Táblatervezési minták
Ez a cikk néhány, a Table service-megoldásokkal való használatra alkalmas mintát ismertet. Azt is látni fogja, hogyan oldhatja meg gyakorlatilag a Table Storage más tervezési cikkeiben tárgyalt problémákat és kompromisszumokat. Az alábbi diagram a különböző minták közötti kapcsolatokat foglalja össze:
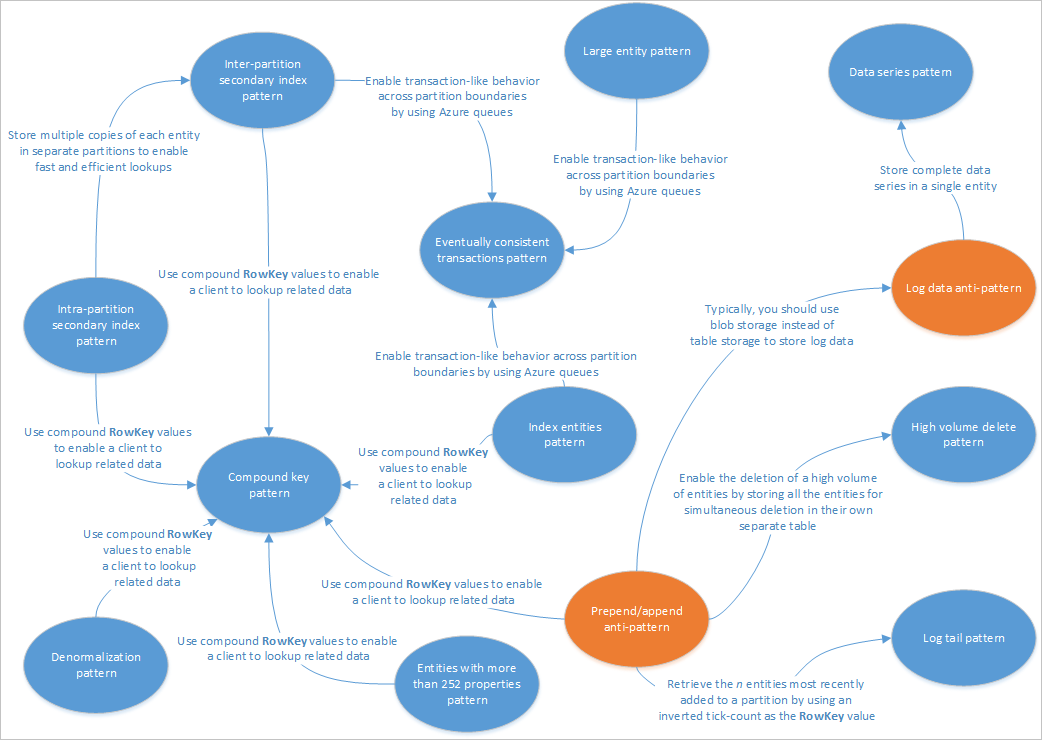
A fenti mintatérkép kiemeli a minták (kék) és az ebben az útmutatóban dokumentált antiminták (narancssárga) közötti kapcsolatokat. Sok más minták, amelyeket érdemes megfontolni. A Table Service egyik fő forgatókönyve például a Materialized View Pattern használata a Command Query Responsibility Szegregáció (CQRS) mintából.
Partíción belüli másodlagos indexminta
Az entitások több példányát tárolhatja különböző RowKey-értékekkel (ugyanabban a partícióban), hogy gyors és hatékony kereséseket és alternatív rendezési sorrendeket biztosíthasson különböző RowKey-értékek használatával. Frissítések példányok közötti konzisztensen megőrizhető az entitáscsoport-tranzakciók (EGT-k) használatával.
Kontextus és probléma
A Table service automatikusan indexeli az entitásokat a PartitionKey és a RowKey értékekkel. Ez lehetővé teszi, hogy az ügyfélalkalmazások hatékonyan lekérjenek egy entitást ezekkel az értékekkel. Az alább látható táblázatstruktúra használatával például egy ügyfélalkalmazás pont lekérdezéssel lekérhet egy adott alkalmazotti entitást a részleg nevével és az alkalmazotti azonosítóval (a PartitionKey és a RowKey értékekkel). Az ügyfél az egyes részlegek alkalmazotti azonosítója szerint rendezve is lekérheti az entitásokat.
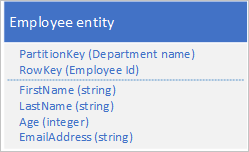
Ha egy másik tulajdonság (például e-mail-cím) értéke alapján is meg szeretne találni egy alkalmazotti entitást, akkor egy kevésbé hatékony partícióvizsgálattal kell megkeresnie egyezést. Ennek az az oka, hogy a táblaszolgáltatás nem biztosít másodlagos indexeket. Emellett nincs lehetőség arra, hogy az alkalmazottak listáját a RowKey-sorrendnél eltérő sorrendben rendezze.
Megoldás
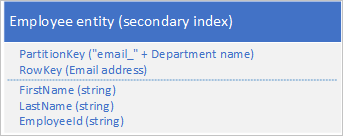
A másodlagos indexek hiányának megkerüléséhez az egyes entitások több példányát is tárolhatja az egyes példányokkal egy másik RowKey-érték használatával. Ha az alább látható struktúrákkal tárol egy entitást, hatékonyan lekérheti az alkalmazotti entitásokat az e-mail-cím vagy az alkalmazott azonosítója alapján. A Sorkulcs, a "empid_" és a "email_" előtagértékeivel egyetlen alkalmazottat vagy alkalmazotti tartományt kérdezhet le e-mail-címek vagy alkalmazotti azonosítók tartományával.

A következő két szűrési feltétel (az egyik az alkalmazotti azonosító alapján keres, a másik az e-mail-cím alapján keres) mindkettő pont típusú lekérdezéseket ad meg:
- $filter=(PartitionKey eq 'Sales' és (RowKey eq 'empid_000223')
- $filter=(PartitionKey eq 'Sales' és (RowKey eq 'email_jonesj@contoso.com')
Ha az alkalmazotti entitások egy tartományát kérdezi le, megadhatja az alkalmazotti azonosító sorrendbe rendezett tartományt, vagy egy e-mail-cím sorrendbe rendezett tartományt a RowKey megfelelő előtagjával rendelkező entitások lekérdezésével.
A Sales osztály összes alkalmazottjának megkeresése a 000100-es tartományban lévő alkalmazottazonosítóval 000199: $filter=(PartitionKey eq 'Sales') és (RowKey ge 'empid_000100') és (RowKey le 'empid_000199')
A Sales osztály összes alkalmazottjának megkeresése az "a" betűvel kezdődő e-mail-címmel: $filter=(PartitionKey eq 'Sales') és (RowKey ge 'email_a') és (RowKey lt 'email_b')
A fenti példákban használt szűrőszintaxis a Table service REST API-ból származik, további információ : Lekérdezési entitások.
Problémák és megfontolandó szempontok
A minta megvalósítása során az alábbi pontokat vegye figyelembe:
A táblatárolás viszonylag olcsó, ezért az ismétlődő adatok tárolásának költségei nem lehetnek jelentős gondok. A tervezés költségeit azonban mindig a várható tárolási követelmények alapján kell értékelnie, és csak duplikált entitásokat kell hozzáadnia az ügyfélalkalmazás által végrehajtott lekérdezések támogatásához.
Mivel a másodlagos indexentitások ugyanabban a partícióban vannak tárolva, mint az eredeti entitások, győződjön meg arról, hogy nem lépi túl az egyes partíciók méretezhetőségi céljait.
A duplikált entitások konzisztensek maradnak egymással, ha EGT-ekkel frissíti az entitás két példányát atomilag. Ez azt jelenti, hogy egy entitás összes példányát ugyanabban a partícióban kell tárolnia. További információ: Az entitáscsoport tranzakcióinak használata című szakasz.
A Sorkulcshoz használt értéknek egyedinek kell lennie az egyes entitásokhoz. Fontolja meg összetett kulcsértékek használatát.
A sorkulcs numerikus értékeinek (például az alkalmazotti azonosító 000223) kitöltése lehetővé teszi a megfelelő rendezést és szűrést a felső és az alsó határ alapján.
Nem feltétlenül kell duplikálnia az entitás összes tulajdonságát. Ha például a RowKey e-mail-címét használó entitásokat kereső lekérdezéseknek nincs szükségük az alkalmazott életkorára, az alábbi struktúrával rendelkezhetnek:
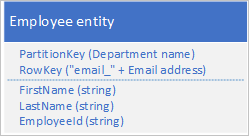
Általában jobb duplikált adatokat tárolni, és biztosítani, hogy egyetlen lekérdezéssel minden szükséges adatot lekérhessen, mint egy lekérdezéssel megkeresni egy entitást, egy másikkal pedig megkeresni a szükséges adatokat.
Mikor érdemes ezt a mintát használni?
Ezt a mintát akkor használja, ha az ügyfélalkalmazásnak különböző kulcsok használatával kell lekérnie az entitásokat, amikor az ügyfélnek különböző sorrendben kell lekérnie az entitásokat, és ahol különböző egyedi értékekkel azonosíthatja az egyes entitásokat. Azonban győződjön meg arról, hogy nem lépi túl a partíció méretezhetőségi korlátait, amikor entitáskereséseket végez a különböző RowKey-értékekkel .
Kapcsolódó minták és útmutatók
Az alábbi minták és útmutatók szintén hasznosak lehetnek a minta megvalósításakor:
- Particionálásközi másodlagos indexminta
- Összetett kulcsminta
- Entitáscsoport tranzakciói
- Heterogén entitástípusok használata
Particionálásközi másodlagos indexminta
Az egyes entitások több példányát tárolhatja különböző RowKey-értékekkel külön partíciókban vagy külön táblákban, hogy gyors és hatékony kereséseket és alternatív rendezési sorrendeket biztosíthasson különböző RowKey-értékek használatával.
Kontextus és probléma
A Table service automatikusan indexeli az entitásokat a PartitionKey és a RowKey értékekkel. Ez lehetővé teszi, hogy az ügyfélalkalmazások hatékonyan lekérjenek egy entitást ezekkel az értékekkel. Az alább látható táblázatstruktúra használatával például egy ügyfélalkalmazás pont lekérdezéssel lekérhet egy adott alkalmazotti entitást a részleg nevével és az alkalmazotti azonosítóval (a PartitionKey és a RowKey értékekkel). Az ügyfél az egyes részlegek alkalmazotti azonosítója szerint rendezve is lekérheti az entitásokat.
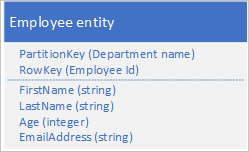
Ha egy másik tulajdonság (például e-mail-cím) értéke alapján is meg szeretne találni egy alkalmazotti entitást, akkor egy kevésbé hatékony partícióvizsgálattal kell megkeresnie egyezést. Ennek az az oka, hogy a táblaszolgáltatás nem biztosít másodlagos indexeket. Emellett nincs lehetőség arra, hogy az alkalmazottak listáját a RowKey-sorrendnél eltérő sorrendben rendezze.
Nagy mennyiségű tranzakcióra készül ezekre az entitásokra vonatkozóan, és minimalizálni szeretné az ügyfél szabályozását szabályozó Table service kockázatát.
Megoldás
A másodlagos indexek hiányának megkerüléséhez az egyes entitások több példányát tárolhatja az egyes példányokkal különböző PartitionKey - és RowKey-értékekkel . Ha az alább látható struktúrákkal tárol egy entitást, hatékonyan lekérheti az alkalmazotti entitásokat az e-mail-cím vagy az alkalmazott azonosítója alapján. A PartitionKey előtagértékei, a "empid_" és a "email_" lehetővé teszik a lekérdezéshez használni kívánt index azonosítását.

A következő két szűrési feltétel (az egyik az alkalmazotti azonosító alapján keres, a másik az e-mail-cím alapján keres) mindkettő pont típusú lekérdezéseket ad meg:
- $filter=(PartitionKey eq 'empid_Sales' és (RowKey eq '000223')
- $filter=(PartitionKey eq 'email_Sales') és (RowKey eq 'jonesj@contoso.com')
Ha az alkalmazotti entitások egy tartományát kérdezi le, megadhatja az alkalmazotti azonosító sorrendbe rendezett tartományt, vagy egy e-mail-cím sorrendbe rendezett tartományt a RowKey megfelelő előtagjával rendelkező entitások lekérdezésével.
- Az értékesítési részleg összes alkalmazottjának megkeresése a 000100-es tartományban lévő alkalmazottazonosítóval, és 000199 az alkalmazottazonosító-rendelések szerint rendezve: $filter=(PartitionKey eq 'empid_Sales') és (RowKey ge '000100') és (RowKey le '000199')
- Ha az értékesítési részleg összes alkalmazottját meg szeretné keresni egy e-mail-címmel, amely az "a" betűvel kezdődik, az e-mail-címrendelések szerint rendezve: $filter=(PartitionKey eq 'email_Sales') és (RowKey ge 'a') és (RowKey lt 'b')
A fenti példákban használt szűrőszintaxis a Table service REST API-ból származik, további információ : Lekérdezési entitások.
Problémák és megfontolandó szempontok
A minta megvalósítása során az alábbi pontokat vegye figyelembe:
Az ismétlődő entitások végül konzisztensek maradnak egymással az végül konzisztens tranzakciós mintával az elsődleges és másodlagos indexentitások fenntartásához.
A táblatárolás viszonylag olcsó, ezért az ismétlődő adatok tárolásának költségei nem lehetnek jelentős gondok. A tervezés költségeit azonban mindig a várható tárolási követelmények alapján kell értékelnie, és csak duplikált entitásokat kell hozzáadnia az ügyfélalkalmazás által végrehajtott lekérdezések támogatásához.
A Sorkulcshoz használt értéknek egyedinek kell lennie az egyes entitásokhoz. Fontolja meg összetett kulcsértékek használatát.
A sorkulcs numerikus értékeinek (például az alkalmazotti azonosító 000223) kitöltése lehetővé teszi a megfelelő rendezést és szűrést a felső és az alsó határ alapján.
Nem feltétlenül kell duplikálnia az entitás összes tulajdonságát. Ha például a RowKey e-mail-címét használó entitásokat kereső lekérdezéseknek nincs szükségük az alkalmazott életkorára, az alábbi struktúrával rendelkezhetnek:
Általában jobb duplikált adatokat tárolni, és gondoskodni arról, hogy egyetlen lekérdezéssel minden szükséges adatot lekérhessen, mint egy lekérdezéssel megkeresni egy entitást a másodlagos index használatával, egy másikkal pedig megkeresni a szükséges adatokat az elsődleges indexben.
Mikor érdemes ezt a mintát használni?
Ezt a mintát akkor használja, ha az ügyfélalkalmazásnak különböző kulcsok használatával kell lekérnie az entitásokat, amikor az ügyfélnek különböző sorrendben kell lekérnie az entitásokat, és ahol különböző egyedi értékekkel azonosíthatja az egyes entitásokat. Ezt a mintát akkor használja, ha el szeretné kerülni, hogy túllépje a partíció méretezhetőségi korlátait, amikor entitáskereséseket végez a különböző RowKey-értékekkel .
Kapcsolódó minták és útmutatók
Az alábbi minták és útmutatók szintén hasznosak lehetnek a minta megvalósításakor:
- Végül konzisztens tranzakciók mintája
- Partíción belüli másodlagos indexminta
- Összetett kulcsminta
- Entitáscsoport tranzakciói
- Heterogén entitástípusok használata
Végül konzisztens tranzakciók mintája
Az Azure-üzenetsorok használatával végleges konzisztens viselkedést engedélyezhet a partíciók vagy a tárolórendszer határai között.
Kontextus és probléma
Az EGT-k több olyan entitáson keresztül engedélyezik az atomi tranzakciókat, amelyek azonos partíciókulcsot használnak. Teljesítmény- és méretezhetőségi okokból dönthet úgy, hogy a konzisztenciakövetelményekkel rendelkező entitásokat külön partíciókban vagy külön tárolórendszerben tárolja: ilyen esetben nem használhat EGT-eket a konzisztencia fenntartásához. Előfordulhat például, hogy a következők közötti végleges konzisztenciát fenn kell tartania:
- Két különböző partícióban tárolt entitások ugyanabban a táblában, különböző táblákban vagy különböző tárfiókokban.
- A Table service-ben tárolt entitás és a Blob szolgáltatásban tárolt blob.
- A Table service-ben tárolt entitás és egy fájlrendszerbeli fájl.
- A Table szolgáltatásban tárolt entitás, amely az Azure Cognitive Search szolgáltatás használatával indexelt.
Megoldás
Az Azure-üzenetsorok használatával olyan megoldást valósíthat meg, amely végleges konzisztenciát biztosít két vagy több partíció vagy tárolórendszer között. Ennek a megközelítésnek a szemléltetéséhez tegyük fel, hogy a régi alkalmazotti entitások archiválására van szükség. A régi alkalmazotti entitásokat ritkán kérdezik le, és ki kell zárni minden olyan tevékenységből, amely a jelenlegi alkalmazottakkal foglalkozik. Ennek a követelménynek a megvalósításához az aktív alkalmazottakat az Aktuális táblában, a régi alkalmazottakat pedig az Archív táblában kell tárolnia. Az alkalmazott archiválásához törölnie kell az entitást az Aktuális táblából, és hozzá kell adnia az entitást az Archív táblához, de nem használhat EGT-t a két művelet végrehajtásához. Annak elkerülése érdekében, hogy egy hiba miatt egy entitás mindkét vagy egyik táblában is megjelenjen, az archív műveletnek végül konzisztensnek kell lennie. Az alábbi szekvenciadiagram a művelet lépéseit ismerteti. A következő szöveg további részleteket tartalmaz a kivétel elérési útjairól.
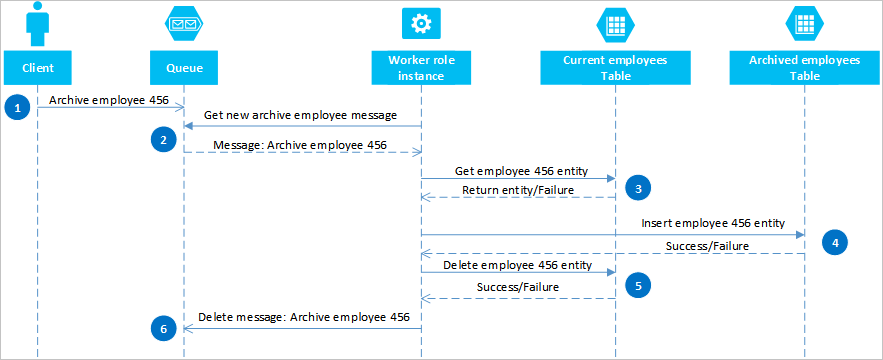
Az ügyfél úgy kezdeményezi az archiválási műveletet, hogy egy üzenetet helyez el egy Azure-üzenetsoron, ebben a példában a 456. alkalmazott archiválásához. A feldolgozói szerepkör lekérdezi az üzenetsort az új üzenetekhez; amikor talál egyet, felolvassa az üzenetet, és egy rejtett másolatot hagy az üzenetsoron. A feldolgozói szerepkör ezután lekéri az entitás egy példányát az Aktuális táblából, beszúr egy másolatot az Archív táblába, majd törli az eredetit az Aktuális táblából. Végül, ha az előző lépések során nem történt hiba, a feldolgozói szerepkör törli a rejtett üzenetet az üzenetsorból.
Ebben a példában a 4. lépés beszúrja az alkalmazottat az Archív táblába. Hozzáadhatja az alkalmazottat egy blobhoz a Blob szolgáltatásban vagy egy fájlrendszerbeli fájlban.
Helyreállítás hibákból
Fontos, hogy a 4. és az 5. lépés műveleteinek idempotensnek kell lenniük abban az esetben, ha a feldolgozói szerepkörnek újra kell indítania az archív műveletet. Ha a Table szolgáltatást használja, a 4. lépésben a "beszúrás vagy csere" műveletet kell használnia, az 5. lépésnél pedig a "delete if exists" műveletet kell használnia a használt ügyfélkódtárban. Ha másik tárolórendszert használ, megfelelő idempotens műveletet kell használnia.
Ha a feldolgozói szerepkör soha nem hajtja végre a 6. lépést, akkor egy időkorlát után az üzenet újra megjelenik az üzenetsoron, és készen áll arra, hogy a feldolgozói szerepkör megpróbálja újra feldolgozni. A feldolgozói szerepkör ellenőrizheti, hogy hányszor olvasták el az üzenetsoron lévő üzeneteket, és szükség esetén megjelölheti azt egy "méreg" üzenetnek a vizsgálathoz, ha külön üzenetsorba küldi. További információ az üzenetsor-üzenetek olvasásáról és a lekérések számának ellenőrzéséről: Üzenetek lekérése.
A Tábla- és üzenetsor-szolgáltatások bizonyos hibái átmeneti hibák, és az ügyfélalkalmazásnak megfelelő újrapróbálkozási logikát kell tartalmaznia a kezelésükhöz.
Problémák és megfontolandó szempontok
A minta megvalósítása során az alábbi pontokat vegye figyelembe:
- Ez a megoldás nem biztosít tranzakcióelkülönítést. Az ügyfél például felolvassa az Aktuális és az Archív táblákat, amikor a feldolgozói szerepkör a 4. és az 5. lépés között volt, és inkonzisztens nézetet láthat az adatokról. Az adatok végül konzisztensek lesznek.
- A végleges konzisztencia biztosításához győződjön meg arról, hogy a 4. és az 5. lépés idempotens.
- A megoldást több üzenetsor és feldolgozói szerepkörpéldány használatával skálázhatja.
Mikor érdemes ezt a mintát használni?
Ezt a mintát akkor használja, ha biztosítani szeretné a különböző partíciókban vagy táblákban található entitások közötti végleges konzisztenciát. Ezt a mintát kiterjesztheti a Table service és a Blob szolgáltatás, valamint más nem Azure Storage-adatforrások, például az adatbázis vagy a fájlrendszer műveleteinek végleges konzisztenciájának biztosításához.
Kapcsolódó minták és útmutatók
Az alábbi minták és útmutatók szintén hasznosak lehetnek a minta megvalósításakor:
- Entitáscsoport tranzakciói
- Egyesítés vagy csere
Megjegyzés:
Ha a tranzakcióelkülönítés fontos a megoldás számára, fontolja meg a táblák újratervezését, hogy lehetővé tegye az EGT-k használatát.
Indexelt entitások mintája
Indexentitások karbantartása az entitáslistákat visszamutató hatékony keresések engedélyezéséhez.
Kontextus és probléma
A Table service automatikusan indexeli az entitásokat a PartitionKey és a RowKey értékekkel. Ez lehetővé teszi, hogy az ügyfélalkalmazás hatékonyan lekérjen egy entitást pont típusú lekérdezéssel. Az alább látható táblázatstruktúra használatával például egy ügyfélalkalmazás hatékonyan lekérhet egy alkalmazotti entitást a részleg nevével és az alkalmazotti azonosítóval (a PartitionKey és a RowKey használatával).

Ha az alkalmazotti entitások listáját egy másik, nem egyedi tulajdonság ( például vezetékneve) értéke alapján szeretné lekérni, akkor kevésbé hatékony partícióvizsgálatot kell használnia a találatok kereséséhez, nem pedig index használatával, hogy közvetlenül megkeresse őket. Ennek az az oka, hogy a táblaszolgáltatás nem biztosít másodlagos indexeket.
Megoldás
Ha vezetéknév alapján szeretné engedélyezni a keresést a fent látható entitásstruktúrával, meg kell őriznie az alkalmazottak azonosítóinak listáját. Ha egy adott vezetéknévvel (például Jones) szeretné lekérni az alkalmazotti entitásokat, először meg kell keresnie a Jones vezetéknevével rendelkező alkalmazottak alkalmazotti azonosítóinak listáját, majd le kell kérnie ezeket az alkalmazotti entitásokat. Az alkalmazotti azonosítók listájának tárolására három fő lehetőség áll rendelkezésre:
- Blob Storage használata.
- Hozzon létre indexentititásokat ugyanabban a partícióban, mint az alkalmazotti entitások.
- Hozzon létre indexentititásokat egy külön partíción vagy táblában.
1. lehetőség: Blob Storage használata
Az első beállításhoz minden egyedi vezetéknévhez létre kell hoznia egy blobot, és minden blobban tárolhatja a PartitionKey (részleg) és a RowKey (alkalmazotti azonosító) értékeinek listáját azoknak az alkalmazottaknak, akik rendelkeznek ezzel a vezetéknévvel. Alkalmazott hozzáadásakor vagy törlésekor gondoskodnia kell arról, hogy a megfelelő blob tartalma végül összhangban legyen az alkalmazotti entitásokkal.
2. lehetőség: Indexentitások létrehozása ugyanabban a partícióban
A második lehetőséghez használja az alábbi adatokat tároló indexentititásokat:
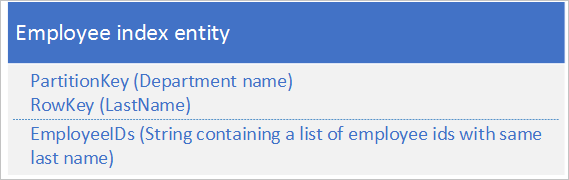
Az EmployeeIDs tulajdonság az alkalmazottak azonosítóinak listáját tartalmazza a RowKeyben tárolt vezetéknévvel rendelkező alkalmazottak számára.
Az alábbi lépések a második lehetőség használata esetén követendő folyamatot ismertetik, amikor új alkalmazottat ad hozzá. Ebben a példában hozzáadunk egy 000152 azonosítójú alkalmazottat és egy Jones vezetéknevet a Sales osztályon:
- Kérje le az indexentitást a "Sales" PartitionKey értékkel és a "Jones" RowKey értékkel. Mentse az entitás ETag elemét a 2. lépésben való használatra.
- Hozzon létre egy entitáscsoport-tranzakciót (vagyis egy kötegműveletet), amely beszúrja az új alkalmazotti entitást (PartitionKey érték "Sales" és RowKey érték "000152"), és frissíti az indexentitást (PartitionKey érték "Sales" és RowKey value "Jones") úgy, hogy hozzáadja az új alkalmazottazonosítót az EmployeeIDs mező listájához. Az entitáscsoport tranzakcióiról további információt az Entitáscsoport tranzakciói című témakörben talál.
- Ha az entitáscsoport tranzakciója optimista egyidejűségi hiba miatt meghiúsul (valaki más módosította az indexentitást), akkor újra kell kezdenie az 1. lépésben.
Hasonló módszerrel törölheti az alkalmazottat, ha a második lehetőséget használja. Az alkalmazott vezetéknevének módosítása kissé összetettebb, mert egy entitáscsoport tranzakcióját kell végrehajtania, amely három entitást frissít: az alkalmazotti entitást, a régi vezetéknév indexentitása és az új vezetéknév indexentitása. A módosítások elvégzése előtt le kell kérnie az egyes entitásokat, hogy lekérje azokat az ETag-értékeket, amelyeket aztán optimista egyidejűséggel végezhet el a frissítések végrehajtásához.
Az alábbi lépések ismertetik azt a folyamatot, amelyet akkor kell követnie, ha a második lehetőség használata esetén meg kell keresnie az összes alkalmazottat egy adott vezetéknévvel egy részlegen. Ebben a példában megkeressük az összes Jones vezetéknevű alkalmazottat az Értékesítési részlegben:
- Kérje le az indexentitást a "Sales" PartitionKey értékkel és a "Jones" RowKey értékkel.
- Elemezze az alkalmazotti azonosítók listáját az EmployeeIDs mezőben.
- Ha további információra van szüksége ezekről az alkalmazottakról (például az e-mail-címükről), kérje le az egyes alkalmazotti entitásokat a PartitionKey "Sales" és RowKey értékével a 2. lépésben beszerzett alkalmazottak listájából.
3. lehetőség: Indexentitások létrehozása külön partícióban vagy táblában
A harmadik lehetőséghez használja az alábbi adatokat tároló indexentititásokat:

Az EmployeeDetails tulajdonság az alkalmazottak azonosítóinak és a részlegnév párjainak listáját tartalmazza azoknak az alkalmazottaknak, akiknek a vezetéknevét a RowKey.
A harmadik lehetőséggel az EGT-ekkel nem tarthatja fenn a konzisztenciát, mert az indexentitások az alkalmazotti entitásoktól eltérő partícióban találhatók. Győződjön meg arról, hogy az indexentitások végül összhangban vannak az alkalmazotti entitásokkal.
Problémák és megfontolandó szempontok
A minta megvalósítása során az alábbi pontokat vegye figyelembe:
- Ehhez a megoldáshoz legalább két lekérdezésre van szükség az egyező entitások lekéréséhez: az egyik az indexentitások lekérdezése a RowKey-értékek listájának lekéréséhez, majd a lekérdezések a lista egyes entitásainak lekéréséhez.
- Mivel az egyes entitások maximális mérete 1 MB, a megoldás 2. és 3. lehetősége feltételezi, hogy a megadott vezetéknévhez tartozó alkalmazotti azonosítók listája soha nem nagyobb 1 MB-nál. Ha az alkalmazottak azonosítóinak listája valószínűleg nagyobb, mint 1 MB, használja az 1. lehetőséget, és tárolja az indexadatokat a Blob Storage-ban.
- Ha a 2. lehetőséget használja (az alkalmazottak hozzáadásának és törlésének kezelésére, valamint az alkalmazott vezetéknevének módosítására) a 2. lehetőséget használja, akkor ki kell értékelnie, hogy a tranzakciók mennyisége megközelíti-e az adott partíció méretezhetőségi korlátait. Ebben az esetben érdemes megfontolnia egy végül konzisztens megoldást (1. vagy 3. lehetőség), amely várólistákkal kezeli a frissítési kérelmeket, és lehetővé teszi az indexentitások tárolását az alkalmazott entitásoktól eltérő partíción.
- Ebben a megoldásban a 2. lehetőség azt feltételezi, hogy vezetéknév alapján szeretne keresni egy részlegen belül: például le szeretné kérni a Jones vezetéknevű alkalmazottak listáját az Értékesítési részlegben. Ha az összes, Jones vezetéknevű alkalmazottat szeretné megkeresni az egész szervezetben, használja az 1. vagy a 3. lehetőséget.
- Implementálhat egy üzenetsor-alapú megoldást, amely végleges konzisztenciát biztosít (további részletekért tekintse meg a végleges konzisztens tranzakciómintát ).
Mikor érdemes ezt a mintát használni?
Ezt a mintát akkor használja, ha olyan entitásokat szeretne megkeresni, amelyek mindegyike közös tulajdonságértékkel rendelkezik, például a Jones vezetéknevű összes alkalmazottat.
Kapcsolódó minták és útmutatók
Az alábbi minták és útmutatók szintén hasznosak lehetnek a minta megvalósításakor:
- Összetett kulcsminta
- Végül konzisztens tranzakciók mintája
- Entitáscsoport tranzakciói
- Heterogén entitástípusok használata
Denormalizálási minta
A kapcsolódó adatok egyetlen entitásban való egyesítése lehetővé teszi az összes szükséges adat egy pontból álló lekérdezéssel való lekérését.
Kontextus és probléma
Egy relációs adatbázisban általában normalizálja az adatokat a duplikációk eltávolításához, ami több táblából adatokat lekérő lekérdezéseket eredményez. Ha az Azure-táblákban normalizálja az adatokat, a kapcsolódó adatok lekéréséhez több ciklikus utazást kell végrehajtania az ügyfélről a kiszolgálóra. Az alábbi táblázatstruktúrával például két körútra van szükség egy részleg adatainak lekéréséhez: az egyik a részleg entitásának lekérése, amely tartalmazza a vezető azonosítóját, majd egy másik kérés a vezető adatainak lekérésére egy alkalmazotti entitásban.

Megoldás
Az adatok két különálló entitásban való tárolása helyett denormalizálja az adatokat, és őrizze meg a felettes adatainak másolatát a részlegen. Például:
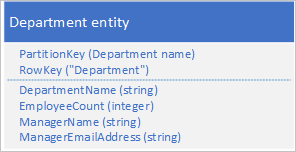
Az ilyen tulajdonságokkal tárolt részlegentitások esetében mostantól egy pont lekérdezés használatával lekérheti a részlegre vonatkozó összes szükséges adatot.
Problémák és megfontolandó szempontok
A minta megvalósítása során az alábbi pontokat vegye figyelembe:
- Bizonyos adatok kétszeri tárolásával kapcsolatos költségekkel jár. A teljesítménybeli előny (amely a tárolási szolgáltatás felé irányuló kevesebb kérésből ered) általában meghaladja a tárolási költségek marginális növekedését (és ezt a költséget részben ellensúlyozza a részleg adatainak lekéréséhez szükséges tranzakciók számának csökkentése).
- A vezetők adatait tároló két entitás konzisztenciáját fenn kell tartania. A konzisztenciaprobléma az EGT-ekkel kezelhető, ha egyetlen atomi tranzakcióban több entitást frissít: ebben az esetben a részleg entitása és a részlegvezető alkalmazotti entitása ugyanabban a partícióban lesz tárolva.
Mikor érdemes ezt a mintát használni?
Ezt a mintát akkor használja, ha gyakran kell megkeresnie a kapcsolódó információkat. Ez a minta csökkenti az ügyfél által a szükséges adatok lekéréséhez szükséges lekérdezések számát.
Kapcsolódó minták és útmutatók
Az alábbi minták és útmutatók szintén hasznosak lehetnek a minta megvalósításakor:
- Összetett kulcsminta
- Entitáscsoport tranzakciói
- Heterogén entitástípusok használata
Összetett kulcsminta
Összetett RowKey-értékekkel engedélyezheti az ügyfélnek, hogy egyetlen pontból álló lekérdezéssel keressen kapcsolódó adatokat.
Kontextus és probléma
A relációs adatbázisokban természetes, hogy a lekérdezésekben lévő illesztésekkel egyetlen lekérdezésben ad vissza kapcsolódó adatokat az ügyfélnek. Az alkalmazottazonosító használatával például megkeresheti azoknak a kapcsolódó entitásoknak a listáját, amelyek tartalmazzák a teljesítményt, és áttekintik az adott alkalmazott adatait.
Tegyük fel, hogy az alkalmazotti entitásokat a Table szolgáltatásban tárolja a következő struktúra használatával:
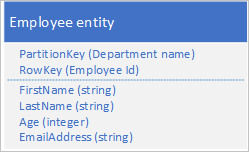
Emellett minden olyan évre vonatkozóan el kell tárolnia az értékelésekkel és teljesítménnyel kapcsolatos előzményadatokat, amelyeket az alkalmazott a szervezetnél dolgozott, és évről évre hozzá kell férnie ezekhez az információkhoz. Az egyik lehetőség egy másik tábla létrehozása, amely az alábbi struktúrájú entitásokat tárolja:
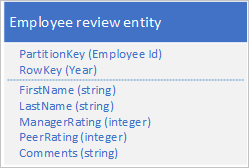
Figyelje meg, hogy ezzel a módszerrel dönthet úgy, hogy megkettőz néhány információt (például utónevet és vezetéknevet) az új entitásban, hogy egyetlen kéréssel lekérhesse az adatokat. Azonban nem tarthatja fenn az erős konzisztenciát, mert nem használhat EGT-t a két entitás atomi frissítésére.
Megoldás
Új entitástípus tárolása az eredeti táblában az alábbi struktúrájú entitások használatával:
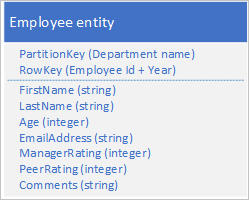
Figyelje meg, hogy a RowKey mostantól egy összetett kulcs, amely az alkalmazottazonosítóból és a felülvizsgálati adatok évéből áll, amely lehetővé teszi az alkalmazott teljesítményének lekérését és az adatok áttekintését egyetlen entitás egyetlen kérésével.
Az alábbi példa azt mutatja be, hogyan kérhető le egy adott alkalmazott összes felülvizsgálati adata (például az értékesítési részleg alkalmazotti 000123):
$filter=(PartitionKey eq 'Sales') és (RowKey ge 'empid_000123') és (RowKey lt '000123_2012')&$select=RowKey,Manager Rating,Peer Rating,Comments
Problémák és megfontolandó szempontok
A minta megvalósítása során az alábbi pontokat vegye figyelembe:
- Megfelelő elválasztó karaktert kell használnia, amely megkönnyíti a RowKey érték elemzését: például 000123_2012.
- Ezt az entitást ugyanabban a partícióban is tárolja, mint a többi olyan entitást, amely ugyanahhoz az alkalmazotthoz kapcsolódó adatokat tartalmaz, ami azt jelenti, hogy egts használatával erős konzisztenciát tarthat fenn.
- Érdemes megfontolnia, hogy milyen gyakran kérdezi le az adatokat annak megállapításához, hogy ez a minta megfelelő-e. Ha például ritkán fér hozzá a felülvizsgálati adatokhoz, és a fő alkalmazotti adatokhoz gyakran külön entitásként kell őket tárolnia.
Mikor érdemes ezt a mintát használni?
Ezt a mintát akkor használja, ha egy vagy több gyakran lekérdezett kapcsolódó entitást kell tárolnia.
Kapcsolódó minták és útmutatók
Az alábbi minták és útmutatók szintén hasznosak lehetnek a minta megvalósításakor:
- Entitáscsoport tranzakciói
- Heterogén entitástípusok használata
- Végül konzisztens tranzakciók mintája
Naplószél minta
A partícióhoz legutóbb hozzáadott n entitásokat egy fordított dátum és idő sorrendben rendező RowKey-érték használatával kérdezheti le.
Kontextus és probléma
Gyakori követelmény a legutóbb létrehozott entitások lekérése, például az alkalmazott által benyújtott 10 legutóbbi költségkövetelmény. A tábla lekérdezései támogatják a $top lekérdezési műveletet, amely egy készlet első n entitását adja vissza: nincs egyenértékű lekérdezési művelet a készlet utolsó n entitásainak visszaadásához.
Megoldás
Az entitásokat egy Sorkulcs használatával tárolja, amely természetesen fordított dátum/idő sorrendben rendez, így a legutóbbi bejegyzés mindig az első a táblában.
Ha például le szeretné tudni kérni az alkalmazott által benyújtott 10 legutóbbi költségkövetkeztetési jogcímet, használhatja az aktuális dátum/idő alapján kiszámított fordított osztásértéket. Az alábbi C#-kódminta bemutatja, hogyan hozhat létre megfelelő "fordított ticks" értéket a RowKey-hez , amely a legutóbbitól a legrégebbiig rendez:
string invertedTicks = string.Format("{0:D19}", DateTime.MaxValue.Ticks - DateTime.UtcNow.Ticks);
A dátum időértékéhez a következő kóddal juthat vissza:
DateTime dt = new DateTime(DateTime.MaxValue.Ticks - Int64.Parse(invertedTicks));
A tábla lekérdezése így néz ki:
https://myaccount.table.core.windows.net/EmployeeExpense(PartitionKey='empid')?$top=10
Problémák és megfontolandó szempontok
A minta megvalósítása során az alábbi pontokat vegye figyelembe:
- A fordított osztás értékét kezdő nullákkal kell beszúrni, hogy a sztring értéke a várt módon legyen rendezve.
- A partíció szintjén tisztában kell lennie a méretezhetőségi célokkal. Ügyeljen arra, hogy ne hozzon létre gyakori elérésű partíciókat.
Mikor érdemes ezt a mintát használni?
Ezt a mintát akkor használja, ha fordított dátum/idő sorrendben kell hozzáférnie az entitásokhoz, vagy ha hozzá kell férnie a legutóbb hozzáadott entitásokhoz.
Kapcsolódó minták és útmutatók
Az alábbi minták és útmutatók szintén hasznosak lehetnek a minta megvalósításakor:
Nagy mennyiségű törlési minta
Nagy mennyiségű entitás törlésének engedélyezése az összes entitás egyidejű törléséhez a saját külön táblájukban való tárolásával; az entitásokat a tábla törlésével törölheti.
Kontextus és probléma
Sok alkalmazás törli azokat a régi adatokat, amelyeknek már nem kell elérhetőnek lenniük egy ügyfélalkalmazás számára, vagy amelyeket az alkalmazás archivált egy másik tárolóeszközre. Ezeket az adatokat általában dátum szerint azonosítja: például törölnie kell a 60 napnál régebbi összes bejelentkezési kérelem rekordjait.
Az egyik lehetséges terv a bejelentkezési kérelem dátumának és időpontjának használata a Sorkulcsban:
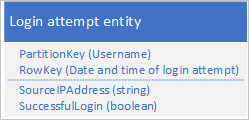
Ez a megközelítés elkerüli a particionálási pontok használatát, mert az alkalmazás minden felhasználóhoz beszúrhat és törölhet bejelentkezési entitásokat egy külön partíción. Ez a megközelítés azonban költséges és időigényes lehet, ha nagy számú entitással rendelkezik, mivel először egy táblavizsgálatot kell végeznie a törölni kívánt entitások azonosításához, majd törölnie kell minden régi entitást. A régi entitások törléséhez szükséges, a kiszolgálóra irányuló ciklikus utazások számát csökkentheti, ha több törlési kérést kötegel az EGT-kbe.
Megoldás
A bejelentkezési kísérletek minden napjára használjon külön táblázatot. A fenti entitásterv használatával elkerülheti az entitások beszúrásakor a hotspotokat, és a régi entitások törlése mostantól egyszerűen csak egy tábla törlésének kérdése naponta (egyetlen tárolási művelet) ahelyett, hogy naponta több száz és több ezer egyéni bejelentkezési entitást talál és töröl.
Problémák és megfontolandó szempontok
A minta megvalósítása során az alábbi pontokat vegye figyelembe:
- Támogatja a tervezés más módszereket is az alkalmazás az adatok használatára, például adott entitások keresésére, más adatokhoz való csatolásra vagy összesített információk generálására?
- Elkerüli a tervezés a gyakori pontokat új entitások beszúrásakor?
- Várjon késést, ha a törlés után ugyanazt a táblanevet szeretné újra felhasználni. Jobb, ha mindig egyedi táblaneveket használ.
- Egy új tábla első használatakor némi szabályozásra számíthat, miközben a Table service megtanulja a hozzáférési mintákat, és elosztja a partíciókat a csomópontok között. Érdemes megfontolnia, hogy milyen gyakran kell új táblákat létrehoznia.
Mikor érdemes ezt a mintát használni?
Ezt a mintát akkor használja, ha nagy mennyiségű entitást kell egyszerre törölnie.
Kapcsolódó minták és útmutatók
Az alábbi minták és útmutatók szintén hasznosak lehetnek a minta megvalósításakor:
- Entitáscsoport tranzakciói
- Entitások módosítása
Adatsorminta
A teljes adatsorokat egyetlen entitásban tárolhatja a kérések számának minimalizálása érdekében.
Kontextus és probléma
Gyakori forgatókönyv, hogy egy alkalmazás olyan adatsort tárol, amelyet általában egyszerre kell lekérnie. Előfordulhat például, hogy az alkalmazás rögzíti, hogy az egyes alkalmazottak hány csevegőüzenetet küldenek óránként, majd ez alapján ábrázolhatja, hogy az egyes felhasználók hány üzenetet küldtek az előző 24 órában. Az egyik terv az lehet, hogy minden alkalmazotthoz 24 entitást tárol:
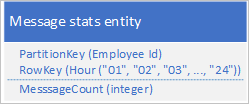
Ezzel a kialakítással könnyen megtalálhatja és frissítheti az entitást az egyes alkalmazottak frissítéséhez, amikor az alkalmazásnak frissítenie kell az üzenetszám értékét. Ha azonban az előző 24 órában végzett tevékenység diagramjának ábrázolásához szeretné lekérni az adatokat, 24 entitást kell lekérnie.
Megoldás
Az egyes órák üzenetszámának tárolásához használja az alábbi kialakítást egy külön tulajdonsággal:
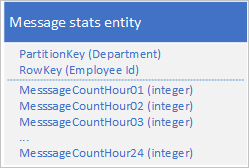
Ezzel a kialakítással egy egyesítési művelettel frissítheti egy alkalmazott üzenetszámát egy adott órára. Most egyetlen entitás kérésével lekérheti a diagram ábrázolásához szükséges összes információt.
Problémák és megfontolandó szempontok
A minta megvalósítása során az alábbi pontokat vegye figyelembe:
- Ha a teljes adatsor nem fér el egyetlen entitásban (egy entitás legfeljebb 252 tulajdonsággal rendelkezhet), használjon alternatív adattárat, például egy blobot.
- Ha egyszerre több ügyfél is frissít egy entitást, az ETag használatával optimista egyidejűséget kell megvalósítania. Ha sok ügyféllel rendelkezik, nagy versengést tapasztalhat.
Mikor érdemes ezt a mintát használni?
Ezt a mintát akkor használja, ha egy adott entitáshoz társított adatsort kell frissítenie és lekérnie.
Kapcsolódó minták és útmutatók
Az alábbi minták és útmutatók szintén hasznosak lehetnek a minta megvalósításakor:
- Nagyméretű entitások mintája
- Egyesítés vagy csere
- Végül konzisztens tranzakcióminta (ha az adatsort blobban tárolja)
Széles entitások mintája
Több fizikai entitás használata 252-nél több tulajdonsággal rendelkező logikai entitások tárolására.
Kontextus és probléma
Az egyes entitások legfeljebb 252 tulajdonsággal rendelkezhetnek (a kötelező rendszertulajdonságok kivételével), és nem tárolhatnak összesen 1 MB-nál több adatot. Egy relációs adatbázisban általában egy sor méretére vonatkozó korlátokat kerekítene fel egy új tábla hozzáadásával és egy 1–1-hez kapcsolat kikényszerítésével.
Megoldás
A Table service használatával több entitást is tárolhat, amelyek egyetlen, 252-nél több tulajdonsággal rendelkező nagy üzleti objektumot jelölnek. Ha például az egyes alkalmazottak által az elmúlt 365 napra küldött csevegőüzenetek számát szeretné tárolni, az alábbi kialakítást használhatja, amely két különböző sémával rendelkező entitást használ:
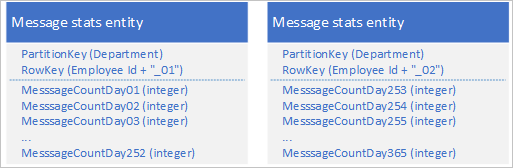
Ha olyan módosítást kell végeznie, amely mindkét entitás frissítését igényli, hogy szinkronizálva maradjanak egymással, használhatja az EGT-t. Ellenkező esetben egyetlen egyesítési művelettel frissítheti az üzenetek számát egy adott napra vonatkozóan. Az egyes alkalmazottak összes adatának lekéréséhez mindkét entitást le kell kérnie, amelyet két hatékony kéréssel is elvégezhet, amelyek partíciókulcsot és RowKey-értéket is használnak.
Problémák és megfontolandó szempontok
A minta megvalósítása során az alábbi pontokat vegye figyelembe:
- A teljes logikai entitás beolvasása legalább két tárolási tranzakciót foglal magában: egyet az egyes fizikai entitások lekéréséhez.
Mikor érdemes ezt a mintát használni?
Ezt a mintát akkor használja, ha olyan entitásokat kell tárolnia, amelyek mérete vagy száma meghaladja az egyes entitások korlátait a Table szolgáltatásban.
Kapcsolódó minták és útmutatók
Az alábbi minták és útmutatók szintén hasznosak lehetnek a minta megvalósításakor:
- Entitáscsoport tranzakciói
- Egyesítés vagy csere
Nagyméretű entitások mintája
A Blob Storage használatával nagy tulajdonságértékeket tárolhat.
Kontextus és probléma
Az egyes entitások összesen legfeljebb 1 MB adatot tárolnak. Ha egy vagy több tulajdonság olyan értékeket tárol, amelyek miatt az entitás teljes mérete meghaladja ezt az értéket, a teljes entitás nem tárolható a Table szolgáltatásban.
Megoldás
Ha az entitás mérete meghaladja az 1 MB-ot, mert egy vagy több tulajdonság nagy mennyiségű adatot tartalmaz, tárolhatja az adatokat a Blob szolgáltatásban, majd tárolhatja a blob címét egy tulajdonságban az entitásban. Tárolhatja például egy alkalmazott fényképét a Blob Storage-ban, és tárolhatja a fényképre mutató hivatkozást az alkalmazott entitás Fénykép tulajdonságában:
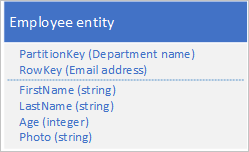
Problémák és megfontolandó szempontok
A minta megvalósítása során az alábbi pontokat vegye figyelembe:
- A Table service entitása és a Blob szolgáltatás adatai közötti végleges konzisztenciának fenntartásához használja az Végül konzisztens tranzakciós mintát az entitások karbantartásához.
- Egy teljes entitás lekérése legalább két tárolási tranzakciót foglal magában: egyet az entitás lekéréséhez, egyet pedig a blobadatok lekéréséhez.
Mikor érdemes ezt a mintát használni?
Ezt a mintát akkor használja, ha olyan entitásokat kell tárolnia, amelyek mérete meghaladja az egyes entitások korlátait a Table szolgáltatásban.
Kapcsolódó minták és útmutatók
Az alábbi minták és útmutatók szintén hasznosak lehetnek a minta megvalósításakor:
Előtűnési/hozzáfűzési minta
Ha nagy mennyiségű beszúrással rendelkezik, növelje a méretezhetőséget úgy, hogy a beszúrásokat több partícióra terjeszti.
Kontextus és probléma
Az entitások elő- vagy hozzáfűzése a tárolt entitásokhoz általában azt eredményezi, hogy az alkalmazás új entitásokat ad hozzá egy partíciósorozat első vagy utolsó partíciójához. Ebben az esetben az összes beszúrás ugyanabban a partícióban történik, amely megakadályozza, hogy a táblaszolgáltatás terheléselosztási beszúrásokat hozzon létre több csomóponton, és az alkalmazás elérhesse a partíció méretezhetőségi céljait. Ha például olyan alkalmazással rendelkezik, amely naplózza az alkalmazottak hálózat- és erőforrás-hozzáférését, akkor az alább látható entitásstruktúra azt eredményezheti, hogy az aktuális óra partíciója hotspottá válik, ha a tranzakciók mennyisége eléri az egyes partíciók méretezhetőségi célját:

Megoldás
Az alábbi alternatív entitásstruktúra elkerüli a hotspotot egy adott partíción, amikor az alkalmazás eseményeket naplóz:
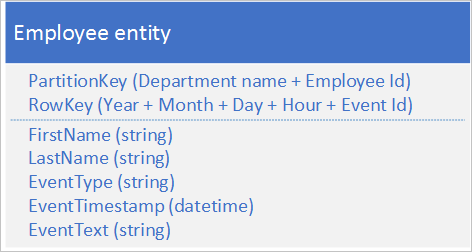
Ebből a példából megtudhatja, hogy a PartitionKey és a RowKey is összetett kulcs. A PartitionKey a részleg és az alkalmazott azonosítója alapján is elosztja a naplózást több partíció között.
Problémák és megfontolandó szempontok
A minta megvalósítása során az alábbi pontokat vegye figyelembe:
- Az alternatív kulcsstruktúra, amely elkerüli a gyakori partíciók beszúrásokon való létrehozását, támogatja-e hatékonyan az ügyfélalkalmazás által létrehozott lekérdezéseket?
- A várható tranzakciók mennyisége azt jelenti, hogy valószínűleg eléri az egyes partíciók méretezhetőségi céljait, és a tárolási szolgáltatás szabályozni fogja?
Mikor érdemes ezt a mintát használni?
Kerülje az előpendált/hozzáfűző antimintát, ha a tranzakciók mennyisége valószínűleg a tárolási szolgáltatás szabályozását eredményezi egy gyakori elérésű partíció elérésekor.
Kapcsolódó minták és útmutatók
Az alábbi minták és útmutatók szintén hasznosak lehetnek a minta megvalósításakor:
Naplóadatok anti-pattern
A naplóadatok tárolásához általában a Table szolgáltatás helyett a Blob szolgáltatást kell használnia.
Kontextus és probléma
A naplóadatok gyakori használati esete egy adott dátum/időtartomány naplóbejegyzéseinek lekérése: például meg szeretné keresni az alkalmazás által egy adott dátumon 15:04 és 15:06 között naplózott összes hibát és kritikus üzenetet. Nem szeretné a naplóüzenet dátumát és idejét használni annak a partíciónak a meghatározásához, amelybe naplóentitások menthetők: ez egy gyakori partíciót eredményez, mert bármikor az összes naplóentitás ugyanazt a PartitionKey-értéket fogja használni (lásd az Elő-előtag/hozzáfűzési minta című szakaszt). A naplóüzenetek következő entitásséma például egy gyakori particionálást eredményez, mert az alkalmazás az aktuális dátum és óra összes naplóüzenetét a partícióra írja:
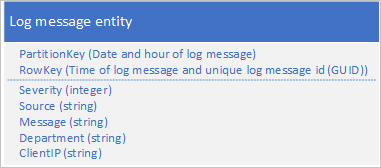
Ebben a példában a Sorkulcs tartalmazza a naplóüzenet dátumát és időpontját, hogy a naplóüzenetek dátum/idő sorrendben legyenek tárolva, és tartalmaz egy üzenetazonosítót, ha több naplóüzenet is ugyanazt a dátumot és időpontot használja.
Egy másik módszer a PartitionKey használata, amely biztosítja, hogy az alkalmazás üzeneteket írjon több partíción. Ha például a naplóüzenet forrása lehetővé teszi az üzenetek több partíció közötti elosztását, az alábbi entitásséma használható:
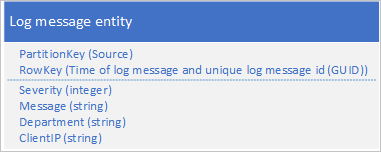
Ezzel a sémával azonban az a probléma, hogy a naplóüzenetek adott időtartamra való lekéréséhez a tábla minden partíciójában keresnie kell.
Megoldás
Az előző szakasz kiemelte azt a problémát, amely miatt a Table service-t a naplóbejegyzések tárolására próbálta használni, és két, nem megfelelő tervet javasolt. Az egyik megoldás egy gyakori elérésű partícióhoz vezetett, amely a gyenge teljesítményre vonatkozó naplóüzenetek kockázatával járt; a másik megoldás gyenge lekérdezési teljesítményt eredményezett, mivel a tábla minden partíciójának vizsgálatára van szükség a naplóüzenetek adott időre való lekéréséhez. A Blob Storage jobb megoldást kínál erre a forgatókönyvre, és így tárolja az Azure Storage Analytics az általa gyűjtött naplóadatokat.
Ez a szakasz azt ismerteti, hogy a Storage Analytics hogyan tárolja a naplóadatokat a Blob Storage-ban a jellemzően tartományonként lekérdezett adatok tárolására szolgáló módszer illusztrációjaként.
A Storage Analytics a naplóüzeneteket több blobban, tagolt formátumban tárolja. A tagolt formátum megkönnyíti az ügyfélalkalmazás számára a naplóüzenetben szereplő adatok elemzését.
A Storage Analytics a blobok elnevezési konvencióját használja, amely lehetővé teszi a keresett naplóüzeneteket tartalmazó blob (vagy blobok) megkeresését. A "queue/2014/07/31/1800/000001.log" nevű blob például az üzenetsor-szolgáltatáshoz kapcsolódó naplóüzeneteket tartalmaz, amelyek 2014. július 31-én 18:00-kor kezdődnek. A "000001" azt jelzi, hogy ez az időszak első naplófájlja. A Storage Analytics a blob metaadatainak részeként rögzíti a fájlban tárolt első és utolsó naplóüzenetek időbélyegeit is. A Blob Storage API lehetővé teszi, hogy névelőtag alapján keresse meg a blobokat egy tárolóban: a 18:00 órai időponttól kezdődően az üzenetsornapló adatait tartalmazó összes blob megkereséséhez használhatja a "queue/2014/07/31/1800" előtagot.
A Storage Analytics belsőleg puffereli a naplóüzeneteket, majd rendszeres időközönként frissíti a megfelelő blobot, vagy létrehoz egy újat a naplóbejegyzések legújabb kötegével. Ez csökkenti a blobszolgáltatásban végrehajtandó írások számát.
Ha egy hasonló megoldást implementál a saját alkalmazásában, meg kell fontolnia, hogyan kezelheti a megbízhatóság (minden naplóbejegyzés írása a Blob Storage-ba, ahogy történik) és a költség és a méretezhetőség (az alkalmazás frissítéseinek pufferelése és a blobtárolóba való írása kötegekben).
Problémák és megfontolandó szempontok
A naplóadatok tárolásának eldöntésekor vegye figyelembe a következő szempontokat:
- Ha olyan táblázattervet hoz létre, amely elkerüli a gyakori elérésű partíciókat, előfordulhat, hogy nem tudja hatékonyan elérni a naplóadatokat.
- A naplóadatok feldolgozásához az ügyfélnek gyakran sok rekordot kell betöltenie.
- Bár a naplóadatok gyakran strukturáltak, a Blob Storage jobb megoldás lehet.
Implementálási szempontok
Ez a szakasz az előző szakaszokban leírt minták megvalósítása során figyelembe veendő szempontok némelyikét ismerteti. A szakasz nagy része olyan C# nyelven írt példákat használ, amelyek a Storage-ügyfélkódtárat használják (az íráskor a 4.3.0-s verziót).
Entitások lekérése
A lekérdezés tervezésével foglalkozó szakaszban leírtak szerint a leghatékonyabb lekérdezés egy pont lekérdezés. Bizonyos esetekben azonban előfordulhat, hogy több entitást kell lekérnie. Ez a szakasz az entitások Storage-ügyfélkódtár használatával történő lekérésének néhány gyakori módszerét ismerteti.
Pont-lekérdezés végrehajtása a Storage-ügyfélkódtár használatával
Pont típusú lekérdezések végrehajtásának legegyszerűbb módja a GetEntityAsync metódus használata az alábbi C# kódrészletben látható módon, amely lekéri a "Sales" értékű PartitionKey és a "212" értékű RowKey nevű entitást:
EmployeeEntity employee = await employeeTable.GetEntityAsync<EmployeeEntity>("Sales", "212");
Figyelje meg, hogy ez a példa hogyan várja el, hogy a lekért entitás EmployeeEntity típusú legyen.
Több entitás lekérése a LINQ használatával
A LINQ használatával több entitást is lekérhet a Table szolgáltatásból a Microsoft Azure Cosmos DB Table Standard library használatakor.
dotnet add package Azure.Data.Tables
Az alábbi példák működéséhez névtereket kell tartalmaznia:
using System.Linq;
using Azure.Data.Tables
Több entitás beolvasása egy szűrőzáradékkal rendelkező lekérdezés megadásával érhető el. A táblavizsgálat elkerülése érdekében mindig szerepeltesse a PartitionKey értéket a szűrő záradékban, és ha lehetséges, a RowKey értéket a tábla- és partícióvizsgálatok elkerülése érdekében. A táblaszolgáltatás korlátozott számú összehasonlító operátort támogat (nagyobb, nagyobb vagy egyenlő, kisebb, kisebb vagy egyenlő, egyenlő és nem egyenlő) a szűrő záradékban való használathoz.
Az alábbi példában employeeTable egy TableClient objektum látható. Ez a példa megkeresi az összes olyan alkalmazottat, akinek a vezetékneve "B" (feltéve, hogy a RowKey a vezetéknevet tárolja) az értékesítési részlegben (feltéve, hogy a PartitionKey tárolja a részleg nevét):
var employees = employeeTable.Query<EmployeeEntity>(e => (e.PartitionKey == "Sales" && e.RowKey.CompareTo("B") >= 0 && e.RowKey.CompareTo("C") < 0));
Figyelje meg, hogyan adja meg a lekérdezés a RowKey és a PartitionKey paramétert is a jobb teljesítmény érdekében.
Az alábbi kódminta a LINQ szintaxis használata nélkül jeleníti meg az egyenértékű funkciókat:
var employees = employeeTable.Query<EmployeeEntity>(filter: $"PartitionKey eq 'Sales' and RowKey ge 'B' and RowKey lt 'C'");
Megjegyzés:
A minta lekérdezési metódusok a három szűrőfeltételt tartalmazzák.
Nagy számú entitás lekérdezésből való lekérése
Az optimális lekérdezés egy partíciókulcs- és egy RowKey-érték alapján ad vissza egy egyedi entitást. Bizonyos esetekben azonban követelmény lehet, hogy több entitást adjon vissza ugyanabból a partícióból vagy akár több partícióból is.
Ilyen esetekben mindig teljes mértékben tesztelnie kell az alkalmazás teljesítményét.
A táblaszolgáltatással kapcsolatos lekérdezések egyszerre legfeljebb 1000 entitást adhatnak vissza, és legfeljebb öt másodpercig hajthatók végre. Ha az eredményhalmaz több mint 1000 entitást tartalmaz, ha a lekérdezés öt másodpercen belül nem fejeződött be, vagy ha a lekérdezés átlépi a partíció határát, a Table service egy folytatási jogkivonatot ad vissza, amely lehetővé teszi az ügyfélalkalmazás számára a következő entitáskészlet kérését. A folytatási jogkivonatok működéséről további információt a Lekérdezés időtúllépése és a Lapozás című témakörben talál.
Ha az Azure Tables ügyfélkódtárát használja, az automatikusan képes kezelni a folytatási jogkivonatokat, mivel az entitásokat ad vissza a Table szolgáltatásból. Az ügyfélkódtárat használó következő C#-kódminta automatikusan kezeli a folytatási jogkivonatokat, ha a táblaszolgáltatás válaszban adja vissza őket:
var employees = employeeTable.Query<EmployeeEntity>("PartitionKey eq 'Sales'")
foreach (var emp in employees)
{
// ...
}
Megadhatja az egy oldalonként visszaadott entitások maximális számát is. Az alábbi példa bemutatja, hogyan kérdezhet le entitásokat a következővel maxPerPage:
var employees = employeeTable.Query<EmployeeEntity>(maxPerPage: 10);
// Iterate the Pageable object by page
foreach (var page in employees.AsPages())
{
// Iterate the entities returned for this page
foreach (var emp in page.Values)
{
// ...
}
}
Speciálisabb esetekben érdemes lehet tárolni a szolgáltatásból visszaadott folytatási jogkivonatot, hogy a kód pontosan a következő oldalak beolvasásának időpontjára legyen szabályozva. Az alábbi példa egy alapforgatókönyvet mutat be, amely beolvassa és alkalmazza a jogkivonatot a lapszámozott eredményekre:
string continuationToken = null;
bool moreResultsAvailable = true;
while (moreResultsAvailable)
{
var page = employeeTable
.Query<EmployeeEntity>()
.AsPages(continuationToken, pageSizeHint: 10)
.FirstOrDefault(); // pageSizeHint limits the number of results in a single page, so we only enumerate the first page
if (page == null)
break;
// Get the continuation token from the page
// Note: This value can be stored so that the next page query can be executed later
continuationToken = page.ContinuationToken;
var pageResults = page.Values;
moreResultsAvailable = pageResults.Any() && continuationToken != null;
// Iterate the results for this page
foreach (var result in pageResults)
{
// ...
}
}
A folytatási jogkivonatok explicit használatával szabályozhatja, hogy az alkalmazás mikor kéri le a következő adatszegmenst. Ha például az ügyfélalkalmazás lehetővé teszi, hogy a felhasználók végiglapozzanak a táblában tárolt entitásokon, a felhasználó dönthet úgy, hogy nem lapozza át a lekérdezés által lekért összes entitást, így az alkalmazás csak egy folytatási jogkivonatot használna a következő szegmens lekéréséhez, ha a felhasználó befejezte a lapozást az aktuális szegmens összes entitásán. Ez a megközelítés számos előnnyel jár:
- Ez lehetővé teszi a Table szolgáltatásból lekérhető adatok mennyiségének korlátozását, valamint a hálózaton való áthelyezést.
- Lehetővé teszi az aszinkron IO végrehajtását a .NET-ben.
- Lehetővé teszi a folytatási jogkivonat állandó tárterületre való szerializálását, hogy az alkalmazás összeomlása esetén is folytatódjon.
Megjegyzés:
A folytatási jogkivonat általában egy 1000 entitást tartalmazó szegmenst ad vissza, bár kevesebb is lehet. Ez akkor is így van, ha a Lekérdezés által visszaadott bejegyzések számát a Take paranccsal korlátozza a keresési feltételeknek megfelelő első n entitások visszaadásához: a táblaszolgáltatás egy n-nél kevesebb entitást tartalmazó szegmenst és egy folytatási jogkivonatot is visszaadhat, amely lehetővé teszi a fennmaradó entitások lekérését.
Kiszolgálóoldali vetítés
Egyetlen entitás legfeljebb 255 tulajdonsággal rendelkezhet, és legfeljebb 1 MB méretű lehet. Ha lekérdezi a táblát, és lekéri az entitásokat, előfordulhat, hogy nincs szüksége az összes tulajdonságra, és elkerülheti az adatok szükségtelen átvitelét (a késés és a költségek csökkentése érdekében). A kiszolgálóoldali vetítéssel csak a szükséges tulajdonságokat viheti át. Az alábbi példa csak az E-mail tulajdonságot kéri le (a PartitionKey, a RowKey, az Időbélyeg és az ETag mellett) a lekérdezés által kiválasztott entitásokból.
var subsetResults = query{
for employee in employeeTable.Query<EmployeeEntity>("PartitionKey eq 'Sales'") do
select employee.Email
}
foreach (var e in subsetResults)
{
Console.WriteLine("RowKey: {0}, EmployeeEmail: {1}", e.RowKey, e.Email);
}
Figyelje meg, hogyan érhető el a RowKey érték annak ellenére, hogy nem szerepel a lekérendő tulajdonságok listájában.
Entitások módosítása
A Storage-ügyfélkódtár lehetővé teszi a táblaszolgáltatásban tárolt entitások módosítását entitások beszúrásával, törlésével és frissítésével. Az EGT-k használatával több beszúrási, frissítési és törlési műveletet kötenek össze, hogy csökkentse a szükséges utak számát, és javítsa a megoldás teljesítményét.
A Storage-ügyfélkódtár egt-beli végrehajtásakor fellépő kivételek általában tartalmazzák annak az entitásnak az indexét, amely a köteg meghiúsulását okozta. Ez akkor hasznos, ha EGT-eket használó kódot keres.
Azt is figyelembe kell vennie, hogy a kialakítás hogyan befolyásolja az ügyfélalkalmazás egyidejűségi és frissítési műveleteit.
Az egyidejűség kezelése
Alapértelmezés szerint a táblaszolgáltatás optimista egyidejűségi ellenőrzéseket hajt végre a Beszúrás, egyesítés és Törlés műveletek egyes entitásainak szintjén, bár lehetséges, hogy az ügyfél kényszerítse a táblaszolgáltatást ezen ellenőrzések megkerülésére. További információ arról, hogy a táblaszolgáltatás hogyan kezeli az egyidejűséget: Concurrency kezelése a Microsoft Azure Storage-ban.
Egyesítés vagy csere
A TableOperation osztály Csere metódusa mindig lecseréli a Table service teljes entitását. Ha nem tartalmaz tulajdonságot a kérelemben, ha a tulajdonság megtalálható a tárolt entitásban, a kérés eltávolítja a tulajdonságot a tárolt entitásból. Hacsak nem szeretne explicit módon eltávolítani egy tulajdonságot egy tárolt entitásból, minden tulajdonságot bele kell foglalnia a kérelembe.
A TableOperation osztály egyesítési módszerével csökkentheti a Table service-nek küldött adatok mennyiségét, amikor frissíteni szeretne egy entitást. Az egyesítési módszer a tárolt entitás minden tulajdonságát lecseréli a kérelemben szereplő entitás tulajdonságértékére, de érintetlenül hagyja a tárolt entitás azon tulajdonságait, amelyek nem szerepelnek a kérelemben. Ez akkor hasznos, ha nagy entitásokkal rendelkezik, és csak kis számú tulajdonságot kell frissítenie egy kérelemben.
Megjegyzés:
A Csere és az egyesítés metódus nem működik, ha az entitás nem létezik. Alternatív megoldásként használhatja az InsertOrReplace és az InsertOrMerge metódusokat, amelyek létrehoznak egy új entitást, ha az nem létezik.
Heterogén entitástípusok használata
A Table service egy séma nélküli táblatároló, amely azt jelenti, hogy egyetlen tábla több típusú entitást tárolhat, így nagy rugalmasságot biztosít a tervezésben. Az alábbi példa egy olyan táblát mutat be, amely az alkalmazotti és a részlegentitásokat egyaránt tárolja:
| PartitionKey | RowKey | Timestamp | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| |||||||||||
| |||||||||||
|
|||||||||||
|
Minden entitásnak továbbra is PartitionKey, RowKey és Timestamp értékekkel kell rendelkeznie, de bármilyen tulajdonságkészlettel rendelkezhet. Ezenkívül az entitás típusát semmi sem jelzi, kivéve, ha úgy dönt, hogy valahol tárolja ezeket az információkat. Az entitástípus azonosítására két lehetőség áll rendelkezésre:
- Az entitástípust előre fel kell függesztetnie a RowKey (vagy esetleg a PartitionKey) elemre. Például: EMPLOY Enterprise kiadás_000123 vagy DEPARTMENT_SALES Sorkulcs értékként.
- Az entitástípust egy külön tulajdonság használatával rögzítheti az alábbi táblázatban látható módon.
| PartitionKey | RowKey | Timestamp | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| |||||||||||||
| |||||||||||||
|
|||||||||||||
|
Az első lehetőség, amely az entitástípust a Sorkulcsra írja elő, akkor hasznos, ha fennáll annak a lehetősége, hogy két különböző típusú entitás ugyanazt a kulcsértéket használja. Az azonos típusú entitásokat is csoportosítja a partícióban.
Az ebben a szakaszban tárgyalt technikák különösen fontosak a Kapcsolatok modellezése című cikk korábbi, öröklési kapcsolatok című témakörében.
Megjegyzés:
Érdemes megfontolnia egy verziószámot az entitástípus értékében, hogy az ügyfélalkalmazások poCO-objektumokat fejlesshessenek, és különböző verziókkal dolgozhassanak.
A szakasz további része a Storage ügyfélkódtár néhány olyan funkcióját ismerteti, amelyek megkönnyítik a több entitástípus használatát ugyanabban a táblában.
Heterogén entitástípusok beolvasása
Ha a Table ügyfélkódtárat használja, három lehetőség közül választhat, hogy több entitástípust használ-e.
Ha ismeri az adott RowKey és PartitionKey értékekkel tárolt entitás típusát, akkor megadhatja az entitás típusát, amikor lekéri az entitást az Előző két példa EmployeeEntity típusú entitások lekéréséhez: Pontlekérdezés végrehajtása a Storage ügyfélkódtár használatával, és több entitás lekérése a LINQ használatával.
A második lehetőség a TableEntity típus (tulajdonságcsomag) használata konkrét POCO-entitástípus helyett (ez a beállítás a teljesítményt is javíthatja, mivel nem szükséges szerializálni és deszerializálni az entitást .NET-típusokba). Az alábbi C#-kód több különböző típusú entitást is lekérhet a táblából, de az összes entitást TableEntity-példányként adja vissza. Ezután az EntityType tulajdonság használatával határozza meg az egyes entitások típusát:
Pageable<TableEntity> entities = employeeTable.Query<TableEntity>(x =>
x.PartitionKey == "Sales" && x.RowKey.CompareTo("B") >= 0 && x.RowKey.CompareTo("F") <= 0)
foreach (var entity in entities)
{
if (entity.GetString("EntityType") == "Employee")
{
// use entityTypeProperty, RowKey, PartitionKey, Etag, and Timestamp
}
}
Más tulajdonságok lekéréséhez a TableEntity osztály entitásánakGetString metódusát kell használnia.
Heterogén entitástípusok módosítása
A törléshez nem kell ismernie az entitás típusát, és a beszúráskor mindig tudja az entitás típusát. A TableEntity típussal azonban anélkül frissíthet egy entitást, hogy ismerné annak típusát, és nem használ poCO-entitásosztályt. Az alábbi kódminta egyetlen entitást kér le, és a frissítés előtt ellenőrzi az EmployeeCount tulajdonság meglétét.
var result = employeeTable.GetEntity<TableEntity>(partitionKey, rowKey);
TableEntity department = result.Value;
if (department.GetInt32("EmployeeCount") == null)
{
throw new InvalidOperationException("Invalid entity, EmployeeCount property not found.");
}
employeeTable.UpdateEntity(department, ETag.All, TableUpdateMode.Merge);
Hozzáférés vezérlése közös hozzáférésű jogosultságkódokkal
A közös hozzáférésű jogosultságkód (SAS) jogkivonatokkal engedélyezheti az ügyfélalkalmazásoknak a táblaentitások módosítását (és lekérdezését) anélkül, hogy a tárfiókkulcsot bele kellene foglalniuk a kódba. Az SAS használatának általában három fő előnye van az alkalmazásban:
- Nem kell a tárfiókkulcsot nem biztonságos platformra (például mobileszközre) terjesztenie annak érdekében, hogy az eszköz hozzáférhessen és módosíthassa az entitásokat a Table szolgáltatásban.
- A webes és feldolgozói szerepkörök által az entitások ügyféleszközökre, például végfelhasználói számítógépekre és mobileszközökre történő kezelése során végzett munka egy részét ki is lehet kapcsolni.
- Korlátozott és időkorlátos engedélyeket rendelhet egy ügyfélhez (például írásvédett hozzáférést engedélyezhet adott erőforrásokhoz).
Az SAS-jogkivonatok tableszolgáltatással való használatáról további információt a Megosztott hozzáférésű jogosultságkódok (SAS) használata című témakörben talál.
Azonban továbbra is létre kell hoznia azokat az SAS-jogkivonatokat, amelyek egy ügyfélalkalmazást biztosítanak a táblaszolgáltatás entitásainak: ezt olyan környezetben kell elvégeznie, amely biztonságos hozzáférést biztosít a tárfiókkulcsokhoz. Általában webes vagy feldolgozói szerepkörrel hozza létre az SAS-jogkivonatokat, és kézbesíti őket az entitásokhoz hozzáférést igénylő ügyfélalkalmazásoknak. Mivel az SAS-jogkivonatok létrehozása és az ügyfeleknek történő kézbesítése továbbra is többletterhelést jelent, érdemes megfontolnia, hogyan csökkentheti a többletterhelést, különösen nagy volumenű forgatókönyvekben.
Létrehozhat egy SAS-jogkivonatot, amely hozzáférést biztosít a tábla entitásainak egy részhalmazához. Alapértelmezés szerint egy SAS-jogkivonatot hoz létre egy teljes táblához, de azt is megadhatja, hogy az SAS-jogkivonat hozzáférést biztosít-e a PartitionKey értékek tartományához, vagy a PartitionKey és a RowKey értékek tartományához. Dönthet úgy, hogy SAS-jogkivonatokat hoz létre a rendszer egyes felhasználói számára, hogy az egyes felhasználók SAS-jogkivonata csak a táblaszolgáltatásban lévő saját entitásokhoz férhessen hozzá.
Aszinkron és párhuzamos műveletek
Feltéve, hogy több partícióra terjeszti a kéréseket, aszinkron vagy párhuzamos lekérdezések használatával javíthatja az átviteli sebességet és az ügyfél válaszkészségét. Előfordulhat például, hogy két vagy több feldolgozói szerepkörpéldánysal is rendelkezik, amelyek párhuzamosan férnek hozzá a táblákhoz. Előfordulhat, hogy egyes feldolgozói szerepkörök felelősek bizonyos partíciókért, vagy egyszerűen több feldolgozói szerepkör-példánysal rendelkeznek, amelyek mindegyike képes elérni a tábla összes partícióját.
Egy ügyfélpéldányon belül a tárolási műveletek aszinkron végrehajtásával javíthatja az átviteli sebességet. A Storage-ügyfélkódtár megkönnyíti az aszinkron lekérdezések és módosítások írását. Első lépés lehet például a szinkron metódus, amely egy partíció összes entitását lekéri az alábbi C#-kódban látható módon:
private static void ManyEntitiesQuery(TableClient employeeTable, string department)
{
TableContinuationToken continuationToken = null;
do
{
var employees = employeeTable.Query<EmployeeEntity>($"PartitionKey eq {department}");
foreach (var emp in employees.AsPages())
{
// ...
continuationToken = emp.ContinuationToken;
}
} while (continuationToken != null);
}
Ezt a kódot egyszerűen módosíthatja úgy, hogy a lekérdezés aszinkron módon fusson az alábbiak szerint:
private static async Task ManyEntitiesQueryAsync(TableClient employeeTable, string department)
{
TableContinuationToken continuationToken = null;
do
{
var employees = await employeeTable.QueryAsync<EmployeeEntity>($"PartitionKey eq {department}");
foreach (var emp in employees.AsPages())
{
// ...
continuationToken = emp.ContinuationToken;
}
} while (continuationToken != null);
}
Ebben az aszinkron példában a következő változások láthatók a szinkron verzióban:
- A metódus aláírása mostantól tartalmazza az aszinkron módosítót, és visszaad egy Feladatpéldányt.
- A lekérdezési metódus meghívása helyett a metódus meghívja a QueryAsync metódust, és a várakozási módosító használatával aszinkron módon kéri le az eredményeket.
Az ügyfélalkalmazás többször is meghívhatja ezt a metódust (a részlegparaméter különböző értékeivel), és minden lekérdezés külön szálon fog futni.
Az entitásokat aszinkron módon is beszúrhatja, frissítheti és törölheti. Az alábbi C#-példa egy egyszerű, szinkron metódust mutat be egy alkalmazotti entitás beszúrásához vagy cseréjéhez:
private static void SimpleEmployeeUpsert(
TableClient employeeTable,
EmployeeEntity employee)
{
var result = employeeTable.UpdateEntity(employee, Azure.ETag.All, TableUpdateMode.Replace);
Console.WriteLine("HTTP Status: {0}", result.Status);
}
Ezt a kódot egyszerűen módosíthatja úgy, hogy a frissítés aszinkron módon fusson az alábbiak szerint:
private static async Task SimpleEmployeeUpsertAsync(
TableClient employeeTable,
EmployeeEntity employee)
{
var result = await employeeTable.UpdateEntityAsync(employee, Azure.ETag.All, TableUpdateMode.Replace);
Console.WriteLine("HTTP Status: {0}", result.Result.Status);
}
Ebben az aszinkron példában a következő változások láthatók a szinkron verzióban:
- A metódus aláírása mostantól tartalmazza az aszinkron módosítót, és visszaad egy Feladatpéldányt.
- Az Entitás frissítéséhez az Execute metódus meghívása helyett a metódus meghívja az ExecuteAsync metódust, és a várakozási módosító használatával aszinkron módon kéri le az eredményeket.
Az ügyfélalkalmazás több aszinkron metódust is meghívhat, és minden metódushívás külön szálon fog futni.