Megjegyzés
Az oldalhoz való hozzáféréshez engedély szükséges. Megpróbálhat bejelentkezni vagy módosítani a címtárat.
Az oldalhoz való hozzáféréshez engedély szükséges. Megpróbálhatja módosítani a címtárat.
A lekérdezések gyorsítása lehetővé teszi, hogy az alkalmazások és az elemzési keretrendszerek jelentősen optimalizálják az adatfeldolgozást úgy, hogy csak azokat az adatokat kérik le, amelyekre egy adott művelet végrehajtásához szükségük van. Ez csökkenti a tárolt adatok kritikus elemzéséhez szükséges időt és feldolgozási teljesítményt.
Áttekintés
A lekérdezésgyorsítás elfogadja a szűrési predikátumokat és az oszlopvetítéseket, amelyek lehetővé teszik az alkalmazások számára a sorok és oszlopok szűrését az adatok lemezről való beolvasásakor. A rendszer csak a predikátum feltételeinek megfelelő adatokat továbbítja a hálózaton keresztül az alkalmazásnak. Ez csökkenti a hálózati késést és a számítási költségeket.
Az SQL használatával megadhatja a sorszűrő predikátumait és oszlopvetületeit egy lekérdezésgyorsítási kérelemben. A kérések csak egy fájlt dolgoznak fel. Ezért az SQL speciális relációs funkciói, például az illesztések és az összesítések szerinti csoportosítás nem támogatottak. A lekérdezésgyorsítás támogatja a CSV- és JSON-formátumú adatokat az egyes kérések bemeneteként.
A lekérdezésgyorsítási funkció nem korlátozódik a Data Lake Storage-ra (olyan tárfiókokra, amelyeken engedélyezve van a hierarchikus névtér). A lekérdezésgyorsítás kompatibilis a tárfiókokban lévő blobokkal, amelyeken nincs engedélyezve hierarchikus névtér. Ez azt jelenti, hogy a már blobként tárolt adatok tárfiókokban történő feldolgozásakor a hálózati késés és a számítási költségek azonos mértékű csökkenését érheti el.
A lekérdezések gyorsításának ügyfélalkalmazásokban való használatára vonatkozó példa: Adatok szűrése az Azure Data Lake Storage lekérdezésgyorsításával.
Adatfolyam
Az alábbi ábra bemutatja, hogy egy tipikus alkalmazás hogyan használja a lekérdezésgyorsítást az adatok feldolgozásához.
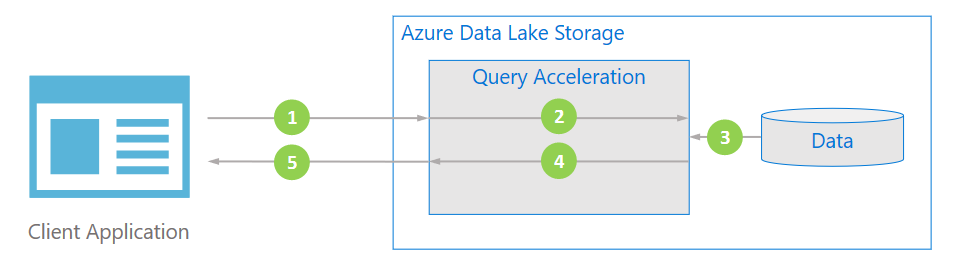
Az ügyfélalkalmazás predikátumok és oszlopvetületek megadásával kér fájladatokat.
A lekérdezésgyorsítás elemzi a megadott SQL-lekérdezést, és osztja el a munkát az adatok elemzéséhez és szűréséhez.
A processzorok beolvassák az adatokat a lemezről, a megfelelő formátummal elemzik az adatokat, majd a megadott predikátumok és oszlopvetítések alkalmazásával szűrik az adatokat.
A lekérdezésgyorsítás egyesíti a válaszszilánkokat az ügyfélalkalmazásba való visszastreameléshez.
Az ügyfélalkalmazás fogadja és elemzi a streamelt választ. Az alkalmazásnak nem kell más adatokat szűrnie, és közvetlenül alkalmazhatja a kívánt számítást vagy átalakítást.
Jobb teljesítmény alacsonyabb költséggel
A lekérdezésgyorsítás úgy optimalizálja a teljesítményt, hogy csökkenti az alkalmazás által továbbított és feldolgozott adatok mennyiségét.
Az összesített értékek kiszámításához az alkalmazások általában lekérik az összes adatot egy fájlból, majd helyileg dolgozzák fel és szűrik az adatokat. Az elemzési számítási feladatok bemeneti/kimeneti mintáinak elemzése azt mutatja, hogy az alkalmazások általában csak 20% igényelnek az általuk beolvasott adatokból egy adott számítás elvégzéséhez. Ez a statisztika akkor is igaz, ha olyan technikákat alkalmaz, mint a partíció metszése. Ez azt jelenti, hogy az adatok 80% szükségtelenül továbbítódik a hálózaton, elemzik és szűrik az alkalmazások. Ez a szükségtelen adatok eltávolítására tervezett minta jelentős számítási költséget jelent.
Annak ellenére, hogy az Azure iparágvezető hálózatot kínál, mind az átviteli sebesség, mind a késés szempontjából, az adatok ezen a hálózaton történő szükségtelen átvitele továbbra is költséges az alkalmazások teljesítménye szempontjából. Ha kiszűri a nem kívánt adatokat a tárolási kérelem során, a lekérdezések gyorsítása kiküszöböli ezt a költséget.
Emellett a szükségtelen adatok elemzéséhez és szűréséhez szükséges processzorterheléshez az alkalmazásnak nagyobb számú és nagyobb virtuális gépet kell kiépítenie a munka elvégzéséhez. Ha ezt a számítási terhelést a lekérdezésgyorsításra irányítja át, az alkalmazások jelentős költségmegtakarítást érhetnek el.
A lekérdezésgyorsítás előnyeit élvező alkalmazások
A lekérdezésgyorsítás elosztott elemzési keretrendszerekhez és adatfeldolgozási alkalmazásokhoz készült.
Az olyan elosztott elemzési keretrendszerek, mint az Apache Spark és az Apache Hive, egy tárolási absztrakciós réteget tartalmaznak a keretrendszeren belül. Ezek a motorok olyan lekérdezésoptimereket is tartalmaznak, amelyek beépíthetik a mögöttes I/O-szolgáltatás képességeinek ismeretét a felhasználói lekérdezések optimális lekérdezési tervének meghatározásakor. Ezek a keretrendszerek elkezdik integrálni a lekérdezésgyorsítást. Ennek eredményeképpen a keretrendszerek felhasználói jobb lekérdezési késést és alacsonyabb teljes bekerülési költséget tapasztalnak anélkül, hogy módosításokat kellene végezniük a lekérdezéseken.
A lekérdezésgyorsítást adatfeldolgozási alkalmazásokhoz is tervezték. Az ilyen típusú alkalmazások általában nagy léptékű adatátalakításokat hajtanak végre, amelyek nem vezetnek közvetlenül elemzési elemzésekhez, így nem mindig használnak kiépített elosztott elemzési keretrendszereket. Ezek az alkalmazások gyakran közvetlenebb kapcsolatban állnak a mögöttes tárolási szolgáltatással, így közvetlenül élvezhetik az olyan funkciók előnyeit, mint a lekérdezések gyorsítása.
Példa arra, hogy egy alkalmazás hogyan integrálhatja a lekérdezésgyorsítást: Adatok szűrése az Azure Data Lake Storage-lekérdezések gyorsításával.
Árképzés
Az Azure Data Lake Storage szolgáltatás megnövekedett számítási terhelése miatt a lekérdezések gyorsításának díjszabási modellje eltér a normál Azure Data Lake Storage-tranzakciós modelltől. A lekérdezésgyorsítás költséget számít fel a beolvasott adatok mennyisége alapján, valamint költséget a hívónak visszaadott adatok mennyisége alapján. További információkért tekintse meg az Azure Data Lake Storage díjszabását.
A számlázási modell módosítása ellenére a lekérdezésgyorsítás díjszabási modellje úgy lett kialakítva, hogy csökkentse a számítási feladatok teljes bekerülési költségét, tekintettel a sokkal drágább virtuális gépek költségeinek csökkentésére.