Kusto lekérdezésnyelv a Microsoft Sentinelben
Kusto lekérdezésnyelv a Microsoft Sentinelben az adatok kezeléséhez és kezeléséhez használt nyelv. A munkaterületre betáplálási naplók nem sokat érnek, ha nem tudja elemezni őket, és az összes adatban elrejti a fontos információkat. Kusto lekérdezésnyelv nemcsak az információk beszerzésének ereje és rugalmassága, hanem az egyszerűség is segít a gyors kezdésben. Ha rendelkezik szkriptkészítési vagy adatbázis-kezelő háttérrel, a cikk tartalma ismerősnek tűnik. Ha nem, ne aggódjon, mivel a nyelv intuitív természete gyorsan lehetővé teszi, hogy saját lekérdezéseket írjon, és értéket teremtsen a szervezet számára.
Ez a cikk bemutatja a Kusto lekérdezésnyelv alapjait, amelyek a leggyakrabban használt függvényeket és operátorokat ismertetik, amelyek a felhasználók által naponta írt lekérdezések 75–80 százalékát fedik le. Ha részletesebbre vagy összetettebb lekérdezésekre van szüksége, kihasználhatja a Microsoft Sentinel új speciális KQL-jének előnyeit (lásd ezt a bevezető blogbejegyzést). Lásd még a hivatalos Kusto lekérdezésnyelv dokumentációt és a különböző online kurzusokat (például a Pluralsightot).
A Microsoft Sentinel az Azure Monitor szolgáltatásra épül, és az Azure Monitor Log Analytics-munkaterületeit használja az összes adat tárolására. Ezek az adatok a következők bármelyikét tartalmazzák:
- külső forrásokból előre definiált táblákba a Microsoft Sentinel adatösszekötők használatával betöltött adatok.
- külső forrásokból felhasználó által definiált egyéni táblákba betöltött adatok, egyénileg létrehozott adatösszekötők és néhány beépített összekötőtípus használatával.
- a Microsoft Sentinel által létrehozott és végrehajtott elemzésekből származó adatok – például riasztások, incidensek és UEBA-adatok.
- a Microsoft Sentinelbe feltöltött adatok, hogy segítsenek az észlelésben és az elemzésben – például fenyegetésfelderítési hírcsatornák és figyelőlisták.
Kusto lekérdezésnyelv az Azure Data Explorer szolgáltatás részeként fejlesztették ki, ezért felhőalapú környezetben található big data-tárolókban való keresésre van optimalizálva. Jacques Cousteau híres tenger alatti felfedező által inspirált (és ennek megfelelően "koo-STOH"-nak is kihangsúlyozott) úgy tervezték, hogy segítsen mélyen belemerülni az adatok óceánjaiba és felfedezni rejtett kincseiket.
Kusto lekérdezésnyelv az Azure Monitorban is használható, és támogatja az Azure Monitor további funkcióit, amelyek lehetővé teszik az adatok lekérését, vizualizációját, elemzését és elemzését a Log Analytics-adattárakban. A Microsoft Sentinelben Kusto lekérdezésnyelv alapuló eszközöket használ, amikor adatokat vizualizál és elemez, és fenyegetéseket keres, akár meglévő szabályokban és munkafüzetekben, akár saját buildelésben.
Mivel Kusto lekérdezésnyelv része szinte mindennek, amit a Microsoft Sentinelben végez, a működés egyértelmű megértése segít abban, hogy jobban kihozza a SIEM-ből.
A Kusto lekérdezésnyelv lekérdezések csak olvasható kérések az adatok feldolgozására és az eredmények visszaadására – nem ír adatokat. A lekérdezések az SQL-hez hasonló adatbázisok, táblák és oszlopok hierarchiájába rendezett adatokon működnek.
A kérések egyszerű nyelven vannak megadva, és egy adatfolyam-modellt használnak, amely megkönnyíti a szintaxis olvasását, írását és automatizálását.
Kusto lekérdezésnyelv lekérdezések pontosvesszővel elválasztott utasításokból állnak. Sokféle utasítás létezik, de csak két széles körben használt típus:
A táblázatos kifejezési utasítások azok, amelyeket általában a lekérdezésekről beszélünk – ezek a lekérdezés tényleges törzse. A táblázatos kifejezési utasításokról fontos tudni, hogy táblázatos bemenetet (táblázatot vagy más táblázatos kifejezést) fogadnak el, és táblázatos kimenetet hoznak létre. Ezek közül legalább egy szükséges. A cikk többi része ezt a fajta állítást tárgyalja.
Az utasítások lehetővé teszik változók és állandók létrehozását és definiálását a lekérdezés törzsén kívül, a könnyebb olvashatóság és sokoldalúság érdekében. Ezek nem kötelezőek, és az adott igényektől függnek. Ezt a fajta állítást a cikk végén foglalkozunk.
Az Azure Portalon egy Log Analytics-bemutató környezetben gyakorolhatja Kusto lekérdezésnyelv utasításokat – beleértve a cikkben szereplőket is. Ennek a gyakorlókörnyezetnek a használata díjmentes, de a hozzáféréshez Azure-fiókra van szüksége.
Ismerkedjen meg a bemutatókörnyezettel. A Log Analyticshez hasonlóan az éles környezetben is számos módon használható:
Válasszon ki egy táblát, amelyre lekérdezést szeretne készíteni. Az alapértelmezett Táblák lapon (a bal felső sarokban látható piros téglalapban) válasszon ki egy táblázatot a témakörök szerint csoportosított táblák listájából (a bal alsó sarokban látható). Bontsa ki a témaköröket az egyes táblák megtekintéséhez, és az egyes táblák további kibontásával megtekintheti az összes mezőt (oszlopot). Ha duplán kattint egy táblára vagy egy mezőnévre, az a kurzor pontjára helyezi a lekérdezési ablakban. Írja be a lekérdezés többi részét a tábla neve után, az alábbiak szerint.
Keresse meg a tanulmányozni vagy módosítani kívánt meglévő lekérdezést. Válassza a Lekérdezések lapot (a bal felső sarokban látható piros téglalapban látható) a választható lekérdezések listájának megtekintéséhez. Vagy válassza a Lekérdezések lehetőséget a jobb felső sarokban lévő gombsávon. A Microsoft Sentinel beépített lekérdezéseivel ismerkedhet meg. Ha duplán kattint egy lekérdezésre, az egész lekérdezést a lekérdezési ablakban helyezi el a kurzor helyén.
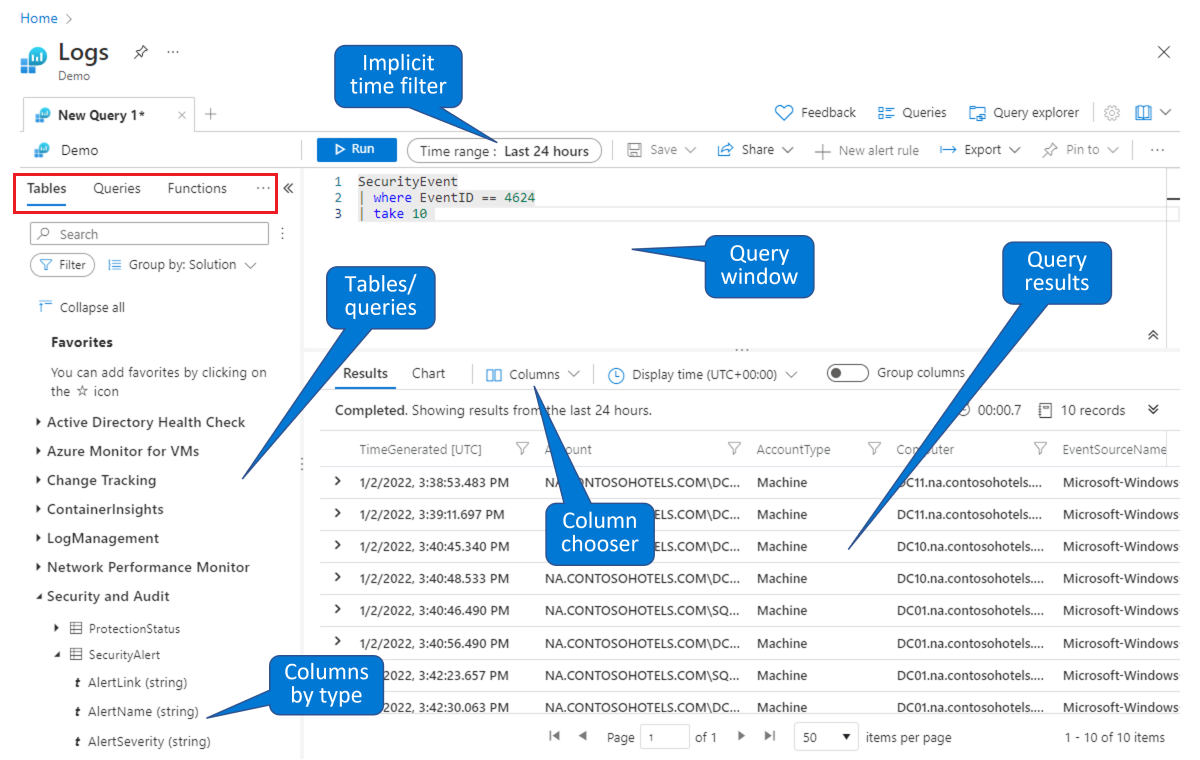
A bemutatókörnyezethez hasonlóan a Microsoft Sentinel-naplók lapon is lekérdezheti és szűrheti az adatokat. Kijelölhet egy táblát, és lehatolással megtekintheti az oszlopokat. Az oszlopválasztóval módosíthatja az alapértelmezett oszlopokat, és beállíthatja a lekérdezések alapértelmezett időtartományát. Ha az időtartomány explicit módon van definiálva a lekérdezésben, az időszűrő nem érhető el (szürkítve). További információk:
Ha a Microsoft egyesített biztonsági üzemeltetési platformjára van beépítve, a Microsoft Defender speciális vadászlapján is lekérdezheti és szűrheti az adatokat. További információ: Speciális keresés a Microsoft Sentinel-adatokkal a Microsoft Defender portálon.
A Kusto lekérdezésnyelv megismerésének jó helye az általános lekérdezési struktúra megismerése. A Kusto-lekérdezések során elsőként a csőszimbólum (|) használata látható. A Kusto-lekérdezések struktúrája azzal kezdődik, hogy az adatokat egy adatforrásból szerzi be, majd átadja az adatokat egy "folyamaton", és minden lépés bizonyos szintű feldolgozást biztosít, majd átadja az adatokat a következő lépésnek. A folyamat végén megkapja a végső eredményt. Valójában ez a folyamat:
Get Data | Filter | Summarize | Sort | Select
Ez az adatátadási koncepció intuitív struktúrát tesz lehetővé, mivel minden lépésnél egyszerűen készíthet mentális képet az adatokról.
Ennek szemléltetéséhez tekintsük át az alábbi lekérdezést, amely a Microsoft Entra bejelentkezési naplóit mutatja be. Ahogy végigolvassa az egyes sorokat, láthatja azokat a kulcsszavakat, amelyek jelzik, hogy mi történik az adatokkal. Az egyes sorokban megjegyzésként szerepeltetjük a folyamat megfelelő szakaszát.
Megjegyzés
A lekérdezés bármely sorához megjegyzéseket fűzhet, ha kettős perjellel (//perjellel) előzi meg őket.
SigninLogs // Get data
| evaluate bag_unpack(LocationDetails) // Ignore this line for now; we'll come back to it at the end.
| where RiskLevelDuringSignIn == 'none' // Filter
and TimeGenerated >= ago(7d) // Filter
| summarize Count = count() by city // Summarize
| sort by Count desc // Sort
| take 5 // Select
Mivel minden lépés kimenete a következő lépés bemenete, a lépések sorrendje meghatározhatja a lekérdezés eredményeit, és befolyásolhatja annak teljesítményét. Fontos, hogy a lépéseket annak megfelelően rendelje meg, hogy mit szeretne kihozni a lekérdezésből.
Tipp.
- Jó ökölszabály az adatok korai szűrése, így csak a releváns adatokat adja át a folyamaton. Ez jelentősen növeli a teljesítményt, és gondoskodik arról, hogy véletlenül ne foglalja bele az irreleváns adatokat az összegzési lépésekbe.
- Ez a cikk néhány egyéb ajánlott eljárást mutat be, amelyek szem előtt tartandóak. A teljesebb listát a lekérdezés ajánlott eljárásaiban találja.
Remélhetőleg most már megbecsüli a lekérdezések általános szerkezetét Kusto lekérdezésnyelv. Most tekintsük át a lekérdezés létrehozásához használt tényleges lekérdezési operátorokat.
Mielőtt belevágnánk a lekérdezési operátorokba, először vessünk egy gyors pillantást az adattípusokra. A legtöbb nyelvhez hasonlóan az adattípus határozza meg, hogy milyen számítások és manipulációk futtathatók egy értéken. Ha például egy sztring típusú érték van, nem fog tudni számtani számításokat végezni rajta.
A Kusto lekérdezésnyelv a legtöbb adattípus a szokásos konvenciók szerint történik, és olyan névvel rendelkezik, amelyet korábban valószínűleg látott. Az alábbi táblázat a teljes listát mutatja:
| Típus | További név/nevek | Egyenértékű .NET-típus |
|---|---|---|
bool |
Boolean |
System.Boolean |
datetime |
Date |
System.DateTime |
dynamic |
System.Object |
|
guid |
uuid, uniqueid |
System.Guid |
int |
System.Int32 |
|
long |
System.Int64 |
|
real |
Double |
System.Double |
string |
System.String |
|
timespan |
Time |
System.TimeSpan |
decimal |
System.Data.SqlTypes.SqlDecimal |
Bár a legtöbb adattípus standard, előfordulhat, hogy kevésbé ismeri az olyan típusokat, mint a dinamikus, az időkeret és a guid.
A dinamikus szerkezet a JSON-hoz hasonló, de egyetlen lényeges különbséggel rendelkezik: olyan Kusto lekérdezésnyelv-specifikus adattípusokat tárolhat, amelyeket a hagyományos JSON nem tud, például beágyazott dinamikus értéket vagy időkeretet. Íme egy példa egy dinamikus típusra:
{
"countryOrRegion":"US",
"geoCoordinates": {
"longitude":-122.12094116210936,
"latitude":47.68050003051758
},
"state":"Washington",
"city":"Redmond"
}
Az időkeret egy olyan adattípus, amely az idő mérésére vonatkozik, például órákra, napokra vagy másodpercekre. Ne keverje össze az időidőt a dátummal, amely a tényleges dátumot és időpontot értékeli ki, nem pedig az idő mértékét. Az alábbi táblázat az időtartomány utótagjainak listáját tartalmazza.
| Függvény | Leírás |
|---|---|
D |
nap |
H |
óra |
M |
perc során. |
S |
másodperc |
Ms |
ezredmásodperc |
Microsecond |
Mikroszekundum |
Tick |
nanoszekundumok |
A GUID egy 128 bites, globálisan egyedi azonosítót képviselő adattípus, amely a [8]-[4]-[4]-[4]-[4]-[12] szabványos formátumot követi, ahol minden [szám] a karakterek számát jelöli, és minden karakter 0-9 vagy a-f között mozoghat.
Megjegyzés
Kusto lekérdezésnyelv táblázatos és skaláris operátorokkal is rendelkezik. A cikk további részében, ha egyszerűen csak az "operátor" szót látja, feltételezheti, hogy táblázatos operátort jelent, kivéve, ha másként fel van jegyezve.
A Kusto lekérdezésnyelv alapvető szókincse - az alap, amely lehetővé teszi a legtöbb feladat elvégzését - operátorok gyűjteménye az adatok szűréséhez, rendezéséhez és kiválasztásához. A fennmaradó feladatok megkövetelik, hogy kiterjesszen a nyelv ismerete, hogy megfeleljen a fejlettebb igényeknek. Bontsunk ki egy kicsit a korábbi példánkban használt parancsok közül, és nézzük meg takea , sortés where.
Mindegyik operátor esetében megvizsgáljuk annak használatát az előző SigninLogs-példában , és hasznos tippet vagy ajánlott eljárást ismerünk meg.
Az alapszintű lekérdezések első sora határozza meg, hogy melyik táblával szeretne dolgozni. A Microsoft Sentinel esetében ez valószínűleg egy naplótípus neve a munkaterületen, például SigninLogs, SecurityAlert vagy CommonSecurityLog. Példa:
SigninLogs
A Kusto lekérdezésnyelv a naplónevek megkülönböztetik a kis- és nagybetűket, ezért SigninLogs signinLogs eltérően értelmezik őket. Ügyeljen az egyéni naplók neveinek kiválasztására, hogy könnyen azonosíthatók legyenek, és ne legyenek túl hasonlóak egy másik naplóhoz.
A take operátor (és az azonos korlát operátor) az eredmények korlátozására szolgál, ha csak egy adott számú sort ad vissza. Ezt követi egy egész szám, amely meghatározza a visszaadni kívánt sorok számát. Általában a lekérdezés végén, a rendezési sorrend meghatározása után használják, és ilyen esetben a rendezési sorrend tetején megadott számú sort adja vissza.
A lekérdezés korábbi verzióinak használata take hasznos lehet egy lekérdezés teszteléséhez, ha nem szeretne nagy adathalmazokat visszaadni. Ha azonban a take műveletet bármely sort művelet elé helyezi, take véletlenszerűen kiválasztott sorokat ad vissza – és valószínűleg a lekérdezés minden futtatásakor más sorokat is. Íme egy példa a take használatára:
SigninLogs
| take 5

Tipp.
Ha egy teljesen új lekérdezésen dolgozik, ahol nem biztos, hogy tudja, hogyan néz ki a lekérdezés, hasznos lehet egy take utasítást az elején elhelyezni, hogy mesterségesen korlátozza az adathalmazt a gyorsabb feldolgozás és kísérletezés érdekében. Ha elégedett a teljes lekérdezéssel, eltávolíthatja a kezdeti take lépést.
A rendezési operátor (és az azonos rendelési operátor) az adatok egy megadott oszlop szerinti rendezésére szolgál. Az alábbi példában a TimeGenerated szerint rendeztük az eredményeket, és a desc paraméterrel csökkenő sorrendbe állítottuk a sorrend irányát, a legmagasabb értékeket helyezve az első helyen; növekvő sorrendben az asc-t használjuk.
Megjegyzés
A rendezések alapértelmezett iránya csökkenő, ezért gyakorlatilag csak azt kell megadnia, hogy növekvő sorrendben szeretne-e rendezni. A rendezési irány megadása azonban minden esetben olvashatóbbá teszi a lekérdezést.
SigninLogs
| sort by TimeGenerated desc
| take 5
Ahogy már említettük, az operátor elé helyeztük az sort operátort take . Először rendezni kell, hogy biztosan megkapjuk a megfelelő öt rekordot.

A felső operátor lehetővé teszi, hogy egyetlen operátorban egyesítsük a sort take műveleteket:
SigninLogs
| top 5 by TimeGenerated desc
Ha két vagy több rekord értéke megegyezik a rendezendő oszlopban, további oszlopokat is hozzáadhat a rendezéshez. Adjon hozzá további rendezési oszlopokat egy vesszővel tagolt listában, amely az első rendezési oszlop után, de a rendezési sorrend kulcsszó előtt található. Példa:
SigninLogs
| sort by TimeGenerated, Identity desc
| take 5
Ha a TimeGenerated több rekord között azonos, akkor az Identitás oszlopban lévő érték alapján próbálja rendezni a rendezést.
Megjegyzés
Mikor és mikor érdemes használni sort taketop
Ha csak egy mezőre rendez, használja
top, mert jobb teljesítményt nyújt, mint a kombináció éstakeasort.Ha egynél több mezőre (például az előző példában)
topkell rendeznie, akkor ezt nem teheti meg, ezért a következőt kell használniasort:take
A where operátor vitathatatlanul a legfontosabb operátor, mivel ez a kulcs annak biztosításához, hogy csak a forgatókönyv szempontjából releváns adathalmazsal dolgozik. Érdemes a lehető leghamarabb szűrni az adatokat, mert ez javítja a lekérdezés teljesítményét azáltal, hogy csökkenti a további lépésekben feldolgozandó adatok mennyiségét; Emellett biztosítja, hogy csak a kívánt adatokon végezzen számításokat. Lásd ezt a példát:
SigninLogs
| where TimeGenerated >= ago(7d)
| sort by TimeGenerated, Identity desc
| take 5
Az where operátor egy változót, egy összehasonlító (skaláris) operátort és egy értéket határoz meg. A mi esetünkben azt használtuk >= , hogy a TimeGenerated oszlop értékének nagyobbnak kell lennie, mint (vagyis későbbi, mint) vagy egyenlőnek kell lennie hét nappal ezelőtt.
A Kusto lekérdezésnyelv kétféle összehasonlító operátor létezik: sztring és numerikus. Az alábbi táblázat a numerikus operátorok teljes listáját mutatja:
| Operátor | Leírás |
|---|---|
+ |
Összeadás |
- |
Kivonás |
* |
Szorzás |
/ |
Részleg |
% |
Moduló |
< |
Kisebb mint |
> |
Nagyobb mint |
== |
Egyenlő |
!= |
Nem egyenlő |
<= |
Kisebb vagy egyenlő |
>= |
Nagyobb vagy egyenlő |
in |
Egyenlő az egyik elemével |
!in |
Nem egyenlő az elemek egyikével sem |
A sztringoperátorok listája hosszabb lista, mert permutációkkal rendelkezik a kis- és nagybetűk érzékenységére, az aláhúzási helyekre, az előtagokra, az utótagokra és még sok másra. Az == operátor egyszerre numerikus és sztring operátor, ami azt jelenti, hogy számokhoz és szövegekhez egyaránt használható. Például az alábbi utasítások mindegyike érvényes lenne, ha az utasítások:
| where ResultType == 0| where Category == 'SignInLogs'
Ajánlott eljárás: A legtöbb esetben valószínűleg több oszlopra szeretné szűrni az adatokat, vagy több módon is szűrni szeretné ugyanazt az oszlopot. Ezekben az esetekben két ajánlott eljárást kell szem előtt tartania.
A kulcsszóval több where utasítást is kombinálhat egyetlen lépésben. Példa:
SigninLogs
| where Resource == ResourceGroup
and TimeGenerated >= ago(7d)
Ha több szűrő csatlakozik egyetlen where utasításhoz a kulcsszó és a kulcsszó használatával, jobb teljesítményt érhet el, ha először csak egyetlen oszlopra hivatkozó szűrőket helyez el. Így az előző lekérdezés írásának jobb módja a következő lenne:
SigninLogs
| where TimeGenerated >= ago(7d)
and Resource == ResourceGroup
Ebben a példában az első szűrő egyetlen oszlopot (TimeGenerated) említ, míg a második két oszlopra hivatkozik (Erőforrás és ResourceGroup).
Az Összegzés a Kusto lekérdezésnyelv egyik legfontosabb táblázatos operátora, de az összetettebb operátorok egyike, amelyből megtudhatja, hogy általánosan új-e a nyelvek lekérdezése. A feladat summarize az, hogy egy adattáblában egy új táblát adjon ki, amelyet egy vagy több oszlop összesít.
Az utasítás alapstruktúrája summarize a következő:
| summarize <aggregation> by <column>
Az alábbiak például a Perf tábla minden CounterName értékének rekordszámát adnák vissza:
Perf
| summarize count() by CounterName

Mivel a kimenet summarize egy új tábla, az utasításban summarize nem explicit módon megadott oszlopok nem lesznek átadva a folyamatnak. A koncepció szemléltetéséhez tekintse meg ezt a példát:
Perf
| project ObjectName, CounterValue, CounterName
| summarize count() by CounterName
| sort by ObjectName asc
A második sorban azt adhatja meg, hogy csak az ObjectName, a CounterValue és a CounterName oszlop érdekel. Ezt követően összegzettük, hogy lekérjük a rekordszámot a CounterName alapján, és végül megpróbáljuk növekvő sorrendbe rendezni az adatokat az ObjectName oszlop alapján. Ez a lekérdezés sajnos hibával meghiúsul (ami azt jelzi, hogy az ObjectName ismeretlen), mert összegzéskor csak a Count és a CounterName oszlopokat vettük fel az új táblába. A hiba elkerülése érdekében hozzáadhatjuk az ObjectName nevet a lépés végére summarize , például a következőhöz:
Perf
| project ObjectName, CounterValue , CounterName
| summarize count() by CounterName, ObjectName
| sort by ObjectName asc
A sor olvasásának módja a summarize következő lenne: "a rekordok számlálónév szerinti összegzése és az ObjectName szerinti csoportosítás". Folytathatja az oszlopok vesszővel elválasztott hozzáadását az summarize utasítás végéhez.

Az előző példára építve, ha egyszerre több oszlopot szeretnénk összesíteni, ezt úgy érhetjük el, hogy aggregációkat adunk hozzá az summarize operátorhoz vesszővel elválasztva. Az alábbi példában nem csak az összes rekord számát, hanem az Összes rekord Számláló oszlopában lévő értékek összegét is megkapjuk (amelyek megfelelnek a lekérdezés összes szűrőjének):
Perf
| project ObjectName, CounterValue , CounterName
| summarize count(), sum(CounterValue) by CounterName, ObjectName
| sort by ObjectName asc

Ez jó alkalomnak tűnik ezeknek az összesített oszlopoknak az oszlopneveiről beszélni. A szakasz elején azt mondtuk, hogy az summarize operátor egy adattáblát vesz fel, és létrehoz egy új táblát, és csak az utasításban summarize megadott oszlopok folytatják a folyamatot. Ezért ha a fenti példát futtatná, az összesítés eredményül kapott oszlopai count_ és sum_CounterValue.
A Kusto motor automatikusan létrehoz egy oszlopnevet anélkül, hogy explicitnek kellene lennenk, de gyakran azt tapasztalja, hogy az új oszlopnak van egy barátságosabb neve. Egyszerűen átnevezheti az oszlopot az summarize utasításban egy új név megadásával, majd az összesítéssel = , például:
Perf
| project ObjectName, CounterValue , CounterName
| summarize Count = count(), CounterSum = sum(CounterValue) by CounterName, ObjectName
| sort by ObjectName asc
Az összegzett oszlopok neve Count és CounterSum.

Az operátornak ennél többről summarize van szó, de érdemes időt szánni a tanulásra, mivel ez a Microsoft Sentinel-adatokon végrehajtandó adatelemzés kulcsfontosságú összetevője.
A legtöbb aggregációs függvény, de a leggyakrabban használt függvények közül néhány az sum(), count()és avg(). Íme egy részleges lista (lásd a teljes listát):
| Függvény | Leírás |
|---|---|
arg_max() |
Egy vagy több kifejezést ad vissza, ha az argumentum teljes méretű |
arg_min() |
Egy vagy több kifejezést ad vissza, ha az argumentum kis méretű |
avg() |
Átlagos értéket ad vissza a csoporton belül |
buildschema() |
A dinamikus bemenet összes értékét elismerő minimális sémát adja vissza |
count() |
A csoport számát adja eredményül. |
countif() |
A csoport predikátumával rendelkező darabszámot adja vissza |
dcount() |
A csoportelemek hozzávetőleges eltérő számát adja vissza |
make_bag() |
Dinamikus értékek tulajdonságcsomagját adja vissza a csoporton belül |
make_list() |
A csoporton belüli összes érték listáját adja vissza |
make_set() |
A csoporton belüli különböző értékek készletét adja vissza |
max() |
A csoport teljes maximális értékét adja eredményül. |
min() |
A csoporton belüli minimális értéket adja eredményül. |
percentiles() |
A csoport percentilis hozzávetőleges értékét adja vissza |
stdev() |
A csoport szórását adja vissza |
sum() |
A csoport elemeinek összegét adja eredményül. |
take_any() |
Véletlenszerű nonempty értéket ad vissza a csoporthoz |
variance() |
A csoport varianciáját adja vissza |
Amikor elkezd többet dolgozni a lekérdezésekkel, előfordulhat, hogy több információval rendelkezik, mint amennyire szüksége van a témákban (vagyis túl sok oszlop van a táblában). Vagy lehet, hogy több információra van szüksége, mint amennyije van (vagyis új oszlopot kell hozzáadnia, amely más oszlopok elemzési eredményeit tartalmazza). Vizsgáljuk meg az oszlopmanipuláció legfontosabb operátorait.
A Project nagyjából egyenértékű számos nyelv kijelölési utasításaival. Így kiválaszthatja, hogy mely oszlopokat tartsa meg. A visszaadott oszlopok sorrendje megegyezik az utasításban szereplő oszlopok sorrendjének megfelelően, ahogyan az ebben a példában project látható:
Perf
| project ObjectName, CounterValue, CounterName

El tudja képzelni, hogy ha széles adathalmazokkal dolgozik, sok oszlopot szeretne megtartani, és ha név szerint adja meg őket, akkor sok gépelésre van szükség. Ezekben az esetekben a projekteltávolodás lehetővé teszi, hogy megszüntesse az eltávolítandó oszlopokat ahelyett, hogy azokat megtartja, például:
Perf
| project-away MG, _ResourceId, Type
Tipp.
Hasznos lehet két helyen használni project a lekérdezésekben, az elején és a végén. A lekérdezés korai szakaszának használatával project javíthatja a teljesítményt azáltal, hogy eltávolítja azokat a nagy adattömböket, amelyeket nem kell átadnia a folyamatnak. Ha ismét a végén használja, eltávolíthatja az előző lépésekben esetleg létrehozott és a végső kimenetben nem szükséges oszlopokat.
Az Extend egy új számított oszlop létrehozásához használható. Ez akkor lehet hasznos, ha számítást szeretne végezni a meglévő oszlopokon, és minden sor kimenetét látni szeretné. Tekintsünk meg egy egyszerű példát, amelyben egy Kbytes nevű új oszlopot számítunk ki, amelyet az MB-érték (a meglévő Mennyiség oszlopban) 1024-gyel való megszorzásával tudunk kiszámítani.
Usage
| where QuantityUnit == 'MBytes'
| extend KBytes = Quantity * 1024
| project DataType, MBytes=Quantity, KBytes
Az utasítás utolsó sorában project átneveztük a Quantity oszlopot Mbytes-re, így könnyen megállapíthatjuk, hogy melyik mértékegység releváns az egyes oszlopokhoz.

Érdemes megjegyezni, hogy a extend már számított oszlopokkal is működik. Hozzáadhatunk például egy további, Bájtok nevű oszlopot, amely kbytes-ből van kiszámítva:
Usage
| where QuantityUnit == 'MBytes'
| extend KBytes = Quantity * 1024
| extend Bytes = KBytes * 1024
| project DataType, MBytes=Quantity, KBytes, Bytes

A Microsoft Sentinelben végzett munkája nagy részét egyetlen naplótípussal végezheti el, de vannak olyan esetek, amikor az adatokat egymással szeretné korrelálni, vagy más adatkészlettel szeretne keresni. A legtöbb lekérdezési nyelvhez hasonlóan a Kusto lekérdezésnyelv is kínál néhány operátort, amelyek különböző típusú illesztések végrehajtására szolgálnak. Ebben a szakaszban a leggyakrabban használt operátorokat union joinés a .
Az Egyesítő csak két vagy több táblát vesz fel, és az összes sort visszaadja. Példa:
OfficeActivity
| union SecurityEvent
Ez az OfficeActivity és a SecurityEvent tábla összes sorát visszaadja. Union néhány paramétert kínál, amelyek az egyesítő viselkedésének módosítására használhatók. A két legfontosabb a forrás és a fajta:
OfficeActivity
| union withsource = SourceTable kind = inner SecurityEvent
A withsource paraméterrel megadhatja egy új oszlop nevét, amelynek értéke egy adott sorban annak a táblának a neve, amelyből a sor származik. A példában a SourceTable oszlopot neveztük el, és a sortól függően az érték vagy OfficeActivity vagy SecurityEvent.
A másik megadott paraméter típus volt, amelynek két lehetősége van: belső vagy külső. A példában belső értéket adtunk meg, ami azt jelenti, hogy az egyesítőben csak azok az oszlopok vannak megőrzve, amelyek mindkét táblában léteznek. Másik lehetőségként, ha külső értéket adtunk volna meg (ez az alapértelmezett érték), akkor a rendszer mindkét tábla összes oszlopát visszaadja.
Az illesztés hasonlóan unionműködik, kivéve, ha ahelyett, hogy új táblázatot hozna létre, sorokat illesztünk össze, hogy új táblát hozzunk létre. A legtöbb adatbázisnyelvhez hasonlóan többféle illesztés is elvégezhető. Az a függvény join általános szintaxisa a következő:
T1
| join kind = <join type>
(
T2
) on $left.<T1Column> == $right.<T2Column>
Az join operátor után megadhatja, hogy milyen típusú illesztéseket szeretnénk végrehajtani, majd egy nyitott zárójelet. A zárójelek között adja meg az összekapcsolni kívánt táblát, valamint a hozzáadni kívánt táblán lévő többi lekérdezési utasítást. A záró zárójel után a bal oldali kulcsszót ($left) használjuk.<columnName> kulcsszó) és jobb ($right.<columnName>) oszlopokat a == operátorral elválasztva. Íme egy példa egy belső illesztésre:
OfficeActivity
| where TimeGenerated >= ago(1d)
and LogonUserSid != ''
| join kind = inner (
SecurityEvent
| where TimeGenerated >= ago(1d)
and SubjectUserSid != ''
) on $left.LogonUserSid == $right.SubjectUserSid
Megjegyzés
Ha mindkét tábla neve megegyezik azoknak az oszlopoknak a nevével, amelyeken illesztést végez, nem kell $left és $right használnia, ehelyett egyszerűen megadhatja az oszlop nevét. A $left és a $right használata azonban explicitebb és általánosan ajánlott eljárásnak számít.
A hivatkozáshoz az alábbi táblázat az elérhető illesztések listáját tartalmazza.
| Illesztés típusa | Leírás |
|---|---|
inner |
Egyetlen értéket ad vissza mindkét tábla egyező sorainak minden kombinációjához. |
innerunique |
A bal oldali táblából származó sorokat adja vissza a csatolt mező különböző értékeivel, amelyek egyezést tartalmaznak a jobb oldali táblában. Ez az alapértelmezett meghatározatlan illesztéstípus. |
leftsemi |
A bal oldali táblából származó összes rekordot visszaadja, amelyek egyezéssel rendelkeznek a jobb oldali táblában. A rendszer csak a bal oldali táblázatból származó oszlopokat adja vissza. |
rightsemi |
A jobb oldali táblából származó összes rekordot visszaadja, amelyek megegyeznek a bal oldali táblában. A rendszer csak a jobb oldali táblázatból származó oszlopokat adja vissza. |
leftanti/leftantisemi |
A bal oldali tábla összes olyan rekordját adja vissza, amelyeknek nincs egyezése a jobb oldali táblában. A rendszer csak a bal oldali táblázatból származó oszlopokat adja vissza. |
rightanti/rightantisemi |
A jobb oldali tábla összes olyan rekordját adja vissza, amely nem egyezik a bal oldali táblával. A rendszer csak a jobb oldali táblázatból származó oszlopokat adja vissza. |
leftouter |
A bal oldali tábla összes rekordjának visszaadása. A jobb oldali táblázatban nem egyező rekordok esetében a cellaértékek null értékűek. |
rightouter |
A jobb oldali táblából származó összes rekordot visszaadja. A bal oldali táblázatban nem egyező rekordok esetén a cellaértékek null értékűek. |
fullouter |
A bal és a jobb oldali táblák összes rekordja egyező vagy sem. A nem egyező értékek null értékűek. |
Tipp.
Ajánlott, hogy a legkisebb asztala legyen a bal oldalon. Bizonyos esetekben a szabály követése hatalmas teljesítménybeli előnyöket biztosíthat a végrehajtott illesztések típusától és a táblák méretétől függően.
Bizonyára emlékszik, hogy az első példában az egyik sor kiértékelő operátorát láttuk. Az evaluate operátort ritkábban használják, mint azokat, amelyeket korábban érintettünk. Azonban az operátor működésének ismerete evaluate megéri az idejét. Még egyszer, itt van az első lekérdezés, ahol a második sorban látható evaluate .
SigninLogs
| evaluate bag_unpack(LocationDetails)
| where RiskLevelDuringSignIn == 'none'
and TimeGenerated >= ago(7d)
| summarize Count = count() by city
| sort by Count desc
| take 5
Ez az operátor lehetővé teszi az elérhető beépülő modulok (beépített függvények) meghívását. Ezek közül a beépülő modulok közül sok az adatelemzésre összpontosít, például az autoclusterre, a diffpatternsre és a sequence_detect, lehetővé téve a fejlett elemzések elvégzését és a statisztikai anomáliák és kiugró értékek felderítését.
A példában használt beépülő modul neve bag_unpack, és egyszerűvé teszi egy dinamikus adattömb felvételét és oszlopokká alakítását. Ne feledje, hogy a dinamikus adatok olyan adattípusok, amelyek a JSON-hoz hasonlóan néznek ki, ahogyan az ebben a példában látható:
{
"countryOrRegion":"US",
"geoCoordinates": {
"longitude":-122.12094116210936,
"latitude":47.68050003051758
},
"state":"Washington",
"city":"Redmond"
}
Ebben az esetben városonként szeretnénk összegezni az adatokat, de a city tulajdonságként szerepel a LocationDetails oszlopban. A városi tulajdonság lekérdezésben való használatához először át kellett alakítanunk egy oszlopba bag_unpack használatával.
Visszatérve az eredeti folyamat lépéseihez, a következőket láttuk:
Get Data | Filter | Summarize | Sort | Select
Most, hogy figyelembe vettük az evaluate operátort, láthatjuk, hogy a folyamat egy új szakaszát jelöli, amely most így néz ki:
Get Data | Parse | Filter | Summarize | Sort | Select
Számos más példa is van az operátorokra és függvényekre, amelyekkel olvashatóbb és áttekinthetőbb formátumban elemezhetők az adatforrások. Ezekről – és a többi Kusto lekérdezésnyelv – a teljes dokumentációban és a munkafüzetben is tájékozódhat.
Most, hogy áttekintettük számos fő operátort és adattípust, foglaljuk össze a Let utasítást, amely nagyszerű módja annak, hogy a lekérdezések könnyebben olvashatók, szerkeszthetők és karbantarthatók legyenek.
Lehetővé teszi egy változó létrehozását és beállítását, vagy egy név hozzárendelését egy kifejezéshez. Ez a kifejezés lehet egyetlen érték, de egy teljes lekérdezés is lehet. Íme egy egyszerű példa:
let aWeekAgo = ago(7d);
SigninLogs
| where TimeGenerated >= aWeekAgo
Itt egy aWeekAgo nevet adtunk meg, és úgy állítottuk be, hogy egyenlő legyen egy időbélyegfüggvény kimenetével, amely egy dátum/idő értéket ad vissza. Ezután pontosvesszővel fejezzük be a let utasítást. Most már rendelkezünk egy új aWeekAgo nevű változóval, amely bárhol használható a lekérdezésben.
Ahogy már említettük, egy let utasítással egy teljes lekérdezést készíthet, és nevet adhat az eredménynek. Mivel a lekérdezési eredmények táblázatos kifejezésekként használhatók a lekérdezések bemeneteként, ezt az elnevezett eredményt táblaként kezelheti egy másik lekérdezés futtatása céljából. Íme egy kis módosítás az előző példában:
let aWeekAgo = ago(7d);
let getSignins = SigninLogs
| where TimeGenerated >= aWeekAgo;
getSignins
Ebben az esetben létrehoztunk egy második let utasítást, amelyben a teljes lekérdezést egy getSignins nevű új változóba csomagoltuk. A korábbiakhoz hasonlóan pontosvesszővel fejezzük be a második let utasítást. Ezután meghívjuk a változót az utolsó sorban, amely futtatja a lekérdezést. Figyelje meg, hogy az aWeekAgo-t a második let utasításban tudtuk használni. Ennek az az oka, hogy az előző sorban határoztuk meg; ha felcserélnénk a let utasítást, hogy a getSignins legyen az első, hibaüzenetet kapnánk.
Most már használhatjuk a getSigninst egy másik lekérdezés alapjaként (ugyanabban az ablakban):
let aWeekAgo = ago(7d);
let getSignins = SigninLogs
| where TimeGenerated >= aWeekAgo;
getSignins
| where level >= 3
| project IPAddress, UserDisplayName, Level
Lehetővé teszi , hogy az utasítások nagyobb erőt és rugalmasságot biztosítsanak a lekérdezések rendszerezésében. Definiálhat skaláris és táblázatos értékeket, valamint létrehozhat felhasználó által definiált függvényeket. Ezek igazán jól jöhetnek, ha összetettebb lekérdezéseket szervez, amelyek több csatlakozást is elvégezhetnek.
Bár ez a cikk csak az alapokat ismerteti, most már rendelkezik a szükséges alapokkal, és a Microsoft Sentinelben végzett munka elvégzéséhez leggyakrabban használt részeket is bemutattuk.
Használja ki a Kusto lekérdezésnyelv munkafüzetet közvetlenül a Microsoft Sentinelben – a Microsoft Sentinel-munkafüzet speciális KQL-jében. Részletes segítséget és példákat nyújt a mindennapi biztonsági műveletek során valószínűleg előforduló számos helyzethez, és számos, a Kusto-lekérdezéseket használó elemre mutat be kész, beépített példákat. Indítsa el ezt a munkafüzetet a Microsoft Sentinel Munkafüzetek lapján.
Speciális KQL-keretrendszerbeli munkafüzet – A KQL-hozzáértés használatának elősegítése egy kiváló blogbejegyzés, amely bemutatja, hogyan használhatja ezt a munkafüzetet.
A Kusto lekérdezésnyelv ismereteinek bővítéséhez és elmélyítéséhez tekintse meg a tanulási, képzési és készségfejlesztő források gyűjteményét.