Megjegyzés
Az oldalhoz való hozzáféréshez engedély szükséges. Megpróbálhat bejelentkezni vagy módosítani a címtárat.
Az oldalhoz való hozzáféréshez engedély szükséges. Megpróbálhatja módosítani a címtárat.
Fontos
A (klasszikus) Machine Learning Studio támogatása 2024. augusztus 31-én megszűnik. Javasoljuk, hogy addig térjen át az Azure Machine Learning használatára.
2021. december 1-től kezdve nem fog tudni létrehozni új (klasszikus) Machine Learning Studio-erőforrásokat. 2024. augusztus 31-ig továbbra is használhatja a meglévő (klasszikus) Machine Learning Studio-erőforrásokat.
- A gépi tanulási projektek ML Studióból (klasszikus) Azure Machine Learning való áthelyezéséről olvashat.
- További információ a Azure Machine Learning.
A (klasszikus) ML Studio dokumentációjának kivezetése folyamatban van, és a jövőben nem várható a frissítése.
Python szkript végrehajtása Machine Learning kísérletből
Kategória: Python nyelvi modulok
Megjegyzés
Csak a következőre vonatkozik: Machine Learning Studio (klasszikus)
Hasonló húzási modulok érhetők el Azure Machine Learning tervezőben.
A modul áttekintése
Ez a cikk azt ismerteti, hogyan futtathat Python kódot a Machine Learning Studio (klasszikus) Python Szkript végrehajtása modulja segítségével. A (klasszikus) Studio Python architektúrájáról és tervezési alapelveiről az alábbi cikkben talál további információt.
A Python olyan feladatokat hajthat végre, amelyeket a meglévő (klasszikus) Studio-modulok jelenleg nem támogatnak, például:
- Adatok vizualizációja a következő használatával:
matplotlib - Adatkészletek és modellek számbavétele Python kódtárak használatával a munkaterületen
- Az Adatok importálása modul által nem támogatott forrásokból származó adatok olvasása, betöltése és manipulálása
A Machine Learning Studio (klasszikus) a Python Anaconda-eloszlását használja, amely számos általános adatfeldolgozási segédprogramot tartalmaz.
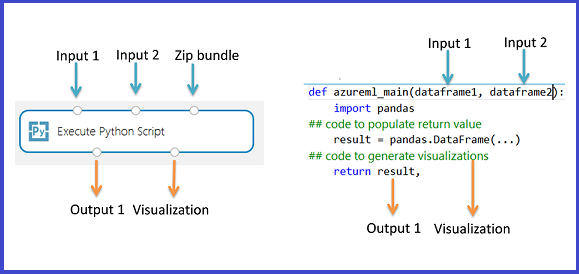
Az Execute Python script használata
Az Execute Python Script modul minta Python kódot tartalmaz, amelyet kiindulási pontként használhat. Az Execute Python Script modul konfigurálásához meg kell adnia a Python szkript szövegmezőjében végrehajtandó bemeneteket és Python kódot.
Adja hozzá az Execute Python Script modult a kísérlethez.
Görgessen a Tulajdonságok panel aljára, és Python Verzió beállításnál válassza ki a szkriptben használni kívánt Python kódtárak és futtatókörnyezet verzióját.
- Anaconda 2.0 eloszlás Python 2.7.7-hez
- Anaconda 4.0 eloszlás Python 2.7.11-hez
- Anaconda 4.0-disztribúció a Python 3.5-ös verzióhoz (alapértelmezett)
Javasoljuk, hogy az új kód beírása előtt állítsa be a verziót. Ha később módosítja a verziót, egy üzenet arra kéri, hogy nyugtázza a módosítást.
Fontos
Ha a kísérletben az Execute Python Script modul több példányát használja, a kísérlet összes moduljához ki kell választania a Python egyetlen verzióját.
Adja hozzá és csatlakozzon a Dataset1-hez minden olyan (klasszikus) Studio-adatkészlethez, amelyet bemenetként szeretne használni. Hivatkozzon erre az adatkészletre a Python szkriptben DataFrame1 néven.
Az adathalmaz használata nem kötelező, ha Python használatával szeretne adatokat létrehozni, vagy Python kóddal közvetlenül a modulba importálja az adatokat.
Ez a modul egy második (klasszikus) Studio-adathalmaz hozzáadását támogatja a Dataset2-en. Hivatkozzon a Python szkript második adathalmazára DataFrame2 néven.
A (klasszikus) Studióban tárolt adathalmazok automatikusan pandas data.frame formátumba lesznek konvertálva, amikor betöltik ezt a modult.
Ha új Python csomagokat vagy kódot szeretne felvenni, adja hozzá az egyéni erőforrásokat tartalmazó tömörített fájlt a Szkriptcsomaghoz. A szkriptcsomag bemenetének tömörített fájlnak kell lennie, amelyet már feltöltött a munkaterületre. Az erőforrások előkészítéséről és feltöltéséről további információt a Tömörített adatok kicsomagolása című témakörben talál.
A feltöltött tömörített archívumban található bármely fájl használható a kísérlet végrehajtása során. Ha az archívum könyvtárszerkezetet tartalmaz, a struktúra megmarad, de az elérési útra előre fel kell függesztetnie egy src nevű könyvtárat.
A Python szkript szövegmezőbe írjon be vagy illessze be az érvényes Python szkriptet.
A Python szkript szövegmezője előre fel van töltve néhány megjegyzésben szereplő utasítással, valamint mintakóddal az adathozzáféréshez és a kimenethez. Ezt a kódot szerkesztenie vagy cserélnie kell. Ügyeljen arra, hogy kövesse Python behúzással és burkolattal kapcsolatos konvenciót.
- A szkriptnek tartalmaznia kell egy, a modul belépési pontjaként elnevezett
azureml_mainfüggvényt. - A belépési pont függvény legfeljebb két bemeneti argumentumot tartalmazhat:
Param<dataframe1>ésParam<dataframe2> - A harmadik bemeneti porthoz csatlakoztatott tömörített fájlok ki vannak csomagolva, és a könyvtárban vannak tárolva,
.\Script Bundleamely szintén hozzá lesz adva a Pythonsys.path.
Ezért ha a zip-fájl tartalmazza
mymodule.py, importálja a következővelimport mymodule: .- Egyetlen adatkészlet adható vissza a Studióba (klasszikus), amelynek típussorozatnak
pandas.DataFramekell lennie. Létrehozhat más kimeneteket a Python-kódban, és közvetlenül az Azure Storage-ba írhatja őket, vagy vizualizációkat hozhat létre a Python eszközzel.
- A szkriptnek tartalmaznia kell egy, a modul belépési pontjaként elnevezett
Futtassa a kísérletet, vagy válassza ki a modult, és kattintson a Kijelölt futtatás gombra, hogy csak a Python szkriptet futtassa.
Az összes adat és kód betöltődik egy virtuális gépre, és a megadott Python környezetben fut.
Results (Eredmények)
A modul a következő kimeneteket adja vissza:
Találatok adatkészlete. A beágyazott Python-kód által végrehajtott számítások eredményeit pandas data.frame formátumban kell megadni, amely automatikusan Machine Learning adathalmaz formátumra lesz konvertálva, hogy az eredményeket a kísérlet más moduljaival is használhassa. A modul kimenetként egyetlen adatkészletre korlátozódik. További információ: Adattábla.
Python eszköz. Ez a kimenet támogatja a konzol kimenetét és a PNG-ábrák megjelenítését a Python értelmező használatával.
Szkripterőforrások csatolása
Az Execute Python Script modul bemenetként támogatja az tetszőleges Python szkriptfájlokat, feltéve, hogy azokat előre előkészítik, és egy .ZIP fájl részeként feltöltik őket a munkaterületre.
Python kódot tartalmazó ZIP-fájl feltöltése a munkaterületre
A Machine Learning Studio (klasszikus) kísérleti területén kattintson az Adathalmazok elemre, majd az Új elemre.
Válassza a helyi fájlból lehetőséget.
Az Új adathalmaz feltöltése párbeszédpanelen kattintson az új adathalmaz típusának kiválasztására szolgáló legördülő listára, és válassza a Zip-fájl (.zip) lehetőséget.
Kattintson a Tallózás gombra a tömörített fájl megkereséséhez.
Írjon be egy új nevet a munkaterületen való használathoz. Az adatkészlethez hozzárendelt név lesz annak a mappának a neve a munkaterületen, ahol a tartalmazott fájlok kinyerve lesznek.
Miután feltöltötte a tömörített csomagot a Studióba (klasszikus), ellenőrizze, hogy a tömörített fájl elérhető-e a Mentett adathalmazok listában, majd csatlakoztassa az adatkészletet a Szkriptcsomag bemeneti portjához.
A ZIP-fájlban található összes fájl használható futásidőben: például mintaadatok, szkriptek vagy új Python csomagok.
Ha a tömörített fájl olyan kódtárakat tartalmaz, amelyek még nincsenek telepítve a Machine Learning Studióban (klasszikus), az egyéni szkript részeként telepítenie kell a Python kódtárcsomagot.
Ha könyvtárstruktúra volt jelen, az megmarad. Módosítania kell azonban a kódot, hogy a könyvtár src-jét az elérési útra elővezhesse.
Hibakeresés Python kódban
Az Execute Python Script modul akkor működik a legjobban, ha a kódot egyértelműen definiált bemenetekkel és kimenetekkel rendelkező függvényként vették fel, nem pedig lazán kapcsolódó végrehajtható utasítások sorozataként.
Ez a Python modul nem támogatja az olyan funkciókat, mint az Intellisense és a hibakeresés. Ha a modul futásidőben meghiúsul, a modul kimeneti naplójában megtekintheti a hiba részleteit. A teljes Python verem nyomkövetése azonban nem érhető el. Ezért azt javasoljuk, hogy a felhasználók egy másik környezetben fejlesszék ki és hibakereséssel végezzenek Python szkripteket, majd importálják a kódot a modulba.
Néhány gyakori probléma, amelyet megkereshet:
Ellenőrizze az adattípusokat abban az adatkeretben, amelyből
azureml_mainvissza szeretne térni. A hibák valószínűleg akkor fordulhatnak elő, ha az oszlopok nem numerikus típusokat és sztringeket tartalmaznak.Távolítsa el a NA-értékeket az adatkészletből Python szkriptből való exportálással
dataframe.dropna(). Az adatok előkészítésekor használja a Clean Missing Data (Hiányzó adatok törlése) modult .Ellenőrizze, hogy a beágyazott kód behúzási és térközhibákat keres-e. Ha a "Behúzáshiba: behúzási blokk várható" hibaüzenet jelenik meg, tekintse meg az alábbi forrásokat útmutatásért:
Ismert korlátozások
A Python futtatókörnyezet tesztkörnyezetben van, és nem teszi lehetővé a hálózathoz vagy a helyi fájlrendszerhez való állandó hozzáférést.
A modul befejezése után minden helyileg mentett fájl el lesz különítve és törölve. A Python kód nem fér hozzá a legtöbb könyvtárhoz azon a gépen, amelyen fut, a kivétel az aktuális könyvtár és annak alkönyvtárai.
Ha egy tömörített fájlt erőforrásként ad meg, a rendszer átmásolja a fájlokat a munkaterületről a kísérlet végrehajtási területére, kicsomagolja, majd felhasználja. Az erőforrások másolása és kicsomagolása memóriát használhat.
A modul egyetlen adatkeretet képes kimenetként kiadni. Nem lehet tetszőleges Python objektumokat, például betanított modelleket közvetlenül visszaküldeni a Studio (klasszikus) futtatókörnyezetbe. Azonban írhat objektumokat a tárolóba vagy a munkaterületre. Egy másik lehetőség, hogy
pickletöbb objektumot szerializál egy bájttömbbe, majd visszaadja a tömböt egy adatkereten belül.
Példák
Példák Python szkriptek studioi (klasszikus) kísérletekkel való integrálására, tekintse meg ezeket az erőforrásokat az Azure AI-galériában:
- Python szkript végrehajtása: Szövegtokenizálás, szövegszármaztatás és egyéb természetes nyelvi feldolgozás használata az Execute Python Script modullal.
- Egyéni R- és Python-szkriptek az Azure ML-ban: Végigvezeti az egyéni kód (R vagy Python) hozzáadásának folyamatán, az adatok feldolgozásán és az eredmények megjelenítésén.
- PyPI-adatok elemzése a Python 3 támogatásának meghatározásához: Becsülje meg azt a pontot, amikor a Python 3-ra vonatkozó igény túllépi az Python 2.7-et a Python használatával.