Az Azure Stream Analytics integrálása az Azure Machine Tanulás
Az Azure Stream Analytics-feladatokban felhasználó által definiált függvényként (UDF) implementálhat gépi tanulási modelleket, hogy valós idejű pontozást és előrejelzéseket hajtson végre a streamelési bemeneti adatokon. Az Azure Machine Tanulás lehetővé teszi bármely népszerű nyílt forráskódú eszköz, például a TensorFlow, a scikit-learn vagy a PyTorch használatát modellek előkészítése, betanítása és üzembe helyezése érdekében.
Előfeltételek
Végezze el az alábbi lépéseket, mielőtt függvényként hozzáad egy gépi tanulási modellt a Stream Analytics-feladathoz:
A modell webszolgáltatásként való üzembe helyezéséhez használja az Azure Machine Tanulás.
A gépi tanulási végpontnak rendelkeznie kell egy társított swaggerszel , amely segít a Stream Analyticsnek megérteni a bemenet és a kimenet sémáját. Ezt a swagger-definíciót hivatkozásként használhatja annak ellenőrzésére, hogy helyesen állította-e be.
Győződjön meg arról, hogy a webszolgáltatás JSON szerializált adatokat fogad és ad vissza.
A modell üzembe helyezése az Azure Kubernetes Service-ben nagy léptékű éles üzembe helyezésekhez. Ha a webszolgáltatás nem tudja kezelni a feladatból érkező kérelmek számát, a Stream Analytics-feladat teljesítménye csökken, ami hatással van a késésre. Az Azure Container Instancesben üzembe helyezett modellek csak az Azure Portal használatakor támogatottak.
Gépi tanulási modell hozzáadása a feladathoz
Azure Machine Tanulás függvényeket közvetlenül az Azure Portalról vagy a Visual Studio Code-ból vehet fel a Stream Analytics-feladatba.
Azure Portal
Navigáljon a Stream Analytics-feladathoz az Azure Portalon, és válassza a Feladatok topológia alatt található Függvények lehetőséget. Ezután válassza az Azure Machine Tanulás Szolgáltatást a +Hozzáadás legördülő menüből.
Töltse ki az Azure Machine Tanulás Service függvényűrlapot a következő tulajdonságértékekkel:
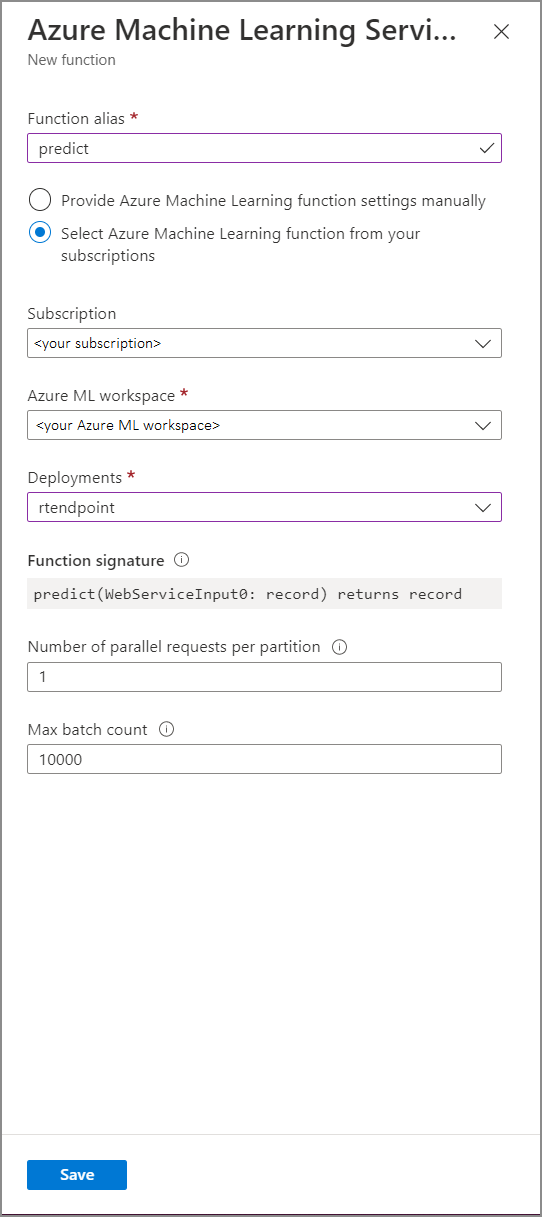
Az alábbi táblázat az Azure Machine Tanulás Service-függvények minden tulajdonságát ismerteti a Stream Analyticsben.
| Tulajdonság | Leírás |
|---|---|
| Függvény aliasa | Adjon meg egy nevet a függvény lekérdezésben való meghívásához. |
| Előfizetés | Az Azure-előfizetése. |
| Azure Machine Learning-munkaterület | Az Azure Machine Tanulás munkaterület, amelyet a modell webszolgáltatásként való üzembe helyezéséhez használt. |
| Végpont | A modellt üzemeltető webszolgáltatás. |
| Függvény aláírása | A webszolgáltatás aláírása, amely az API sémaspecifikációjából származik. Ha az aláírás nem töltődik be, ellenőrizze, hogy a pontozószkriptben mintabemenetet és kimenetet adott-e meg a séma automatikus létrehozásához. |
| Párhuzamos kérések száma partíciónként | Ez egy speciális konfiguráció a nagy léptékű átviteli sebesség optimalizálásához. Ez a szám a feladat egyes partícióiból a webszolgáltatásnak küldött egyidejű kéréseket jelöli. A hat streamelési egységből (SU) és alacsonyabbból egy partícióval rendelkező feladatok. A 12 termékváltozattal rendelkező feladatok két partícióval rendelkeznek, 18 termékváltozat három partícióval és így tovább. Ha például a feladat két partícióval rendelkezik, és ezt a paramétert négyre állítja be, a feladattól nyolc egyidejű kérés érkezik a webszolgáltatáshoz. |
| Maximális kötegszám | Ez egy speciális konfiguráció a nagy léptékű átviteli sebesség optimalizálásához. Ez a szám a webszolgáltatásnak küldött egyetlen kérelemben kötegelt események maximális számát jelöli. |
Gépi tanulási végpont meghívása a lekérdezésből
Amikor a Stream Analytics-lekérdezés meghív egy Azure Machine Tanulás UDF-t, a feladat létrehoz egy JSON szerializált kérést a webszolgáltatásnak. A kérés egy modellspecifikus sémán alapul, amelyet a Stream Analytics a végpont swaggeréből következtet.
Figyelmeztetés
A gépi Tanulás végpontok nem lesznek meghívva, amikor az Azure Portal lekérdezésszerkesztőjével tesztel, mert a feladat nem fut. A végponthívás portálról történő teszteléséhez a Stream Analytics-feladatnak futnia kell.
Az alábbi Stream Analytics-lekérdezés egy példa egy Azure Machine-Tanulás UDF meghívására:
SELECT udf.score(<model-specific-data-structure>)
INTO output
FROM input
WHERE <model-specific-data-structure> is not null
Ha az ML UDF-nek küldött bemeneti adatok inkonzisztensek a várt sémával, a végpont egy 400-as hibakódot tartalmazó választ ad vissza, amely miatt a Stream Analytics-feladat sikertelen állapotba kerül. Javasoljuk, hogy engedélyezze az erőforrásnaplókat a feladatához, ami lehetővé teszi az ilyen problémák egyszerű hibakeresését és hibaelhárítását. Ezért erősen ajánlott:
- Az ML UDF bemenetének ellenőrzése nem null értékű
- Ellenőrizze minden olyan mező típusát, amely bemenet az ML UDF-hez annak biztosítása érdekében, hogy az megfeleljen a végpont által vártnak
Feljegyzés
Az ML UDF-ek kiértékelése egy adott lekérdezési lépés minden egyes sorára érvényes, még akkor is, ha feltételes kifejezéssel (pl. CASE WHEN [A] IS NOT NULL THEN udf.score(A) ELSE '' END). Szükség esetén a WITH záradék használatával hozzon létre eltérő útvonalakat, és csak akkor hívja meg az ML UDF-et, ha szükséges, mielőtt az UNION használatával újra egyesítené az útvonalakat.
Több bemeneti paraméter átadása az UDF-nek
A gépi tanulási modellek bemeneteinek leggyakoribb példái a numpy tömbök és a DataFrame-ek. Egy tömböt JavaScript UDF használatával hozhat létre, és jSON-szerializált DataFrame-et hozhat létre a WITH záradék használatával.
Bemeneti tömb létrehozása
Létrehozhat egy JavaScript UDF-t, amely fogadja az N számú bemenetet, és létrehoz egy tömböt, amely az Azure Machine Tanulás UDF bemeneteként használható.
function createArray(vendorid, weekday, pickuphour, passenger, distance) {
'use strict';
var array = [vendorid, weekday, pickuphour, passenger, distance]
return array;
}
Miután hozzáadta a JavaScript UDF-et a feladathoz, meghívhatja az Azure Machine Tanulás UDF-et a következő lekérdezéssel:
WITH
ModelInput AS (
#use JavaScript UDF to construct array that will be used as input to ML UDF
SELECT udf.createArray(vendorid, weekday, pickuphour, passenger, distance) as inputArray
FROM input
)
SELECT udf.score(inputArray)
INTO output
FROM ModelInput
#validate inputArray is not null before passing it to ML UDF to prevent job from failing
WHERE inputArray is not null
A következő JSON egy példakérés:
{
"Inputs": {
"WebServiceInput0": [
["1","Mon","12","1","5.8"],
["2","Wed","10","2","10"]
]
}
}
Pandas vagy PySpark DataFrame létrehozása
A záradék használatával WITH létrehozhat egy szerializált JSON-adatkeretet, amely bemenetként továbbítható az Azure Machine Tanulás UDF-hez az alább látható módon.
Az alábbi lekérdezés létrehoz egy DataFrame-et a szükséges mezők kiválasztásával, és a DataFrame-et használja az Azure Machine Tanulás UDF bemeneteként.
WITH
Dataframe AS (
SELECT vendorid, weekday, pickuphour, passenger, distance
FROM input
)
SELECT udf.score(Dataframe)
INTO output
FROM Dataframe
WHERE Dataframe is not null
Az alábbi JSON egy példakérés az előző lekérdezésből:
{
"Inputs": {
"WebServiceInput0": [
{
"vendorid": "1",
"weekday": "Mon",
"pickuphour": "12",
"passenger": "1",
"distance": "5.8"
},
{
"vendorid": "2",
"weekday": "Tue",
"pickuphour": "10",
"passenger": "2",
"distance": "10"
}]
}
}
Az Azure Machine Tanulás UDF-ek teljesítményének optimalizálása
Amikor üzembe helyezi a modellt az Azure Kubernetes Service-ben, profilt készíthet a modellről az erőforrás-kihasználtság meghatározásához. Emellett engedélyezheti az alkalmazás Elemzések az üzemelő példányok számára a kérések arányának, a válaszidőknek és a hibák arányának megértéséhez.
Ha nagy eseményteljesítményű forgatókönyve van, előfordulhat, hogy módosítania kell a következő paramétereket a Stream Analyticsben, hogy alacsony végpontok közötti késéssel optimális teljesítményt érjen el:
- Kötegek maximális száma.
- A partíciónkénti párhuzamos kérések száma.
A megfelelő kötegméret meghatározása
A webszolgáltatás üzembe helyezése után 50-től kezdődően különböző kötegméretű mintakérelmet küld, és több százra növeli azt. Például: 200, 500, 1000, 2000 stb. Megfigyelheti, hogy egy bizonyos kötegméret után a válasz késése nő. Az a pont, amely után a válasz késése növekszik, a feladat maximális kötegszámának kell lennie.
A partíciónkénti párhuzamos kérések számának meghatározása
Optimális skálázás esetén a Stream Analytics-feladatnak több párhuzamos kérést kell küldenie a webszolgáltatásnak, és néhány ezredmásodpercen belül választ kell kapnia. A webszolgáltatás válaszának késése közvetlenül befolyásolhatja a Stream Analytics-feladat késését és teljesítményét. Ha a feladatból a webszolgáltatásba irányuló hívás hosszú időt vesz igénybe, valószínűleg megnő a vízjel késleltetése, és a háttérbeli bemeneti események száma is megnőhet.
Alacsony késést érhet el, ha biztosítja, hogy az Azure Kubernetes Service-fürt a megfelelő számú csomóponttal és replikával legyen kiépítve. Kritikus fontosságú, hogy a webszolgáltatás magas rendelkezésre állású legyen, és sikeres válaszokat ad vissza. Ha a feladat olyan hibát kap, amely újrapróbálkozható, például a szolgáltatás nem érhető el (503), automatikusan újra próbálkozik exponenciális visszakapcsolással. Ha a feladat válaszként kap egy ilyen hibát a végponttól, a feladat sikertelen állapotba kerül.
- Hibás kérés (400)
- Ütközés (409)
- Nem található (404)
- Nem engedélyezett (401)
Korlátozások
Ha felügyelt Azure ML-végpontszolgáltatást használ, a Stream Analytics jelenleg csak olyan végpontokhoz tud hozzáférni, amelyek nyilvános hálózati hozzáférése engedélyezve van. Erről bővebben az Azure ML privát végpontjairól szóló oldalon olvashat.