Az Apache Spark (Azure Synapse Analytics által működtetett) használata a gépi tanulási folyamatban (elavult)
A KÖVETKEZŐKRE VONATKOZIK: Python SDK azureml v1
Python SDK azureml v1
Figyelmeztetés
A Python SDK v1-ben elérhető Azure Synapse Analytics-integráció elavult. A felhasználók az Azure Machine Learninggel társított szolgáltatásként regisztrált Synapse-munkaterületet a továbbiakban is használhatják. Új Synapse-munkaterületet azonban már nem lehet regisztrálni az Azure Machine Learninggel társított szolgáltatásként. Javasoljuk, hogy a CLI v2 és a Python SDK v2-ben elérhető felügyelt (automatikus) Synapse-számítási és csatolt Synapse Spark-készleteket használja. További részletekért lásd https://aka.ms/aml-spark : .
Ebből a cikkből megtudhatja, hogyan használhatja a Azure Synapse Analytics által működtetett Apache Spark-készleteket számítási célként egy Azure Machine Learning-folyamat adatelőkészítési lépéseként. Megtudhatja, hogyan használhatja egyetlen folyamat az adott lépéshez megfelelő számítási erőforrásokat, például az adatok előkészítését vagy a betanítást. Látni fogja, hogyan készülnek fel az adatok a Spark-lépésre, és hogyan lesznek átadva a következő lépésnek.
Előfeltételek
Hozzon létre egy Azure Machine Learning-munkaterületet az összes folyamaterőforrás tárolásához.
Konfigurálja a fejlesztési környezetet az Azure Machine Learning SDK telepítéséhez, vagy használjon egy Azure Machine Learning számítási példányt a már telepített SDK-val.
Azure Synapse Analytics-munkaterület és Apache Spark-készlet létrehozása (lásd: Rövid útmutató: Kiszolgáló nélküli Apache Spark-készlet létrehozása Synapse Studio használatával).
Az Azure Machine Learning-munkaterület és a Azure Synapse Analytics-munkaterület összekapcsolása
Az Apache Spark-készleteket egy Azure Synapse Analytics-munkaterületen hozhatja létre és felügyelheti. Ha egy Apache Spark-készletet egy Azure Machine Learning-munkaterülettel szeretne integrálni, az Azure Synapse Analytics-munkaterületre kell hivatkoznia.
Miután összekapcsolta az Azure Machine Learning-munkaterületet és a Azure Synapse Analytics-munkaterületeket, csatolhat egy Apache Spark-készletet az
Python SDK (az alábbiak szerint)
Azure Resource Manager (ARM) sablon (lásd ezt az ARM-példasablont).
- A parancssor használatával követheti az ARM-sablont, hozzáadhatja a társított szolgáltatást, és csatolhatja az Apache Spark-készletet a következő kóddal:
az deployment group create --name --resource-group <rg_name> --template-file "azuredeploy.json" --parameters @"azuredeploy.parameters.json"
Fontos
Az Azure Synapse Analytics-munkaterületre való sikeres csatoláshoz tulajdonosi szerepkörrel kell rendelkeznie az Azure Synapse Analytics-munkaterület erőforrásában. A hozzáférését az Azure Portalon ellenőrizheti.
A társított szolgáltatás létrehozásakor rendszer által hozzárendelt felügyelt identitást (SAI) kap. Ehhez a hivatkozási szolgáltatás SAI-jának "Synapse Apache Spark-rendszergazda" szerepkört kell hozzárendelnie Synapse Studio-től, hogy elküldhesse a Spark-feladatot (lásd: Synapse RBAC-szerepkör-hozzárendelések kezelése Synapse Studio).
Az Azure Machine Learning-munkaterület felhasználójának "Közreműködő" szerepkört is meg kell adnia az erőforrás-kezelés Azure Portal.
A Azure Synapse Analytics-munkaterület és az Azure Machine Learning-munkaterület közötti hivatkozás lekérése
A munkaterületen lévő társított szolgáltatásokat a következő kóddal kérdezheti le:
from azureml.core import Workspace, LinkedService, SynapseWorkspaceLinkedServiceConfiguration
ws = Workspace.from_config()
for service in LinkedService.list(ws) :
print(f"Service: {service}")
# Retrieve a known linked service
linked_service = LinkedService.get(ws, 'synapselink1')
Workspace.from_config() Először is a konfiguráció használatával éri el az Azure Machine Learning-munkaterületet (config.jsonlásd: Munkaterület konfigurációs fájljának létrehozása). Ezután a kód kinyomtatja a munkaterületen elérhető összes társított szolgáltatást. LinkedService.get() Végül lekéri a nevű 'synapselink1'társított szolgáltatást.
Az Apache Spark-készlet csatolása számítási célként az Azure Machine Learninghez
Ha az Apache Spark-készletet szeretné használni a gépi tanulási folyamat egy lépésének végrehajtásához, csatolnia kell azt ComputeTarget a folyamatlépéshez, az alábbi kódban látható módon.
from azureml.core.compute import SynapseCompute, ComputeTarget
attach_config = SynapseCompute.attach_configuration(
linked_service = linked_service,
type="SynapseSpark",
pool_name="spark01") # This name comes from your Synapse workspace
synapse_compute=ComputeTarget.attach(
workspace=ws,
name='link1-spark01',
attach_configuration=attach_config)
synapse_compute.wait_for_completion()
Az első lépés a konfigurálása SynapseCompute. Az linked_service argumentum az előző LinkedService lépésben létrehozott vagy lekért objektum. Az type argumentumnak a következőnek kell lennie SynapseSpark: . A pool_name argumentumnak SynapseCompute.attach_configuration() meg kell egyeznie a Azure Synapse Analytics-munkaterület egyik meglévő készletével. Az Apache Spark-készlet Azure Synapse Analytics-munkaterületen való létrehozásával kapcsolatos további információkért lásd: Rövid útmutató: Kiszolgáló nélküli Apache Spark-készlet létrehozása Synapse Studio használatával. A típusa attach_config .ComputeTargetAttachConfiguration
A konfiguráció létrehozása után létre kell hoznia egy gépi tanulást ComputeTarget a Workspace, ComputeTargetAttachConfigurationés a név megadásával, amellyel hivatkozni szeretne a gépi tanulási munkaterületen belüli számításra. A hívás ComputeTarget.attach() aszinkron, így a minta blokkolja, amíg a hívás befejeződik.
SynapseSparkStep Csatolt Apache Spark-készletet használó létrehozása
Az Apache Spark-készleten lévő Spark-mintajegyzetfüzet-feladat egy egyszerű gépi tanulási folyamatot határoz meg. Először is a jegyzetfüzet egy adat-előkészítési lépést határoz meg, amelyet az synapse_compute előző lépésben meghatározottak hajtanak. Ezután a jegyzetfüzet meghatároz egy betanításhoz jobban alkalmas számítási célra épülő betanítási lépést. A mintajegyzetfüzet a Titanic túlélési adatbázisát használja az adatok bemenetének és kimenetének szemléltetésére; valójában nem tisztítja meg az adatokat, és nem készít prediktív modellt. Mivel ebben a mintában nincs valós betanítás, a betanítási lépés egy olcsó, CPU-alapú számítási erőforrást használ.
Az adatok objektumokon keresztül áramlik egy gépi DatasetConsumptionConfig tanulási folyamatba, amely táblázatos adatokat vagy fájlkészleteket tárolhat. Az adatok gyakran a munkaterület adattárában található Blob Storage-fájlokból származnak. Az alábbi kód néhány tipikus kódot mutat be egy gépi tanulási folyamat bemenetének létrehozásához:
from azureml.core import Dataset
datastore = ws.get_default_datastore()
file_name = 'Titanic.csv'
titanic_tabular_dataset = Dataset.Tabular.from_delimited_files(path=[(datastore, file_name)])
step1_input1 = titanic_tabular_dataset.as_named_input("tabular_input")
# Example only: it wouldn't make sense to duplicate input data, especially one as tabular and the other as files
titanic_file_dataset = Dataset.File.from_files(path=[(datastore, file_name)])
step1_input2 = titanic_file_dataset.as_named_input("file_input").as_hdfs()
A fenti kód feltételezi, hogy a fájl Titanic.csv blobtárolóban található. A kód bemutatja, hogyan olvashatja a fájlt TabularDataset és néven FileDataset. Ez a kód csak bemutatási célokra szolgál, mivel zavaró lenne duplikálni a bemeneteket, vagy egyetlen adatforrást táblatartalmú erőforrásként és fájlként is értelmezni.
Fontos
A bemenetként való használathoz FileDataset a azureml-core verziónak legalább 1.20.0a következőnek kell lennie: . Ennek a osztály használatával Environment történő megadásáról az alábbiakban olvashat.
Amikor egy lépés befejeződik, dönthet úgy, hogy a következőhöz hasonló kóddal tárolja a kimeneti adatokat:
from azureml.data import HDFSOutputDatasetConfig
step1_output = HDFSOutputDatasetConfig(destination=(datastore,"test")).register_on_complete(name="registered_dataset")
Ebben az esetben az adatok egy nevű test fájlban datastore lesznek tárolva, és a machine learning-munkaterületen a nevű registered_datasetfájlban Dataset lesznek elérhetők.
Az adatok mellett a folyamatlépések lépésenkénti Python-függőségekkel is rendelkezhetnek. Az egyes SynapseSparkStep objektumok pontos Azure Synapse Apache Spark-konfigurációt is megadhatnak. Ez a következő kódban jelenik meg, amely azt határozza meg, hogy a azureml-core csomagverziónak legalább 1.20.0. (Ahogy korábban említettük, ez a követelmény azureml-core egy bemenetként való használatához FileDataset szükséges.)
from azureml.core.environment import Environment
from azureml.pipeline.steps import SynapseSparkStep
env = Environment(name="myenv")
env.python.conda_dependencies.add_pip_package("azureml-core>=1.20.0")
step_1 = SynapseSparkStep(name = 'synapse-spark',
file = 'dataprep.py',
source_directory="./code",
inputs=[step1_input1, step1_input2],
outputs=[step1_output],
arguments = ["--tabular_input", step1_input1,
"--file_input", step1_input2,
"--output_dir", step1_output],
compute_target = 'link1-spark01',
driver_memory = "7g",
driver_cores = 4,
executor_memory = "7g",
executor_cores = 2,
num_executors = 1,
environment = env)
A fenti kód egyetlen lépést határoz meg az Azure Machine Learning-folyamatban. Ez a lépés environment egy adott azureml-core verziót határoz meg, és szükség esetén további conda- vagy pip-függőségeket is hozzáadhat.
A SynapseSparkStep tömöríti és feltölti a helyi számítógépről az alkönyvtárat ./code. A könyvtár újra létrejön a számítási kiszolgálón, és a lépés az adott könyvtárból futtatja a fájlt dataprep.py . A inputs és outputs a lépés a step1_input1korábban tárgyalt , step1_input2és step1_output objektum. Ezeknek az értékeknek a szkripten belüli elérésének legegyszerűbb módja, dataprep.py ha társítja őket a nevűvel arguments.
Az Apache Spark konstruktor-vezérlőjének következő argumentumkészlete SynapseSparkStep . Az compute_target az 'link1-spark01' , amelyet korábban számítási célként csatoltunk. A többi paraméter határozza meg a használni kívánt memóriát és magokat.
A mintajegyzetfüzet a következő kódot használja a következőhöz dataprep.py:
import os
import sys
import azureml.core
from pyspark.sql import SparkSession
from azureml.core import Run, Dataset
print(azureml.core.VERSION)
print(os.environ)
import argparse
parser = argparse.ArgumentParser()
parser.add_argument("--tabular_input")
parser.add_argument("--file_input")
parser.add_argument("--output_dir")
args = parser.parse_args()
# use dataset sdk to read tabular dataset
run_context = Run.get_context()
dataset = Dataset.get_by_id(run_context.experiment.workspace,id=args.tabular_input)
sdf = dataset.to_spark_dataframe()
sdf.show()
# use hdfs path to read file dataset
spark= SparkSession.builder.getOrCreate()
sdf = spark.read.option("header", "true").csv(args.file_input)
sdf.show()
sdf.coalesce(1).write\
.option("header", "true")\
.mode("append")\
.csv(args.output_dir)
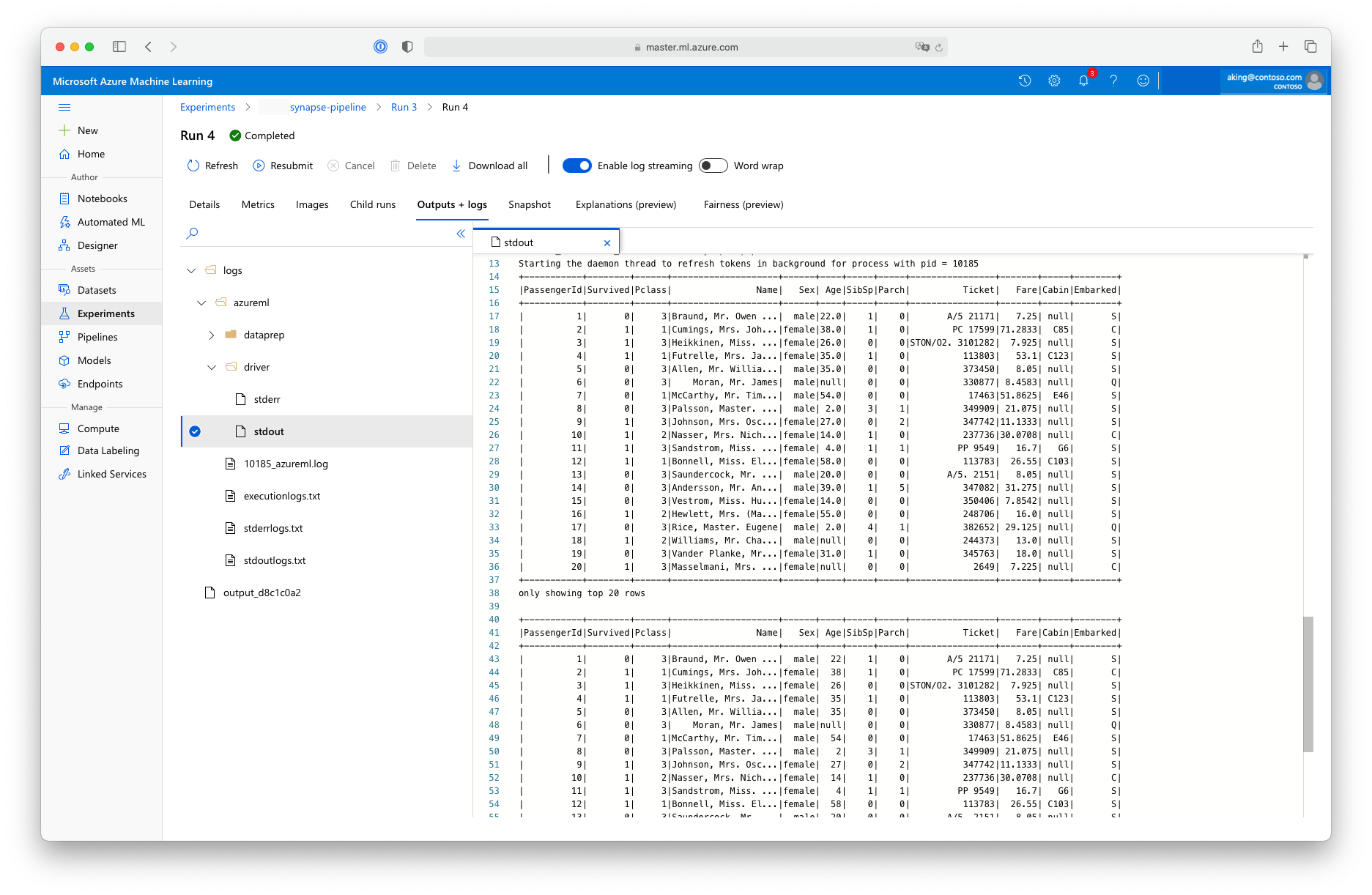
Ez az "adat-előkészítési" szkript nem végez valós adatátalakítást, de bemutatja, hogyan lehet adatokat lekérni, spark-adatkeretté konvertálni, és hogyan lehet elvégezni néhány alapvető Apache Spark-módosítást. A kimenetet az Azure Machine Learning Studióban a gyermekfeladat megnyitásával, az Outputs + logs (Kimenetek és naplók ) lapon, majd a logs/azureml/driver/stdout fájl megnyitásával találja meg az alábbi ábrán látható módon.
SynapseSparkStep A használata folyamatban
Az alábbi példa az előző szakaszban létrehozott kimenetet SynapseSparkStep használja. A folyamat más lépései saját egyedi környezetekkel rendelkezhetnek, és az adott feladatnak megfelelő különböző számítási erőforrásokon futhatnak. A mintajegyzetfüzet a "betanítási lépést" egy kis CPU-fürtön futtatja:
from azureml.core.compute import AmlCompute
cpu_cluster_name = "cpucluster"
if cpu_cluster_name in ws.compute_targets:
cpu_cluster = ComputeTarget(workspace=ws, name=cpu_cluster_name)
print('Found existing cluster, use it.')
else:
compute_config = AmlCompute.provisioning_configuration(vm_size='STANDARD_D2_V2', max_nodes=1)
cpu_cluster = ComputeTarget.create(ws, cpu_cluster_name, compute_config)
print('Allocating new CPU compute cluster')
cpu_cluster.wait_for_completion(show_output=True)
step2_input = step1_output.as_input("step2_input").as_download()
step_2 = PythonScriptStep(script_name="train.py",
arguments=[step2_input],
inputs=[step2_input],
compute_target=cpu_cluster_name,
source_directory="./code",
allow_reuse=False)
A fenti kód szükség esetén létrehozza az új számítási erőforrást. Ezután az step1_output eredmény a betanítási lépés bemenetévé lesz konvertálva. A as_download() beállítás azt jelenti, hogy az adatok a számítási erőforrásba kerülnek, ami gyorsabb hozzáférést eredményez. Ha az adatok olyan nagyok lennének, hogy nem férnének el a helyi számítási merevlemezen, akkor a as_mount() FUSE fájlrendszeren keresztül streamelheti az adatokat. A compute_target második lépés a , 'cpucluster'nem az 'link1-spark01' adat-előkészítési lépésben használt erőforrás. Ez a lépés az előző lépésben használt helyett dataprep.py egy egyszerű programot train.py használ. A részleteket train.py a mintajegyzetfüzetben tekintheti meg.
Miután meghatározta az összes lépést, létrehozhatja és futtathatja a folyamatot.
from azureml.pipeline.core import Pipeline
pipeline = Pipeline(workspace=ws, steps=[step_1, step_2])
pipeline_run = pipeline.submit('synapse-pipeline', regenerate_outputs=True)
A fenti kód létrehoz egy folyamatot, amely a Azure Synapse Analytics () és a betanítási lépés (step_1step_2) által működtetett Apache Spark-készletek adat-előkészítési lépéséből áll. Az Azure a lépések közötti adatfüggőségek vizsgálatával kiszámítja a végrehajtási gráfot. Ebben az esetben csak egy egyszerű függőség szükséges, amelyhez step2_input feltétlenül szükség step1_outputvan.
A hívás, ha pipeline.submit szükséges, létrehoz egy nevű synapse-pipeline kísérletet, és aszinkron módon elindít egy feladatot benne. A folyamat egyes lépései ennek a fő feladatnak a Gyermekfeladataiként futnak, és a Studio Kísérletek oldalán tekinthetők meg és tekinthetők meg.