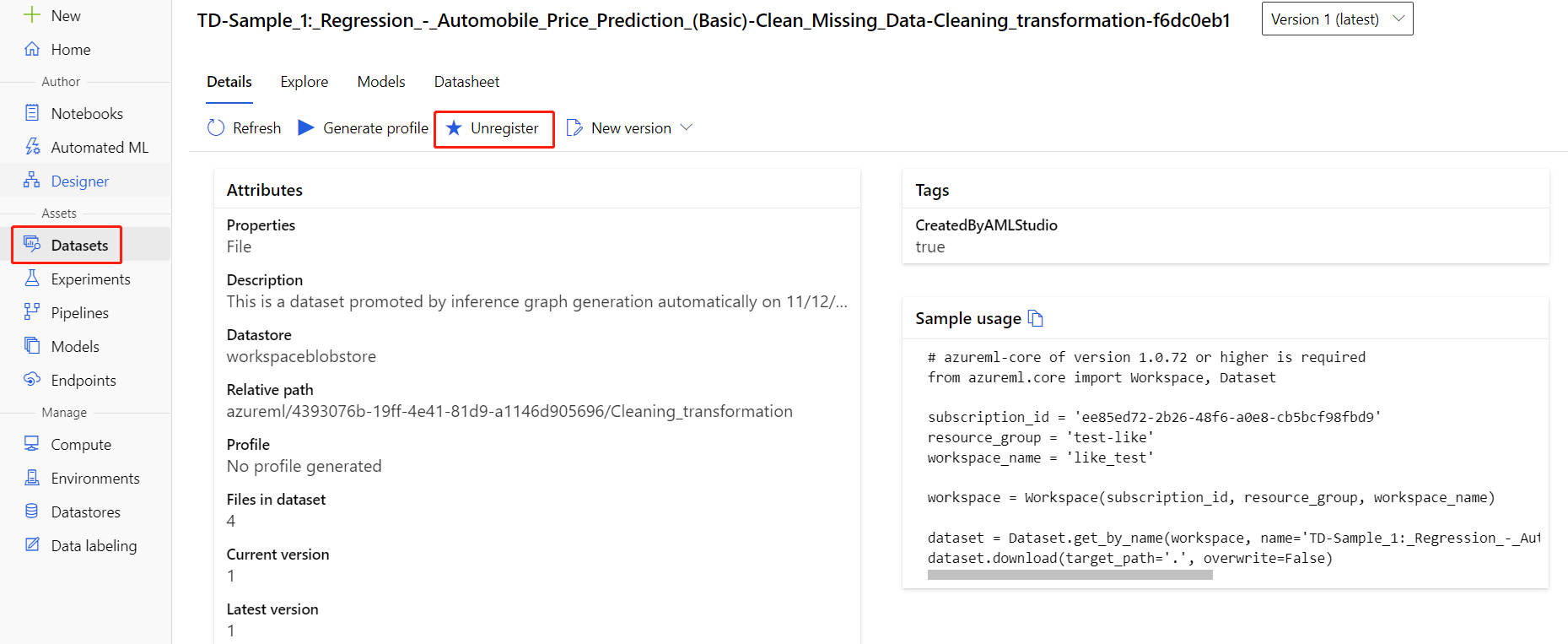
Az adathalmazok regisztrációját a munkaterületről az egyes adathalmazok kiválasztásával és a Regisztráció törlése lehetőség kiválasztásával szüntetheti meg.
Adathalmaz törléséhez lépjen a tárfiókba az Azure Portal vagy az Azure Storage Explorer használatával, és törölje manuálisan ezeket az eszközöket.
Következő lépések
Ismerje meg a prediktív elemzés és a gépi tanulás alapjait a következő oktatóanyaggal : Autóárak előrejelzése a tervezővel