Oktatóanyag: Event Hubs-adatok parquet formátumban történő rögzítése és elemzése Azure Synapse Analytics használatával
Ez az oktatóanyag bemutatja, hogyan hozhat létre olyan feladatot a Stream Analytics nincs kódszerkesztővel, amely az Event Hubs-adatokat parquet formátumban Azure Data Lake Storage Gen2.
Eben az oktatóanyagban az alábbiakkal fog megismerkedni:
- Eseménygenerátor üzembe helyezése, amely mintaeseményeket küld egy eseményközpontba
- Stream Analytics-feladat létrehozása kódszerkesztő nélkül
- Bemeneti adatok és séma áttekintése
- Konfigurálja Azure Data Lake Storage Gen2, hogy melyik eseményközpont adatai legyenek rögzítve
- Stream Analytics-feladat futtatása
- A parquet-fájlok lekérdezése a Azure Synapse Analytics használatával
Előfeltételek
A kezdés előtt győződjön meg arról, hogy elvégezte a következő lépéseket:
- Ha nem rendelkezik Azure-előfizetéssel, hozzon létre egy ingyenes fiókot.
- Telepítse a TollApp eseménygenerátor alkalmazást az Azure-ban. Állítsa az intervallum paramétert 1 értékre, és használjon egy új erőforráscsoportot ehhez a lépéshez.
- Hozzon létre egy Azure Synapse Analytics-munkaterületet egy Data Lake Storage Gen2 fiókkal.
Stream Analytics-feladat létrehozása kódszerkesztő nélkül
Keresse meg azt az erőforráscsoportot, amelyben a TollApp eseménygenerátor üzembe lett helyezve.
Válassza ki a Azure Event Hubs névteret.
Az Event Hubs-névtér lapon válassza az Event Hubs elemet a bal oldali menü Entitások területén.
Válassza ki a példányt
entrystream.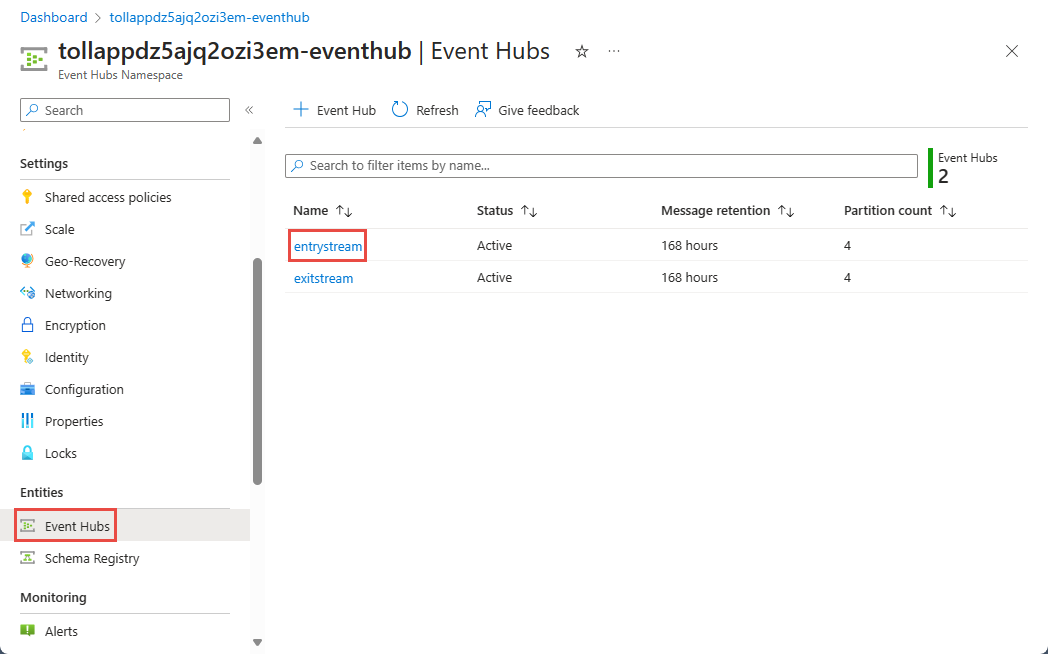
Az Event Hubs-példány lapon válassza az Adatok feldolgozása lehetőséget a bal oldali menü Szolgáltatások szakaszában.
Válassza a Start lehetőséget az Adatok rögzítése az ADLS Gen2-be parquet formátumú csempén.
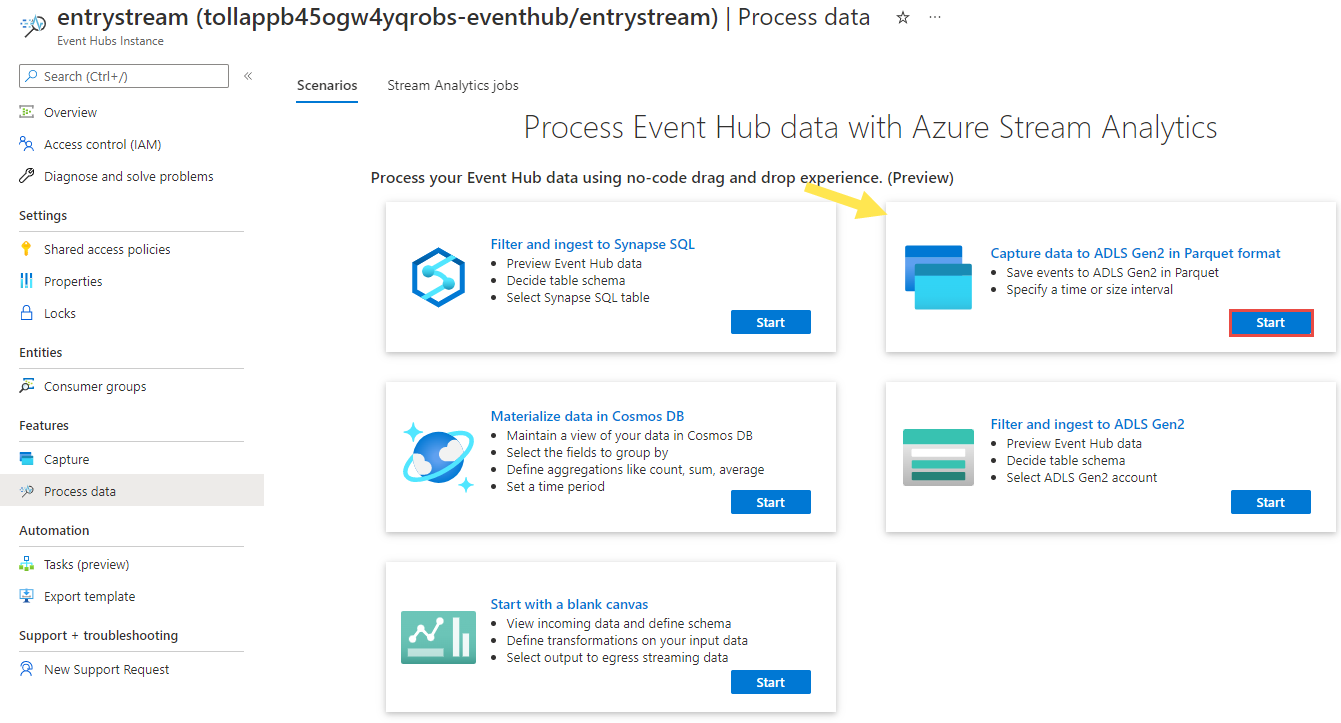
Nevezze el a feladatot
parquetcapture, és válassza a Létrehozás lehetőséget.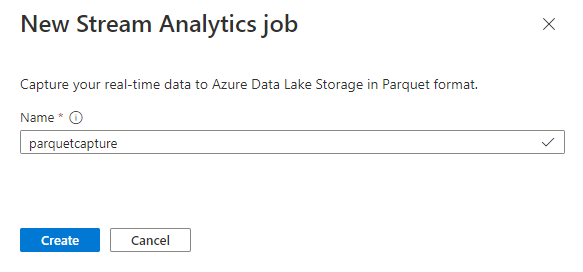
Az eseményközpont konfigurációs oldalán erősítse meg az alábbi beállításokat, majd válassza a Csatlakozás lehetőséget.
Fogyasztói csoport: Alapértelmezett
A bemeneti adatok szerializálási típusa: JSON
Hitelesítési mód , amellyel a feladat csatlakozni fog az eseményközponthoz: Kapcsolati sztring.
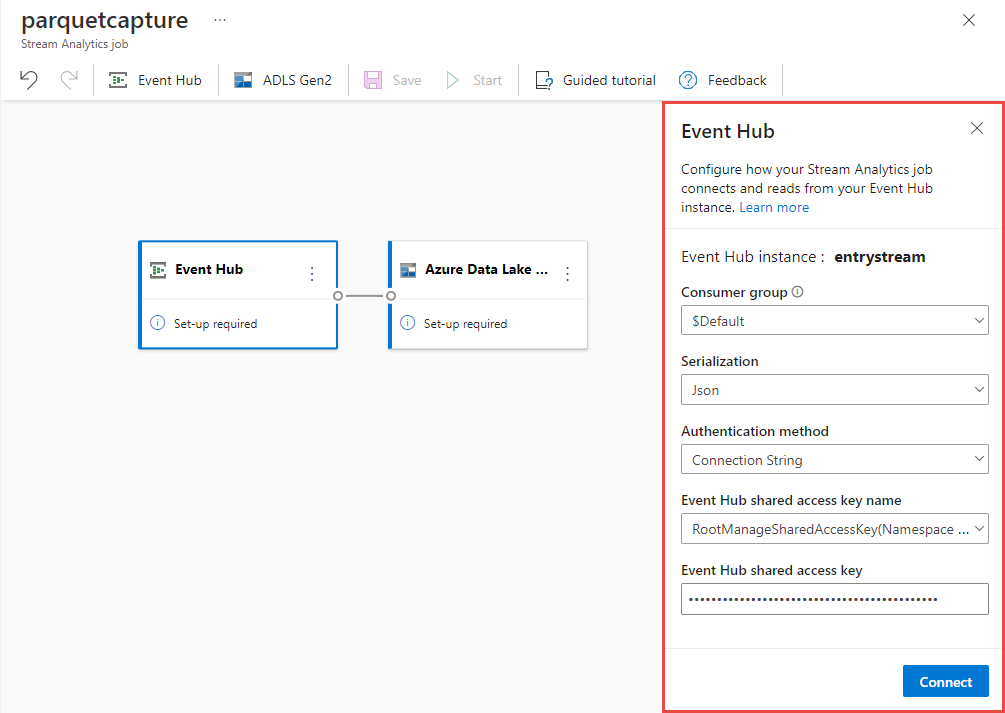
Néhány másodpercen belül látni fogja a minta bemeneti adatokat és a sémát. Dönthet úgy, hogy elveti a mezőket, átnevezi a mezőket, vagy módosítja az adattípust.
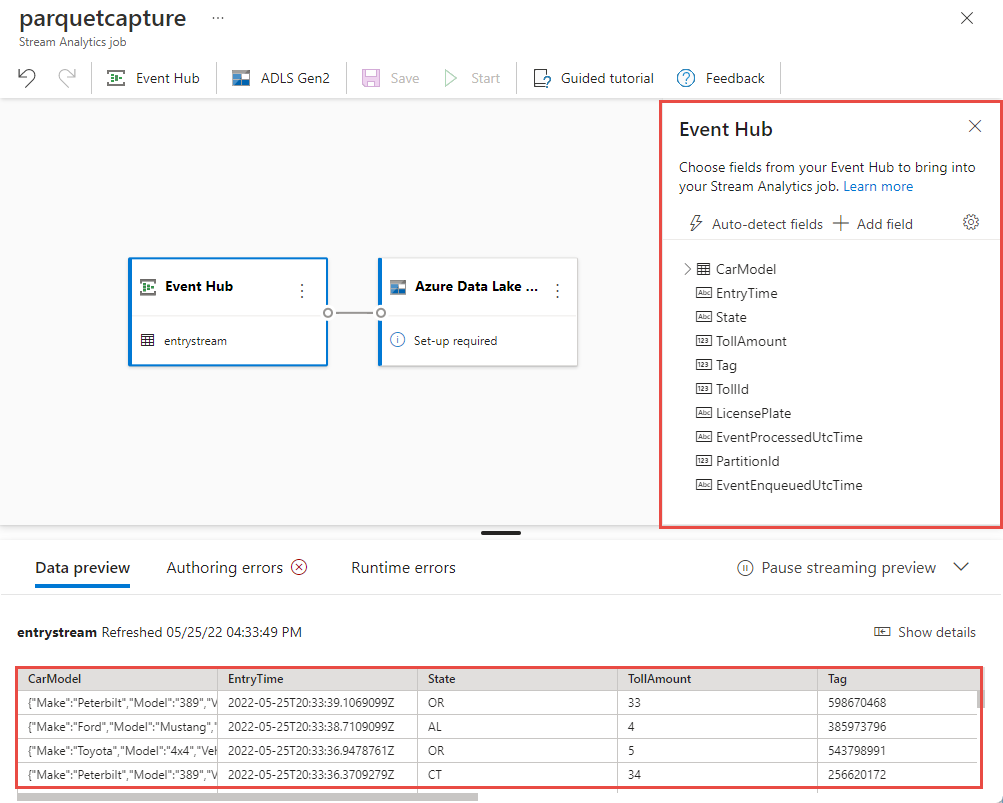
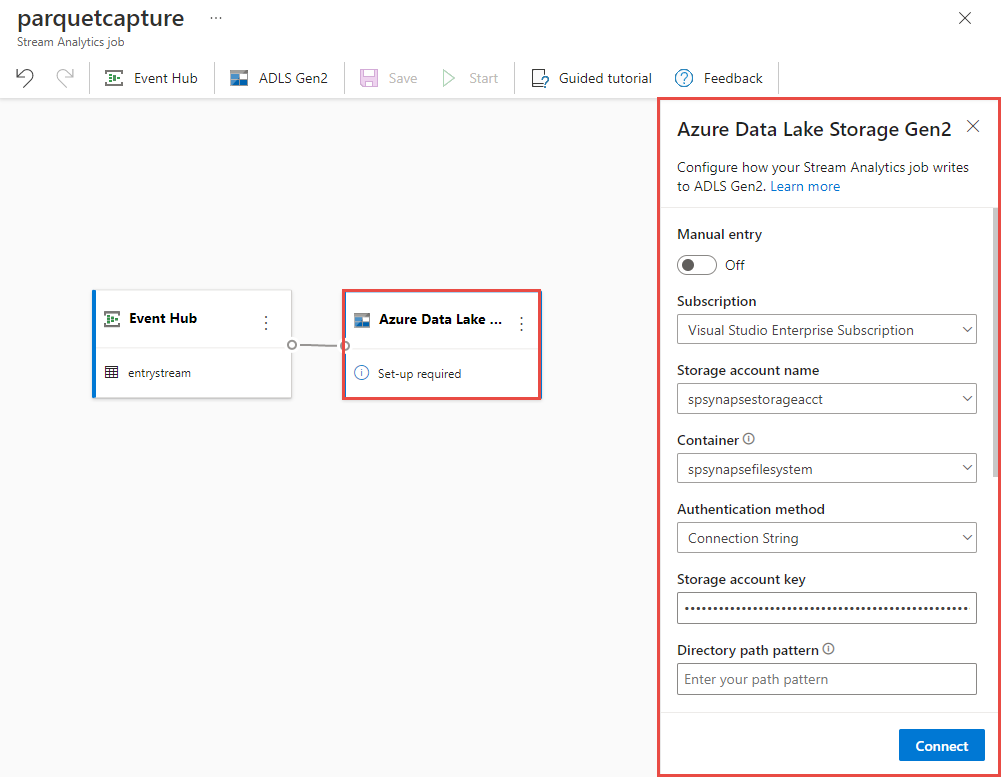
Válassza ki a Azure Data Lake Storage Gen2 csempét a vásznon, és konfigurálja a
- Előfizetés, ahol az Azure Data Lake Gen2-fiók a következő helyen található:
- A tárfiók neve, amelynek meg kell egyeznie a Azure Synapse Analytics-munkaterülethez használt ADLS Gen2-fiókkal, az Előfeltételek szakaszban.
- Tároló, amelyen belül létrejönnek a Parquet-fájlok.
- Elérésiút-minta {date}/{time} értékre állítva
- A dátum- és időminta az alapértelmezett éééé-hh-nn és óóé.
- Válassza a Csatlakozás lehetőséget
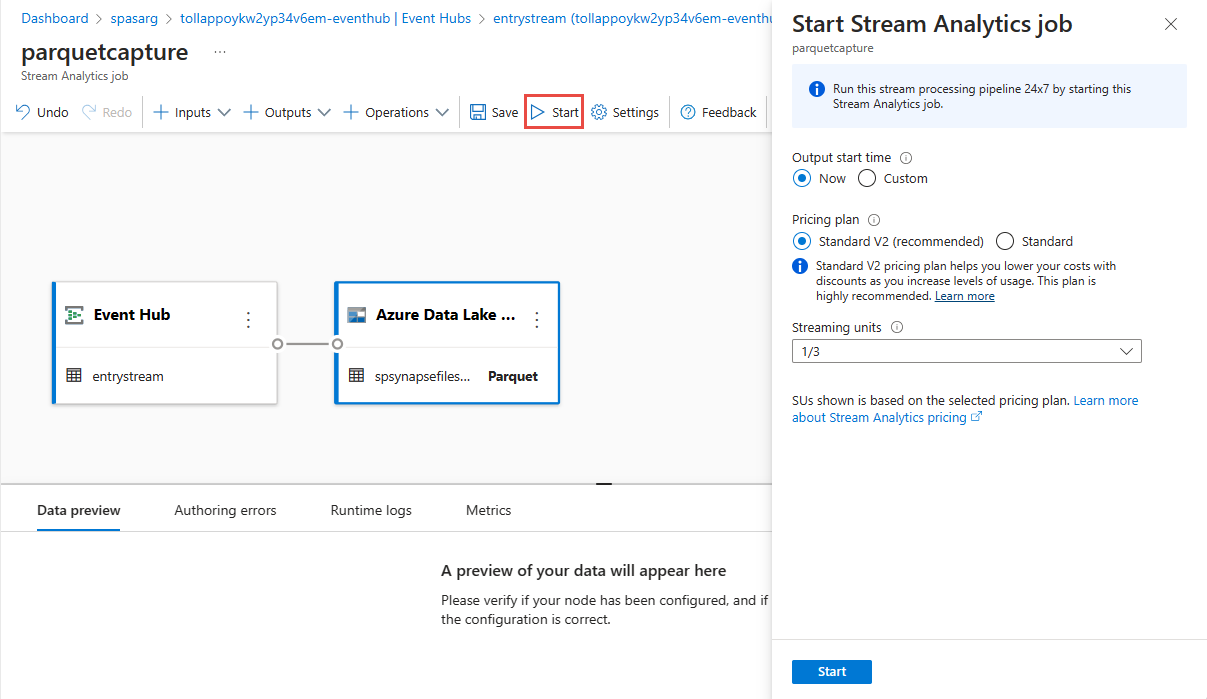
A felső menüszalagon válassza a Mentés lehetőséget a feladat mentéséhez, majd válassza a Start lehetőséget a feladat futtatásához. A feladat elindítása után a jobb sarokban válassza az X lehetőséget a Stream Analytics-feladatlap bezárásához.
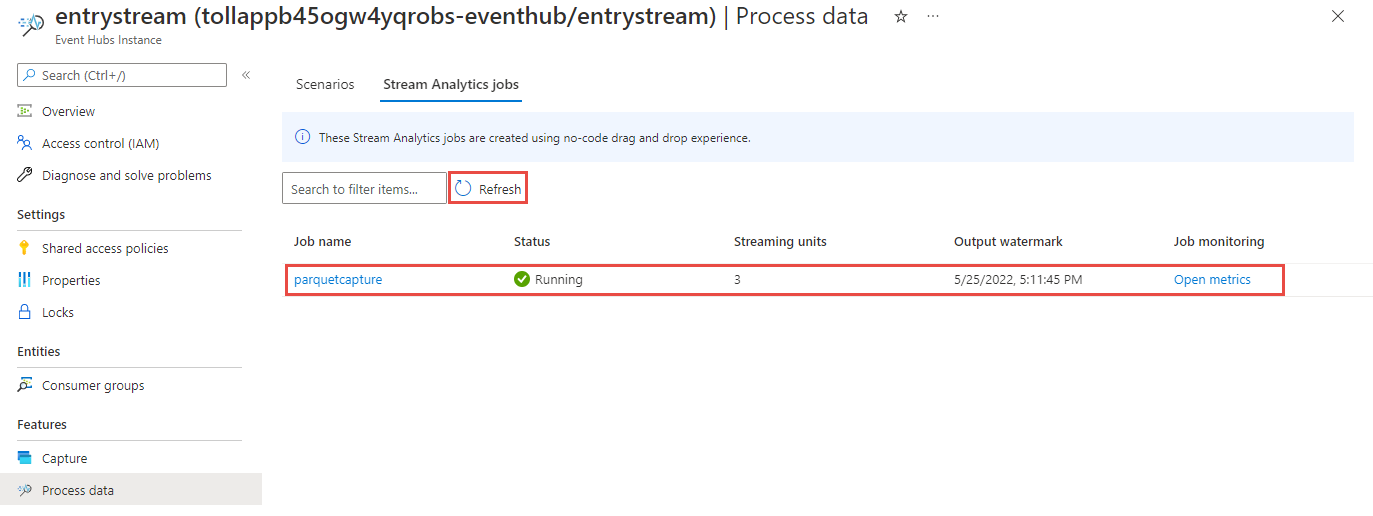
Ezután megjelenik a kódszerkesztővel létrehozott Összes Stream Analytics-feladat listája. Két percen belül a feladat futási állapotba kerül. A lapon a Frissítés gombra kattintva megtekintheti, hogy az állapot a Létrehozás – Indítás –>> Futtatás beállításról változik-e.








Kimenet megtekintése a Azure Data Lake Storage Gen 2-fiókban
Keresse meg az előző lépésben használt Azure Data Lake Storage Gen2 fiókot.
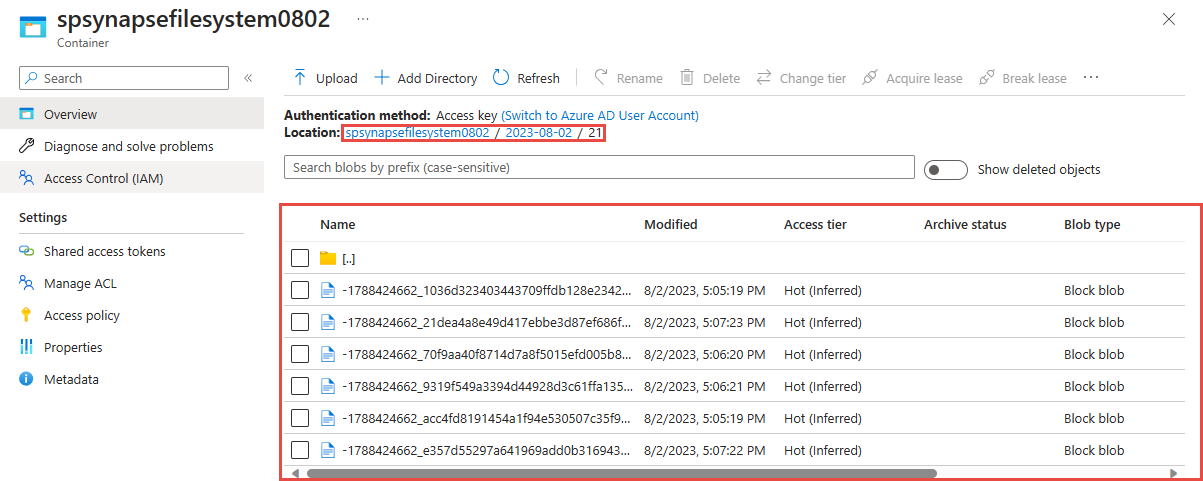
Válassza ki az előző lépésben használt tárolót. Az előző lépésben használt {date}/{time} útvonalminta alapján létrehozott parkettafájlok láthatók.
Rögzített adatok lekérdezése Parquet formátumban Azure Synapse Analytics használatával
Lekérdezés Azure Synapse Spark használatával
Keresse meg a Azure Synapse Analytics-munkaterületet, és nyissa meg a Synapse Studio.
Hozzon létre egy kiszolgáló nélküli Apache Spark-készletet a munkaterületen, ha még nem létezik.
A Synapse Studio lépjen a Fejlesztés központra, és hozzon létre egy új jegyzetfüzetet.
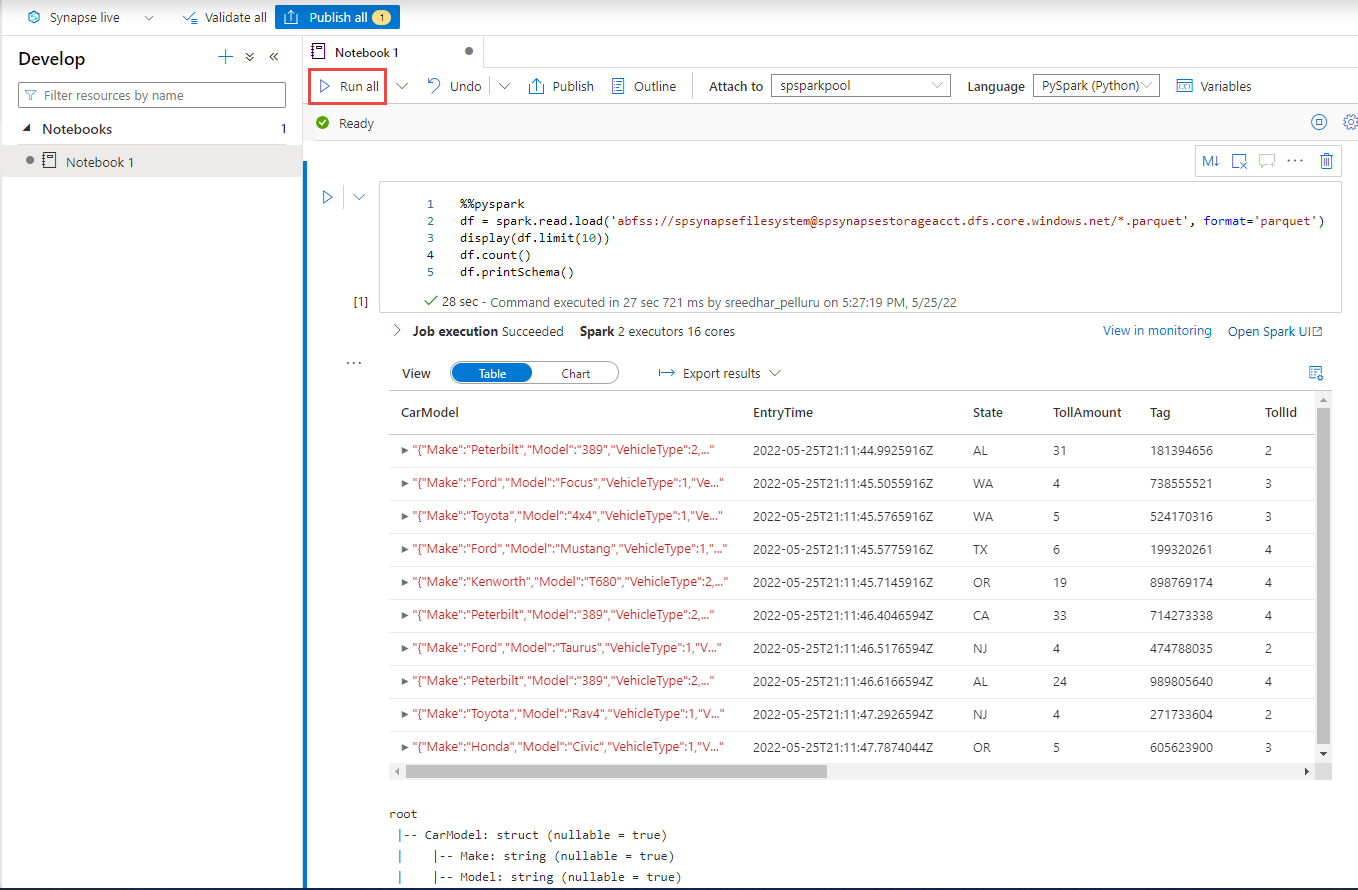
Hozzon létre egy új kódcellát, és illessze be a következő kódot a cellába. Cserélje le a tárolót és az adlsname-t az előző lépésben használt tároló és ADLS Gen2-fiók nevére.
%%pyspark df = spark.read.load('abfss://container@adlsname.dfs.core.windows.net/*/*/*.parquet', format='parquet') display(df.limit(10)) df.count() df.printSchema()Az eszköztár Csatolás eleméhez válassza ki a Spark-készletet a legördülő listából.
Az eredmények megtekintéséhez válassza az Összes futtatása lehetőséget

Lekérdezés Azure Synapse kiszolgáló nélküli SQL használatával
A Fejlesztési központban hozzon létre egy új SQL-szkriptet.
Illessze be a következő szkriptet, és futtassa a beépített kiszolgáló nélküli SQL-végponttal . Cserélje le a tárolót és az adlsname-t az előző lépésben használt tároló és ADLS Gen2-fiók nevére.
SELECT TOP 100 * FROM OPENROWSET( BULK 'https://adlsname.dfs.core.windows.net/container/*/*/*.parquet', FORMAT='PARQUET' ) AS [result]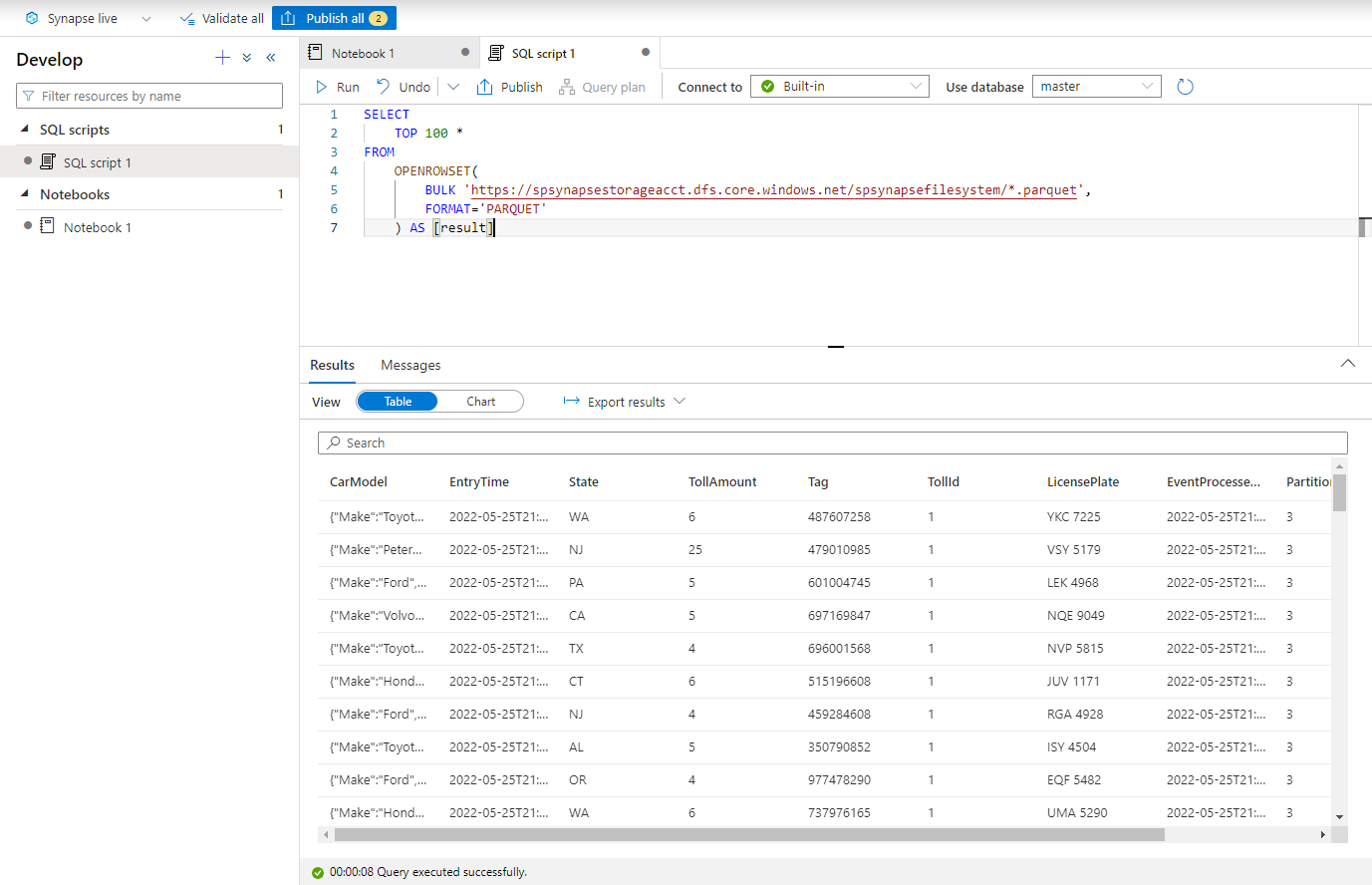

Az erőforrások eltávolítása
- Keresse meg az Event Hubs-példányt, és tekintse meg a Stream Analytics-feladatok listáját a Folyamatadatok szakaszban. Állítsa le a futó feladatokat.
- Nyissa meg azt az erőforráscsoportot, amelyet a TollApp eseménygenerátor üzembe helyezésekor használt.
- Válassza az Erőforráscsoport törlése elemet. Írja be az erőforráscsoport nevét a törlés megerősítéséhez.
Következő lépések
Ebben az oktatóanyagban megtanulta, hogyan hozhat létre Stream Analytics-feladatot a nincs kódszerkesztővel az Event Hubs-adatfolyamok Parquet formátumú rögzítéséhez. Ezután a Azure Synapse Analytics használatával lekérdezte a parquet fájlokat a Synapse Spark és a Synapse SQL használatával.