Megjegyzés
Az oldalhoz való hozzáféréshez engedély szükséges. Megpróbálhat bejelentkezni vagy módosítani a címtárat.
Az oldalhoz való hozzáféréshez engedély szükséges. Megpróbálhatja módosítani a címtárat.
Az Azure Stream Analytics egyéni mezőkkel vagy attribútumokkal és egyéni DateTime útvonalmintákkal támogatja az egyéni blobkimenet particionálását.
Egyéni mező vagy attribútumok
Az egyéni mező- vagy bemeneti attribútumok javítják az alsóbb rétegbeli adatfeldolgozási és jelentéskészítési munkafolyamatokat azáltal, hogy nagyobb mértékben szabályozhatják a kimenetet.
Partíciókulcs beállításai
A bemeneti adatok particionálásához használt partíciókulcs vagy oszlopnév tartalmazhat a blobnevekhez elfogadott karaktereket. A beágyazott mezők nem használhatók partíciókulcsként, kivéve, ha aliasokkal együtt használják őket. Bizonyos karakterek használatával azonban fájlhierarchiát hozhat létre. Ha például olyan oszlopot szeretne létrehozni, amely két másik oszlopból származó adatokat egyesít egy egyedi partíciókulcs létrehozásához, az alábbi lekérdezést használhatja:
SELECT name, id, CONCAT(name, "/", id) AS nameid
A partíciókulcsnak , BIGINTvagy FLOATBIT (1.2 kompatibilitási szint vagy magasabb) kell lennieNVARCHAR(MAX). A DateTime, Arrayés Records típusok nem támogatottak, de partíciókulcsként is használhatók, ha sztringekké konvertálják őket. További információ: Azure Stream Analytics-adattípusok.
Példa
Tegyük fel, hogy egy feladat bemeneti adatokat vesz fel egy külső videojáték-szolgáltatáshoz csatlakoztatott élő felhasználói munkamenetekből, ahol a betöltött adatok egy oszlopot client_id tartalmaznak a munkamenetek azonosításához. Az adatok client_idparticionálásához állítsa be a blob elérési útja mintamezőt úgy, hogy a blob kimeneti tulajdonságai között szerepeljen partíció jogkivonat {client_id} a feladat létrehozásakor. Mivel a különböző client_id értékekkel rendelkező adatok a Stream Analytics-feladaton keresztül áramlanak, a kimeneti adatok mappánként egyetlen client_id érték alapján külön mappákba lesznek mentve.

Hasonlóképpen, ha a feladat bemenete több millió érzékelő érzékelőadataiból származik, ahol mindegyik érzékelő rendelkezik egy-egy sensor_idérzékelővel, akkor az útvonalminta az lenne, ha az egyes érzékelők adatait különböző mappákba particionálná {sensor_id} .
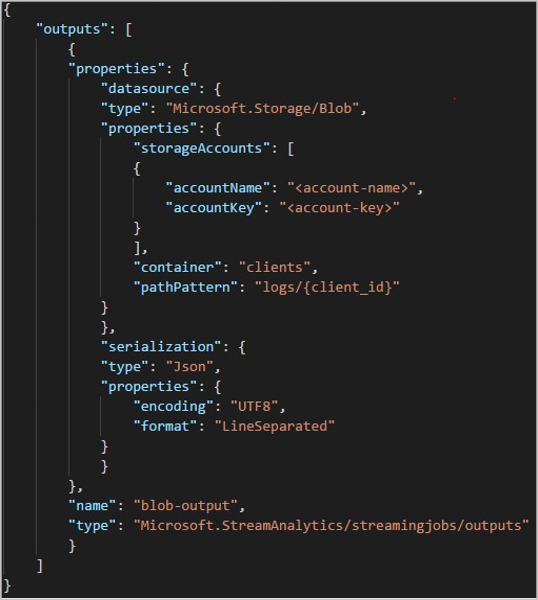
A REST API használatakor a kérelemhez használt JSON-fájl kimeneti szakasza a következő képhez hasonlóan nézhet ki:
A feladat futtatása után a tároló a clients következő képhez hasonlóan nézhet ki:
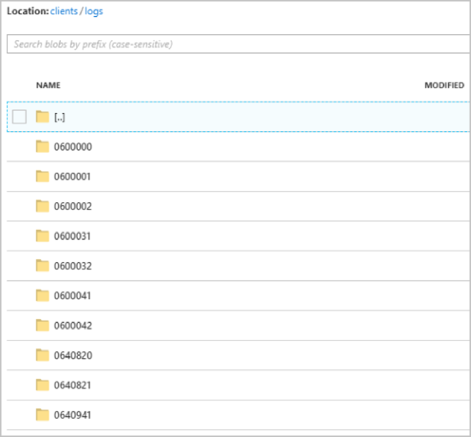
Minden mappa több olyan blobot tartalmazhat, amelyekben minden blob egy vagy több rekordot tartalmaz. Az előző példában egyetlen blob található egy olyan mappában, amely a következő tartalommal van megjelölve "06000000" :
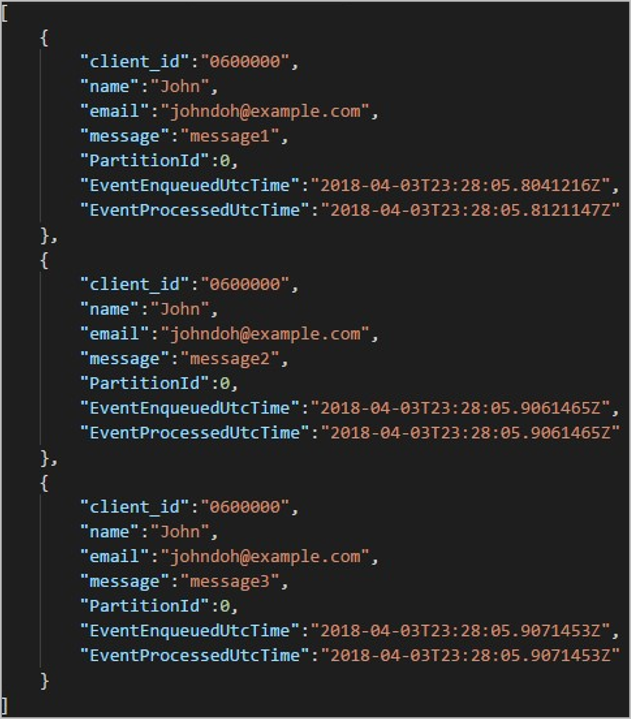
Figyelje meg, hogy a blob minden rekordjának van egy client_id olyan oszlopa, amely megfelel a mappa nevének, mert a kimeneti elérési út kimenetének particionálására használt oszlop volt client_id.
Korlátozások
Az elérésiút-minta blob kimeneti tulajdonságában csak egy egyéni partíciókulcs engedélyezett. Az alábbi útvonalminták mindegyike érvényes:
cluster1/{date}/{aFieldInMyData}cluster1/{time}/{aFieldInMyData}cluster1/{aFieldInMyData}cluster1/{date}/{time}/{aFieldInMyData}
Ha az ügyfelek egynél több bemeneti mezőt szeretnének használni, létrehozhatnak egy összetett kulcsot a blobkimenetben lévő egyéni elérésiút-partíció lekérdezésében a használatával
CONCAT. Például:select concat (col1, col2) as compositeColumn into blobOutput from input. Ezután megadhatócompositeColumnegyéni elérési útként az Azure Blob Storage-ban.A partíciókulcsok nem érzékenyek a kis- és nagybetűkre, ezért a partíciókulcsok hasonlóak
Johnésjohnegyenértékűek. Emellett a kifejezések nem használhatók partíciókulcsként. Például{columnA + columnB}nem működik.Ha egy bemeneti adatfolyam olyan rekordokból áll, amelyek partíciókulcs-számossága 8000 alatt van, a rendszer hozzáfűzi a rekordokat a meglévő blobokhoz. Csak akkor hoznak létre új blobokat, ha szükséges. Ha a számosság meghaladja a 8000-et, nincs garancia arra, hogy a meglévő blobok meg lesznek írva. Az új blobok nem jönnek létre tetszőleges számú, azonos partíciókulcsú rekordhoz.
Ha a blobkimenet nem módosíthatóként van konfigurálva, a Stream Analytics minden egyes adatküldéskor létrehoz egy új blobot.
Egyéni DateTime-útvonalminták
Az egyéni DateTime útvonalminták lehetővé teszik a Hive Streaming-konvencióknak megfelelő kimeneti formátum megadását, így a Stream Analytics képes adatokat küldeni az Azure HDInsightnak és az Azure Databricksnek az alsóbb rétegbeli feldolgozáshoz. Az egyéni DateTime elérésiút-minták egyszerűen implementálhatóak a datetime blobkimenet Elérési útelőtag mezőjében található kulcsszó és a formátumjelölő használatával. Például: {datetime:yyyy}.
Támogatott jogkivonatok
Az egyéni formátumok eléréséhez DateTime a következő formátumkijelölő jogkivonatok használhatók önállóan vagy kombinálva.
| Formátumkijelölő | Leírás | Eredmények a 2018-01-02T10:06:08 példaidőn |
|---|---|---|
| {datetime:yyyyy} | Az év négyjegyű számként | 2018 |
| {datetime:MM} | Hónap 01 és 12 között | 01 |
| {datetime:M} | 1 és 12 közötti hónap | 0 |
| {datetime:dd} | Nap 01 és 31 között | 02 |
| {datetime:d} | Nap 1 és 31 között | 2 |
| {datetime:HH} | Óra 24 órás formátumban, 00 és 23 között | 10 |
| {datetime:mm} | Perc 00 és 60 között | 06 |
| {datetime:m} | Perc 0 és 60 között | 6 |
| {datetime:ss} | Másodperc 00 és 60 között | 08 |
Ha nem szeretne egyéni DateTime mintákat használni, hozzáadhatja a {date} és/vagy {time} a jogkivonatot az Elérési út előtag mezőhöz, hogy beépített DateTime formátumokat tartalmazó legördülő menüt hozzon létre.
Bővíthetőség és korlátozások
Az elérési út mintájában tetszőleges számú jogkivonatot használhat{datetime:<specifier>}, amíg el nem éri az elérési út előtagjának karakterkorlátját. A formátumjelölők nem kombinálhatók egyetlen jogkivonaton belül a dátum- és idő legördülő listákban már felsorolt kombinációkon túl.
A következő elérésiút-partícióhoz logs/MM/dd:
| Érvényes kifejezés | Érvénytelen kifejezés |
|---|---|
logs/{datetime:MM}/{datetime:dd} |
logs/{datetime:MM/dd} |
Az elérési út előtagjában többször is használhatja ugyanazt a formátumkijelölőt. A jogkivonatot minden alkalommal meg kell ismételni.
Hive Streaming-konvenciók
A Blob Storage egyéni elérési útvonalmintái a Hive Streaming konvencióval használhatók, amely azt várja, hogy a mappák címkéje column= szerepeljen a mappanévben.
Például: year={datetime:yyyy}/month={datetime:MM}/day={datetime:dd}/hour={datetime:HH}.
Az egyéni kimenet kiküszöböli a táblák módosításának és a partíciók manuális hozzáadásának a Stream Analytics és a Hive közötti portadatokhoz való hozzáadását. Ehelyett számos mappa automatikusan hozzáadható az alábbiak használatával:
MSCK REPAIR TABLE while hive.exec.dynamic.partition true
Példa
Hozzon létre egy tárfiókot, egy erőforráscsoportot, egy Stream Analytics-feladatot és egy bemeneti forrást a Stream Analytics Azure Portal rövid útmutatójának megfelelően. Használja ugyanazokat a mintaadatokat, amelyeket a rövid útmutatóban használt. A mintaadatok a GitHubon is elérhetők.
Hozzon létre egy blob kimeneti fogadót a következő konfigurációval:
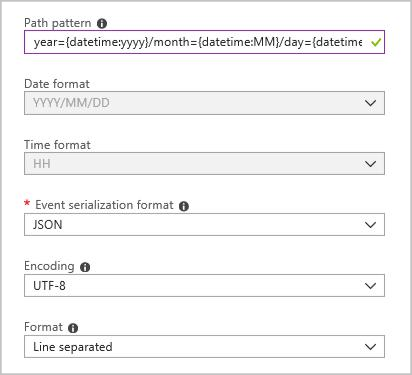
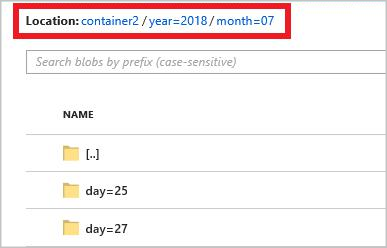
A teljes útvonalminta a következő:
year={datetime:yyyy}/month={datetime:MM}/day={datetime:dd}
A feladat indításakor létrejön a blobtárolóban az elérési út mintáján alapuló mappastruktúra. Lehatolást végezhet a napi szinten.