Teljes szöveges keresés az Azure AI Searchben
A teljes szöveges keresés olyan információlekérési módszer, amely megfelel az indexben tárolt egyszerű szövegeknek. A "Hotelek San Diegóban a tengerparton" lekérdezési sztring alapján például a keresőmotor tokenizált sztringeket keres ezen kifejezések alapján. A vizsgálat hatékonyabbá tétele érdekében a lekérdezési sztringek lexikális elemzésen esnek át: az összes kifejezés alsóbb sorba helyezése, az olyan stopszavak eltávolítása, mint a "the", és a kifejezések primitív gyökéralakokra való csökkentése. Ha talál egyező kifejezéseket, a keresőmotor lekéri a dokumentumokat, relevancia szerinti sorrendbe rendezi őket, és a legjobb eredményeket adja vissza.
A lekérdezés végrehajtása összetett lehet. Ez a cikk azoknak a fejlesztőknek szól, akiknek mélyebb ismeretekre van szükségük a teljes szöveges keresés működéséről az Azure AI Searchben. Szöveges lekérdezések esetén az Azure AI Search zökkenőmentesen biztosítja a várt eredményeket a legtöbb forgatókönyvben, de időnként előfordulhat, hogy valamilyen módon "ki nem használt" eredményt kap. Ezekben a helyzetekben a Lucene-lekérdezések végrehajtásának négy fázisában (lekérdezéselemzés, lexikális elemzés, dokumentumegyeztetés, pontozás) háttérrel azonosíthatja a lekérdezési paraméterek vagy indexkonfigurációk konkrét módosításait, amelyek a kívánt eredményt eredményezik.
Feljegyzés
Az Azure AI Search az Apache Lucene-t használja a teljes szöveges kereséshez, de a Lucene-integráció nem teljes. Szelektíven tesszük elérhetővé és kiterjesztjük a Lucene-funkciókat, hogy engedélyezzük az Azure AI Search számára fontos forgatókönyveket.
Az architektúra áttekintése és diagramja
A lekérdezés végrehajtásának négy szakasza van:
- Lekérdezés elemzése
- Lexikális elemzés
- Dokumentum lekérése
- Pontozás
A teljes szöveges keresési lekérdezés a lekérdezés szövegének elemzésével kezdődik a keresési kifejezések és operátorok kinyeréséhez. Két elemző van, így a sebesség és az összetettség között választhat. A következő elemzési fázis, ahol az egyes lekérdezési kifejezések néha fel vannak bontva, és új űrlapokra vannak újra létrehozva. Ez a lépés segít szélesebb hálót kiterjeszteni arra, hogy mi tekinthető lehetséges egyezésnek. A keresőmotor ezután megvizsgálja az indexet, hogy megkeresse az egyező kifejezéseket tartalmazó dokumentumokat, és minden egyes egyezést pontozza. Az eredményhalmazt ezután az egyes egyező dokumentumokhoz rendelt relevanciapont alapján rendezi. A rangsorolt lista tetején lévőket a rendszer visszaadja a hívó alkalmazásnak.
Az alábbi ábra a keresési kérelmek feldolgozásához használt összetevőket mutatja be.
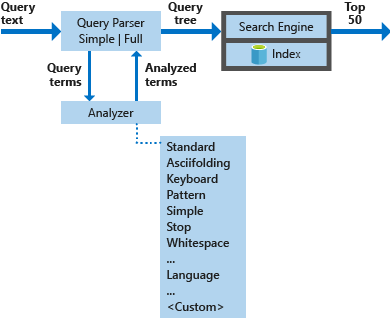
| A legfontosabb összetevők | Funkcionális leírás |
|---|---|
| Lekérdezéselemzők | Különítse el a lekérdezési kifejezéseket a lekérdezési operátoroktól, és hozza létre a keresőmotornak küldendő lekérdezési struktúrát (egy lekérdezési fát). |
| Analizátorok | Lexikális elemzést végezhet a lekérdezési kifejezéseken. Ez a folyamat magában foglalhatja a lekérdezési kifejezések átalakítását, eltávolítását vagy kibővítését. |
| Index | Hatékony adatstruktúra az indexelt dokumentumokból kinyert kereshető kifejezések tárolására és rendszerezésére. |
| Kereső | Lekéri és pontozza az egyező dokumentumokat az invertált index tartalma alapján. |
A keresési kérelmek működése
A keresési kérések a találathalmazban visszaadandó eredmény teljes specifikációját jelentik. Legegyszerűbb formában ez egy üres lekérdezés, semmilyen feltétel nélkül. Egy reálisabb példa paramétereket, több lekérdezési kifejezést is tartalmaz, esetleg bizonyos mezőkre terjed ki, esetleg szűrőkifejezéssel és rendezési szabályokkal.
Az alábbi példa egy keresési kérés, amelyet a REST API használatával küldhet az Azure AI Searchnek.
POST /indexes/hotels/docs/search?api-version=2023-11-01
{
"search": "Spacious, air-condition* +\"Ocean view\"",
"searchFields": "description, title",
"searchMode": "any",
"filter": "price ge 60 and price lt 300",
"orderby": "geo.distance(location, geography'POINT(-159.476235 22.227659)')",
"queryType": "full"
}
Ebben a kérésben a keresőmotor a következő műveleteket hajtja végre:
Megkeresi azokat a dokumentumokat, ahol az ár legalább 60 usd, és nem éri el a 300 USD-t.
Végrehajtja a lekérdezést. Ebben a példában a keresési lekérdezés kifejezésekből és kifejezésekből áll:
"Spacious, air-condition* +\"Ocean view\""(a felhasználók általában nem írnak be írásjeleket, de a példában való belefogalmazás lehetővé teszi számunkra, hogy elmagyarázzuk, hogyan kezelik az elemzők).Ebben a lekérdezésben a keresőmotor megvizsgálja a "searchFields" kifejezésben megadott leírás- és címmezőket az olyan dokumentumokban, amelyek a kifejezést
"spacious", illetve az előtaggal"air-condition"kezdődő kifejezéseket tartalmazzák"Ocean view". A "searchMode" paraméter bármely kifejezés (alapértelmezett) vagy mindegyik esetében használható, olyan esetekben, amikor nincs explicit módon szükség egy kifejezésre (+).Az eredményül kapott szállodacsoportot egy adott földrajzi hely közelében rendeli meg, majd visszaadja az eredményeket a hívó alkalmazásnak.
A cikk a keresési lekérdezés feldolgozásáról szól: "Spacious, air-condition* +\"Ocean view\"". A szűrés és a rendezés hatókörön kívül esik. További információkért tekintse meg a Search API referenciadokumentációját.
1. szakasz: Lekérdezés elemzése
Mint megjegyeztük, a lekérdezési sztring a kérés első sora:
"search": "Spacious, air-condition* +\"Ocean view\"",
A lekérdezéselemző elválasztja az operátorokat (például * és + a példában) a keresési kifejezésektől, és a keresési lekérdezést egy támogatott típusú allekérdezésekre bontja:
- önálló kifejezések kifejezés-lekérdezése (például tágas)
- idézett kifejezések kifejezés lekérdezése (például óceánnézet)
- előtag-lekérdezés kifejezésekhez, majd előtag operátor
*(például légkondicionáló)
A támogatott lekérdezéstípusok teljes listájáért tekintse meg a Lucene-lekérdezés szintaxisát
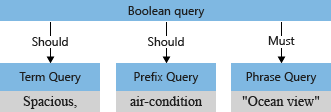
Az allekérdezésekhez társított operátorok határozzák meg, hogy a lekérdezésnek "kell" vagy "teljesülnie" ahhoz, hogy egy dokumentum egyezésnek minősüljön. Az operátor például +"Ocean view" "kötelező" + .
A lekérdezéselemző átalakítja az al lekérdezéseket egy lekérdezési fába (a lekérdezést jelképező belső struktúrába), amely a keresőmotornak továbbítja. A lekérdezési elemzés első szakaszában a lekérdezésfa így néz ki.
Támogatott elemzők: Egyszerű és teljes Lucene
Az Azure AI Search két különböző lekérdezési nyelvet tesz elérhetővé ( simple alapértelmezett) és full. A paraméter keresési kéréssel való beállításával queryType megadhatja a lekérdezéselemzőnek, hogy melyik lekérdezési nyelvet választja, hogy tudja, hogyan értelmezze az operátorokat és a szintaxist.
Az egyszerű lekérdezési nyelv intuitív és robusztus, gyakran alkalmas a felhasználói bemenetek ügyféloldali feldolgozás nélküli értelmezésére. Támogatja a webes keresőmotorok által ismert lekérdezési operátorokat.
A teljes Lucene lekérdezési nyelv, amelyet a beállítással
queryType=fullkap, kibővíti az alapértelmezett egyszerű lekérdezési nyelvet, és további operátorok és lekérdezéstípusok, például helyettesítő, homályos, regex és mező hatókörű lekérdezések támogatását nyújtja. Az egyszerű lekérdezési szintaxisban küldött reguláris kifejezés például lekérdezési sztringként, nem pedig kifejezésként értelmezendő. A cikkben szereplő példakérés a Teljes Lucene lekérdezési nyelvet használja.
A searchMode hatása az elemzőre
Egy másik keresési kérelem paraméter, amely hatással van az elemzésre, a "searchMode" paraméter. A logikai lekérdezések alapértelmezett operátorát vezérli: bármely (alapértelmezett) vagy összes.
Ha a "searchMode=any" az alapértelmezett érték, akkor a tágas és a légkondicionáló közötti térelválasztó VAGY (||), így a minta lekérdezési szöveg a következőnek felel meg:
Spacious,||air-condition*+"Ocean view"
Az explicit operátorok, például + a +"Ocean view"logikai lekérdezések szerkezetében egyértelműek (a kifejezésnek egyeznie kell ). Kevésbé nyilvánvaló, hogyan értelmezzük a fennmaradó kifejezéseket: tágas és légkondicionáló. A keresőmotor keressen találatokat az óceánra néző, tágas és légkondicionált? Vagy meg kell találnia az óceán látképét, plusz a fennmaradó kifejezések egyikét ?
Alapértelmezés szerint ("searchMode=any"), a keresőmotor feltételezi a szélesebb körű értelmezést. Bármelyik mezőnek egyeznie kell , az "vagy" szemantikát tükrözve. A korábban bemutatott kezdeti lekérdezésfa a két "kell" művelettel az alapértelmezett értéket jeleníti meg.
Tegyük fel, hogy most a "searchMode=all" értéket állítjuk be. Ebben az esetben a tér "és" műveletként van értelmezve. A dokumentumban mindkét feltételnek szerepelnie kell, hogy egyezésnek minősüljön. Az eredményként kapott minta lekérdezés a következőképpen lesz értelmezve:
+Spacious,+air-condition*+"Ocean view"
A lekérdezés módosított lekérdezési fája a következő lesz, ahol egy egyező dokumentum mindhárom rész lekérdezésének metszete:

Feljegyzés
A "searchMode=any" kiválasztása a "searchMode=all" kifejezésre a reprezentatív lekérdezések futtatásával legjobban meghozott döntés. Azok a felhasználók, akik valószínűleg operátorokat is belefoglalnak (gyakoriak a dokumentumtárakban való kereséskor), intuitívabb eredményeket találhatnak, ha a "searchMode=all" logikai lekérdezési szerkezeteket tájékoztat. A "searchMode" és az operátorok közötti kölcsönhatásról további információt az Egyszerű lekérdezés szintaxisa című témakörben talál.
2. szakasz: Lexikális elemzés
A lexikális elemzők a lekérdezésfa strukturálása után feldolgozzák a kifejezés- és kifejezés-lekérdezéseket . Az elemző elfogadja az elemző által adott szöveges bemeneteket, feldolgozza a szöveget, majd jogkivonatos kifejezéseket küld vissza, amelyeket a lekérdezési fába kell beépíteni.
A lexikális elemzés leggyakoribb formája a *nyelvi elemzés, amely egy adott nyelvre vonatkozó szabályok alapján alakítja át a lekérdezési kifejezéseket:
- Lekérdezési kifejezés csökkentése egy szó gyökéralakjára
- Nem alapvető szavak eltávolítása (stopwords, például "the" vagy "and" angol nyelven)
- Összetett szó kompatibilitása összetevőkre
- Nagybetűs szó alsó burkolata
Ezek a műveletek általában törlik a felhasználó által megadott szövegbevitel és az indexben tárolt kifejezések közötti különbségeket. Az ilyen műveletek túlmutatnak a szövegfeldolgozáson, és magában a nyelvben részletes ismereteket igényelnek. A nyelvi tudatosság ezen rétegének hozzáadásához az Azure AI Search a Lucene és a Microsoft nyelvelemzőinek hosszú listáját támogatja.
Feljegyzés
Az elemzési követelmények a forgatókönyvtől függően minimálistól a bonyolultig terjedhetnek. A lexikális elemzés összetettségét az előre definiált elemzők egyikének kiválasztásával vagy saját egyéni elemző létrehozásával szabályozhatja. Az elemzők kereshető mezőkre terjednek ki, és egy meződefiníció részeként vannak megadva. Ez lehetővé teszi a lexikális elemzések mezőnkénti variációit. Meghatározatlan, a szabványos Lucene-elemzőt használja a rendszer.
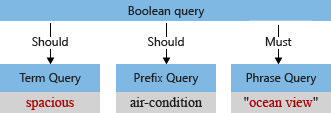
A példánkban az elemzés előtt a kezdeti lekérdezési fa "Tágas" kifejezéssel rendelkezik, egy nagybetűs "S" és egy vesszővel, amelyet a lekérdezéselemző a lekérdezési kifejezés részeként értelmez (a vessző nem tekinthető lekérdezési nyelv operátorának).
Amikor az alapértelmezett elemző feldolgozza a kifejezést, kisbetűs "óceánnézet" és "tágas" lesz, és eltávolítja a vessző karaktert. A módosított lekérdezési fa a következőképpen néz ki:
Az elemző viselkedésének tesztelése
Az elemző viselkedése az Analyze API használatával tesztelhető. Adja meg az elemezni kívánt szöveget, hogy lássa, az adott elemző milyen kifejezéseket hoz létre. Ha például látni szeretné, hogy a standard elemző hogyan dolgozza fel a "légkondicionáló" szöveget, a következő kérést állíthatja ki:
{
"text": "air-condition",
"analyzer": "standard"
}
A standard elemző a bemeneti szöveget a következő két jogkivonatra bontja, és olyan attribútumokkal jegyzeteli őket, mint a kezdő és záró eltolás (a találatok kiemeléséhez használatos), valamint a pozíciójuk (kifejezésmegfeleltetéshez használatos):
{
"tokens": [
{
"token": "air",
"startOffset": 0,
"endOffset": 3,
"position": 0
},
{
"token": "condition",
"startOffset": 4,
"endOffset": 13,
"position": 1
}
]
}
A lexikális elemzés kivételei
A lexikális elemzés csak olyan lekérdezéstípusokra vonatkozik, amelyek teljes kifejezéseket igényelnek – kifejezés-lekérdezésre vagy kifejezés-lekérdezésre. Nem vonatkozik a hiányos kifejezéseket tartalmazó lekérdezéstípusokra – előtagos lekérdezésre, helyettesítő lekérdezésre, regex lekérdezésre – vagy egy homályos lekérdezésre. Ezek a lekérdezéstípusok, beleértve a példánkban szereplő kifejezéssel air-condition* rendelkező előtagot is, közvetlenül a lekérdezésfához lesznek hozzáadva, megkerülve az elemzési szakaszt. Ezeknek a típusoknak a lekérdezési feltételein végrehajtott egyetlen átalakítás az alsóbbfokú.
3. szakasz: Dokumentumlekérés
A dokumentumlekérés az indexben egyező kifejezésekkel rendelkező dokumentumok keresésére utal. Ezt a szakaszt egy példán keresztül értjük a legjobban. Kezdjük azzal, hogy egy hotelindex a következő egyszerű sémával rendelkezik:
{
"name": "hotels",
"fields": [
{ "name": "id", "type": "Edm.String", "key": true, "searchable": false },
{ "name": "title", "type": "Edm.String", "searchable": true },
{ "name": "description", "type": "Edm.String", "searchable": true }
]
}
Feltételezzük továbbá, hogy ez az index a következő négy dokumentumot tartalmazza:
{
"value": [
{
"id": "1",
"title": "Hotel Atman",
"description": "Spacious rooms, ocean view, walking distance to the beach."
},
{
"id": "2",
"title": "Beach Resort",
"description": "Located on the north shore of the island of Kauaʻi. Ocean view."
},
{
"id": "3",
"title": "Playa Hotel",
"description": "Comfortable, air-conditioned rooms with ocean view."
},
{
"id": "4",
"title": "Ocean Retreat",
"description": "Quiet and secluded"
}
]
}
A kifejezések indexelésének menete
A lekérés megértéséhez segít megismerni az indexelés néhány alapjait. A tárolási egység egy invertált index, amely minden kereshető mezőhöz tartozik. Az invertált indexen belül az összes dokumentum összes kifejezésének rendezett listája található. Minden kifejezés megfelel azoknak a dokumentumoknak a listájára, amelyekben előfordul, amint az az alábbi példában is látható.
Ha fordított indexben szeretné létrehozni a kifejezéseket, a keresőmotor lexikális elemzést végez a dokumentumok tartalma felett, hasonlóan ahhoz, ami a lekérdezésfeldolgozás során történik:
- A szöveges bemenetek az elemző konfigurációjától függően kisbetűs, írásjelek és így tovább.
- A jogkivonatok a lexikális elemzés kimenetei.
- A rendszer hozzáadja a kifejezéseket az indexhez.
Gyakori, de nem kötelező ugyanazokat az elemzőket használni a keresési és indexelési műveletekhez, hogy a lekérdezési kifejezések jobban hasonlítson az indexen belüli kifejezésekre.
Feljegyzés
Az Azure AI Search lehetővé teszi, hogy további indexAnalyzer és mezőparamétereken keresztül különböző elemzőket adjon meg az indexeléshez és searchAnalyzer a kereséshez. Ha nincs meghatározva, a tulajdonsággal rendelkező analyzer elemzőkészlet az indexeléshez és a kereséshez is használható.
Invertált index például dokumentumokhoz
A címmezőhöz visszatérve a fordított index a következőképpen néz ki:
| Időszak | Dokumentumlista |
|---|---|
| Atman | 1 |
| Beach | 2 |
| Hotel | 1, 3 |
| Óceán | 4 |
| Playa | 3 |
| Resort | 3 |
| Visszavonulás | 4 |
A cím mezőben csak a szálloda jelenik meg két dokumentumban: 1, 3.
A leírási mező esetében az index a következő:
| Időszak | Dokumentumlista |
|---|---|
| Levegő | 3 |
| és | 4 |
| Beach | 1 |
| Kondicionált | 3 |
| Kényelmes | 3 |
| Távolság | 1 |
| island | 2 |
| kauaʻi | 2 |
| található | 2 |
| north (észak) | 2 |
| Óceán | 1, 2, 3 |
| / | 2 |
| ekkor | 2 |
| Csendes | 4 |
| Szobák | 1, 3 |
| Félreeső | 4 |
| Shore | 2 |
| Tágas | 1 |
| műveletnek a(z) | 1, 2 |
| felhasználóként a(z) | 1 |
| megtekintés | 1, 2, 3 |
| Gyaloglás | 1 |
| nevű és | 3 |
Lekérdezési kifejezések egyeztetése indexelt kifejezésekhez
A fenti invertált indexek alapján térjünk vissza a minta lekérdezéshez, és nézzük meg, hogyan találhatók egyező dokumentumok a példa lekérdezésünkhöz. Ne feledje, hogy a végső lekérdezési fa a következőképpen néz ki:
A lekérdezés végrehajtása során a rendszer egymástól függetlenül hajtja végre az egyes lekérdezéseket a kereshető mezőkön.
A TermQuery, "tágas", megfelel az 1. dokumentumnak (Hotel Atman).
A "légkondicionáló*" előtag nem felel meg a dokumentumoknak.
Ez a viselkedés néha összezavarja a fejlesztőket. Bár a légkondicionált kifejezés megtalálható a dokumentumban, az alapértelmezett elemző két kifejezésre osztja. Ne feledje, hogy a részleges kifejezéseket tartalmazó előtag-lekérdezések nem lesznek elemezve. Ezért a "légkondicionáló" előtaggal rendelkező kifejezések az invertált indexben jelennek meg, és nem találhatók.
A PhraseQuery,"ocean view" megkeresi az "ocean" és a "view" kifejezéseket, és ellenőrzi a kifejezések közelségét az eredeti dokumentumban. Az 1., a 2. és a 3. dokumentum megfelel a lekérdezésnek a leírásmezőben. Figyelje meg, hogy a 4. dokumentumban az óceán kifejezés szerepel a címben, de nem tekinthető egyezésnek, mivel az "óceánnézet" kifejezést keressük az egyes szavak helyett.
Feljegyzés
A keresési lekérdezések egymástól függetlenül hajthatók végre az Azure AI Search-index összes kereshető mezőjén, hacsak nem korlátozza a searchFields paraméterrel beállított mezőket, ahogyan az a példa keresési kérelemben is látható. A rendszer visszaadja a kijelölt mezők bármelyikében egyező dokumentumokat.
Összességében a szóban forgó lekérdezés esetében az egyező dokumentumok az 1, 2, 3.
4. szakasz: Pontozás
A keresési eredményhalmaz minden dokumentuma relevanciapontot kap. A relevanciapont függvénye az, hogy magasabbra rangsorolja azokat a dokumentumokat, amelyek a keresési lekérdezés által kifejezett felhasználói kérdésekre a legjobban válaszolnak. A pontszám kiszámítása a megfelelt kifejezések statisztikai tulajdonságai alapján történik. A pontozási képlet középpontjában a TF/IDF (kifejezés frekvencia-inverz dokumentum gyakorisága) áll. A ritka és gyakori kifejezéseket tartalmazó lekérdezésekben a TF/IDF előlépteti a ritka kifejezést tartalmazó eredményeket. Például egy hipotetikus indexben, amelyben az összes Wikipedia-szócikk szerepel, az elnök lekérdezésének megfelelő dokumentumokból az elnöknek megfelelő dokumentumok relevánsabbnak minősülnek, mint a dokumentumok, amelyeken megfeleltetik azokat.
Pontozási példa
Idézzük fel a példában szereplő lekérdezésnek megfelelő három dokumentumot:
search=Spacious, air-condition* +"Ocean view"
{
"value": [
{
"@search.score": 0.25610128,
"id": "1",
"title": "Hotel Atman",
"description": "Spacious rooms, ocean view, walking distance to the beach."
},
{
"@search.score": 0.08951007,
"id": "3",
"title": "Playa Hotel",
"description": "Comfortable, air-conditioned rooms with ocean view."
},
{
"@search.score": 0.05967338,
"id": "2",
"title": "Ocean Resort",
"description": "Located on a cliff on the north shore of the island of Kauai. Ocean view."
}
]
}
Az 1. dokumentum azért felelt meg a legjobban a lekérdezésnek, mert mind a tágas kifejezés, mind a szükséges kifejezés óceánnézete a leírás mezőben szerepel. A következő két dokumentum csak az ocean view kifejezésnek felel meg. Meglepő lehet, hogy a 2. és a 3. dokumentum relevanciapontszáma eltérő, annak ellenére, hogy ugyanúgy egyeztek meg a lekérdezéssel. Ennek az az oka, hogy a pontozási képlet több összetevőt tartalmaz, mint csak a TF/IDF. Ebben az esetben a 3. dokumentum valamivel magasabb pontszámot kapott, mert leírása rövidebb. Ismerje meg Lucene gyakorlati pontozási képletét, amelyből megtudhatja, hogy a mezőhossz és más tényezők hogyan befolyásolhatják a relevanciapontszámot.
Egyes lekérdezéstípusok (helyettesítő karakterek, előtagok, regex) mindig állandó pontszámot ad a teljes dokumentum pontszámához. Ez lehetővé teszi, hogy a lekérdezésbővítésen keresztül talált találatok bekerüljenek az eredményekbe, de a rangsorolás befolyásolása nélkül.
Egy példa bemutatja, miért fontos ez. A helyettesítő karakterek keresései, beleértve az előtagkereséseket is, definíció szerint nem egyértelműek, mivel a bemenet egy részleges sztring, amely nagyon sok különböző kifejezés lehetséges egyezéseit tartalmazza (vegye figyelembe a "tour*" bemenetét, a "tourettes", a "tourettes" és a "tourmaline" találatokkal). Az eredmények természetéből adódóan nem lehet ésszerűen következtetni arra, hogy mely kifejezések értékesebbek másoknál. Ezért figyelmen kívül hagyjuk a kifejezés gyakoriságát, amikor a pontozás helyettesítő karakterek, előtagok és regex típusú lekérdezéseket eredményez. Egy részleges és teljes kifejezéseket tartalmazó többrészes keresési kérelemben a részleges bemenet eredményei állandó pontszámmal vannak beépítve, hogy elkerüljék a potenciálisan váratlan találatok felé irányuló elfogultságokat.
Relevanciahangolás
A relevanciapontszámokat kétféleképpen hangolhatja az Azure AI Searchben:
A pontozási profilok szabálykészlet alapján előléptetik a dokumentumokat a rangsorolt találatok listájában. A példánkban a címmezőben egyező dokumentumokat relevánsabbnak tekinthetjük, mint a leírás mezőben egyező dokumentumokat. Továbbá, ha az indexünk minden szállodához rendelkezik ármezővel, alacsonyabb áron előléptethetnénk a dokumentumokat. További információ a pontozási profilok keresési indexhez való hozzáadásáról.
A kifejezésfokozás (csak a Teljes Lucene lekérdezési szintaxisban érhető el) olyan növelő operátort
^biztosít, amely a lekérdezésfa bármely részére alkalmazható. A példánkban a légkondicionáló előtag*keresése helyett a légkondicionáló vagy az előtag pontos kifejezésére is rákereshet, de a pontos kifejezéssel egyező dokumentumok rangsorolása a következő kifejezésre való kiemeléssel érhető el: légkondicionáló^2||légkondicionáló*. További információ a lekérdezések kifejezésnöveléséről.
Pontozás elosztott indexben
Az Azure AI Search összes indexe automatikusan több szegmensre oszlik, így a szolgáltatás vertikális felskálázása vagy leskálázása során gyorsan eloszthatjuk az indexet több csomópont között. Ha egy keresési kérést adnak ki, az egyes szegmensekre külön-külön kerül sor. Az egyes szegmensek eredményei ezután egyesülnek, és pontszám alapján vannak rendezve (ha nincs más rendezés definiálva). Fontos tudni, hogy a pontozó függvény a lekérdezési kifejezés gyakoriságát az inverz dokumentum gyakoriságával súlyolja a szegmensen belüli összes dokumentumban, nem pedig az összes szegmensben!
Ez azt jelenti, hogy egy relevanciapont eltérő lehet az azonos dokumentumok esetében, ha különböző szegmenseken találhatók. Szerencsére az ilyen különbségek általában eltűnnek, mivel az indexben lévő dokumentumok száma egyenletesebb kifejezéseloszlás miatt nő. Nem lehet feltételezni, hogy egy adott dokumentum melyik szegmensére kerül. Ha azonban egy dokumentumkulcs nem változik, az mindig ugyanahhoz a szegmenshez lesz hozzárendelve.
A dokumentumpontszám általában nem a legjobb attribútum a dokumentumok megrendeléséhez, ha a sorrend stabilitása fontos. Ha például két dokumentum azonos pontszámmal rendelkezik, nem garantálható, hogy az egyik előbb megjelenik ugyanannak a lekérdezésnek a későbbi futtatásaiban. A dokumentum pontszámának csak az eredményekhalmaz többi dokumentumához viszonyítva kell általánosan érzékelnie a dokumentum relevanciáját.
Összefoglalás
A kereskedelmi keresőmotorok sikere növelte a magánadatok teljes szöveges keresésére vonatkozó elvárásokat. Szinte bármilyen keresési élmény esetén elvárjuk, hogy a motor megértse szándékunkat, még akkor is, ha a kifejezések hibásak vagy hiányosak. Az is előfordulhat, hogy az egyezések közel azonos kifejezések vagy szinonimák alapján lesznek meghatározva, amelyeket soha nem határoztunk meg.
Technikai szempontból a teljes szöveges keresés rendkívül összetett, kifinomult nyelvi elemzést és szisztematikus feldolgozást igényel a lekérdezési kifejezések lepárlásával, kibontásával és átalakításával, hogy releváns eredményt adjon. Az eredendő összetettségek miatt számos tényező befolyásolhatja a lekérdezés kimenetelét. Ezért a teljes szöveges keresés mechanikája megértéséhez szükséges idő befektetése kézzelfogható előnyökkel jár, ha váratlan eredményeken próbál dolgozni.
Ez a cikk az Azure AI Search kontextusában vizsgálta meg a teljes szöveges keresést. Reméljük, hogy elegendő hátteret biztosít a gyakori lekérdezési problémák megoldásának lehetséges okainak és megoldásainak felismeréséhez.
Következő lépések
Hozza létre a mintaindexet, próbálja ki a különböző lekérdezéseket, és tekintse át az eredményeket. Útmutatásért tekintse meg az indexek portálon való összeállítását és lekérdezését ismertető cikket.
Próbálkozzon más lekérdezési szintaxissal a Dokumentumok keresése példaszakaszból vagy a Portál Keresőböngészőjének Egyszerű lekérdezési szintaxisából .
Tekintse át a pontozási profilokat , ha szeretné finomhangolni a rangsorolást a keresőalkalmazásban.
Megtudhatja, hogyan alkalmazhat nyelvspecifikus lexikális elemzőket.
Egyéni elemzőket konfigurálhat minimális feldolgozáshoz vagy speciális feldolgozáshoz adott mezőkön.
Lásd még
Dokumentumok keresése – REST API
Egyszerű lekérdezési szintaxis
Visszajelzés
Hamarosan elérhető: 2024-ben fokozatosan kivezetjük a GitHub-problémákat a tartalom visszajelzési mechanizmusaként, és lecseréljük egy új visszajelzési rendszerre. További információ: https://aka.ms/ContentUserFeedback.
Visszajelzés küldése és megtekintése a következőhöz: