Oktatóanyag: Tervező – Kód nélküli regressziós modell betanítása
Lineáris regressziós modell betanítása, amely előrejelzi az autóárakat az Azure Machine Learning tervezőjével. Ez az oktatóanyag egy kétrészes sorozat első része.
Ez az oktatóanyag az Azure Machine Learning designert használja további információkért: Mi az Az Azure Machine Learning-tervező?
Feljegyzés
A Tervező kétféle összetevőt támogat, a klasszikus előre összeállított összetevőket (v1) és az egyéni összetevőket (v2). Ez a két összetevőtípus NEM kompatibilis.
A klasszikus előre összeállított összetevők elsősorban az adatfeldolgozáshoz és a hagyományos gépi tanulási feladatokhoz, például a regresszióhoz és a besoroláshoz biztosítanak előre összeállított összetevőket. Ez az összetevőtípus továbbra is támogatott marad, de nem lesznek új összetevők hozzáadva.
Az egyéni összetevők lehetővé teszik, hogy a saját kódját összetevőként csomagolja. Támogatja az összetevők munkaterületek közötti megosztását és a közvetlen létrehozást a Studio, a CLI v2 és az SDK v2 felületeken.
Új projektek esetén javasoljuk, hogy egyéni összetevőt használjon, amely kompatibilis az AzureML V2-vel, és folyamatosan új frissítéseket fog kapni.
Ez a cikk a klasszikus előre összeállított összetevőkre vonatkozik, és nem kompatibilis a CLI v2-vel és az SDK v2-vel.
Az oktatóanyag első részében megtanulhatja, hogyan:
- Hozzon létre egy új folyamatot.
- Adatok beolvasása.
- Adatok előkészítése.
- Gépi tanulási modell betanítása.
- Gépi tanulási modell kiértékelése.
Az oktatóanyag második részében valós idejű következtetési végpontként helyezi üzembe a modellt, hogy előrejelezhesse az autó árát az Ön által küldött műszaki specifikációk alapján.
Feljegyzés
Az oktatóanyag befejezett verziója mintafolyamatként érhető el.
A kereséshez lépjen a munkaterület tervezőjéhez. Az Új folyamat szakaszban válassza az 1. minta – Regresszió: Automobile Price Prediction(Basic).
Fontos
Ha nem látja a dokumentumban említett grafikus elemeket, például a stúdióban vagy a tervezőben lévő gombokat, előfordulhat, hogy nem rendelkezik a megfelelő szintű engedélyekkel a munkaterülethez. Forduljon az Azure-előfizetés rendszergazdájához, és ellenőrizze, hogy a megfelelő hozzáférési szintet kapta-e. További információk: Felhasználók és szerepkörök kezelése.
Új folyamat létrehozása
Az Azure Machine Learning-folyamatok több gépi tanulási és adatfeldolgozási lépést rendszereznek egyetlen erőforrásba. A folyamatok lehetővé teszik összetett gépi tanulási munkafolyamatok rendszerezését, kezelését és újrafelhasználását projektek és felhasználók között.
Azure Machine Learning-folyamat létrehozásához Azure Machine Learning-munkaterületre van szükség. Ebben a szakaszban megtudhatja, hogyan hozhatja létre mindkét erőforrást.
Új munkaterület létrehozása
A tervező használatához Azure Machine Learning-munkaterületre van szüksége. A munkaterület az Azure Machine Learning legfelső szintű erőforrása, központi helyet biztosít az Azure Machine Learningben létrehozott összes összetevővel való munkához. A munkaterület létrehozásával kapcsolatos utasításokért lásd a munkaterület erőforrásainak létrehozását ismertető témakört.
Feljegyzés
Ha a munkaterület virtuális hálózatot használ, további konfigurációs lépéseket kell végrehajtania a tervező használatához. További információ: Az Azure Machine Learning Studio használata Azure-beli virtuális hálózaton
A folyamat létrehozása
Feljegyzés
A Tervező két összetevőtípust támogat, a klasszikus előre összeállított összetevőket és az egyéni összetevőket. Ez a két összetevőtípus nem kompatibilis.
A klasszikus előre összeállított összetevők elsősorban az adatfeldolgozáshoz és a hagyományos gépi tanulási feladatokhoz, például a regresszióhoz és a besoroláshoz biztosítanak előre összeállított összetevőket. Ez az összetevőtípus továbbra is támogatott marad, de nem lesznek új összetevők hozzáadva.
Az egyéni összetevők lehetővé teszik, hogy saját kódot adjon meg összetevőként. Támogatja a munkaterületek közötti megosztást és a zökkenőmentes szerkesztést a Studio, a parancssori felület és az SDK felületei esetében.
Ez a cikk a klasszikus előre összeállított összetevőkre vonatkozik.
Jelentkezzen be a ml.azure.com, és válassza ki a használni kívánt munkaterületet.
Tervező kiválasztása –> Klasszikus előre összeállított
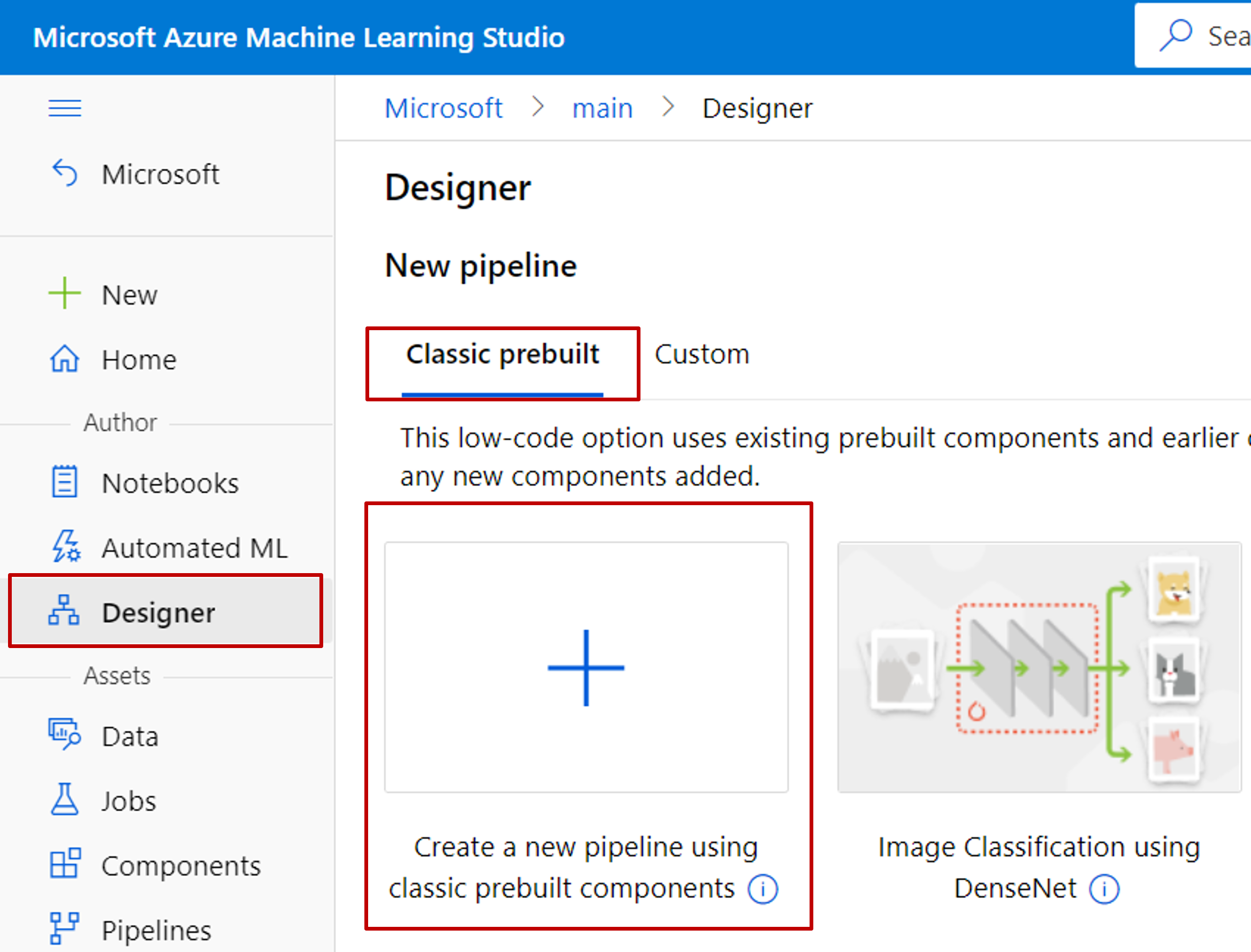
Válassza a Create a new pipeline using classic prebuilt components (Új folyamat létrehozása klasszikus előre összeállított összetevőkkel) lehetőséget.
Kattintson a ceruza ikonra az automatikusan létrehozott folyamat piszkozat neve mellett, nevezze át autóár-előrejelzésre. A névnek nem kell egyedinek lennie.
Adatok importálása
A tervező számos mintaadatkészletet tartalmaz, amellyel kísérletezhet. Ehhez az oktatóanyaghoz használja az Automobile price data (Raw) adatokat.
A folyamatvászon bal oldalán található az adathalmazok és összetevők palettája. Válassza az Összetevő –> Mintaadatok lehetőséget.
Jelölje ki az Autóárak (Nyers) adathalmazt, és húzza a vászonra.
Az adatok vizualizációja
Az adatokat vizualizálva megismerheti a használni kívánt adathalmazt.
Kattintson a jobb gombbal az Autóárak adataira (Nyers), és válassza az Előzetes adatok lehetőséget.
Válassza ki az adatablak különböző oszlopait az egyes oszlopok adatainak megtekintéséhez.
Minden sor egy autót jelöl, és az egyes autókhoz társított változók oszlopokként jelennek meg. Ebben az adatkészletben 205 sor és 26 oszlop található.
Adatok előkészítése
Az adathalmazok általában előzetes feldolgozást igényelnek az elemzés előtt. Előfordulhat, hogy néhány hiányzó értéket észlelt az adathalmaz vizsgálatakor. Ezeket a hiányzó értékeket törölni kell, hogy a modell megfelelően elemezhesse az adatokat.
Oszlop eltávolítása
Egy modell betanításakor tennie kell valamit a hiányzó adatokkal kapcsolatban. Ebben az adatkészletben a normalizált veszteségek oszlopban sok érték hiányzik, ezért ezt az oszlopot teljesen kizárja a modellből.
A vászontól balra található adathalmazokban és összetevő-palettán kattintson az Összetevő elemre, és keresse meg az Adathalmaz összetevő Oszlopainak kijelölése elemét.
Húzza az Adathalmaz oszlopainak kijelölése összetevőt a vászonra. Húzza az összetevőt az adathalmaz-összetevő alá.
Csatlakoztassa az Automobile price data (Raw) adatkészletet az Adathalmaz oszlopainak kiválasztása összetevőhöz. Húzza az adathalmaz kimeneti portjáról , amely a vászonon lévő adathalmaz alján lévő kis kör, az Adathalmaz oszlopainak kijelölése bemeneti portjára, amely az összetevő tetején lévő kis kör.
Tipp.
Amikor egy összetevő kimeneti portját egy másik bemeneti portjához csatlakoztatja, a folyamaton keresztül hozhat létre adatfolyamot.
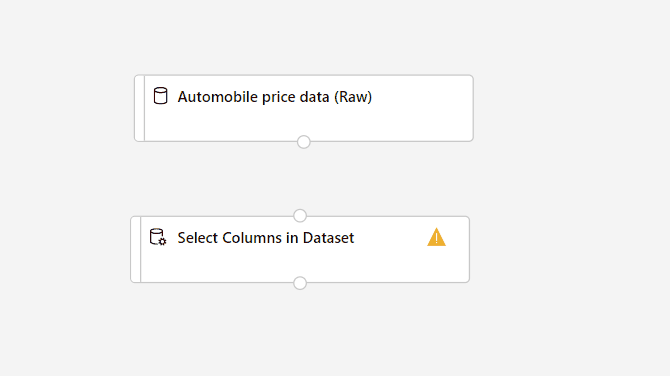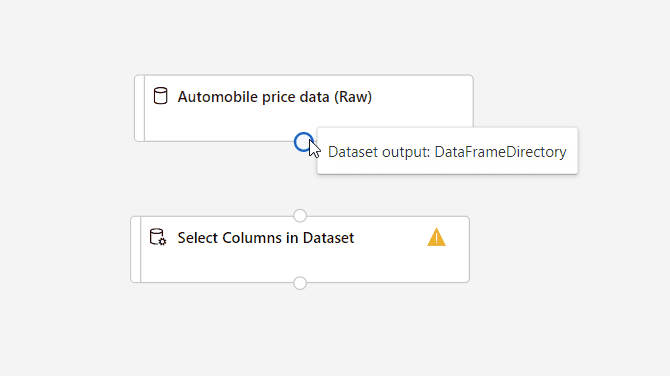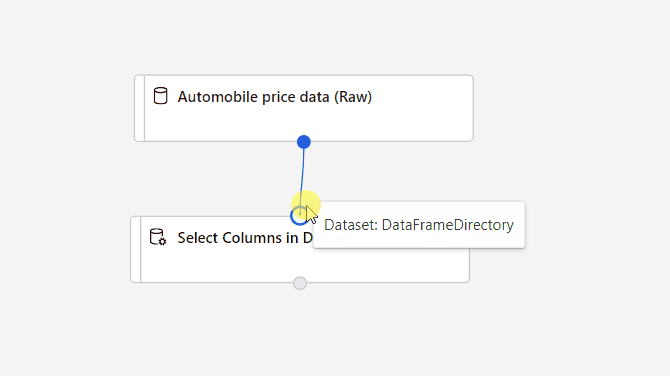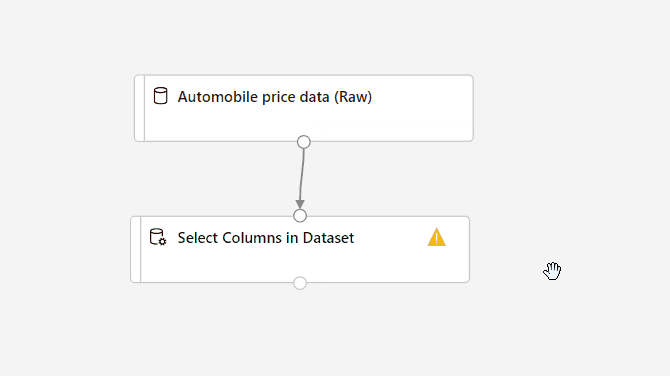
Válassza ki az Adathalmaz-összetevő Oszlopok kijelölése elemét.
Kattintson a vászon jobb oldalán található Beállítások ikonra az összetevő részletei panel megnyitásához. Másik lehetőségként kattintson duplán az Adathalmaz oszlopainak kijelölése összetevőre a részletek panel megnyitásához.
Válassza a panel jobb oldalán található Szerkesztés oszlopot .
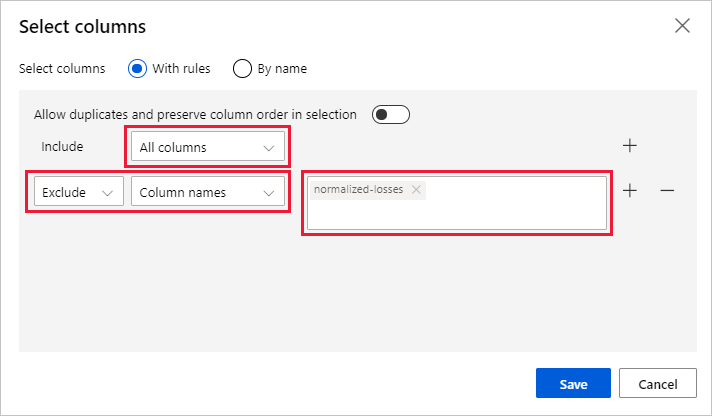
Bontsa ki az Oszlopnevek legördülő listában a Belefoglalás lehetőséget, és válassza az Összes oszlop lehetőséget.
Válassza ki az + új szabály hozzáadásához.
A legördülő menükben válassza a Kizárás és az Oszlopnevek lehetőséget.
Írja be a normalizált veszteségeket a szövegmezőbe.
A jobb alsó sarokban válassza a Mentés lehetőséget az oszlopválasztó bezárásához.
Az Adathalmaz-összetevő részletei panel Oszlopok kijelölése paneljén bontsa ki a Csomópont adatai lehetőséget.
Jelölje ki a Megjegyzés szövegmezőt, és írja be a Normalizált veszteségek kizárása lehetőséget.
A gráfon megjegyzések jelennek meg, amelyek segítenek a folyamat rendszerezésében.
Hiányzó adatok törlése
Az adathalmaz továbbra is hiányzó értékekkel rendelkezik a normalizált veszteségek oszlop eltávolítása után. A fennmaradó hiányzó adatokat a Hiányzó adatok törlése összetevővel távolíthatja el.
Tipp.
A hiányzó értékeknek a bemeneti adatokból való megtisztítása előfeltétele a legtöbb összetevő tervezőben való használatának.
A vászon bal oldalán található adathalmazokban és összetevő-palettán kattintson az Összetevő elemre, és keresse meg a Hiányzó adatok törlése összetevőt.
Húzza a Hiányzó adatok törlése összetevőt a folyamatvászonra. Csatlakoztassa az Adathalmaz-összetevő Oszlopválasztás eleméhez.
Válassza a Hiányzó adatok törlése összetevőt.
Kattintson a vászon jobb oldalán található Beállítások ikonra az összetevő részletei panel megnyitásához. Másik lehetőségként kattintson duplán a Hiányzó adatok törlése összetevőre a részletek panel megnyitásához.
Válassza a panel jobb oldalán található Szerkesztés oszlopot .
A tisztítandó oszlopok ablakban bontsa ki a Belefoglalás melletti legördülő menüt. Kijelölés, Minden oszlop
Válassza a Mentés lehetőséget
A Hiányzó adatok törlése összetevő részletei panel Tisztítás módban válassza a Teljes sor eltávolítása lehetőséget.
A Hiányzó adatok törlése összetevő részletei panelen bontsa ki a Csomópont adatai lehetőséget.
Jelölje ki a Megjegyzés szövegmezőt, és írja be a Hiányzó értéksorok eltávolítása parancsot.
A folyamatnak így kell kinéznie:
Gépi tanulási modell betanítása
Most, hogy már rendelkezik az adatok feldolgozásához szükséges összetevőkkel, beállíthatja a betanítási összetevőket.
Mivel előre szeretné jelezni az árat, ami egy szám, használhat regressziós algoritmust. Ebben a példában lineáris regressziós modellt használ.
Az adatok felosztása
Az adatok felosztása gyakori feladat a gépi tanulásban. Az adatokat két különálló adatkészletre fogja felosztani. Az egyik adatkészlet betanozza a modellt, a másik pedig teszteli, hogy a modell milyen jól teljesített.
A vászon bal oldalán található adathalmazokban és összetevő-palettán kattintson az Összetevő elemre, és keresse meg az Adatok felosztása összetevőt.
Húzza az Adatok felosztása összetevőt a folyamatvászonra.
Csatlakoztassa a Hiányzó adatok törlése összetevő bal oldali portját az Adatok felosztása összetevőhöz.
Fontos
Győződjön meg arról, hogy a Tiszta hiányzó adatok bal oldali kimeneti portja csatlakozik a felosztott adatokhoz. A bal oldali port tartalmazza a megtisztított adatokat. A megfelelő port tartalmazza az elvetett adatokat.
Válassza ki az Adatok felosztása összetevőt.
Kattintson a vászon jobb oldalán található Beállítások ikonra az összetevő részletei panel megnyitásához. Másik lehetőségként kattintson duplán az Adatok felosztása összetevőre a részletek panel megnyitásához.
Az Adatok felosztása panelen állítsa az első kimeneti adathalmaz sorainak törtrészét 0,7-re.
Ez a beállítás az adatok 70 százalékát felosztja a modell betanításához, 30 százalékát pedig teszteléshez. A 70%-os adathalmaz a bal oldali kimeneti porton keresztül lesz elérhető. A fennmaradó adatok a megfelelő kimeneti porton keresztül érhetők el.
Az Adatok felosztása panelen bontsa ki a Csomópont adatai lehetőséget.
Jelölje ki a Megjegyzés szövegmezőt, és írja be Az adathalmaz felosztása betanítási csoportra (0.7) és tesztkészletre (0.3).
A modell betanítása
Betanítsa a modellt úgy, hogy egy olyan adatkészletet ad neki, amely tartalmazza az árat. Az algoritmus létrehoz egy modellt, amely elmagyarázza a funkciók és az ár közötti kapcsolatot a betanítási adatok szerint.
A vászon bal oldalán található adathalmazokban és összetevő-palettán kattintson az Összetevő elemre, és keresse meg a lineáris regressziós összetevőt.
Húzza a lineáris regressziós összetevőt a folyamatvászonra.
A vászon bal oldalán található adatkészletekben és összetevő-palettán kattintson az Összetevő elemre, és keresse meg a Modell betanítása összetevőt.
Húzza a Modell betanítása összetevőt a folyamatvászonra.
Csatlakoztassa a lineáris regressziós összetevő kimenetét a Betanítási modell összetevő bal oldali bemenetéhez.
Csatlakoztassa a Split Data összetevő betanítási adatkimenetét (bal oldali portját) a Modell betanítása összetevő jobb bemenetéhez.
Fontos
Győződjön meg arról, hogy a Split Data bal oldali kimeneti portja csatlakozik a Betanítási modellhez. A bal oldali port tartalmazza a betanítási csoportot. A megfelelő port tartalmazza a tesztkészletet.
Válassza ki a Modell betanítása összetevőt.
Kattintson a vászon jobb oldalán található Beállítások ikonra az összetevő részletei panel megnyitásához. Másik lehetőségként kattintson duplán a Modell betanítása összetevőre a részletek panel megnyitásához.
Válassza a panel jobb oldalán található Szerkesztés oszlopot .
A megjelenő Címke oszlopablakban bontsa ki a legördülő menüt, és válassza az Oszlopnevek lehetőséget.
A szövegmezőbe írja be az árat a modell által előrejelezni kívánt érték megadásához.
Fontos
Győződjön meg arról, hogy pontosan megadja az oszlop nevét. Ne nagybetűsítse az árat.
A folyamatnak így kell kinéznie:
A Score Model összetevő hozzáadása
Miután betanított egy modellt az adatok 70 százalékával, a többi 30 százalékot is felhasználhatja a modell működésének megtekintéséhez.
A vászontól balra található adathalmazokban és összetevő-palettán kattintson az Összetevő elemre, és keresse meg a Score Model összetevőt.
Húzza a Score Model összetevőt a folyamatvászonra.
Csatlakoztassa a Modell betanítása összetevő kimenetét a Score Model bal oldali bemeneti portjához. Csatlakoztassa a Split Data összetevő tesztadat-kimenetét (jobb portját) a Score Model megfelelő bemeneti portjához.
A Modell kiértékelése összetevő hozzáadása
A Modell kiértékelése összetevő használatával kiértékelheti, hogy a modell milyen jól értékelte a tesztadatkészletet.
A vászontól balra található adathalmazokban és összetevő-palettán kattintson az Összetevő elemre, és keresse meg a Modell kiértékelése összetevőt.
Húzza a Modell kiértékelése összetevőt a folyamatvászonra.
Csatlakoztassa a Score Model összetevő kimenetét a Modell kiértékelése bal oldali bemenetéhez.
A végső folyamatnak így kell kinéznie:
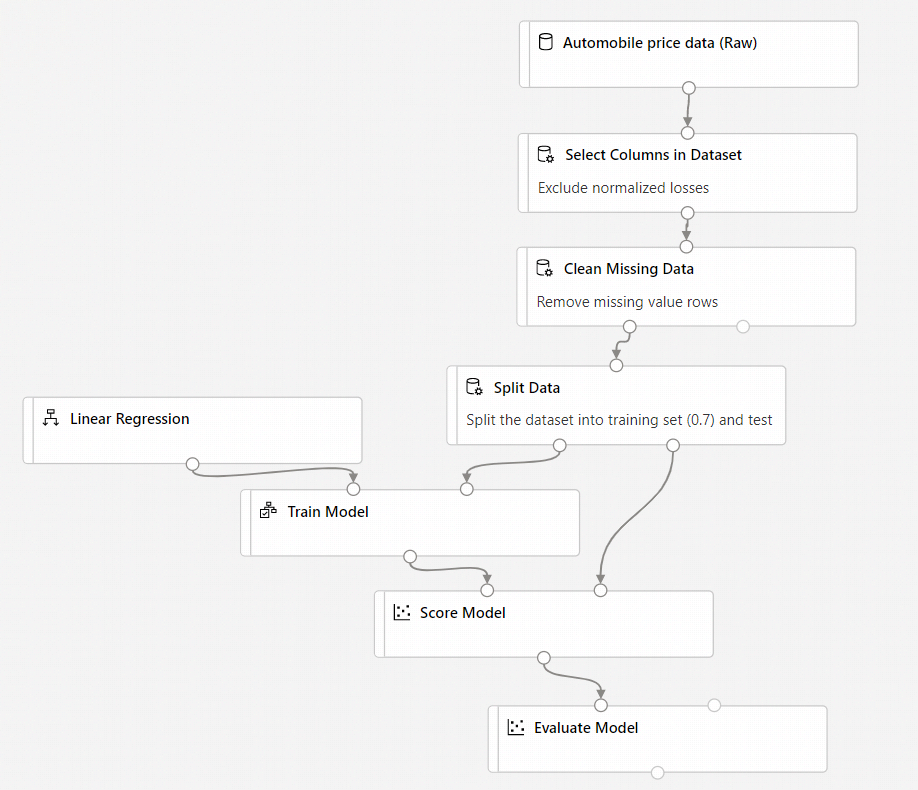
Folyamat elküldése
A folyamat elküldéséhez válassza a Konfigurálás > Küldés lehetőséget a jobb felső sarokban.

Ezután megjelenik egy lépésenkénti varázsló, amely a varázslót követve küldi el a folyamatfeladatot.
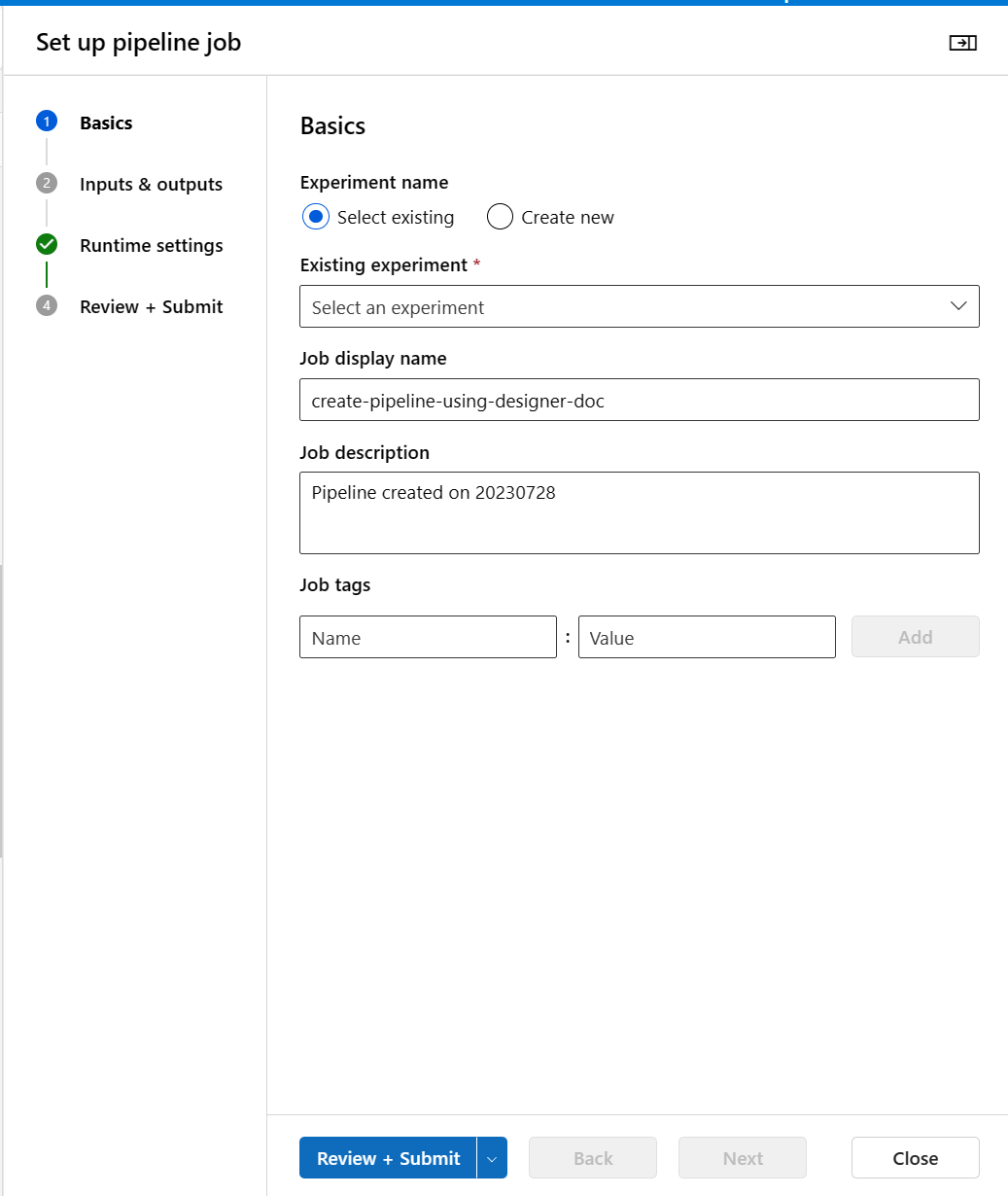

Az Alapszintű lépésekben konfigurálhatja a kísérletet, a feladat megjelenítendő nevét, a feladat leírását stb.
A Bemenetek és kimenetek lépésben a folyamatszintre előléptetett bemenetekhez/kimenetekhez rendelhet értéket. Ebben a példában üres lesz, mert nem előléptettünk semmilyen bemenetet/kimenetet a folyamat szintjére.
A futtatókörnyezet beállításaiban konfigurálhatja az alapértelmezett adattárat és az alapértelmezett számítást a folyamathoz. Ez a folyamat összes összetevőjének alapértelmezett adattára/számítása. Ha azonban explicit módon állít be egy másik számítási vagy adattárat egy összetevőhöz, a rendszer tiszteletben tartja az összetevőszint-beállítást. Ellenkező esetben az alapértelmezett értéket használja.
A Véleményezés + Küldés lépés az utolsó lépés az összes beállítás áttekintéséhez a küldés előtt. A varázsló emlékezni fog az utolsó konfigurációra, ha valaha beküldi a folyamatot.
A folyamatfeladat elküldése után a tetején egy üzenet jelenik meg, amely a feladat részleteire mutató hivatkozást tartalmaz. Erre a hivatkozásra kattintva áttekintheti a feladat részleteit.

Pontozott címkék megtekintése
A feladat részletei lapon ellenőrizheti a folyamatfeladat állapotát, eredményeit és naplóit.
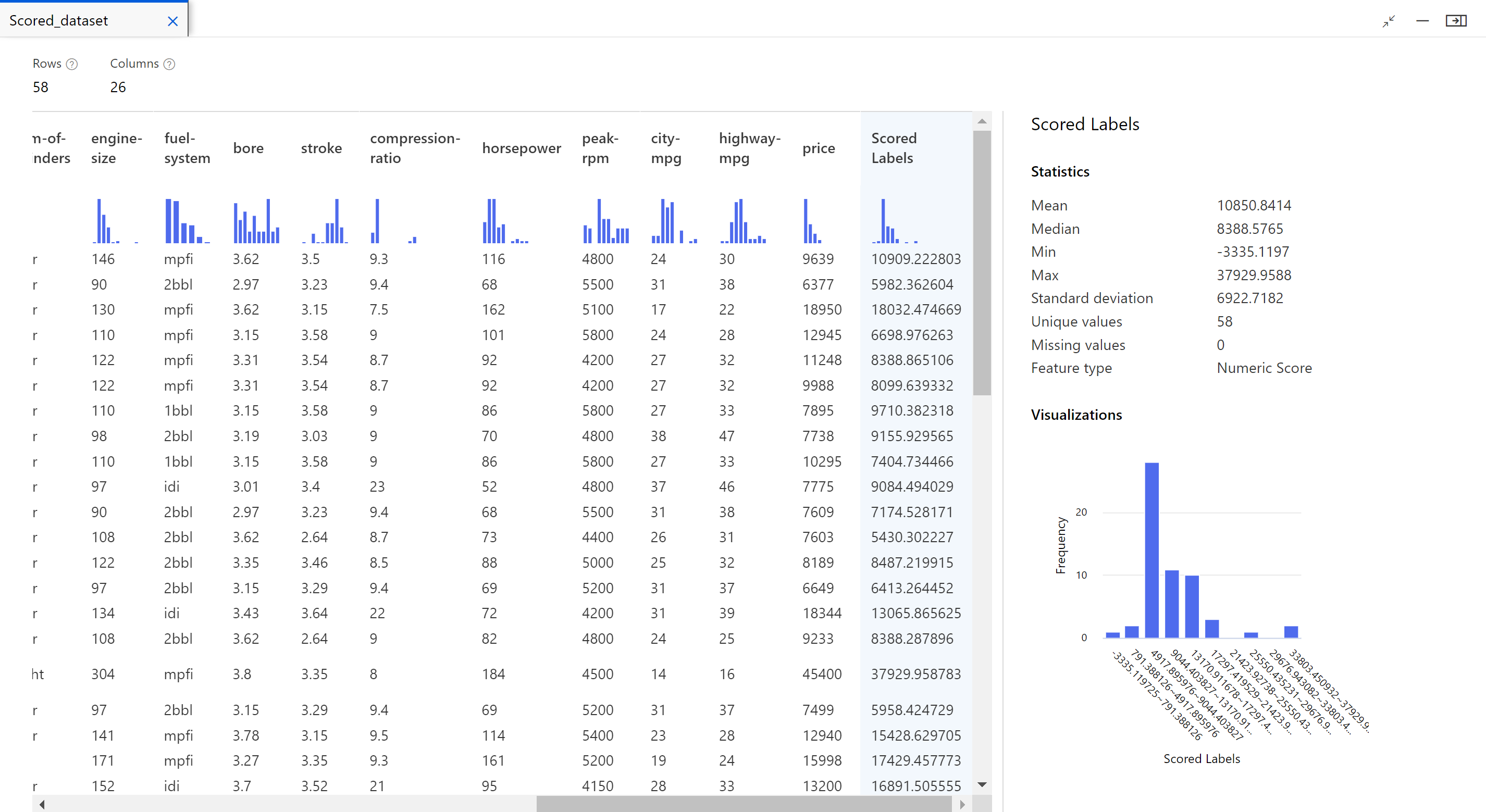
A feladat befejezése után megtekintheti a folyamatfeladat eredményeit. Először tekintse meg a regressziós modell által generált előrejelzéseket.
Kattintson a jobb gombbal a Score Model összetevőre, és válassza az Előnézeti adatok>pontozott adatkészletet a kimenet megtekintéséhez.
Itt láthatja az előrejelzett árakat és a tényleges árakat a tesztelési adatokból.
Modellek kiértékelése
A Modell kiértékelése funkcióval megtekintheti, hogy a betanított modell milyen jól teljesített a tesztadatkészleten.
- Kattintson a jobb gombbal a Modell kiértékelése összetevőre, és válassza az Előzetes adatok>kiértékelési eredményei lehetőséget a kimenet megtekintéséhez.
A modellhez a következő statisztikák jelennek meg:
- Átlagos abszolút hiba (MAE): Az abszolút hibák átlaga. A hiba az előrejelzett érték és a tényleges érték közötti különbség.
- Root Mean Squared Error (gyökátlagos négyzetes eltérés, RMSE): a tesztelési adathalmazon végzett előrejelzések eltéréseinek négyzetéből számított átlag négyzetgyöke.
- Relative Absolute Error (relatív abszolút eltérés): a tényleges értékek és az összes tényleges értékek átlaga közötti különbségek abszolút eltérésének átlaga.
- Relative Squared Error (relatív négyzetes eltérés): a négyzetes eltérések átlaga a tényleges értékek és az összes tényleges érték átlaga közötti különbség négyzetes értékéhez viszonyítva.
- Meghatározási együttható: Az R négyzetes értéknek is nevezett statisztikai metrika azt jelzi, hogy egy modell mennyire illeszkedik az adatokhoz.
Az összes hibastatisztikára igaz, hogy minél kisebb az érték, annál jobb a modell. Egy kisebb érték azt jelzi, hogy az előrejelzések közelebb vannak a tényleges értékekhez. A meghatározási együttható esetében minél közelebb van az értéke egyhez (1.0), annál jobbak az előrejelzések.
Az erőforrások eltávolítása
Hagyja ki ezt a szakaszt, ha folytatni szeretné az oktatóanyag 2. részével, a modellek üzembe helyezésével.
Fontos
A létrehozott erőforrásokat más Azure Machine Learning-oktatóanyagok és útmutatók előfeltételeiként használhatja.
Minden törlése
Ha nem tervez semmit, amit létrehozott, törölje a teljes erőforráscsoportot, hogy ne járjon költségekkel.
Az Azure Portalon válassza ki az erőforráscsoportokat az ablak bal oldalán.
A listában válassza ki a létrehozott erőforráscsoportot.
Válassza az Erőforráscsoport törlése elemet.
Az erőforráscsoport törlése a tervezőben létrehozott összes erőforrást is törli.
Egyes objektumok törlése
Abban a tervezőben, ahol létrehozta a kísérletet, törölje az egyes objektumokat a kijelöléssel, majd a Törlés gombra kattintva.
Az itt létrehozott számítási cél automatikusan nulla csomópontra skálázódik automatikusan, ha nincs használatban. Ez a művelet a díjak minimalizálása érdekében történik. Ha törölni szeretné a számítási célt, hajtsa végre az alábbi lépéseket:
Az adathalmazok regisztrációját a munkaterületről az egyes adathalmazok kiválasztásával és a Regisztráció törlése lehetőség kiválasztásával szüntetheti meg.
Adathalmaz törléséhez lépjen a tárfiókba az Azure Portal vagy az Azure Storage Explorer használatával, és törölje manuálisan ezeket az eszközöket.
Következő lépések
A második részben megtanulhatja, hogyan helyezheti üzembe a modellt valós idejű végpontként.